机器学习--神经网络训练:批次(batch)和动量(momentum)
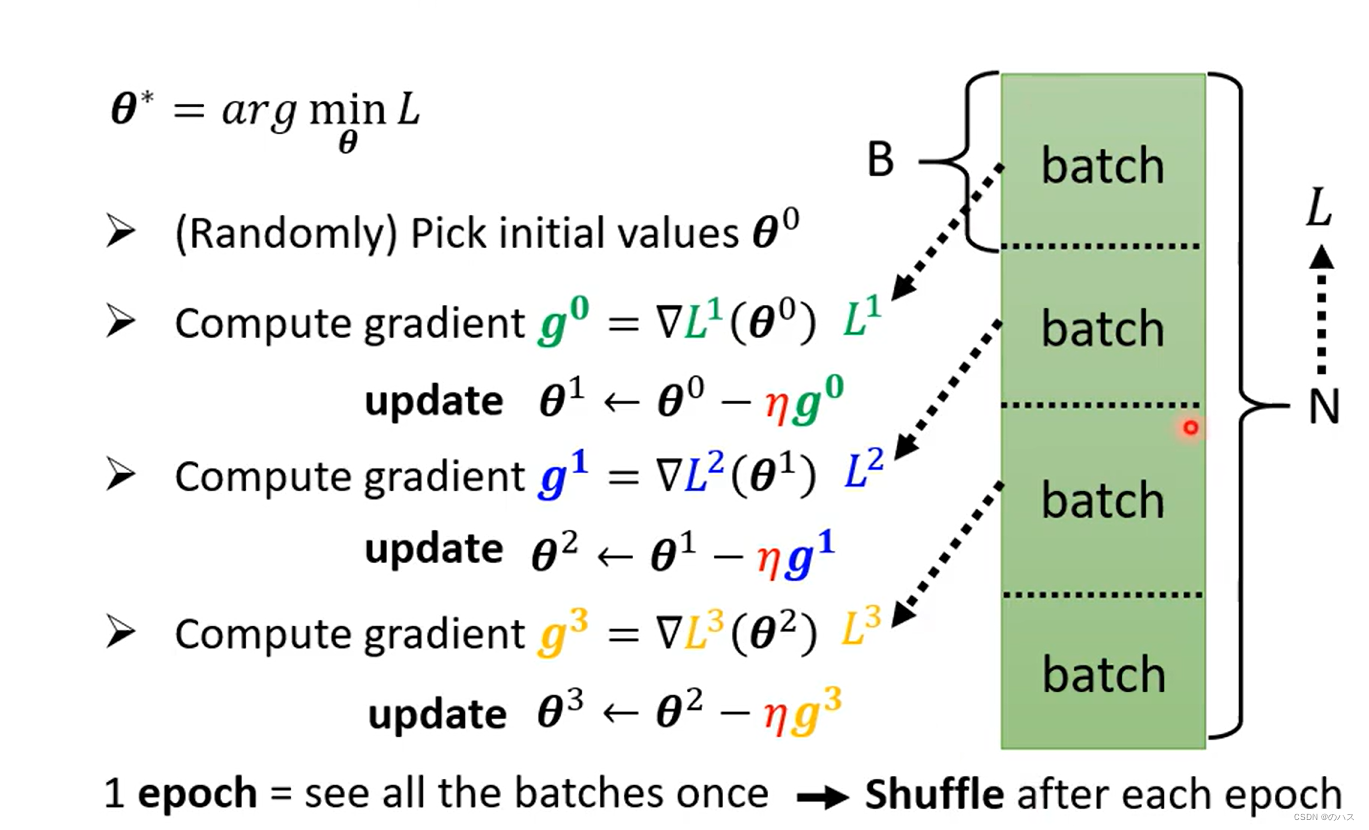
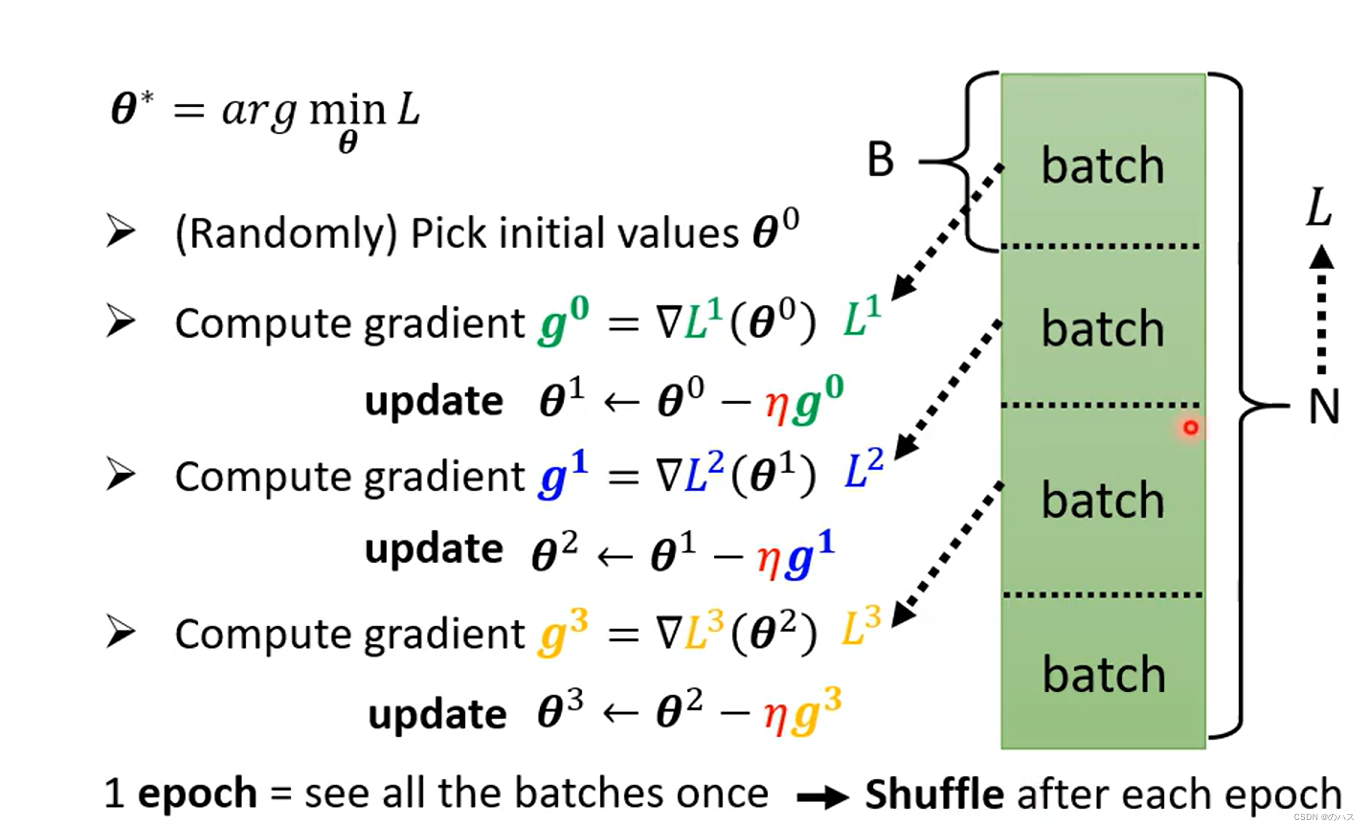
之前介绍过了,把训练数据分为很多个batch,然后每个batch算梯度并更新,所有batch全部计算过一次为一个,在一个echo完成后下一个echo前,需要先进行(洗牌,打乱次序),即再次将训练数据重新分配,与之前的分配方式区别开。
一、分批次优化
1.复习
之前介绍过了,把训练数据分为很多个batch,然后每个batch算梯度并更新,所有batch全部计算过一次为一个echo,在一个echo完成后下一个echo前,需要先进行shuffle(洗牌,打乱次序),即再次将训练数据重新分配,与之前的分配方式区别开。
2.大batch 和 小 batch 的优劣分析
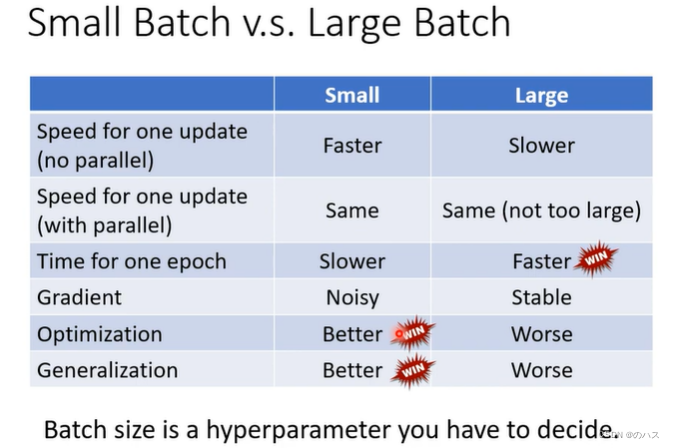
