
多智能体路径规划综述(万字长文解读)--2022
多智能体路径规划(multi-agent path finding,MAPF)是为多个智能体规划路径的问题,关键约束是多个智能体同时沿着规划路径行进而不会发生冲突按照规划方式不同:MAPF算法分为集中式规划算法和分布式规划算法,集中式规划算法是最经典和最常用的MAPF算法,主要分为基于A*搜索、基于冲突搜索、基于代价增长树和基于规约四种算法;分布式执行算法分为专家演讲型,改进通信型和任务分解型三种
多智能体路径规划综述–2022
前言
多智能体路径规划(multi-agent path finding,MAPF)是为多个智能体规划路径的问题,关键约束是多个智能体同时沿着规划路径行进而不会发生冲突
按照规划方式不同:MAPF算法分为集中式规划算法和分布式规划算法,集中式规划算法是最经典和最常用的MAPF算法,主要分为基于A*搜索、基于冲突搜索、基于代价增长树和基于规约四种算法;分布式执行算法分为专家演讲型,改进通信型和任务分解型三种算法
一、引言
MAPF问题:对不同起始位置的多个智能体到他们各自目标位置的路径规划问题,关键约束是在保证智能体
之间互相不碰撞的前提下到达目标位置,并保证路径规划的速度和质量。
传统MAPF挑战:环境的动态变化和智能体的数量增加,基于搜索的MAPF算法通过引入优先规划、大领域搜索和复杂的启发式函数来优化改进算法的性能;而基于强化学习的MAPF算法在解决动态和变化环境的MAPF表现出巨大的潜力。
1. 集中式规划
集中式规划方法由一个中央控制器来为所有智能体规划路径,它的前提假设是中央规划器掌握了所有智能体的起始位置、目标位置和障碍物位置等信息。集中式规划算法是最经典和常用的MAPF 算法,在求解的速度和质量上都达到较好的效果。
2. 分布式执行算法
分布式执行算法主要是基于强化学习的算法,前提假设是每个智能体只掌握了视野内(一定范围内)智能体和障碍物的位置等信息,智能体根据当前策略不断和环境进行交互,获取环境下一到达状态和该动作奖励,计算并更新策略,目标是最大化累积奖励,最后找到一个最大化累积奖励的动作序列,完成多智能体路径规划任务。这类算法可以扩展到高密度和动态的部分可观察的环境中,高效解决现实世界中的多智能体路径实时再规划问题。
3. 当前研究
MAPF 的研究主要有两大方向,一是如何改进现有的算法,二是在实际应用中如何处理约束。在实际应用场景中要考虑机器的速度、加速度、转角,以及各种干扰的约束,而多智能体路径规划将这些设定进行抽象化,将运动控制离散为时间步,将研究的重点集中在求解速度和质量上。
二、经典多智能体路径规划问题
1.经典MAPF问题描述
k个智能体的经典MAPF问题定义为一个元组
(
G
,
s
,
t
)
(G,s,t)
(G,s,t),其中
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)是一个无向图,无向图中的节点
v
∈
V
v\in V
v∈V是智能体可以占据的位置,边
(
n
,
n
′
)
∈
E
(n,n')\in E
(n,n′)∈E表示智能体从节点n移动到n‘的连线,k代表智能体的数量
a
1
,
a
2
,
a
3
.
.
.
.
.
.
a
k
{a_1,a_2,a_3......a_k}
a1,a2,a3......ak,s是初始位置的集合,每个智能体都有一个初始位置
s
i
∈
s
s_i\in s
si∈s,t是目标位置的集合,每个智能体都有一个目标位置
t
i
∈
t
t_i\in t
ti∈t
在经典MAPF 问题中,时间被离散为时间步长。在每个时间步长中,每个智能体可以执行一个动作,一般有五种类型的动作:向上、向下、向左、向右和等待。
一个单智能体的路径规划是从起始位置到目标位置一系列动作的集合
π
=
(
a
1
,
a
2
,
a
3
,
.
.
.
.
,
a
n
)
\pi =(a_1,a_2,a_3,....,a_n)
π=(a1,a2,a3,....,an),k 个智能体的路径规划问题就是 k 条路径的集合
Π
=
(
π
1
,
π
2
,
.
.
.
,
π
k
)
\Pi =(\pi_1,\pi_2,...,\pi_k)
Π=(π1,π2,...,πk) 其中第i 个智能体对应路径
π
i
\pi_i
πi
2.冲突类型
MAPF的首要目标就是找到所有agent的路径规划以及每个agent之间不产生冲突,常见的冲突类型如下:

这里以(a)为例,智能体1与智能体2,在同一时间步内同时穿过一条边,也就是
π
1
(
x
)
=
π
2
(
x
)
\pi_1(x)=\pi_2(x)
π1(x)=π2(x),
π
1
(
x
+
1
)
=
π
2
(
x
+
1
)
\pi_1(x+1)=\pi_2(x+1)
π1(x+1)=π2(x+1),其他类型的冲突不再赘述。
3.目标函数
用来评估MAPF解决方案最常见的三个目标函数是:
m
a
x
1
≤
i
≤
k
t
(
π
i
)
\mathop{max}\limits_{1\leq i\leq k}t(\pi_i)
1≤i≤kmaxt(πi)…(1)
∑
1
≤
i
≤
k
t
(
π
i
)
\sum\limits_{1\leq i\leq k}t(\pi_i)
1≤i≤k∑t(πi)…(2)
∑
1
≤
i
≤
k
l
(
π
i
)
\sum\limits_{1\leq i\leq k}l(\pi_i)
1≤i≤k∑l(πi)…(3)
目标函数(1)表示最晚到达目标位置的智能体所花费的时间,目标函数(2)表示所有agents到达目标位置花费的总时间,目标函数(3)表示所有智能体到达目标位置的路径长度总和。
三、集中式规划算法
MAPF 集中式规划算法的前提假设是中央规划器掌握了全局信息,即所有智能体的起始位置、目标位置和障碍物位置信息等
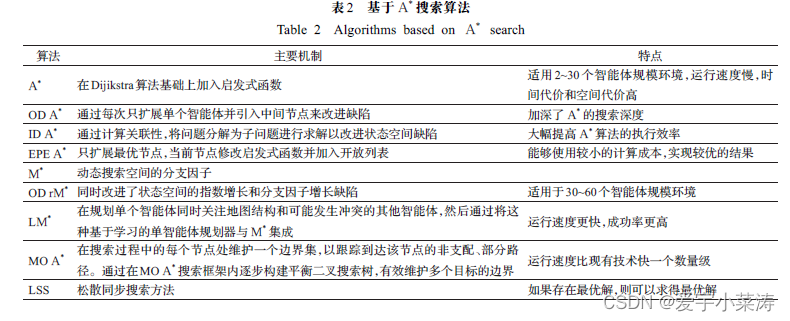
1.基于A*的搜索算法
A* 在小规模智能体环境中是最佳搜索算法。它维护两个顶点列表:开放列表和关闭列表。最初将开始节点放入开放列表中,在每次迭代中,在开放列表中搜索相邻节点,并把起始节点放入关闭列表中。对于每个新生成的开放列表中的节点,A* 算法计算以下几个值:
(1)g(n)从源节点到n节点的最短路径代价
(2)parent(n)是该节点的父节点
(3)h(n)从n节点到目标节点的启发式路径代价估计值
如果h*(n)是节点n到目标节点的完美启发式函数,如果知道每个节点的h*(n),即可以选择出从源节点到目标节点的最短路径,A*算法选择open-list中g(n)+h(n)最小的节点计算其周围的节点,并将此节点放入close-list中,依次迭代下去直至找到目标节点。
1.1.A* 算法应用到多智能体
