
基于昇思MindSpore实现的时空超分辨率CycMuNet+,显著提高视频画质
论文标题CycMuNet+: Cycle-Projected Mutual Learning for Spatial-Temporal Video Super-Resolution论文来源CVPR2022/TPAMI论文链接https://openaccess.thecvf.com/content/CVPR2022/papers/Hu_Spatial-Temporal_Space_Hand-in-
论文标题
CycMuNet+: Cycle-Projected Mutual Learning for Spatial-Temporal Video Super-Resolution
论文来源
CVPR2022/TPAMI
论文链接
https://openaccess.thecvf.com/content/CVPR2022/papers/Hu_Spatial-Temporal_Space_Hand-in-Hand_Spatial-Temporal_Video_Super-Resolution_via_Cycle-Projected_Mutual_Learning_CVPR_2022_paper.pdf
代码链接
https://github.com/tongyuantongyu/cycmunet/tree/main/mindspore
昇思MindSpore作为一个开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能,超大规模AI预训练、极简开发、安全可信的体验,2020.3.28开源来已超过5百万的下载量,昇思MindSpore已支持数百+AI顶会论文,走入Top100+高校教学,通过HMS在5000+App上商用,拥有数量众多的开发者,在AI计算中心,金融、智能制造、金融、云、无线、数通、能源、消费者1+8+N、智能汽车等端边云车全场景逐步广泛应用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、套件、模型众智、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
在科技界、学术界和工业界对昇思MindSpore的广泛支持下,基于昇思MindSpore的AI论文2023年在所有AI框架中占比7%,连续两年进入全球第二,感谢CAAI和各位高校老师支持,我们一起继续努力做好AI科研创新。昇思MindSpore社区支持顶级会议论文研究,持续构建原创AI成果。我会不定期挑选一些优秀的论文来推送和解读,希望更多的产学研专家跟昇思MindSpore合作,一起推动原创AI研究,昇思MindSpore社区会持续支撑好AI创新和AI应用,本文是MindSpore AI顶会论文系列第19篇,我选择了来自武汉大学计算机学院的王正老师团队的一篇论文解读,感谢各位专家教授同学的投稿。
昇思MindSpore旨在实现易开发、高效执行、全场景覆盖三大目标。通过使用体验,昇思MindSpore这一深度学习框架的发展速度飞快,它的各类API的设计都在朝着更合理、更完整、更强大的方向不断优化。此外,昇思不断涌现的各类开发工具也在辅助这一生态圈营造更加便捷强大的开发手段,例如MindSpore Insight,它可以将模型架构以图的形式呈现出来,也可以动态监控模型运行时各个指标和参数的变化,使开发过程更加方便。
01研究背景