按预计来说,大的batch会需要更长的时间来进行一次位置更新,但是我们的GPU是可以做平行运算的,所以说只要数据不是太大,其实不需要花费更长的时间,但一个batch很大就会导致时间增加。
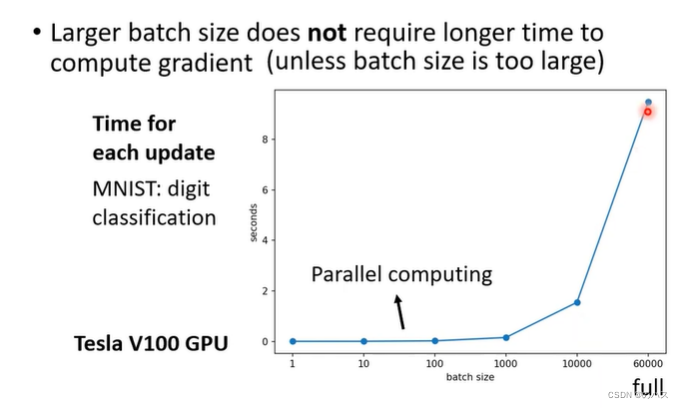
更小的batch在一个epoch中会有更多次update,每次update会进行一次梯度计算以及位置移动,所以总的来说,小的batch一个epoch的所花费的时间反而会更长一点。

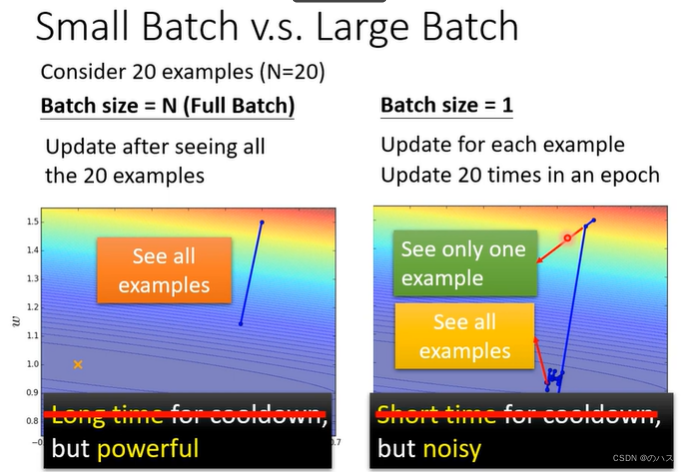
但是相应的,小的batch在模型优化上面会表现更好,我们可以从图上看出,因为模型会被优化很多次,可能你的L1,你求梯度等于0了,但是在这个地方L2上的梯度不为0,这样就能够进一步优化,降低我们的Loss。

在测试数据上我们也可以看到,小的batch的效果会更好,而大的batch反而产生了overfitting。
