

第十九篇【传奇开心果系列】Python的OpenCV库技术点案例示例:文字识别与OCR
OpenCV文字识别与OCR:用于识别图像中的文字内容,并进行光学字符识别。OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理计算机视觉算法。虽然CV 本身并不包含专门的 OCR(Optical Character Recognition,光学字符识别)功能,但可以配合其他 OCR 引擎或库来实现图像中的文字识别。O
传奇开心果短博文系列
- 系列短博文目录
- Python的OpenCV库技术点案例示例系列
- 短博文目录
- 前言
- 一、OpenCV 文字识别介绍
- 二、图像预处理示例代码
- 三、文字区域检测示例代码
- 四、文字识别示例代码
- 五、文字后处理示例代码
- 六、OpenCV结合Tesseract OCR库实现文字识别示例代码
- 七、OpenCV结合OCRopus库文字识别示例代码
- 八、OpenCV 结合Google Cloud Vision API 文字识别示例代码
- 九、OpenCV结合图像预处理技术文字识别示例代码
- 十、OpenCV结合文字区域检测技术文字识别示例代码
- 十一、归纳总结
系列短博文目录
Python的OpenCV库技术点案例示例系列
短博文目录
前言
 OpenCV文字识别与OCR:用于识别图像中的文字内容,并进行光学字符识别。
OpenCV文字识别与OCR:用于识别图像中的文字内容,并进行光学字符识别。
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理计算机视觉算法。虽然CV 本身并不包含专门的 OCR(Optical Character Recognition,光学字符识别)功能,但可以配合其他 OCR 引擎或库来实现图像中的文字识别。
OCR 是一种将图像中的文本内容转换为可编辑文本的技术。它可以应用于各种场景,如自动化数据录入、图像搜索、车牌识别、文档扫描等。
一、OpenCV 文字识别介绍
 (一)在使用 OpenCV 进行文字识别时,通常的步骤如下:
(一)在使用 OpenCV 进行文字识别时,通常的步骤如下:
-
图像预处理:使用 OpenCV 的图像处理功能,如灰度化、二值化、滤波等,对图像进行预处理,以提高文字识别的准确性。
-
文字区域检测:通过边缘检测、轮廓检测等技术,找到图像中的文字区域。
-
文字识别:将文字区域提取出来,使用 OCR 引擎或库进行光学字符识别。常见的 OCR 引擎包括 Tesseract、OCRopus、Google Cloud Vision 等。
-
文字后处理:对识别结果进行后处理,如去除噪声、校正错误、整理格式等。
(二)OpenCV结合其他 OCR 引擎或库来实现完整的文字识别功能
在实际应用中,可以根据项目需求选择合适的 OCR 引擎,并结合 OpenCV 进行图像处理和文字区域检测,以实现准确的文字识别功能。
下面补充一些关于OpenCV文字识别与OCR的信息:
-
Tesseract OCR:Tesseract 是一个开源的 OCR 引擎,由 Google 开发和维护。它支持多种语言,并且具有较高的文字识别准确性。你可以使用 Tesseract OCR 库来配合 OpenCV 进行文字识别。
-
OCRopus:OCRopus 是基于 Tesseract 的 OCR 引擎,提供了更多的自定义和扩展性。它允许你根据特定需求进行训练和优化,以提高文字识别的效果。
-
Google Cloud Vision API:Google Cloud Vision 是一种云端 OCR 服务,提供了强大的文字识别功能。它可以处理多种图像类型,包括扫描文档、照片、屏幕截图等,并提供了准确的文字识别结果。
-
图像预处理技术:在文字识别之前,通常需要对图像进行预处理来提高识别准确性。常见的预处理技术包括灰度化、二值化、去噪、图像增强等。OpenCV 提供了丰富的图像处理函数和算法,可以用于这些预处理步骤。
-
文字区域检测技术:在文字识别过程中,需要确定图像中的文字区域。常用的文字区域检测技术包括边缘检测、轮廓检测、连通组件分析等。OpenCV 提供了这些功能的实现方法,可以帮助你找到图像中的文字区域。
总之,OpenCV 是一个强大的计算机视觉库,可以与 OCR 引擎结合使用,实现图像中的文字识别。通过合理选择 OCR 引擎,并结合适当的图像预处理和文字区域检测技术,可以获得准确和高效的文字识别结果。
二、图像预处理示例代码
 以下是使用 OpenCV 进行图像预处理的示例代码,包括灰度化、二值化和滤波:
以下是使用 OpenCV 进行图像预处理的示例代码,包括灰度化、二值化和滤波:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
P = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 中值滤波
filtered = cv2.medianBlur(binary, 3)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray)
