

YOLOv8最新改进系列:YOLOv8华为提出Gold-YOLO,高效实时目标检测器,精度再提升,多目标、小目标无处遁形!
YOLOv8华为提出Gold-YOLO,高效实时目标检测器,精度再提升,多目标、小目标无处遁形!
YOLOv8最新改进系列:YOLOv8华为提出Gold-YOLO,高效实时目标检测器,精度再提升,多目标、小目标无处遁形!
安排!!!只管遥遥领先就完了!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv8最新改进系列的源码包,已更新了33种+损失函数的改进!自己排列组合2-4种后,不考虑位置已达5万种以上改进方法!考虑位置不同后可排列上百万种!!专注AI学术,关注B站博主:AI学术叫叫兽!
YOLOv8最新改进系列:YOLOv8华为提出Gold-YOLO,高效实时目标检测器,精度再提升,多目标、小目标无处遁形!!!!
一、Gold-YOLO概述
1.1 文章摘要(让我看看怎么个事儿)
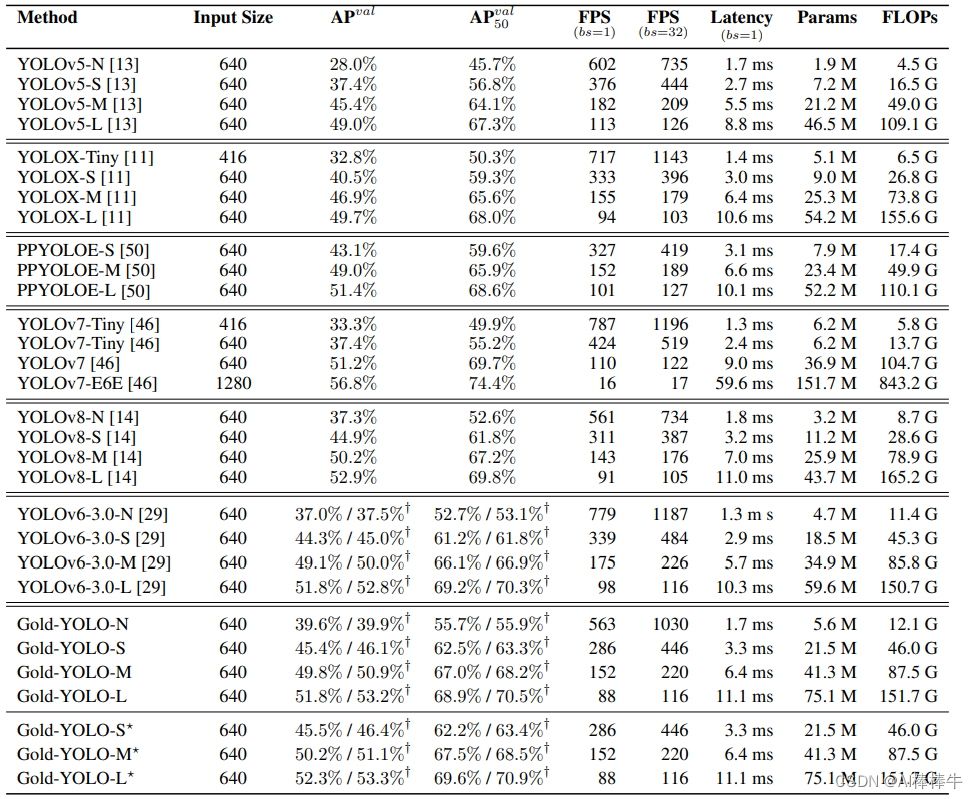
在过去的几年中,YOLO 系列模型已成为实时目标检测领域的领先方法。许多研究通过修改架构、增加数据和设计新的损失,将基线提升到更高的水平。然而,我们发现以前的模型仍然存在信息融合问题,尽管特征金字塔网络(FPN)和路径聚合网络(PANet)已经缓解了这个问题。因此,本研究提供了一种先进的Gatherand-Distribute机制(GD)机制,通过卷积和自注意力操作来实现。这种新设计的模型被命名为Gold-YOLO,它增强了多尺度特征融合能力,并在所有模型尺度上实现了延迟和准确性之间的理想平衡。此外,我们首次在 YOLO 系列中实现了 MAE 式的预训练,使 YOLO 系列模型可以从无监督预训练中受益。 Gold-YOLO-N 在 COCO val2017 数据集上获得了出色的 39.9% AP,在 T4 GPU 上获得了 1030 FPS,比之前具有类似 FPS 的 SOTA 模型 YOLOv6-3.0-N 提高了 2.4%。
1.2 介绍(翻译了原文-机翻)
物体检测作为一项基本的视觉任务,旨在识别物体的类别并定位物体的位置。可广泛应用于智能安防、自动驾驶、机器人导航、医疗诊断等领域。高性能和低延迟的物体检测器在边缘设备上的部署越来越受到关注。在过去的几年里,研究人员对基于 CNN 的检测网络进行了广泛的研究,逐渐将目标检测框架从两阶段(例如 Faster RCNN [40] 和 Mask RCNN [22])发展到一阶段(例如 YOLO) [37]),从基于锚点(例如,YOLOv3 [39]和YOLOv4 [2])到无锚点(例如,CenterNet [10],FCOS [44]和YOLOX [11])。 [12,7,16]通过NAS研究了物体检测任务的最优网络结构。单阶段检测模型,尤其是YOLO系列模型,因其结构简单、速度与精度之间的平衡而受到业界的广泛欢迎。骨干的改善也是视觉领域的一个重要研究方向。正如调查[18]中所述,[23,24,57,19]在精度和速度之间取得了平衡,而[9,33,20,17]在精度方面表现出了很强的表现。这些主干网络提高了原始模型在不同视觉任务中的性能,从对象检测等高级任务到图像恢复等低级任务。通过使用编码器-解码器结构
