
写文章




- @m0_59805198
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
训练Stable Diffusion(SD) Lora模型巨详细教程 赛博丹炉/青龙脚本/秋叶云端使用教程 主用赛博丹炉(道玄)巨小白巨啰嗦,全是干货和踩过的坑
试了很多的sd训练,尤其是sd的lora的训练,问题一大堆,现在写个博客汇总一下。

联想电脑的无线WIFI图标没了,代码56(已解决,新奇方法)
首先说明一下,我的拯救者突然有一天右下角那里点开WIFI图标没了,就是都没有选择WiFi的图标了,猜测或许是电脑自己更新更坏了,不知道。
训练Stable Diffusion(SD) Lora模型巨详细教程 赛博丹炉/青龙脚本/秋叶云端使用教程 主用赛博丹炉(道玄)巨小白巨啰嗦,全是干货和踩过的坑
试了很多的sd训练,尤其是sd的lora的训练,问题一大堆,现在写个博客汇总一下。
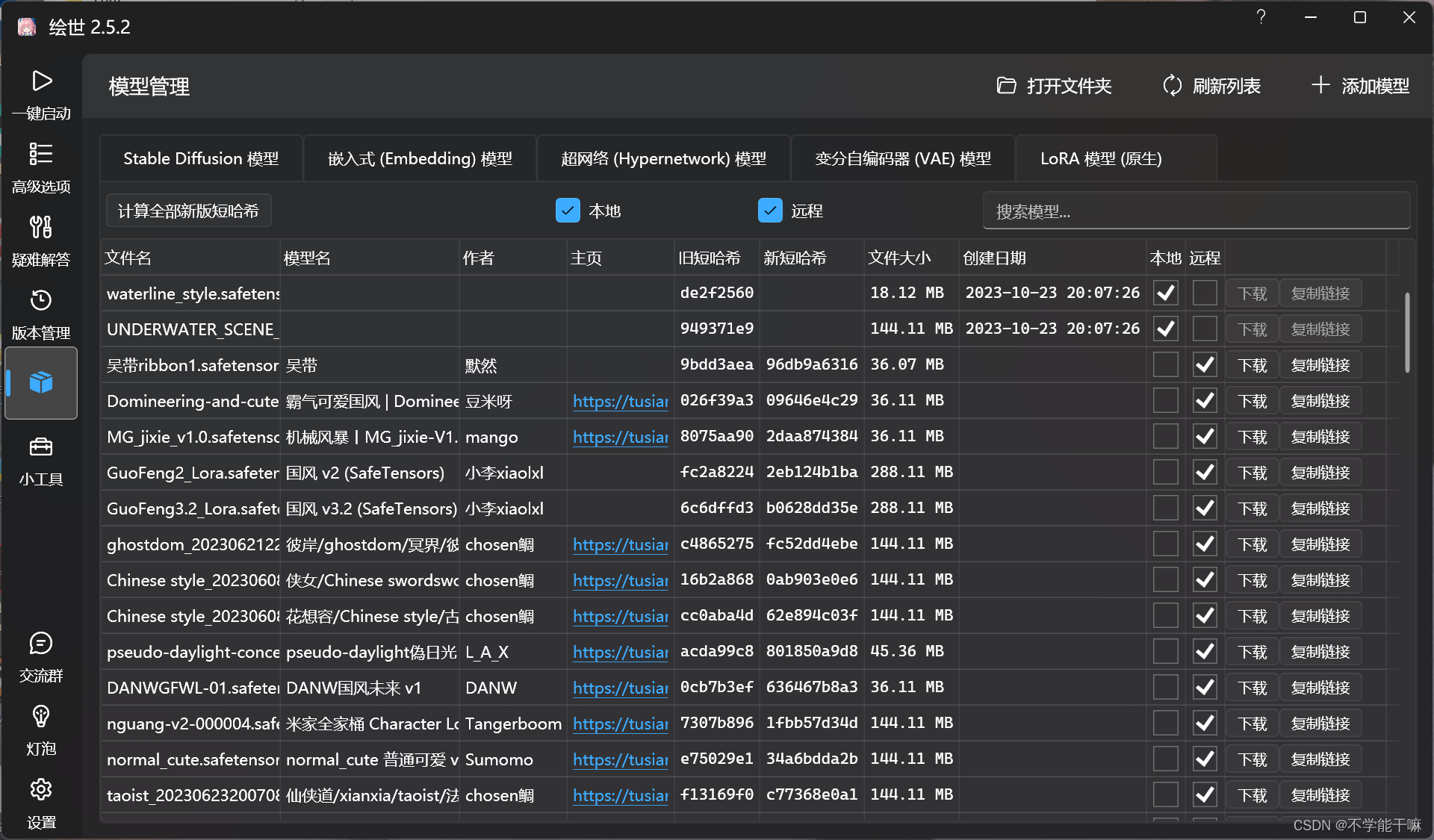
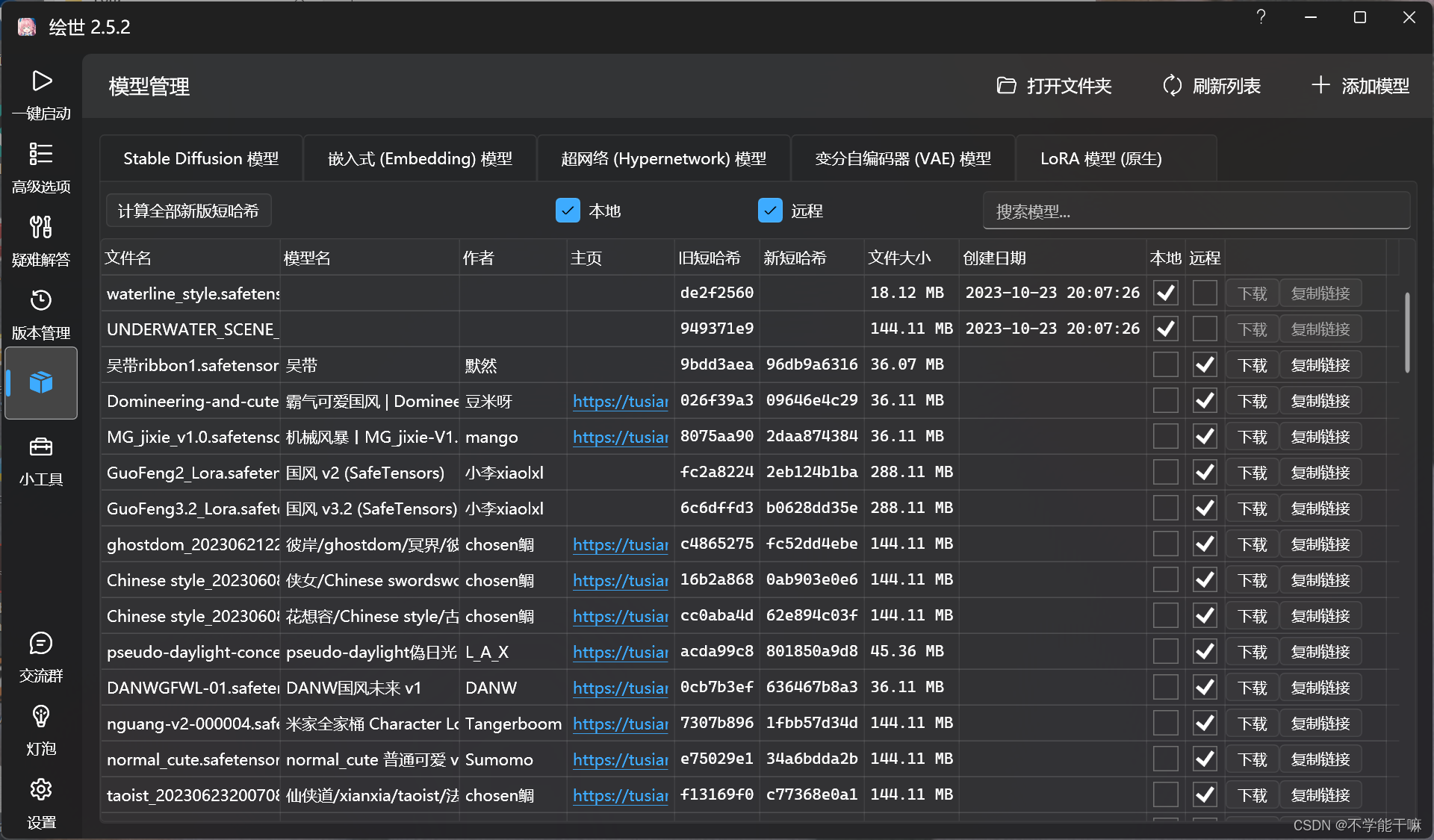
SD整合包,Lora模型下载了放models/Lora文件夹里,但是webui页面加载不出来(已解决)
5.之后有看到让把下载的模型放到放在...\extensions\sd-webui-additional-networks\models\lora里的,但是我看了一下我的整合包,没有这个路径和文件夹,感觉是整合包版本更新了的原因,然后我试啊试,终于找到了一个路径很类似这个主路径,就是D:\BaiduNetdiskDownload\sd-webui-aki-v4.4\extensions-built
SD整合包,Lora模型下载了放models/Lora文件夹里,但是webui页面加载不出来(已解决)
5.之后有看到让把下载的模型放到放在...\extensions\sd-webui-additional-networks\models\lora里的,但是我看了一下我的整合包,没有这个路径和文件夹,感觉是整合包版本更新了的原因,然后我试啊试,终于找到了一个路径很类似这个主路径,就是D:\BaiduNetdiskDownload\sd-webui-aki-v4.4\extensions-built
到底了