毕业设计:基于深度学习的动态手势识别系统 人工智能
毕业设计:基于深度学习的动态手势识别系统利用深度学习和计算机视觉技术,能够准确地识别手势并将其分类。通过对手势图像进行特征提取和数据扩充,使用KNN模型进行训练和分类。这项毕业设计为计算机毕业生提供了一个有意义的研究课题,并开拓了一个创新的方向,为未来的手势识别技术发展提供了新的思路和方法。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个具有挑战性和创新性的研究课题。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的动态手势识别系统
设计思路
一、课题背景与意义
随着人机交互需求的增加,以人为中心的交互技术备受关注。本文提出了一种基于深度学习的手势识别模型,能够通过最佳阈值切割图像并进行手势识别。该模型利用傅里叶描述子计算轮廓,并通过图像预处理、肤色检测、特征提取和图像分割等步骤提取相关信息。综合应用上述技术,深度学习模型在手势识别领域具有广泛的应用价值。这种模型为人机交互领域的研究和应用提供了创新的方向,并有望为实现更自然、直观的人机交互体验做出重要贡献。
二、算法理论原理
2.1 卷积神经网络
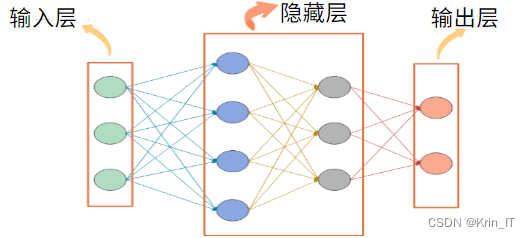
传统的神经网络由神经元和计算关系组成,不同神经元之间存在复杂的计算关系,并且这些计算关系都有一个权重,在模型训练过程中不断调整这些权重。然而,传统神经网络的缺点在于参数众多、冗余度大、难以训练。每层节点和上一层节点相连接的全连接网络结构导致了参数冗余和计算开销的增加。这限制了传统神经网络的性能和扩展性。因此,为了克服这些问题,研究者提出了各种改进的神经网络结构,卷积神经网络(CNN)以提高模型的效率和性能。这些改进使得神经网络在计算机视觉、自然语言处理和语音识别等领域取得了重大突破,并为深度学习的发展奠定了基础。
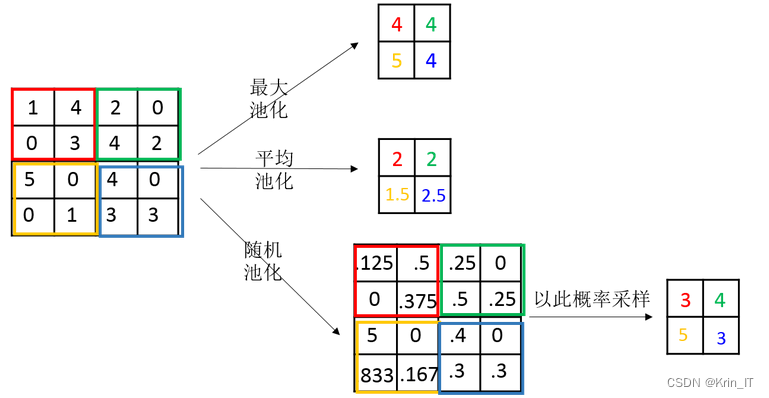
手势识别是一项关键的人机交互技术,而CNN通过其对图像特征的有效学习和提取能力,在手势识别任务中取得了显著的成果。CNN的卓越性能主要得益于其特殊的网络结构和参数共享机制。卷积层通过卷积操作对输入图像进行特征提取,提取到的特征能够捕捉到手势中的空间局部性。池化层则负责对特征图进行下采样,减少数据维度和参数量,同时保留关键特征。这种卷积和池化的交替操作使得CNN能够自动学习到图像中的抽象特征,并具备平移不变性和部分空间不变性的特性。
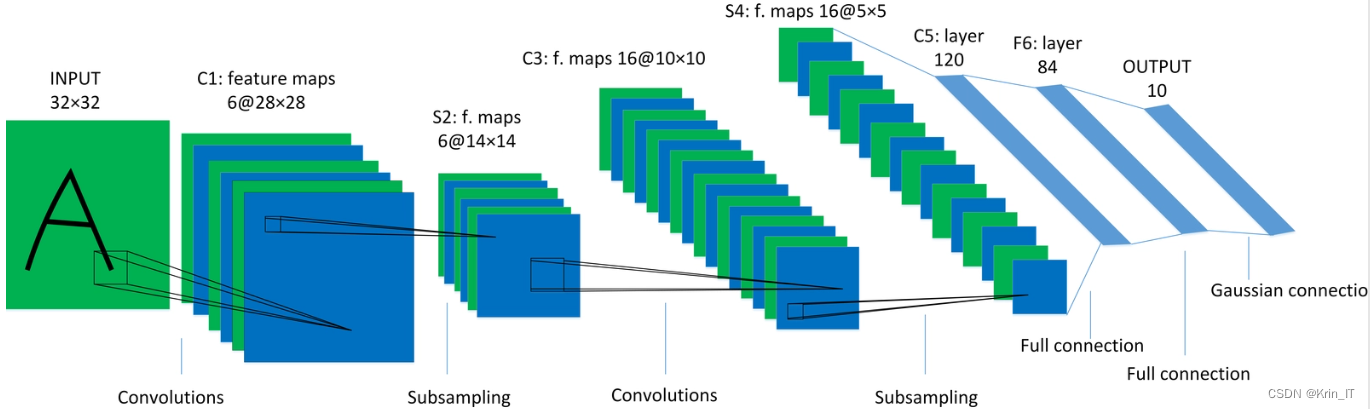
在手势识别系统中,CNN通常会经过预处理步骤,如肤色检测和图像分割,以提取手势区域。然后,这些手势图像经过CNN的前向传播,通过多个卷积层和池化层进行特征提取和降维。最后,通过全连接层和Softmax分类器进行手势的识别和分类。
卷积神经网络在手势识别系统中 在实时性、准确性和鲁棒性等方面表现出色,能够识别出手势的动态和静态特征,为人机交互提供了更自然、直观的方式。
相关代码示例:
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 数据预处理和准备