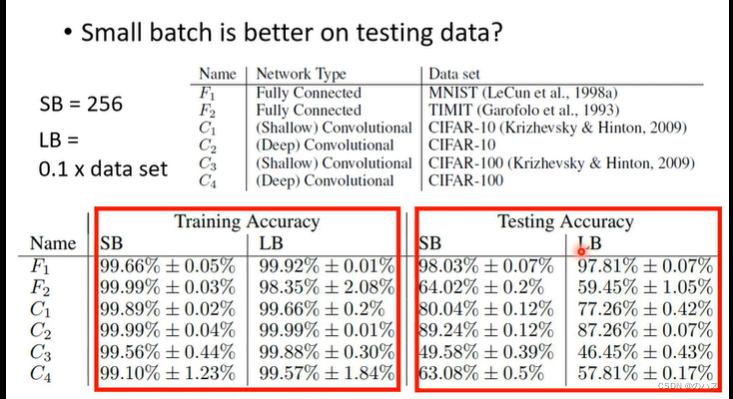
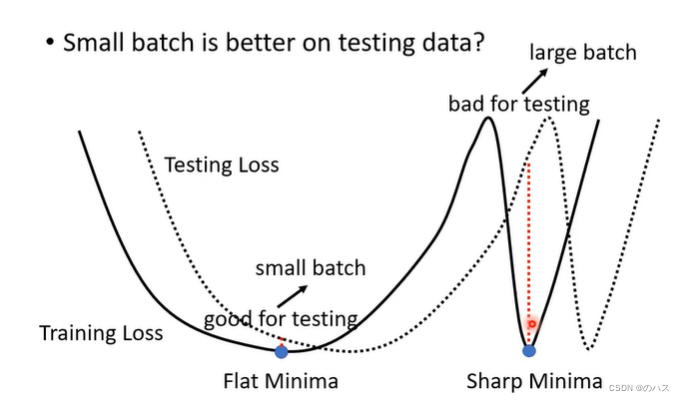
为什么呢?其实minima也分为好的minima和坏的minima,对于这种比较平的minima,我们一般认为是好的,这种很尖的minima,我们认为是坏的minima(大的batch比较容易产生这样的minima),可以看实线minima对应的虚线处的Loss(因为训练数据和测试数据的Loss函数还是有一点点区别的)sharp 的minima对应的Loss可能于训练时的Loss天差地别,这就是大的batch在测试数据上表现不好的原因,而小的batch的minima比较平,就算是与测试数据的Loss函数有点区别也不会相差太大。
可知运行速度来讲大的batch会更快一些,但是小的batch在训练和实际测试是的表现会更好,可以说可有个的优点,所以batch的大小又是一个我们需要自己定义的参数,一个hyperparameter。