针对 Transformer,研究人员构建了一系列类似 DETR 的物体检测模型,例如 DETR [3] 和 DINO [54]。这些模型可以捕获物体之间的远程依赖性,使基于变压器的检测器能够实现与最精致的经典检测器相当或更好的性能。尽管基于 Transformer 的检测器性能显着,但与基于 CNN 的模型的速度相比,它们仍存在不足。基于 CNN 的小规模目标检测模型仍然在速度与精度权衡中占据主导地位,例如 YOLOX [11] 和 YOLOv6-v8 [30,46,14]。
我们专注于实时目标检测模型,特别是用于移动部署的YOLO系列。主流的实时物体检测器由三部分组成:脊柱、颈部和头部。主干架构已被广泛研究[39,41,9,33],头部架构通常是直接的,由几个卷积层或全连接层组成。 YOLO系列中的颈部通常使用特征金字塔网络(FPN)及其变体来融合多级特征。这些颈部模块基本上遵循图3所示的架构。然而,当前的信息融合方法有一个显着的缺陷:当需要跨层集成信息时(例如,level-1和level-3融合),传统的类似FPN的结构无法无损地传输信息,这阻碍了YOLO更好的信息融合。基于全局信息融合的概念,TopFormer[56]在语义分割任务中取得了显着的成果。在本文中,我们在 TopFormer 理论的基础上进行了扩展,提出了一种新颖的收集和分发机制(GD),通过全局融合多层次特征并将全局信息注入更高层次来实现 YOLO 中有效信息交换。这显着增强了颈部的信息融合能力,而不会显着增加延迟,从而提高了模型在不同物体尺寸上的性能。具体来说,GD机制包括两个分支:浅层收集和分布分支和深层收集和分布分支,分别通过基于卷积的块和基于注意力的块提取和融合特征信息。为了进一步促进信息流,我们引入了一个轻量级的相邻层融合模块,该模块在局部范围内结合了相邻层的特征。我们的 Gold-YOLO 架构超越了现有的 YOLO 系列,有效地证明了我们提出的方法的有效性。为了进一步提高模型的精度,我们还引入了预训练方法,使用 MAE 方法在 ImageNet 1K 上对主干网进行预训练,这显着提高了模型的收敛速度和精度。例如,经过预训练的 Gold-YOLO-S 达到了 46.4% 的 AP,这比之前的 SOTA YOLOv6-3.0-S 在相似速度下的 AP 为 45.0% 更好。
二、方法
2.1 Glod-YOLO网络框架
golo-yolo为了避免不停迭代的间接融合不同level的信息,提出一种GD(gather-and-distribute聚合-分发)的机制,整体结构如下:
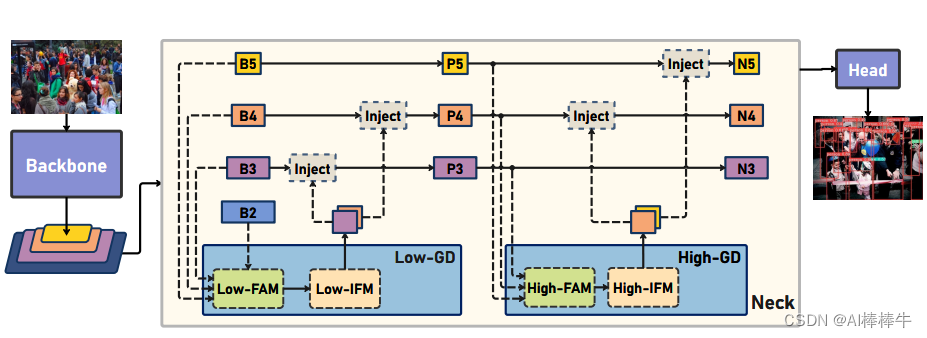
其中GD主要分成3个模块:FAM(Feature Alignment Module,特征对齐模块)、IFM(Information Fusion Module,信息融合模块)、Inject(Information Injection Module,信息注入模块)
2.2 low-GD模块
low-GD主要用于融合模型浅层的特征信息,此处为B2,B3,B4,B5的特征,包含上述说的2个模块,具体过程如下图所示:
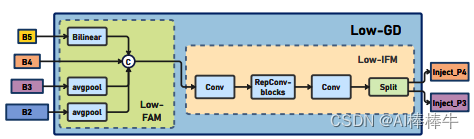
是一个FAM模块,用下图公式表达,即先将B2,B3,B4,B5统一到B4的[h/4,w/4]的尺寸,然后在channel上concat,
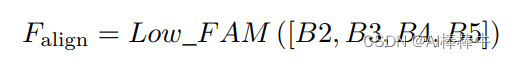
2.2.1 Low-IFM模块
将FAM的输出先经过多层RepBlock提取信息,然后再按channel分成2部分,如下图公式,得到inj_p3和inj_p4,作为后续Inject的输入,此处得到的特征图作为global信息。
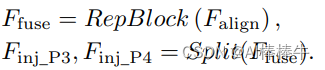
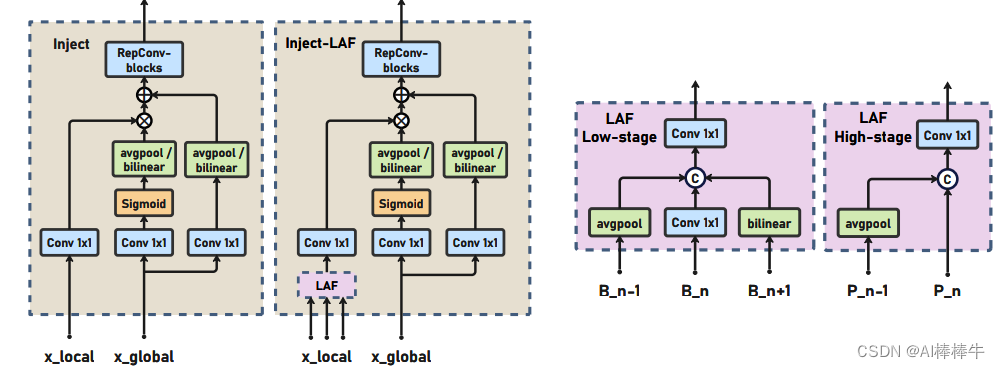
2.2.2 Inject模块
Inject模块分成Inject和带LAF模块的Inject.LAF网络介绍见2.5即可。
low-inject的具体过程用下图公式表达,其中global代表是用FAM模块将多层融合一起的特征,local代表的是每层的特征,比如B2
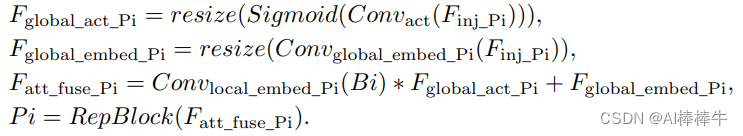
2.3 high-GD模块(high-GD结构上类似low-GD,包含GD的3个模块)
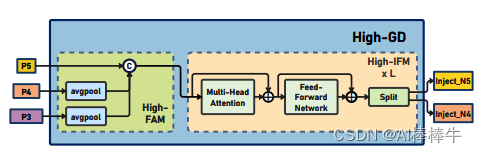
2.3.1 high-FAM模块
输入只用了p3,p4,p5,其中p5下图中的B5
计算公式如下:
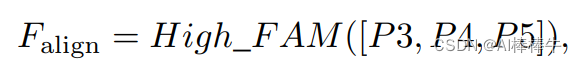
2.3.2 high-IFM模块
high-IFM的结构也有改动,由于high-FAM输出的特征尺寸变小了,为了充分融合全局信息,具体如下图,将low-gd中的repblock替换成了transformer模块,这里的transformer是基于卷积实现的,将linear线性层替换成了conv,layernorm替换成了batch norm。
计算公式如下:
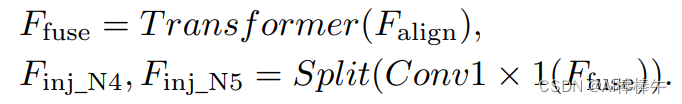
2.3.2 inject模块
计算公式如下:
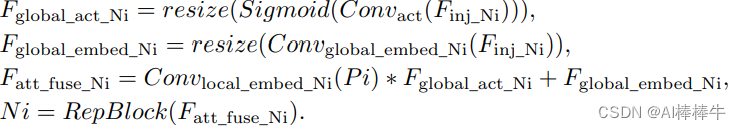
2.4 LAF网络模块
LAF是一个轻量的邻层融合模块,如下图所示,对输入的local特征(Bi或pi)先和邻域特征融合,然后再走inject模块,这样local特征图也具有了多层的信息。
2.5 实验结果
三、 改进教程
3.1 修改YAML文件
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
3.2 新建Gold-YOLO.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
3.3 修改tasks.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
四、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:AI学术叫叫兽
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)