A* 搜索在MAPF 中的状态一般被称为k - agent 状态空间,其状态数等于将v 个智能体分别放置在v 个不同节点状态数,一种放置方法对应于一种状态。简单的方法将A* 搜索启发式函数应用到MAPF 中,是全局启发式函数等于所有智能体各自启发式函数之和。在k-agent的搜索空间内,最大的搜索空间为 ∣ v ∣ k |v|^k ∣v∣k,分支因子(每个节点产生子节点的数量,假定为n联通问题)为 ∣ n ∣ k |n|^k ∣n∣k,因为A* 必须沿着最优路径扩展所有的节点,因此A* 算法在解决大规模智能体的MAPF 问题时效率和质量都不高。
1.2.A* 算法拓展
对A*提出两个有效的拓展:因子分解与独立检测
因子分解(operator decomposition,OD):OD设计用于改进k - agent 搜索空间的分支因子指数增长的缺陷。具体做法如下:将智能体按任意顺序排序,得到原顶点
(
s
(
1
)
,
s
(
2
)
,
.
.
.
,
s
(
k
)
)
(s(1),s(2),...,s(k))
(s(1),s(2),...,s(k)),此时只考虑第一个智能体的行为,会生成一组顶点,表示第一个智能体在时间步1的可能位置,还包括其他智能体在时间步0的位置,这些节点全添加至open-list中,此时在展开第二个节点,只考虑第二个智能体的动作,会生成第二组节点,表示第二个智能体在时间步1的位置,以及第一个agent在时间步1的位置和其他智能体在时间步0的位置,依次迭代下去,在第k层状态节点时表达了所有智能体在时间步1的所有可能位置,能够表达同时一时间步长所有agent的位置节点称为full节点,继续搜索,直至到达表示目
(
t
(
1
)
,
t
(
2
)
,
.
.
.
,
t
(
k
)
)
(t(1),t(2),...,t(k))
(t(1),t(2),...,t(k))的full节点。
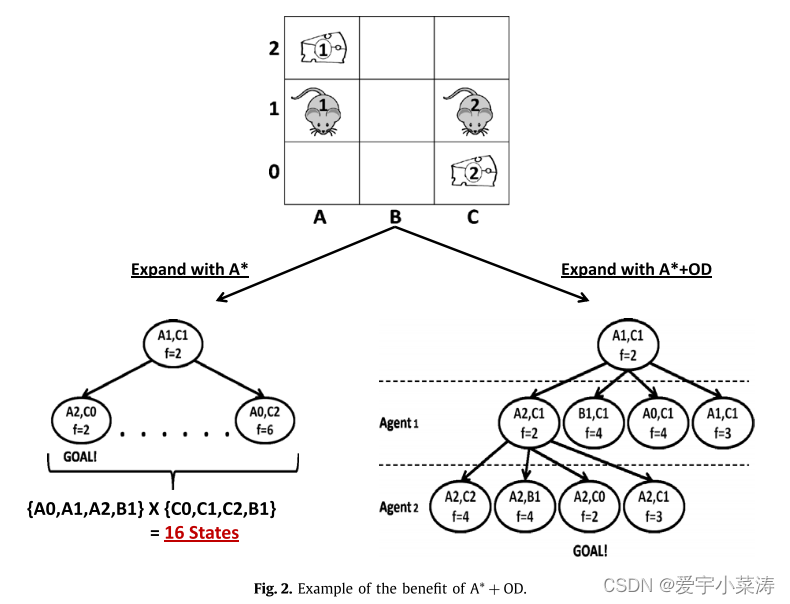
优点:有OD的A* 与无OD的A* 相比,其明显优势在于分支因子。OD大幅缩减了A* 搜索的分支因子,OD A* 引入了大量的中间状态节点,使得A* 搜索的深度加深了k 倍。在MAPF 中,由于加入启发式函数对中间状态节点进行剪枝,因此OD的引入是有益的。

