

训练SD的Lora模型出现的问题以及解决方法
不管是用脚本还是丹炉什么的工具,训练过程中总是出现很多的问题,现目前对于跑通训练都是一件很费劲的事情,记录一下我在训练lora时候出现的问题。首先明确一下对于环境创建应该是没有问题的,青龙脚本创建显示了安装完毕的字眼/丹炉直接开启前自动安装好。首先大部分训练报错,然后最后说一个“returned non-zero exit status 1” Train finished,我最开始就以为是这个问题
前言
不管是用脚本还是丹炉什么的工具,训练过程中总是出现很多的问题,现目前对于跑通训练都是一件很费劲的事情,记录一下我在训练lora时候出现的问题。首先明确一下对于环境创建应该是没有问题的,青龙脚本创建显示了安装完毕的字眼/丹炉直接开启前自动安装好。

报错以及解决方法
1. 报错解决思路
首先大部分训练报错,然后最后说一个“returned non-zero exit status 1” Train finished,我最开始就以为是这个问题,到处问或者说搜这个报错怎么解决,但实际上这是只是一个报错说明,出现这个句子的报错情况很多很多,只是最后给你返回一个这个,具体的报错情况实际上是在上面找,尤其是红色标出来的才是真正的报错,这是很重要的一点,甚至说你报错想截图问大佬,你也得截图正确大佬才能给你回答不是,你截最后只包含这个句子很可能是找不到真正出错的地方的。
其次虽然有报错,但是代码跑起来了,是在实际训练的,那就不要管,人和代码总有一个能跑~
2. No model named ‘triton’
每次训练开始都会在开头出现的问题,“triton”这个不算问题,有没有这个模块暂时不重要,不会影响下面的训练。
3. CUDA out of memory

显存超了,自己电脑的显卡带不动,一是可以降低参数batch_size=1或者2,如果还是不行就只能使用云端部署,租别人的牛逼显卡(开始炼丹氪金)。