# 假设训练数据和标签存储在train_data和train_labels中,测试数据存储在test_data中
# train_data的形状为 (样本数量, 图片宽度, 图片高度, 图像通道数),train_labels的形状为 (样本数量, 类别数量)
# 构建CNN模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(图像宽度, 图像高度, 图像通道数)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(类别数量, activation='softmax'))
# 编译和训练模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=训练轮数, batch_size=批次大小)
# 在测试集上评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
print('Test accuracy:', test_acc)
# 对新的手势图像进行预测
predictions = model.predict(new_gesture_data)2.2 手势识别
手势识别系统的步骤包括实时手势图像获取、图像预处理、特征提取和手势分类。下面是一个更详细的总结:
-
实时手势图像获取:使用摄像头或其他图像采集设备获取实时手势图像。
-
图像预处理:对获取的手势图像进行预处理,以提高图像的清晰度和减少噪声。预处理步骤可以包括图像增强、图像锐化等技术,以改善图像质量。
-
特征提取:从预处理后的手势图像中提取特征,以捕捉手势的关键信息。在手势识别中,常用的特征提取方法包括计算手势的轮廓、颜色特征、纹理特征等。
-
手势分割:根据特定的手势识别任务需求,对手势图像进行分割,提取出手势区域。在手势识别中,常用的分割方法是基于阈值的二值化算法。可以使用颜色空间转换(如YCrcb颜色空间中的Cr分量)来提高分割效果。
-
手势分类:将分割后的手势图像输入到训练好的机器学习模型(如卷积神经网络)中进行分类。模型将根据学习到的特征和训练数据进行手势分类,确定当前手势的类别。
-
获取手势信息:根据分类结果,获取手势的相关信息,如手势的标签、动作、意图等,以支持后续的人机交互操作。
特征图像可以通过可视化的方式展示原始数据中的特征信息,帮助研究人员和分析师更直观地观察、分析和解释数据。特征图像不仅可以用于特征选择和提取,指导数据预处理步骤,还可以应用于模式识别和分类任务。通过特征图像,我们能够更好地理解数据中的特征,传达数据的含义,并支持决策和沟通。
特征图像的创建过程如下:
-
创建一个空白图像:首先,创建一个与原始图像尺寸相同的空白图像。
-
填充像素值:将描述子的每个元素作为像素值填充到图像中对应的位置。这将在特征图像中表达出原始图像中的特征信息。
-
调整图像大小和尺度:根据特定的应用场景,可能需要调整特征图像的大小和尺度,以便更好地展示和分析特征。
-
图像处理技术:使用各种图像处理技术,如调色板、平滑滤波器、边缘检测等,来突出显示特征。这些技术可以增强特征的可视化效果,使其更易于理解和分析。
-
叠加显示:将特征图像与原始曲线图像进行叠加显示,以便直观地比较和分析特征与原始数据之间的关系。
相关代码示例:
import cv2
import numpy as np
from keras.models import load_model
# 加载训练好的手势识别模型
model = load_model('gesture_model.h5')
# 获取实时手势图像
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 图像预处理
# 进行图像增强、锐化等操作来提高图像清晰度
# 手势分割
# 将图像转换到YCrCb颜色空间,并使用Cr分量进行阈值分割
# 手势分类
# 将分割后的手势图像输入到模型中进行分类
gesture = model.predict(np.expand_dims(frame, axis=0))
# 获取手势信息
# 根据分类结果获取手势的标签、动作等信息
# 在图像上绘制识别结果
cv2.putText(frame, gesture, (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示图像
