K8S架构原理【详解】
对K8S简单的理解提示:以下是本篇文章正文内容,下面案例可供参考Kubernetes 是一个可移植、可扩展的、开源的容器管理平台,简称 Kubernetes。什么是可移植?可移植:在 kubernetes 中部署的应用都是基于镜像的,镜像是可移植的,可以被多个环境使用,可以从一个环境迁移到另一个环境。什么是可扩展?可扩展:安装 Kubernetes的节点可以根据业务规模动态扩缩容、Kubernet
文章目录
前言
对K8S简单的理解
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是K8S?
Kubernetes 是一个可移植、可扩展的、开源的容器管理平台,简称 Kubernetes。
什么是可移植?
可移植:在 kubernetes 中部署的应用都是基于镜像的,镜像是可移植的,可以被多个环境使用,可以从一个环境迁移到另一个环境。
什么是可扩展?
可扩展:安装 Kubernetes的节点可以根据业务规模动态扩缩容、Kubernetes中的 pod 应用也可以实现自动扩缩容。
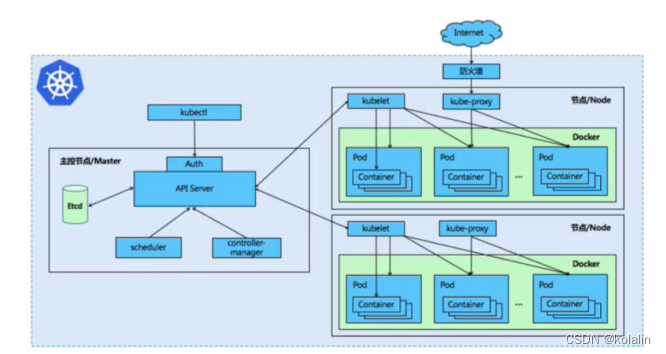
二、K8S的组成以及架构

1.K8S核心组件
K8S的组成:主要包括Master主节点和Node节点
Matser主节点主要包括:
etcd:是一个管理配置信息和服务发现(service discovery)的项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。
apiserver: 提供 Kubernetesapi,是整个系统的对外接口,提供资源操作的唯一入口,供客户端和其它组件调用,提供了 Kubernetes各类资源对象。(pod,deployment,service 等)的增删改查,是整个系统的数据总线和数据中心,并提供认证、授权、访问控制、API 注册和发现等机制,并将操作对象持久化到 etcd中,相当于“营业厅”。
scheduler:负责 Kubernetes集群中 pod 的调度的 ,scheduler 通过与apiserver 交互监听到创建 Pod副本的信息后,它会检索所有符合该 Pod 要求的工作节点列表,开始执行 Pod 调度逻辑。调度成功后将Pod 绑定到目标节点上,相当于“调度室”。
controller-manager:与 apiserver 交互,实时监控和维护 Kubernetes集群的控制器的健康情况,对有故障的进行处理和恢复,相当于“大总管”。
Node 节点实现相对简单一点,主要是由 kubelet 和 kube-proxy 两部分组成
kubelet: 每个 Node 节点上的 kubelet 定期就会调用 API Server 的 REST 接口报告自身状态,API Server 接收这些信息后,将节点状态信息更新到 etcd 中。kubelet 也通过 API Server 监听 Pod信息,从而对 Node 机器上的 POD 进行管理:如创建、删除、更新 Pod。
kube-proxy:提供网络代理和负载均衡,是实现 service 的通信与负载均衡机制的重要组件,kube-proxy 负责为 Pod 创建代理服务,从 apiserver 获取所有 service 信息,并根据 service 信息创建代理服务,实现 service 到 Pod 的请求路由和转发,从而实现 Kubernetes层级的虚拟转发网络,将到service 的请求转发到后端的 pod 上。
Container runtime负责镜像管理以及Pod和容器的真正运行(CRI)。
2.其他组件
1)kube-dns 负责为整个集群提供 DNS 服务
2)Ingress Controller 为服务提供外网入口
3)Heapster 提供资源监控
4)Dashboard 提供 GUIFederation 提供跨可用区的集群
5)Fluentd-elasticsearch 提供集群日志采集、存储与查询
三、K8S的资源对象
1.最小调度单元 Pod
Pod 是 Kubernetes 中的最小调度单元,当指派容器时,容器实际上并不会指派到物理硬件上,容器会被分配到一个 Pod 里,一个 Pod 封装一个容器(也可以封装多个容器),Pod 里的容器共享存储、网络等资源。也就是说,应该把整个 pod 看作虚拟机,然后每个容器相当于运行在虚拟机上的进程。所有容器都被统一安排和调度,并运行在共享的上下文中。对于具体应用而言,Pod 是它们的逻辑主机,Pod 包含业务相关的多个应用容器
形象解释:
可以把 pod 看成是一个“豌豆荚”,里面有很多“豆子”(容器)。一个豌豆荚里的豆子,它们吸收着共同的营养成分、肥料、水分等,Pod 和容器的关系也是一样,Pod 里面的容器共享 pod 的空间、资源、网络、存储等
2.资源对象标签 label
label 是标签的意思,Kubernetes中的资源对象大都可以打上标签,如 Node、Pod、Service 等,一个资源可以绑定任意多个 label,Kubernetes通过 Label 可实现多维度的资源分组管理,后续可通过 Label Selector 查询和筛选拥有某些 Label 的资源对象,例如创建一个 Pod,给定一个 Label 是app=tomcat,那么 service 可以通过 label selector 选择拥有 app=tomcat 的 pod,和其相关联,也可通过 app=tomcat 删除拥有该标签的 Pod 资源。
3.Service
在 kubernetes 中,Pod 是有生命周期的,Pod 重启 IP 就会发生变化。如果我们的服务都是将Pod 的 IP 地址写死,Pod 的挂掉或者重启,和刚才重启的 pod 相关联的其他服务将会找不到它所关联的 Pod,为了解决这个问题,在 kubernetes 中定义了 service 资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service 是一组 Pod的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector 实现的。
4.Ingress
Ingress 可以把进入到集群内部的请求转发到集群中的一些服务上,从而可以把服务映射到集群外部。Ingress 能把集群内 Service 配置成外网能够访问的 URL,流量负载均衡,提供基于域名访问的虚拟主机等
5. 资源对象详解
具体见链接
四、K8S工作原理(运维管理员、用户访问)
K8S的工作原理可以分为两方面理解:
1.K8S的工作流程(pod的创建流程)
简单理解:运维人员调度K8S时的流程