随着短视频和直播的兴起,在线视频领域用户使用时长已经超过社交领域,同时用户对视频画质的要求不断提高。视频的帧率和分辨率作为衡量视频质量的两个重要指标,对人眼主观感受影响良多,但是高帧率、高分辨率的视频对网络传输带宽、传输设备等要求也随之提高。而且在现实环境中,大多数获取的视频数据具有低帧率和低分辨率。因此对于能够将给定视频转换为具有更高帧率和分辨率的视频的框架,肯定有很大的需求。所以如何有效地联合视频时间超分辨率和空间超分辨率技术进行视频时空超分率,也受到国内外研究人员的广泛关注。

图1:视频时空超分辨率不同方案
如图1所示,目前先进的视频时空视频超分辨率方法主要分成两类:基于两阶段方法和基于一阶段方法。基于两阶段的方法将视频时间超分辨率和空间超分辨率视为两个独立的任务,并依次执行这两个任务进行视频时空超分辨率,然而这个方法并没有考虑两个任务的互惠性。基于一阶段的方法将视频时间超分辨率和空间超分辨率整合到一个统一的框架进行视频时空超分辨率,但是他们仍然只考虑两个任务的单边关系。导致最后重建的结果有明显的伪影。
为了解决上述的问题,我们提出了一种基于单阶段循环映射互相学习的策略,以保证视频时间和空间超分任务互相学习,进而促进时空信息的充分利用。在所提出的方法中,我们设计了上下映射单元,有效地利用时间相关性用于空间细节的重建,同时,更新的空间信息反过来巩固时间的预测。通过多次的迭代,时间和空间信息能够完全的互相利用。基准数据集上的结果表明,所提出的方法在视频时间超分,视频空间超分和视频时空超分任务实现了显着改进。
02团队介绍
胡梦顺:武汉大学三年级博士生。期间已经发表TPAMI、TCSVT、CVPR、AAAI、ACMMM等高水平期刊和论文。主要研究方向:视频时空超分辨率,视频插帧。
江奎:哈尔滨工业大学副教授。获2022 ACM 武汉博士论文奖。在顶级期刊和会议(如TPAMI、TIP、CVPR、ICCV、AAAI、ACM MM)发表论文30余篇。主要研究方向:图像/视频处理。
王正:武汉大学计算机学院/国家多媒体软件工程技术研究中心教授,计算机实验教学中心主任,国家级人才计划青年项目(海外)入选者。曾任东京大学助理教授,日本文部科学省卓越研究员,日本学术振兴会外国人特别研究员,获中国留日同学会最优秀青年学者奖。在顶级期刊和会议(如TPAMI、TIP、CVPR、ICCV、AAAI、ACM MM)发表论文70余篇,获PCM 2014最佳论文奖,ICME 2021最佳论文提名,入选斯坦福大学2022年度“全球前2%顶尖科学家榜单”。主持国家重点研发计划子课题和湖北省重点研发计划项目。近两年指导学生获得“中国软件杯”大学生软件设计大赛、全国大学生物联网设计竞赛、华为ICT大赛、中国研究生人工智能创新大赛、中国研究生网络安全创新大赛等学科竞赛全国一等奖。其中,InvisDefense隐身衣获得共青团中央创青春微信公众平台等国内外媒体关注和报道。主要研究方向为多媒体内容分析、身份辨识、社会安全治理等,
白翔:华中科技大学自动化学院教授,博士生导师,国家防伪工程中心副主任。曾先后访问于美国Temple大学和加州大学洛杉矶分校,入选微软铸星计划。他已在计算机视觉与模式识别领域一流国际期刊和会议如PAMI、IJCV、CVPR、ICCV、ECCV、NIPS、ICML上发表论文30余篇,担任国际期刊Frontier of Computer Science, Pattern Recognition Letters, Neurocomputing, Pattern Recognition, Journal of Computer Science and Technolgy等编委或客座编辑。尤其在形状的匹配与检索、场景OCR取得了一系列重要研究成果,引起了国际同行的关注,入选2014、2015年中国高被引学者。他的研究工作曾获微软学者,国家自然科学基金优秀青年基金的资助。担任中国计算机学会计算机视觉专委会(CCF-CV)常务委员,中国图象图形学学会理事,是视觉与学习青年研讨会(VALSE)在线活动主要发起人之一。他的研究领域为计算机视觉与模式识别,具体包括目标识别、形状分析、自然场景文字识别及智能交通系统。