cv2.imshow('Binary Image', binary)
cv2.imshow('Filtered Image', filtered)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理。通过设定阈值和使用 OTSU 自适应阈值算法,将灰度图像转换为二值图像,将结果存储在 binary 变量中。
最后,使用 cv2.medianBlur() 函数对二值图像进行中值滤波,以去除噪声。将滤波后的图像存储在 filtered 变量中。
最后,使用 cv2.imshow() 函数显示原始图像、灰度图像、二值图像和滤波后的图像。使用 cv2.waitKey() 函数等待键盘输入,最后使用 cv2.destroyAllWindows() 函数关闭窗口。
这些预处理步骤可以根据需要进行调整和组合,以提高文字识别的准确性和质量。请根据实际情况选择适合的预处理方法。
三、文字区域检测示例代码
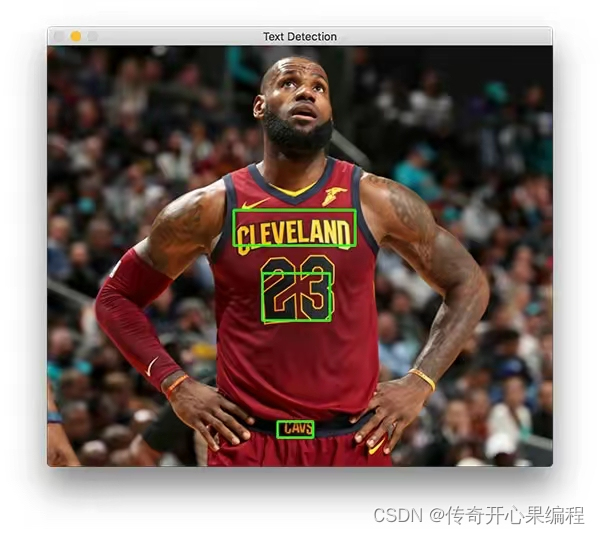 以下是使用 OpenCV 进行文字区域检测的示例代码,包括边缘检测和轮廓检测:
以下是使用 OpenCV 进行文字区域检测的示例代码,包括边缘检测和轮廓检测:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 边缘检测
edges = cv2.Canny(gray, 50, 150)
# 轮廓检测
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制矩形框
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.Canny() 函数进行边缘检测,将结果存储在 edges 变量中。在这个示例中,我们使用 Canny 边缘检测算法,设定阈值为 50 和 150。
最后,使用 cv2.findContours() 函数对边缘图像进行轮廓检测,将轮廓结果存储在 contours 变量中。我们使用 cv2.RETR_EXTERNAL 参数表示只检测外部轮廓,并使用 cv2.CHAIN_APPROX_SIMPLE 参数表示使用简化的轮廓表示。
接下来,使用 cv2.rectangle() 函数在原始图像上绘制矩形框,标识出文字区域。通过 cv2.boundingRect() 函数获取每个轮廓的边界框坐标,然后使用 cv2.rectangle() 函数绘制矩形框。
最后,使用 cv2.imshow() 函数显示原始图像和边缘图像。使用 cv2.waitKey() 函数等待键盘输入,最后使用 cv2.destroyAllWindows() 函数关闭窗口。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行参数调整和算法优化,以达到更好的文字区域检测效果。
四、文字识别示例代码
 以下是使用 OpenCV 进行文字识别的示例代码,结合 Tesseract OCR 引擎进行光学字符识别:
以下是使用 OpenCV 进行文字识别的示例代码,结合 Tesseract OCR 引擎进行光学字符识别:
import cv2
import pytesseract
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 使用 Tesseract 进行文字识别
result = pytesseract.image_to_string(binary, lang='eng')
# 打印识别结果
print(result)
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
最后,使用 pytesseract.image_to_string() 函数将二值图像传递给 Tesseract OCR 引擎进行文字识别。通过指定 lang 参数来选择使用的语言,这里使用了英文 'eng'。
识别结果会存储在 result 变量中,你可以根据需要进行后续处理或打印输出。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。此外,你也可以选择其他 OCR 引擎或库来替代 Tesseract,如 OCRopus 或 Google Cloud Vision,使用方法类似。
五、文字后处理示例代码
 文字后处理是在文字识别完成后对识别结果进行进一步处理的步骤,常见的后处理操作包括去除噪声、校正错误和整理格式。以下是一个简单的示例代码,展示了如何使用 Python 进行文字后处理:
文字后处理是在文字识别完成后对识别结果进行进一步处理的步骤,常见的后处理操作包括去除噪声、校正错误和整理格式。以下是一个简单的示例代码,展示了如何使用 Python 进行文字后处理:
import re
def postprocess_text(text):
# 去除非字母和数字的字符
text = re.sub(r'[^a-zA-Z0-9]', '', text)