独立检测(independence detection,ID):D 试图将带有k -agent 的MAPF 问题分解为含有更少智能体的更小的MAPF 问题。其工作原理如下::首先,每个智能体为自己找到一个最优路径方案,同时忽略所有其他智能体,然后开始独立检测,如果一对智能体的计划之间存在冲突,这些智能体就合并为一个单一的元智能体。然后,用A* +OD求出其中两个智能体的最优解,忽略其他所有智能体。这个过程以迭代的方式继续,在每次迭代中检测到单个冲突,合并冲突(元)智能体,然后用A* +OD进行最优解决。当智能体的计划之间没有冲突时,进程停止。
优点:在最坏的情况下,ID 最终会将所有智能体合并到一个元智能体,并解决生成智能体的MAPF 问题。ID 是一个非常通用的框架的MAPF 求解器,ID 能够提高多数MAPF 问题求解的效率。
M算法:与A相似搜索k-agent搜索空间,为改进分支因子,M*动态的改变搜索空间的分支因子。具体做法:起初,每当扩展一个节点时,只生成一个节点,该节点对于所有单个智能体的最佳路径,因此对于k个智能体生成k条最佳路径,但每个智能体沿着各自路径移动,可能会生成一个节点表示一对智能体i与j之间的冲突,将i与j加入冲突集合中,重新展开搜索,对于不在冲突集的agent,只考虑单个智能体其最优路径上的动作。
2.基于冲突的搜索算法
基于冲突搜索算法是目前最常用的算法,目前求解MAPF 速度和质量最好的算法大都是在基于冲突搜索算法上进行改进和优化。
2.1.CBS原理
CBS术语:
path:单个agent的路径
solution:所有agent的path的集合,也就是MAPF的全局规划局结果
conflict:在上述的solution中,n条path之间可能会有冲突,描述形式为 ( a i , a j , v , t ) (a_i,a_j,v,t) (ai,aj,v,t),表示在时刻t, a i a_i ai与 a j a_j aj同时占据顶点v
constraints:一个约束 ( a i , v , t ) (a_i,v,t) (ai,v,t)表示在时刻t, a i a_i ai不能占据顶点v
主要思想:高层搜索和低层搜索,构建一棵二叉搜索树查找解。在根节点为所有智能体单独规划路径,然后通过添加限制的方式消解冲突,每个节点规划路径考虑节点被添加的限制并忽略其他智能体。底层执行带有约束的单机规划,例如用传统 A* 算法,顶层遍历底层的规划路径,检查路径之间是否有冲突,如果有冲突则施加约束重新进行底层单机规划,直到所有底层路径无冲突为止
具体的工作原理:
顶层:使用约束树结构解决底层冲突,包括约束(根据冲突得到)、当前的计算的全局路径、全局代价cost
生成树:从父节点到子节点,根据当前的约束进行拆分为两个子约束,根据当前的约束计算得出全局路径,根据计算得到的solution计算出全局cost,找到整个约束树最小的cost,判断子节点是否还用冲突,如果有则继续迭代,直至没有为止
底层:单机搜索,采用经典的A*算法
优缺点:它的特点在于求解速度快,相比其他方法能够求解更大规模的问题,缺点是实现难度较高。原有的用A* 整体规划求解MAPF 问题需要在扩展同时考虑各个智能体之间的冲突,生成大量无意义的节点,影响搜索的效率。CBS 通过添加限制解决冲突,求解速度更快。
2.2.基于CBS的改进算法