胡瑞敏:西安电子科技大学网络与信息安全学院院长,二级教授,第七届中国青年科技奖和第五届中国青年科技创新奖获得者。曾任武汉大学学术委员会副主任委员、计算机学院/国家网络安全学院院长。担任国家重点研发计划(在研)和重大科技专项(已结题)首席专家,曾任海康威视公司第一任研究院院长、TCL公司技术顾问、美亚柏科研究所首席科学家,和华为、科大讯飞等公司长期合作。先后主持四项多媒体大数据信息处理和网络空间自然行为与社会理解领域国家自然科学基金重点项目,指导研究生获互联网+金奖、智慧城市大赛特等奖、移动终端大赛一等奖、CCF优秀博士论文奖、ACM中国优秀博士论文和中国图形图像学会优秀博士论文提名奖。近年来开展包括多媒体信息处理、人工智能、大数据分析和自然行为与社会理解等技术在内的交叉学科研究,重点专注空间海量视频编码与信息智能处理、大数据自然行为与社会理解(可信身份/隐秘组织/复杂关系/模式行为/安全解析)的理论与方法研究,16年在美国NIST举办的国际视频大数据分析领域最著名的Trecvid实例竞赛中取得30项全球第一的优异成绩。
03论文简介
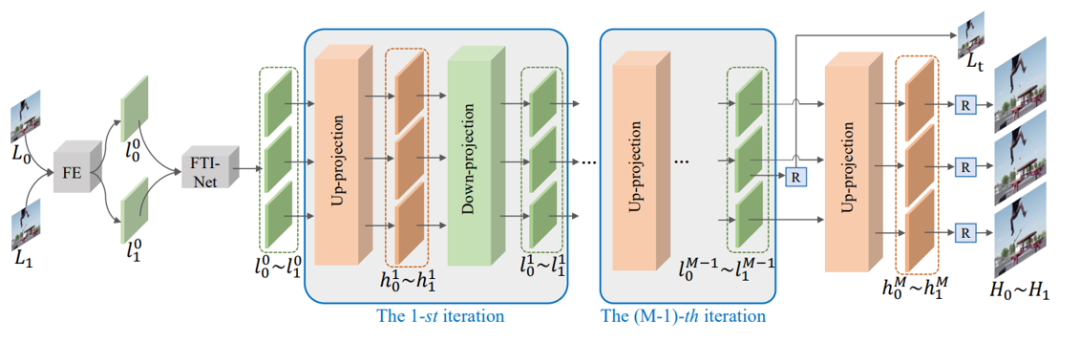
图2:视频时空超分辨率框架
如图二所示,本篇论文的实验设置是给定两个低分辨率的帧来生成三个高分辨率帧以及对应的低分辨率中间帧。具体地,CycMuNet首先利用特征提取器(FE)来抽取低分辨率输入帧的特征,然后采用一个特征插值网络(FTI-Net)来插帧中间低分辨率中间帧的特征,接着利用提出的循环上下映射单元(Up-projection和Down-projection)来充分学习它们的时空信息,减少跨空间错误,最后利用重建模块(R)来生成高分辨率帧和对应的低分辨率中间帧。
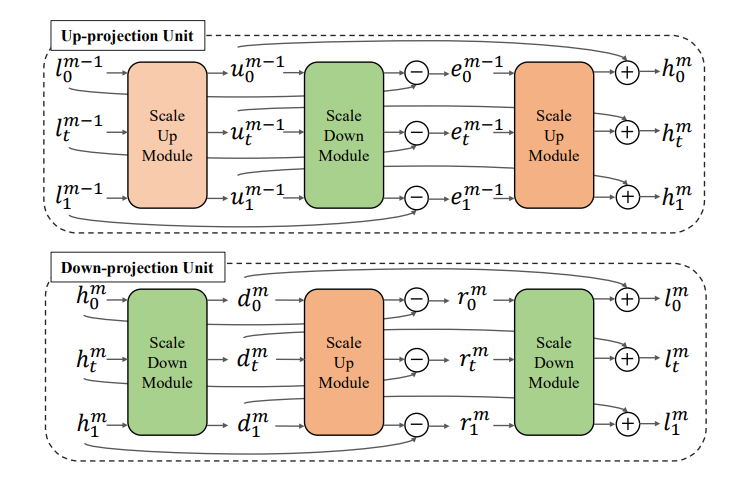
图3:上映射单元和下映射单元结构
本篇文章的核心思想是循环映射互相学习,以保证时间和空间视频超分任务互相学习,进而促进时空信息的充分利用。如图3所示,它主要由迭代的上下映射单元完成。对于上映射单元,它的作用是利用高帧率视频的时间上下文信息来促进空间细节信息的重建。每个上映射单元包含两个尺度上采样模块和一个尺度下采样模块。具体地,我们首先利用一个尺度上采样模块来获取粗糙的高分辨率特征。然后利用一个尺度下采样模块来反向映射到低分辨率空间学习跨空间的错误,最后将这些错误信息通过一个尺度上采样模块反向映射到高分辨率空间来细化前面获取粗略的高分辨率特征。对于下映射单元,它的作用是利用更新的空间信息来巩固时间信息的预测。其过程和上采样模块类似。
04实验结果
为了验证我们方法的有效性。我们与先进的视频时空超分辨率、视频空间超分辨率和视频时间超分辨率方法进行比较。分析如下:
(1)视频时空超分辨率:如表1所示,基于一阶段方法探索两个任务的单边关系明显好于基于两阶段方法。我们方法挖掘通过迭代的上下映射单元来挖掘这两个任务的相互关系,实现进一步的效果提升。
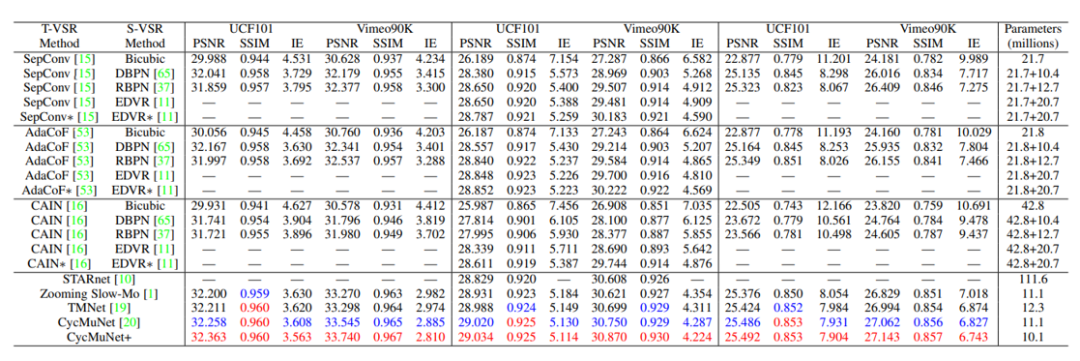
表1:视频时空超分辨率比较
(2)视频空间超分辨率:如表2所示,我们的方法在更少的参数和训练的数据的基础上实现同等表现。主要得益于上映射单元利用高帧率视频的上下文信息用于视频空间超分。