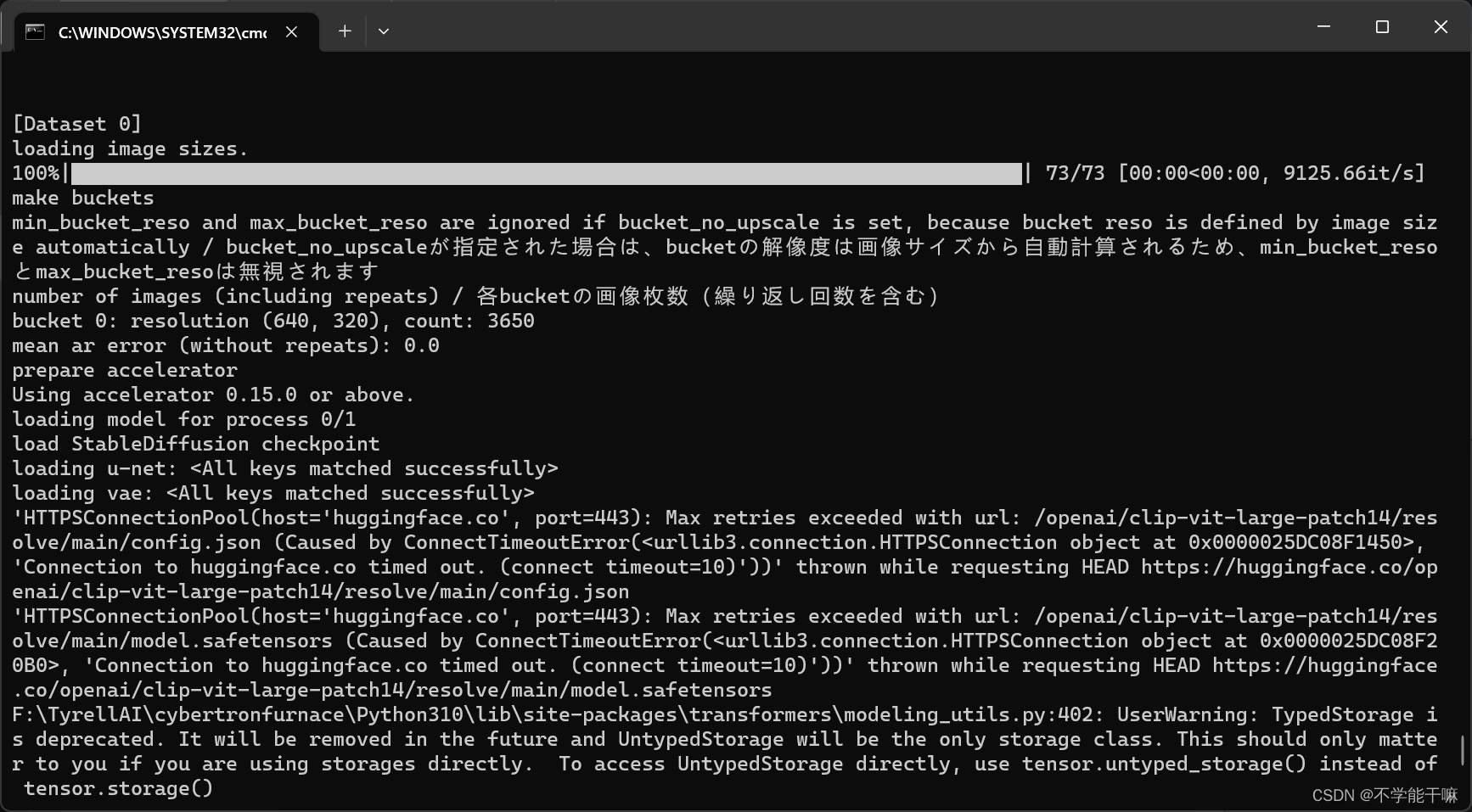
4. OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and itooks like openaiip-vit-large-patchl4 is not the path to a directorycontaining a file named config. json.
是网络问题,huggingface连接失败,没有科学上网或者要换一个稳定的节点梯子。
如果本身训练没有报这个错,训练过程尽量不要打开科学上网(或者说魔法上网)。
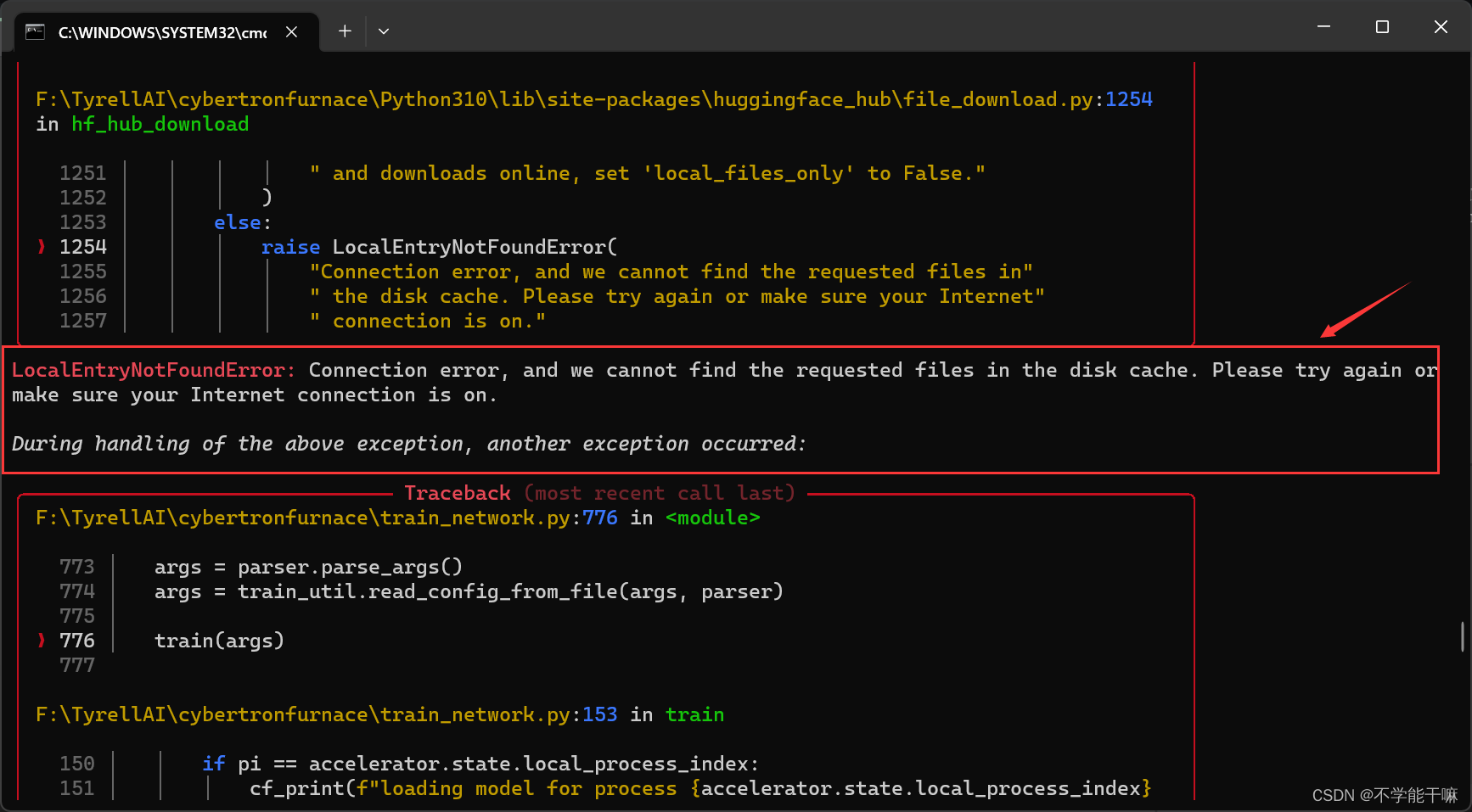

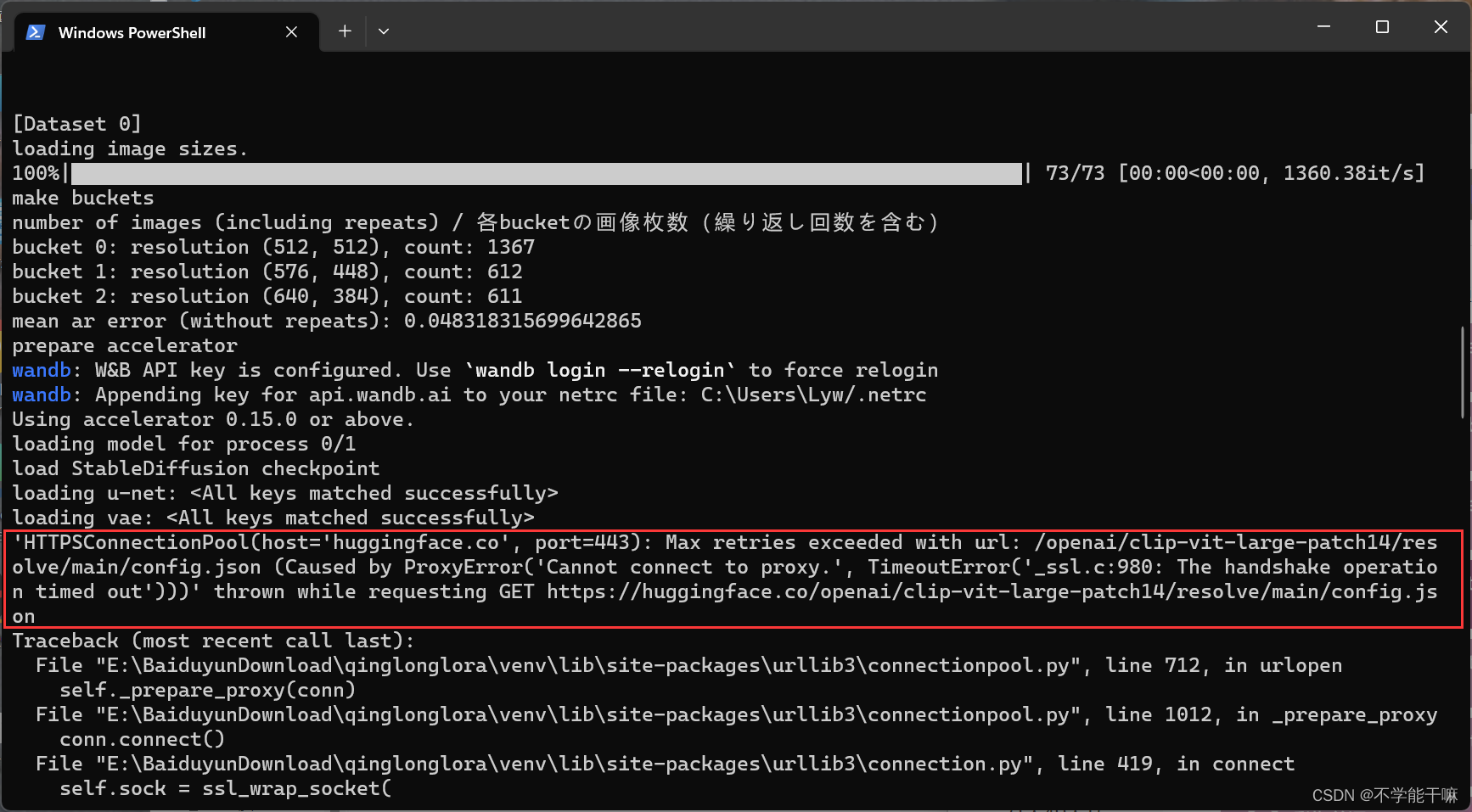
这里也有huggingface一大堆显示,但没有报错不导致train finished就不用管。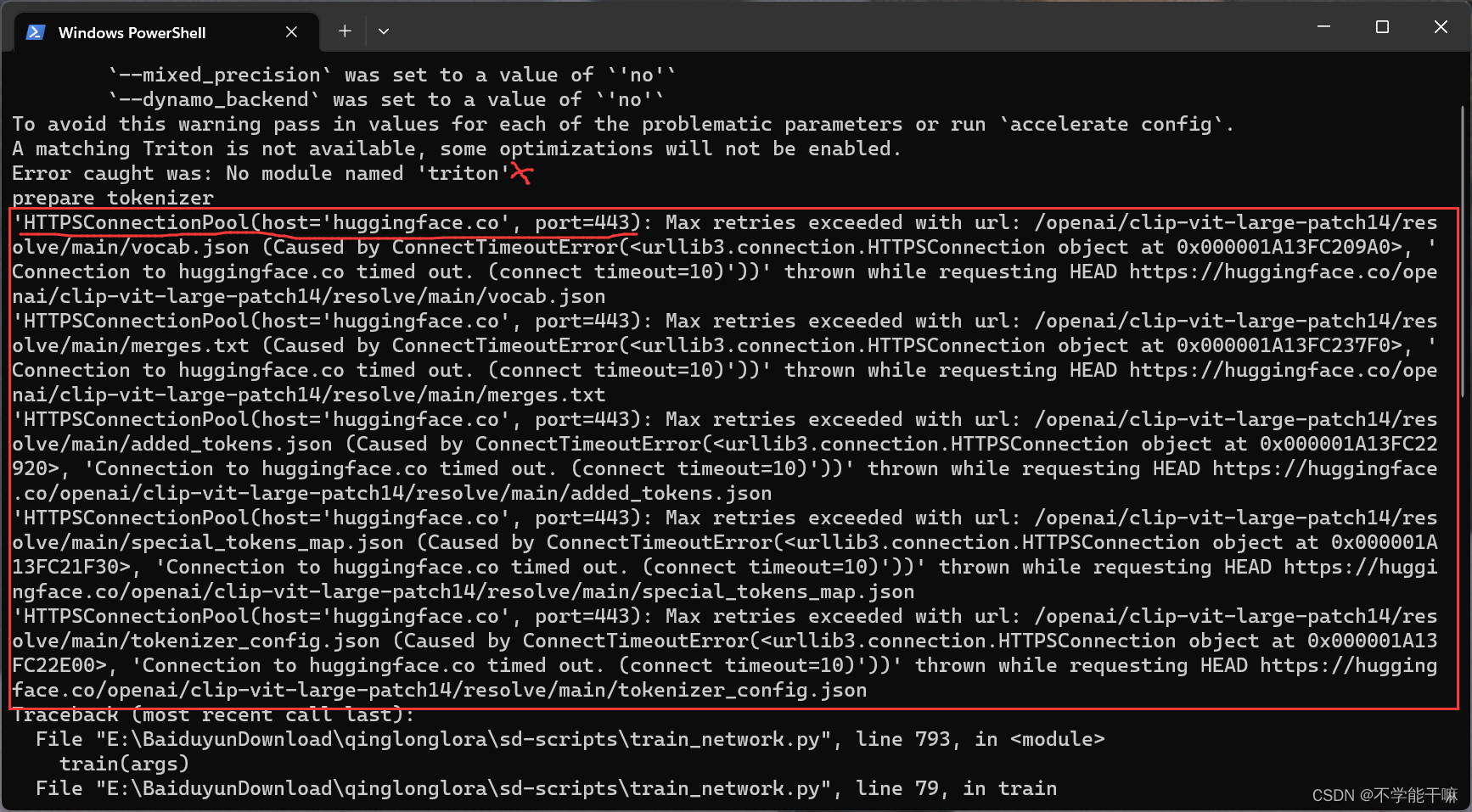