3.代价增长树搜索算法
代价增长树搜索(increasing cost tree search,ICTS)算法将MAPF 问题分解为两个问题:找到每个智能体的代价和找到这些代价的有效解决问题方案
3.1.基于ICTS搜索算法
ICTS并不直接搜索k-agent搜索空间,将两个搜索过程结合到一起:高层搜索与底层搜索
高层搜索:找出每个智能体的最优路径的cost,底层搜索:对高层搜索的节点状态进行验证是否存在一组最优解。具体的算法过程如下图

举例说明:对于下图中的例子使用ICTS算法进行求解

进行高层搜索,建立每个agent对应的最优路径
按照宽度优先的原则选择node建立深度优先的MMD(在此说明MMD中存放着同一花销的所有路径可能情况,
M
M
D
i
t
MMD_i^t
MMDit表达智能体i,cost为c的所有路径的集合)

对于一对agent进行MMD叉乘,消去具有冲突的路径

底层搜索:检测是否存在最佳路径
下图展示出k=2的任务图,更加便于理解


3.2.基于ICTS搜索算法的改进算法

4.基于规约的算法
规约方法是从理论到实践的各种计算机领域中使用的最突出的技术之一。MAPF 问题是NP-hard 的问题,可以将MAPF 问题规约为其他已解决的标准问题,如布尔可满足性(satisfaction fiability,SAT)、约束满足问题(constraint satisfaction problems,CSP)、约束优化问题(constraint optimization problems,COP)、答案集编程(answer set programming,ASP)。许多MAPF问题可建模为CSP 或者COP。
优势:使用规约算法的主要好处是当前通用的规约求解器非常高效,并且变得越来越好。特别是现在的SAT求解器非常高效,能处理上万个变量。
5.其他集中式规划算法
其他集中式规划算法主要是两种或者两种以上算法的相融合算法。特别是将基于搜索的算法和机器学习相结合,使算法在性能上有很大提升,相关工作总结于表5

四、分布式执行算法
近年来,经典的MAPF 算法已经能够解决大部分路径规划问题。然而这些问题的前提假设都是中央规划器掌握完整的地图信息和所有智能体的位置等信息,并且集中式方法需要收集地图信息和所有智能体的信息以规划最优路径,导致消耗大量的计算资源。随着技术的发展,去中心化的方法越来越流行,智能体在与环境交互过程中,通过和一定距离范围内的其他智能体通信来规划路径,泛化性较好,可以扩展到大规模智能体的环境。
1.单智能体强化学习算法对比

2.多智能体强化学习算法对比

3.基于深度强化学习的多智能体路径规划
使用RL 方法解决MAPF 问题面临的许多挑战,例如环境奖励稀疏、环境动态复杂等。任何一种强化学习算法直接应用于MAPF 问题都会出现学习速度慢和学习质量不高的问题。针对以上问题,研究人员采用了各种组合技术对基于强化学习的MAPF 方法进行改进,使得强化学习的MAPF 方法能够扩展到上千个智能体的环境,并且求解的质量和效率得到大大的提高。按照改进技术的特点,大致将基于RL 的MAPF 方法分为专家演示型、改进通信性和任务分解型三类,不同类型算法的优缺点总结于表8。

3.1.专家演示型
专家演示型方法主要采用强化学习和模仿学习(imitation learning,IL)和相结合的方法,这部分工作总结于表9。

PRIMAL(pathfinding via reinforcement and imitation multi-agent learning),一种新的MAPF 框架,它的算法原理如图4 所示。

工作流程:在每一回合开始,随机选择是基于RL 或者基于IL 进行学习,在基于RL 学习中,在每个时间步长,每个智能体从环境中获取其观察值和奖励值并输入到神经网络,神经网络输出一个动作。不同智能体的动作按照随机顺序依次执行。基于IL 的方法中,由经典的MAPF 规划器作为专家经验,对所有智能体动作进行协调规划。它结合了RL 和IL 去学习完全去中心化的策略。
在这个框架中,智能体处于部分可观察环境当中,只能观察到有限视野内的信息,智能体学习考虑其他智能体的位置对自己的影响,从而有利于整个集体而不仅仅是自己的最优路径。通过同时学习单个智能体路径(基于RL)和模仿集中式专家经验(IL),智能体最终学习到一个去中心化的策略,同时包含了智能体之间的协调合作。
3.2.改进通信型
在高密度智能体的MAPF中,系统需要多个智能体在环境完全不可知的情况下相互关联,因此需要智能体之间进行通信。
相关工作总结于表10。