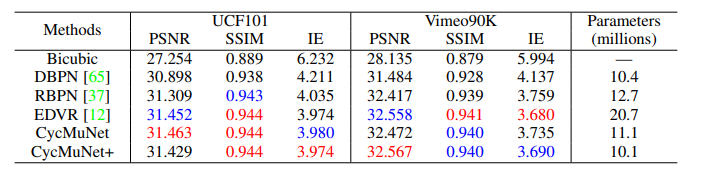
表2:视频空间超分辨率比较
(3)视频时间超分辨率:如表3所示,我们的方法明显实现更好的表现。得益于我们充分利用来自下映射单元的高分辨率信息用于低分辨率中间帧生成。
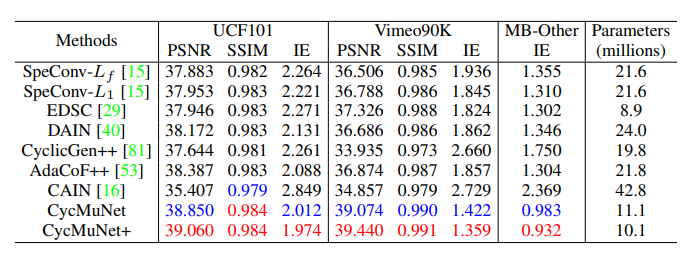
表3:视频时间超分辨率比较
CycMuNet模型的前期开发在PyTorch框架上进行,为了适应国产化的需求,我们将CycMuNet模型移植到了昇思MindSpore框架,以支持在昇腾Ascend硬件上训练和执行。下面记录了移植过程,并对昇思MindSpore和PyTorch的使用体验进行了对比。与PyTorch不同的是:
(1)代码开发:在编写PyTorch代码时,如何管理好各种tensor的存储位置是一个困扰我们的问题:在使用GPU的训练代码中,一不小心可能会漏掉将一个输入移动到GPU显存中;在测试时,如果需要在CPU或其他的加速设备上运行,又需要手动清理或改写散落在各处的存储位置移动操作,这也导致了尽管PyTorch本身是个跨平台的框架,但大量使用PyTorch实现的网络只能在CUDA环境下执行。昇思MindSpore的设计从根本上解决了这一问题,我们只需要在顶层代码处设置目标设备,其余的代码不需要更改就可以在不同的设备上运行。这一设计让我们只需要编写一次代码就可以支持不同的设备,同时避免了在不同硬件上开发的网络实现之间出现生态割裂。
(2)模型训练:昇思MindSpore不需要手动编写每一步的数据生成、正向计算、反向传播、权重更新等步骤,而是把训练所需要的各种信息聚合在了一个Model类当中,由框架来完成训练过程中的一系列操作。这一设计初见并不是那么易懂,但这让昇思MindSpore框架能够掌握整个训练过程,从而让框架可以对整个流程进行整体优化。
(3)模型部署:昇思MindSpore使用静态图的设计相比于PyTorch带来了一个很大的好处:我们可以自然地将训练完成的模型的权重和结构一起保存下来,脱离我们使用Python编写的结构定义代码。这一特性对于模型在生产环境的部署十分有帮助:在部署模型时,我们往往不希望再运行一个Python解释器,而是需要一个精简的运行环境。昇思MindSpore可以将模型轻松地导出为专用的MindIR或通用的ONNX格式,而PyTorch编写的网络要导出为ONNX,则要么需要对已有的代码进行改写为TorchScript支持的形式,要么导出的结果可能并不正确、依旧需要更改代码的写法。因此昇思MindSpore对代码编写方式的要求,实际上是一个优势,为后续的部署工作铺平了道路。
05总结与展望
(1)我们提出了一个新颖的一阶段循环映射相互学习网络用于视频时空超分率,以保证视频时间和空间超分任务互相学习来充分探索视频的时空信息。
(2)我们设计迭代的上下映射单元来完成两个任务相互学习,丰富的空间信息通过下映射单元来促进时间预测,同时时间相关性通过上映射单元来细化纹理和细节。
(3)实验表明,所提出的方法在视频时间超分,视频空间超分和视频时空超分任务实现了显着改进。
致谢:本研究成果得到了中国人工智能学会-华为MindSpore学术奖励基金的资助。
往期回顾
论文精讲 | 基于昇思MindSpore实现多域原型对比学习下的泛化联邦原型学习
论文精讲 | 基于昇思的等夹角向量基(EBVs)分类性能显著优于传统分类器详解

昇腾万里,让智能无所不及
更多推荐

 0
0 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)