# 校正错误
# ...
# 整理格式
# ...
return text
# 假设识别结果存储在 result 变量中
result = "H3llo, W0r1d!"
# 进行文字后处理
processed_text = postprocess_text(result)
# 打印处理后的结果
print(processed_text)
在上述示例中,我们定义了一个 postprocess_text() 函数来执行文字后处理操作。这个函数使用正则表达式 re.sub() 来去除非字母和数字的字符,只保留字母和数字。你可以根据实际需求定制自己的规则来去除其他特定字符。
除了去除噪声外,文字后处理还可以用于校正识别错误和整理识别结果的格式。校正错误的方法可以根据实际情况选择,例如使用拼写纠正算法或者通过与词典进行比对来进行修正。整理格式的方法也可以根据需求进行定制,例如添加分隔符、调整字母大小写等。
在示例代码中,我们假设识别结果存储在 result 变量中,然后将其传递给 postprocess_text() 函数进行后处理。处理后的结果存储在 processed_text 变量中,并打印输出。
请注意,这只是一个简单的示例代码,实际的文字后处理操作可能会更加复杂,需要根据具体需求进行定制。你可以根据实际情况来编写适合你的后处理函数,以提高文字识别结果的准确性和质量。
六、OpenCV结合Tesseract OCR库实现文字识别示例代码
 以下是一个示例代码,展示了如何结合 OpenCV 和 Tesseract OCR 进行文字识别:
以下是一个示例代码,展示了如何结合 OpenCV 和 Tesseract OCR 进行文字识别:
import cv2
import pytesseract
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 使用 Tesseract 进行文字识别
result = pytesseract.image_to_string(binary, lang='eng')
# 打印识别结果
print(result)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
最后,使用 pytesseract.image_to_string() 函数将二值图像传递给 Tesseract OCR 引擎进行文字识别。通过指定 lang 参数来选择使用的语言,这里使用了英文 'eng'。
识别结果会存储在 result 变量中,你可以根据需要进行后续处理或打印输出。
请注意,运行此代码之前,你需要先安装并配置好 OpenCV 和 Tesseract OCR。你可以通过 pip install opencv-python 和 pip install pytesseract 命令来安装相应的库。同时,确保已经下载并安装了 Tesseract OCR 的语言数据包,以支持相应语言的识别。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。你还可以通过调整 Tesseract OCR 的参数来优化识别结果,例如设置字典、调整识别方式等。
七、OpenCV结合OCRopus库文字识别示例代码
 OCRopus 是一个基于 Tesseract 的 OCR 引擎,它提供了更多的自定义和扩展性,允许你根据特定需求进行训练和优化,以提高文字识别的效果。下面是一个使用 OpenCV 结合 OCRopus 进行文字识别的示例代码:
OCRopus 是一个基于 Tesseract 的 OCR 引擎,它提供了更多的自定义和扩展性,允许你根据特定需求进行训练和优化,以提高文字识别的效果。下面是一个使用 OpenCV 结合 OCRopus 进行文字识别的示例代码:
import cv2
from ocropy import ocrolib
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 保存图像到临时文件
cv2.imwrite('temp.png', binary)
# 使用 OCRopus 进行文字识别
ocrolib.iopen('temp.png').binarize().write_page('temp.ocropus')
ocrolib.tesseract_page('temp.ocropus').write_text()
# 读取识别结果
with open('temp.txt', 'r', encoding='utf-8') as file:
result = file.read()
# 打印识别结果
print(result)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
接下来,我们将二值图像保存到临时文件 temp.png 中,以便 OCRopus 进行处理。
然后,使用 OCRopus 的 ocrolib 模块来进行文字识别。我们首先使用 ocrolib.iopen() 函数打开二值图像文件,然后使用 .binarize() 方法对图像进行二值化处理,并将处理结果保存为 OCRopus 的页面格式 temp.ocropus。
接着,使用 ocrolib.tesseract_page() 函数对页面进行 OCR 识别,并将识别结果保存为文本文件 temp.txt。
最后,我们读取文本文件中的识别结果,并将其存储在 result 变量中。你可以根据需要进行后续处理或打印输出。
