使用pytorch进行深度学习网络模型训练,实现车型识别
残差结构是通过一个快捷连接,极大的减少了参数数量,降低了内存使用。除了最开始看到的train-val图表、Top-、Top-5的error记录表以外,在训练过程中,使用进度条打印当前训练的进度、训练精度等信息。任何一个深度学习的模型训练都是离不开数据集的,根据多种多样的数据集,我们应该使用一个方式将数据集用一种通用的结构返回,方便网络模型的加载处理。启动器是项目的入口,通过对启动器参数的设置,可以
模型训练
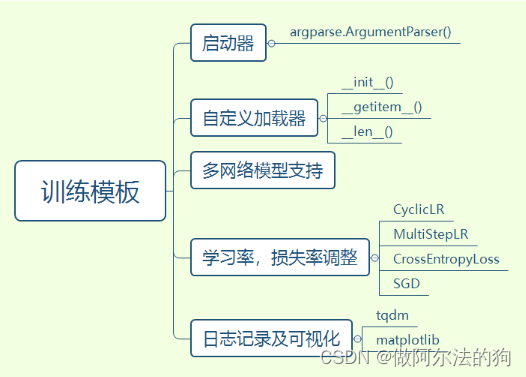
训练模型主要分为五个模块:启动器、自定义数据加载器、网络模型、学习率/损失率调整以及训练可视化。
启动器是项目的入口,通过对启动器参数的设置,可以进行很多灵活的启动方式,下图为部分启动器参数设置。

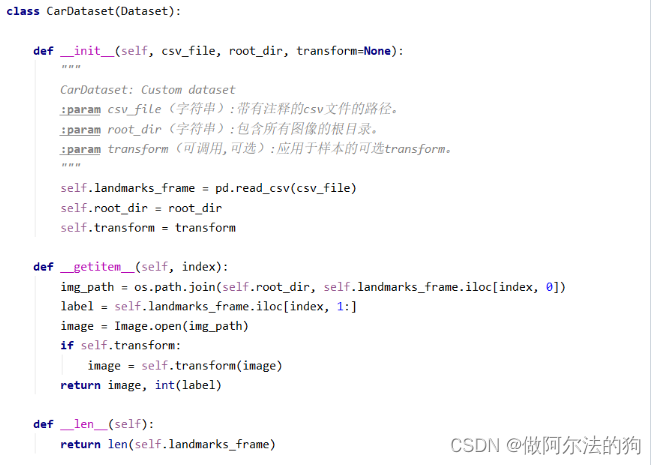
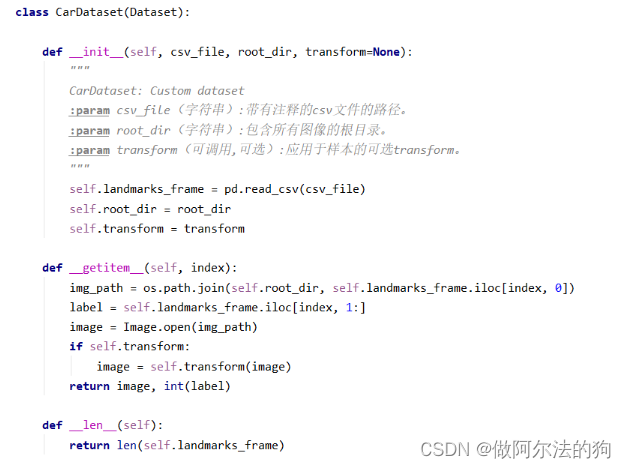
任何一个深度学习的模型训练都是离不开数据集的,根据多种多样的数据集,我们应该使用一个方式将数据集用一种通用的结构返回,方便网络模型的加载处理。
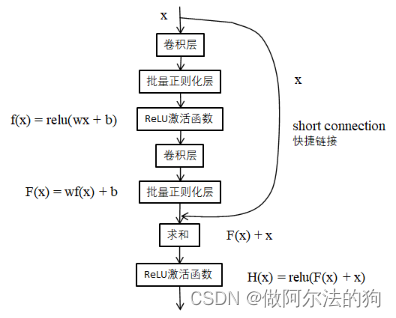
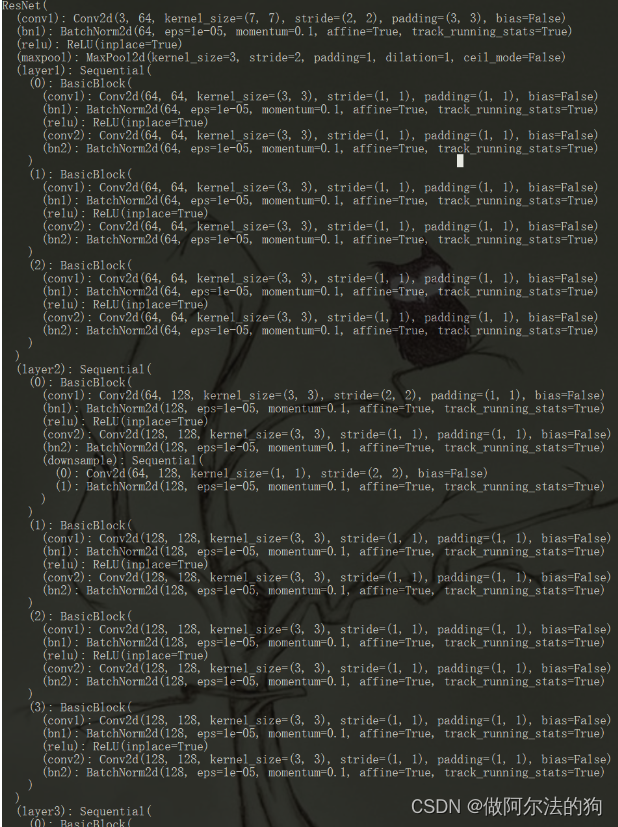
这里使用了残差网络Resnet-34,代码中还提供了Resnet-18、Resnet-50、Resnet-101以及Resnet-152。残差结构是通过一个快捷连接,极大的减少了参数数量,降低了内存使用。
以下为残差网络的基本结构和Resnet-34 部分网络结构图。
除了最开始看到的train-val图表、Top-、Top-5的error记录表以外,在训练过程中,使用进度条打印当前训练的进度、训练精度等信息。打印时机可以通过上边提到的 启动器 优雅地配置。