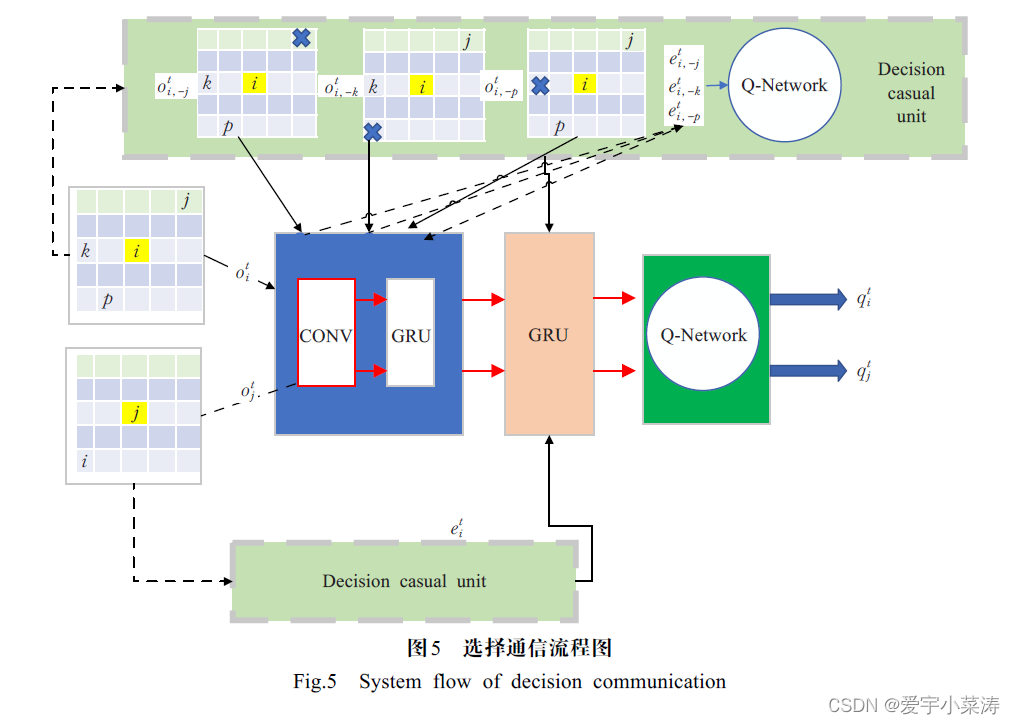
在大规模智能体的MAPF中,为了加强协调与合作,智能体之间会进行通信,多智能体强化学习往往采用广播通信的方式,信息被传播到一定范围内的其他所有智能体,虽然相对于非通信的方式具有较大的改进,但需要大量的宽带,并在实践中引起额外的系统开销和延迟。
请求应答机制(DCC),其训练过程如图5所示,选择通信流程共分四个模块:第一模块是局部观察输入,智能体在每个时间步获得6x6的方格形状作为输入;第二个模块是观察编码,将智能体的局部观察输入通过卷积神经网络GRU进行编码;第三个模块是选择判断单元,观察编码修改局部观察后输入到Q网络中,比较去掉该智能体和有该智能体的Q值变化来判断邻居智能体的信息是否对自己有用;第四个单元是通信模块,智能体选择通信后,将信息进行聚合,随后输入Q网络得到下一步的动作。
3.3.任务分解型
大型动态环境的MAPF是具有挑战性的,每个智能体不仅需要有效到达目标,同时避免与其他智能体或对象冲突,因此将任务进行分解是一种重要的方法,相关工作总结于表11