请注意,在运行此代码之前,你需要先安装并配置好 OCRopus 和 Tesseract OCR。你可以通过 pip install ocropy 命令来安装 OCRopus。同时,确保已经下载并安装了 Tesseract OCR 的语言数据包,以支持相应语言的识别。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。你还可以根据需要调整 OCRopus 的参数和配置文件,以优化识别结果。
八、OpenCV 结合Google Cloud Vision API 文字识别示例代码
要结合 OpenCV 和 Google Cloud Vision API 进行文字识别,你需要先设置好 Google Cloud 平台的相关服务,并安装 google-cloud-vision 库。下面是一个示例代码,展示了如何使用 OpenCV 结合 Google Cloud Vision API 进行文字识别:
import cv2
from google.cloud import vision
# 读取图像
image = cv2.imread('image.jpg')
# 将图像转换为字节流
_, img_encoded = cv2.imencode('.jpg', image)
img_bytes = img_encoded.tobytes()
# 使用 Google Cloud Vision API 进行文字识别
client = vision.ImageAnnotatorClient()
image = vision.Image(content=img_bytes)
response = client.text_detection(image=image)
texts = response.text_annotations
# 打印识别结果
for text in texts:
print(text.description)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
然后,我们使用 cv2.imencode() 函数将图像编码为 JPG 格式的字节流,然后将其转换为字节字符串 img_bytes。
接下来,我们使用 google-cloud-vision 库中的 ImageAnnotatorClient 类创建一个 Cloud Vision API 的客户端。
然后,我们将图像字节字符串传递给 vision.Image 类创建一个图像对象 image。
接着,我们使用 client.text_detection() 方法对图像进行文字识别,返回一个包含文字信息的响应对象 response。
最后,我们从响应对象中提取出识别结果 texts,并遍历打印每个文字块的内容。
请注意,在运行此代码之前,你需要先在 Google Cloud 平台上创建一个项目,并启用 Vision API 服务。然后,你需要安装 google-cloud-vision 库,并配置好你的身份验证凭据。
此外,你还可以根据需要,使用 Cloud Vision API 的其他功能,如检测文字语言、识别文本坐标等。具体的 API 使用方法和参数设置可以参考 Google Cloud Vision API 的官方文档。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。同时,你需要根据你的实际需求和云平台的限制,选择适合的服务套餐和配置。
九、OpenCV结合图像预处理技术文字识别示例代码
 在文字识别之前,进行图像预处理是提高识别准确性的重要步骤。OpenCV 提供了丰富的图像处理函数和算法,可以用于各种预处理技术。以下是一些常见的预处理技术示例代码:
在文字识别之前,进行图像预处理是提高识别准确性的重要步骤。OpenCV 提供了丰富的图像处理函数和算法,可以用于各种预处理技术。以下是一些常见的预处理技术示例代码:
- 灰度化:
import cv2
# 读取彩色图像
image = cv2.imread('image.jpg')
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- 二值化:
import cv2
# 读取灰度图像
gray = cv2.imread('gray_image.jpg', 0)
# 使用固定阈值二值化
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 使用自适应阈值二值化
binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
- 去噪:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 使用中值滤波去除噪声
denoised = cv2.medianBlur(image, 5)
# 使用高斯滤波去除噪声
denoised = cv2.GaussianBlur(image, (5, 5), 0)
- 图像增强:
import cv2
import numpy as np
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 直方图均衡化
equalized = cv2.equalizeHist(gray)
# 自适应直方图均衡化
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
adaptive_equalized = clahe.apply(gray)