模型移植
import os
import torch
import torchvision
model_pth = os.path.join("results", "2020-04-27_10-27-17", 'checkpoint.pth.tar')
# 将resnet34模型保存为Android可以调用的文件
mobile_pt = os.path.join("results", "2020-04-27_10-27-17", 'resnet34.pt')
num_class = 13
device = 'cpu' # 'cuda:0' # cpu
model = torchvision.models.resnet34(num_classes=num_class)
model = torch.nn.DataParallel(model, [0])
model.to(device=device)
checkpoint = torch.load(model_pth, map_location=device)
model.load_state_dict(checkpoint['state_dict'])
model.eval() # 模型设为评估模式
# 1张3通道224*224的图片
input_tensor = torch.rand(1, 3, 224, 224) # 设定输入数据格式
traced_script_module = torch.jit.trace(model.module, input_tensor) # 模型转化
traced_script_module.save(mobile_pt) # 保存文件
启动模型训练
启动前需要确保你已经有了本项目使用的数据集 CompCars
重新开始新的训练
python start.py --data_root “./data” --gpus 0,1,2 -w 2 -b 120 --num_class 13
–data_root 数据集路径位置
–gups 使用gpu训练的块数
-w 为gpu加载自定义数据集的工作线程
-b 用来gpu训练的 batch size是多少
–num_class 分类类别数量
使用上次训练结果继续训练
python start.py --data_root “./data” --gpus 0,1,2 -w 2 -b 120 --num_class 13 --resume “results/2020-04-14_12-36-16”
–data_root 数据集路径位置
–gups 使用gpu训练的块数
-w 为gpu加载自定义数据集的工作线程
-b 用来gpu训练的 batch size是多少
–num_class 分类类别数量
–resume 上次训练结果文件夹,可继续上次的训练
模型移植
将训练好的模型转换为Android可以执行的模型
python transfor.py
项目定制化
找寻自己的数据集
需要修改启动脚本中 --num_class,模型类别
目前项目中具备很多备注记录,稍加review代码就可以理解,如有不清楚,可以私信询问。

昇腾万里,让智能无所不及
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)