5. Loss=nan
训练过程中看loss变化,正常趋势是慢慢在往下降,然后过程中可能有数值起伏,降的程度会根据学习率走,但正常都是一点点一点点地降的,一下子降很多比如直接降到0.01就有问题。
但是训练着训练着loss=nan了,说明输入信息有问题,后面没训练了,因为即使在动但是相当于网络不思考了,不收敛了,没有必要训练了,只能去检查设置的参数是否有误,再重新训练。
![]() loss=nan的问题从以下方面去思考解决:调整数据集,删除一些图片,调整参数,换优化器,学习率等,而且一旦出现这类问题就可以ctrl+c中断训练了,要解决了再重启重新训练,而不是苦苦硬撑着,这是没用的。
loss=nan的问题从以下方面去思考解决:调整数据集,删除一些图片,调整参数,换优化器,学习率等,而且一旦出现这类问题就可以ctrl+c中断训练了,要解决了再重启重新训练,而不是苦苦硬撑着,这是没用的。
这里我是把正则化暂时关闭不训练,应该是正则化的问题,但同时也关闭了lycoris,因为训练的是lora不是它,之后重新训练,loss就正常了。
![]()

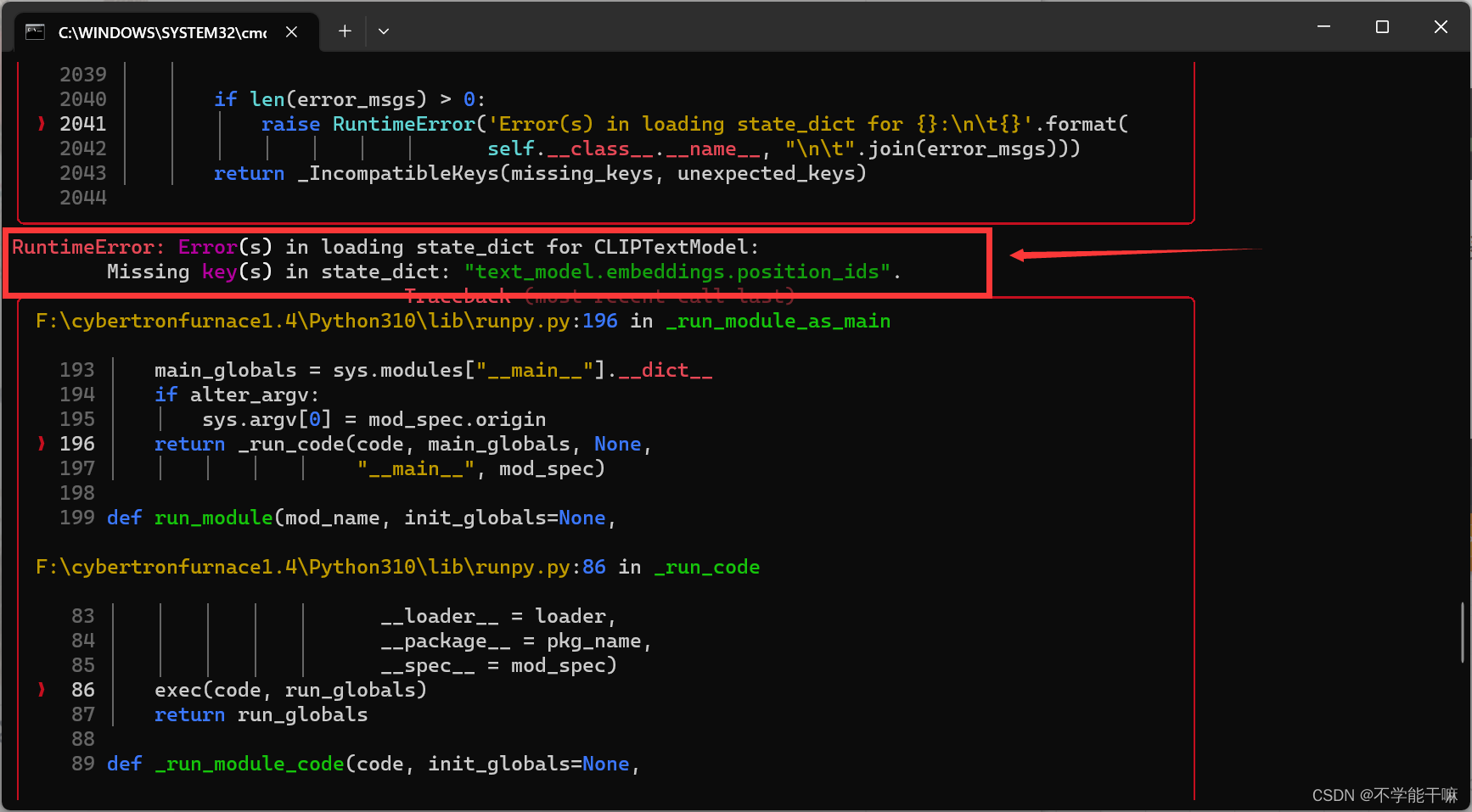
6. RuntimeError: Error(s) in loading state _dict for CLIPTextModel: Missing key(s) in state_dict:"text_model.embeddings .position ids"
chat告诉我是因为代码训练尝试加载CLIPTextModel的权重(state_dict),但是该权重中缺少了text_model.embeddings.position_ids这个键,或者说CLIPTextModel版本与您加载的权重版本不匹配导致的。
解决方法是我换了一个常用的底模,之前的底模训练就会有这个报错,我就换了一个anything的,就好了。

7. 训练正常,但是还是有WARNING报错,不用在乎~
先说明一下,青龙训练的lora结果是保存在output文件夹里,这个文件夹会在训练过程中自动创建。

感觉这里的4个报错都是同一个意思, “警告(用户提供的步长:2小于当前步长:2590。正在删除条目:{'loss/epoch':0.13706338185479,'_timestamp':1700138808.416837})”。
8. 最后wandb链接(要科学上网)打开也看不到内容,即使注册登录了打开也显示404(待解决)


9. 训练过程中不生成样图
训练参数-样图设置-训练每N轮生成样图设置为0,不然即使前面设置了训练每50步也不会出图。

训练成功的部分截图




旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)