这些是一些常见的图像预处理技术示例代码,你可以根据具体情况选择适合的预处理步骤和参数。在实际应用中,可能需要结合多种预处理技术,并进行参数调整和优化,以获得最佳的文字识别效果。
请注意,在使用 OpenCV 进行图像预处理时,可以根据图像的特点和需求选择适当的函数和算法。同时,还可以结合其他图像处理库或算法,如 PIL、numpy 等,以实现更复杂的图像处理任务。
这些示例代码只是为了演示常见的图像预处理技术,并不能覆盖所有情况。在实际应用中,你可能需要根据具体需求进行更详细和复杂的图像处理操作。
十、OpenCV结合文字区域检测技术文字识别示例代码
 在文字识别过程中,确定图像中的文字区域是一个关键步骤。OpenCV 提供了多种文字区域检测技术的实现方法,包括边缘检测、轮廓检测和连通组件分析。以下是一些示例代码,展示了如何使用 OpenCV 结合这些技术来识别文字区域:
在文字识别过程中,确定图像中的文字区域是一个关键步骤。OpenCV 提供了多种文字区域检测技术的实现方法,包括边缘检测、轮廓检测和连通组件分析。以下是一些示例代码,展示了如何使用 OpenCV 结合这些技术来识别文字区域:
- 边缘检测:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Canny 边缘检测
edges = cv2.Canny(gray, 50, 150)
- 轮廓检测:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 查找轮廓
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
- 连通组件分析:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 连通组件分析
_, labels, stats, _ = cv2.connectedComponentsWithStats(binary)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
然后,我们根据需要进行灰度化操作,将彩色图像转换为灰度图像。
接下来,我们可以选择使用边缘检测的方法,如 cv2.Canny() 函数,或者使用轮廓检测的方法,如 cv2.findContours() 函数,来获取图像中的文字区域的边缘或轮廓信息。
另外,我们还可以使用连通组件分析的方法,如 cv2.connectedComponentsWithStats() 函数,来获取图像中的文字区域的连通组件信息。
请注意,这些示例代码只是为了演示常见的文字区域检测技术,并不能覆盖所有情况。在实际应用中,你可能需要根据具体需求和图像特点,选择适合的方法和参数,并进行适当的后处理和优化,以获得准确的文字区域。
同时,你还可以结合其他图像处理技术,如形态学操作、角点检测等,来进一步提高文字区域的检测效果。
十一、归纳总结
 OpenCV 是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉功能。结合 OCR(Optical Character Recognition)技术,可以实现文字识别的功能。下面是关于 OpenCV 文字识别与 OCR 的一些归纳总结知识点:
OpenCV 是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉功能。结合 OCR(Optical Character Recognition)技术,可以实现文字识别的功能。下面是关于 OpenCV 文字识别与 OCR 的一些归纳总结知识点:
-
图像预处理:在文字识别之前,通常需要对图像进行预处理,以提高识别准确性。常见的预处理技术包括灰度化、二值化、去噪、图像增强等。OpenCV 提供了丰富的图像处理函数和算法,可以用于这些预处理步骤。
-
文字区域检测:确定图像中的文字区域是文字识别的关键步骤。常用的文字区域检测技术包括边缘检测、轮廓检测、连通组件分析等。OpenCV 提供了这些功能的实现方法,可以帮助你找到图像中的文字区域。
-
OCR 引擎:OCR 引擎是实现文字识别的核心组件。OpenCV 并没有内置 OCR 功能,但可以与其他 OCR 引擎集成,如 Tesseract、OCRopus 等。这些 OCR 引擎提供了强大的文字识别能力,可以识别多种语言和字体的文字。
-
文字识别流程:文字识别通常包括图像预处理、文字区域检测和文字识别三个主要步骤。通过使用 OpenCV 进行图像预处理和文字区域检测,再结合 OCR 引擎进行文字识别,可以实现完整的文字识别流程。
-
参数调优:在进行文字识别时,需要根据具体情况进行参数调优,以获得最佳的识别效果。例如,在图像预处理中,可以调整灰度化方法、二值化阈值等参数;在文字区域检测中,可以选择合适的边缘检测算法、轮廓检测方法等。
-
多语言支持:OCR 引擎通常支持多种语言的文字识别。你可以根据需要选择合适的语言模型和字库,以支持相应语言的识别。
-
性能优化:文字识别可能涉及大量的图像处理和计算操作,对计算资源要求较高。为了提高性能,可以采用多线程、GPU 加速等技术手段,以加快文字识别的速度。

这些是关于 OpenCV 文字识别与 OCR 的一些归纳总结知识点。在实际应用中,需要根据具体需求和场景,选择合适的方法和工具,进行适当的参数调优和优化,以获得准确和高效的文字识别结果。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 48
48 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)