混合策略方法(HPL):将MAPF问题分解为两个子任务:到达目标和避免冲突。训练框架流程图如下图所示。

为了完成每一项任务,利用RL 的方法,如深度蒙特卡洛树搜索、Q混合网络和策略梯度方法,来设计智能体观察值到动作的映射,最后将学习到达目标策略和避免碰撞策略混合为一个策略。接下来,引入策略混合机制,最终得到一个单一的混合策略,该策略允许每个智能体表现出两类行为-个人行为(到达目标)和合作行为(避免与其他智能体发生冲突)
3.4.其他基于RL的MAPF算法
主要的算法有:(1)针对MAPF环境的特点,在MADRL基础上进行改进的MAPF算法;(2)将基于RL的MAPF 算法和传统算法或者其他领域先进技术相结合的算法;(3)针对MAPF 应用在机场调度、自动仓库和无人机等实际应用场景,如何处理实际约束而提出的解决方案。
五、基于RL的MAPF算法的挑战
(1)奖励稀疏问题:多智能体路径规划过程通常是目标驱动的,环境给予的奖励通常在智能体到达目标终点。在环境尺寸较大的环境中,智能体很难获得最终的奖励信号。此外,为了促进智能体快速到达目标,给予每个时间步负奖励,但这也导致智能体在长期负奖励信号下产生异常的动作,例如智能体在原地保持不动。稀疏的奖励问题还会导致学习效率低下和收敛速度慢。解决奖励稀疏问题的主要方法有好奇心驱动、奖励塑形和分层强化学习等。
好奇心驱动主要思想是构建内在好奇心模块,以从环境中提取额外的内在奖励信号,鼓励智能体进行更有效的探索。
奖励塑造的主要思想是手动调整和修改智能体在不同状态下的奖励信号。奖励塑造更为直观,但是高度依赖于专家经验。
分层强化学习的主要思想是将任务分解为多个离散或连续且易于解决的子任务,然后分而治之。
(2)样本效率低:RL 智能体每次面对新的任务,都要从头开始学习。在训练初期,过多的无用数据导致智能体低效的学习和更新策略。因此,如何更好地探索有价值的策略和提高有价值的经验采样效率是研究的热点方向,也是提高基于RL MAPF 算法性能的关键。
(3)环境动态复杂:多智能体路径规划任务需要多个智能体同时参与,且智能体之间需要相互配合并且决策的结果会相互影响。在多智能体系统中,各个智能体需要在环境不完全可知的情况下互相关联完成任务。在MAPF 场景中的环境是复杂的、动态的。这些特性给学习过程带来很大的困难,例如,随着智能体数量的增长,联合状态及动作空间的规模呈现出指数增长;多个智能体同时学习,每个智能体策略改变都会影响其他智能体策略改变。针对上述困难,可以在动态环境中借助一些辅助信息弥补其不可见信息,从而提高学习的效率。为了达到这个目的,研究者们提出一些方法,例如,智能体之间的通信,即智能体通过发送和接受抽象的通信信息来分析环境中其他智能体的情况从而协调各自的策略。
六、总结与展望
虽然经典的集中式规划算法是目前最常用的也是效率最高的算法。基于多智能体深度强化学习的分布式执行算法在实时解决路径重新规划问题上展示了较大的潜力,缺点是训练时间较长。用集中式规划算法作为专家知识来加速强化学习的训练的方法在多智能体路径规划问题上收到较好效果。
未来的研究方向归纳为以下3 个方面:
(1)为所有智能体在任意环境中规划最优路径是NP-hard 问题,因此使用实时的MAPF 算法并不保证所有的智能体都成功规划路径。可以通过实验来确定在一组具有代表性的MAPF 实例中最好的MAPF 算法,但在什么时候使用哪个MAPF 算法可以做得更好,在解决一些实际环境中必须快速做出决定,可以使用机器学习中的分类算法来定义一个快速计算映射,从MAPF 实例的特征到性能最好的MAPF 算法,以提高完成率,而不是使用单一算法解决每个问题。
(2)对于一个实际的MAPF 问题,没有那种算法最有效。基于A* 和规约算法对于智能体密度小的环境最有效,CBS 和ICTS 算法对大型地图环境最有效,基于强化学习的分布式执行算法对部分可观察的环境最有效。未来工作的一个具有吸引力的方向是创建混合算法,以促进不同MAPF 求解器的优势互补。
(3)现在MAPF 问题假设智能体的动作是离散的,只有前后左右和等待五个动作,且没有考虑智能体运动的速度以及智能体体力消耗的因素,而真实世界的MAPF 问题的智能体大多都是连续动作的,且智能体运动速度是连续变化,如何将离散动作升级到连续动作和节省智能体运动体力是未来工作的一个研究方向。
七、引用
刘志飞, 舄曹, 蔦赖, 等. 多智能体路径规划综述[J]. Journal of Computer Engineering & Applications, 2022, 58(20).

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)