cv2.imshow('Gesture Recognition', frame)
# 按下'q'键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头和关闭窗口
cap.release()
cv2.destroyAllWindows()三、检测的实现
由于网络上没有现有的合适的数据集,我决定自己进行拍摄,收集手势识别场景的照片,并制作了一个全新的数据集。这个数据集包含了各种真实的手势示例,涵盖了不同的手势动作和背景环境。通过现场拍摄,我能够捕捉到真实的手势表达和多样的使用场景,这将为我的手势识别研究提供更准确、可靠的数据。

数据扩充是对手势识别数据集进行增强的关键步骤,可以通过镜像翻转、旋转、缩放、平移、亮度调整、噪声添加和裁剪等方法生成更多样的手势图像。这些方法可以增加数据集的多样性和数量,提高模型的泛化能力,并使其对手势的位置、大小、旋转、光照和噪声等变化具有鲁棒性。在进行数据扩充时,需要确保生成的图像仍然保持手势的真实性和可识别性。通过合理地应用数据扩充技术,可以为手势识别研究提供更准确、可靠的数据基础,推动该领域的发展和应用。

相关代码示例:
import cv2
import numpy as np
# 读取原始图像
image = cv2.imread('gesture_image.jpg')
# 镜像翻转
flipped_image = cv2.flip(image, 1) # 1表示水平翻转,0表示垂直翻转
# 旋转
angle = 30 # 旋转角度
rows, cols = image.shape[:2]
rotation_matrix = cv2.getRotationMatrix2D((cols / 2, rows / 2), angle, 1)
rotated_image = cv2.warpAffine(image, rotation_matrix, (cols, rows))
# 显示图像
cv2.imshow('Original Image', image)
cv2.imshow('Flipped Image', flipped_image)
cv2.imshow('Rotated Image', rotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()在手势识别任务中,通过提取的手势特征进行机器学习模型训练是一种常见的方法。在实验中,使用了KNN模型进行训练和分类
使用KNN模型进行训练的基本步骤:
-
准备训练数据:将扩充后的特征向量与对应的手势类别标签配对,形成训练数据集。确保特征向量和类别标签的顺序一致。
-
特征标准化:根据需要,对特征向量进行标准化处理,以确保各个特征具有相同的尺度。常见的标准化方法包括均值归一化和标准差归一化等。
-
初始化KNN模型:使用机器学习库(如scikit-learn)导入KNN模型,并根据需要设置KNN算法的参数,如K值、距离度量方法等。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5) # 设置K值为5- 模型训练:使用训练数据集对KNN模型进行训练。
- 模型评估:使用测试数据集评估模型的性能和泛化能力。
- 模型预测:使用训练好的KNN模型对新的手势特征向量进行分类预测。
knn.fit(X_train, y_train)
accuracy = knn.score(X_test, y_test)
y_pred = knn.predict(X_new)毕设帮助,疑难解答,欢迎打扰!
最后

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)