那么结合这两者优点,就可以即快速的得到好的模型,用能够在测试中有很好的效果。
二、动量(momentum)
1.引入
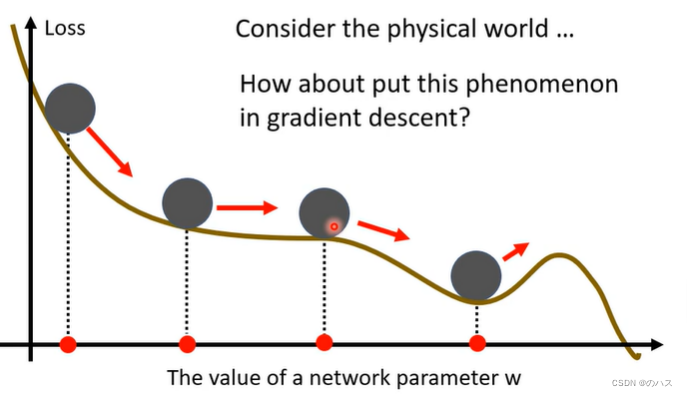
假设我们的Loss就是一个真正的斜坡,这个球滚下来,就算到了我们的这个saddle point 如果动量足够他还是会翻过这个坡然后继续往下滚,我们怎样把这种现象用到我们的优化中呢。
先来看一下一般情况下的update:
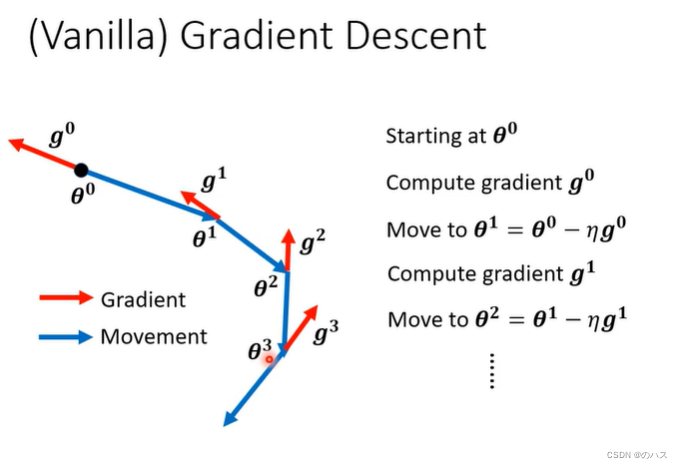
更好的做法就是,把我们的用算出来的gradient的反方向和上一步的movement方向,做矢量和得到这一步的方向。
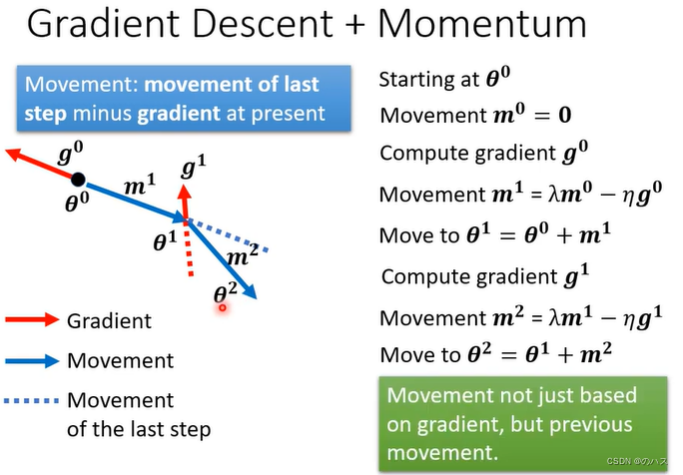
用一个图来描述就是这样:


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)