管理员通过kubectl提交pod创建指令,指令可以时yaml文件,yaml文件里面定义很多pod参数,比如镜像、版本等。
①管理员通过客户端发送创建pod的请求到master节点上传送到API Server
②API Server会将Pod信息存入etcd中
③Controller Manager控制器通过(watch机制)API接口发现pod信息更新,然后请求API Server到etcd拿到相关信息,根据预设的资源模板创建pod清单
④将创建的信息返回给API Server,API Server再将数据更新存到etcd中。
⑤scheduler通过(监听机制)API Server中信息的变化,通过API Server到etcd返回拿到节点信息,scheduler会通过调度算法的预选策略和优选策略筛选出最合适的Node节点,生成pod的模板,将结果返回给apiserver,api将信息存到etcd(已有模板)。
⑥API Server通知对应节点的kubelet,kubelet发现Pod调度到本节点,通过API Server拿到相关信息,再通过容器(例如docker)创建并运行Pod的容器。
⑦Kube-proxy给pod分配网络资源,包括服务的发布以及负载均衡的配置
2. K8S中访问请求原理(用户访问K8S的工作原理)
访问流程:

例如:客户发送请求xxx.com
请求xxx.com —> Ingress ----> Service —> KubeDNS/CoreDNS —> Kube-proxy —> pod

用户发起请求,请求传送到Ingress
Ingress :作用是定义请求如何转发到service的规则,ingress支持7层代理转发,它可以通过根据不同的域名或者URL访问路径把请求流量转发到不同的service上,实现调度不同业务域、不同URL访问路径的业务流量。
Service: 提供了服务的负载均衡和反向代理的能力,(详解三种类型)发来的请求通过负载均衡 4层代理转发到它所关联的后端pod上。
KubeDNS:依靠DNS进行解析,将域名解析成DNS获得虚拟IP。
Kube-proxy(详解三种工作模式) :对虚拟IP的请求按策略转发给后端,通过不同的工作模式设置不同的转发规则,确定转发到哪个pod上。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了K8S的架构的部分内容,如有问题,欢迎评论区讨论。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)