跳槽去搞国产大模型,收入能涨多少?
原创:谭婧夏尽秋来,2023年国产大模型看似喧闹已止,进入稳定竞争期。作为一种新的IT解决方案,国产大模型一出生便伴随着激烈竞争。外有GPT4,内有多家公司角逐“中国版ChatGPT”。据我所知,就国内某家头部大模型创业公司的收入来说,几千万的合同已经有了。况且,组队窗口期已经进入后期,难度越来越大。而竞争格局未定,研发还在拼命烧钱。虽说优秀人才越多越好,但客观规律是IT人才结构呈金字塔形,顶部人
原创:谭婧
夏尽秋来,2023年国产大模型看似喧闹已止,进入稳定竞争期。
作为一种新的IT解决方案,国产大模型一出生便伴随着激烈竞争。
外有GPT4,内有多家公司角逐“中国版ChatGPT”。
据我所知,就国内某家头部大模型创业公司的收入来说,几千万的合同已经有了。
况且,组队窗口期已经进入后期,难度越来越大。
而竞争格局未定,研发还在拼命烧钱。
虽说优秀人才越多越好,但客观规律是IT人才结构呈金字塔形,顶部人才是极少数。
本文中,我借用《王者荣耀》游戏段位顺序,划分大模型技术段位:
王者,白金,黄金,青铜。
王者们,那些科技大厂背景的领军人,硬核科研背景的AI科学家,已经陆续“众神归位”。
字节跳动的杨红霞(原阿里达摩院)。
百川智能的陈炜鹏(原搜狗旧部)。
昆仑万维的颜水成(原360),等等。
另有一些大神独立门户,爱诗科技(原字节跳动王长虎),HiDream.ai(原京东梅涛),衔远科技(原京东周伯文)……
无论大厂,还是创业公司,挖人靠钱。
那么当下,白金,黄金,青铜段位面临什么样的境况呢?
(一)白金段位:不设上线
当猎头询问“薪酬带宽”,多家大模型创业公司负责人做出类似表态:
“收入不设上限,就怕你们找不来人。”
通用大模型有且有很多未知的技术秘密,关键技术路线更依靠金字塔上一层决策。
路线创新会有风险,但又不能一味跟在别人屁股后面跑。
不设上线的表态,从一个侧面反映出这类人才的重要性,尤其是已有大模型高水平实战经验,且“实线带人”。
一位从业者向我表达:“不要用资深一词描述研发管理层主力,过于模糊,他们实现技术,把握节奏,以及保持团队内部稳定。”
这时候,不得不说:“火车跑得快,全靠车头带。
比如百川智能,有面试候选人告诉我:“陈炜鹏负责大模型开源策略。”
而百川的开源策略也被业内专家夸赞颇多,在短短几个月的时间内打出了声量,也打出了技术影响力,亦使融资受益。
近几个月,甲方客户(传统行业头部)和大模型创业公司频繁交流。
中石油旗下尤其擅长数字化的企业(昆仑数智科技)的员工告诉我,目前市面上鼎鼎有名的大模型科技巨头和上市公司差不多都来交流过。上一波如此密集的交流还是国产数据库。
一些甲方企业在“炼”行业大模型,甲方企业对领先创业公司的员工很是偏爱,毕竟,跳槽会带来珍贵的经验。不仅如此,老牌IT服务厂商也不想落后。
比如,一家甲方客户告诉我:
“有的AI初创公司,技术水平真的很高。那些骨干研发管理层的水平就很好,哪怕下面带的兵都是校招的,团队逼一逼也能出活。虽然花的时间长些,但迟早都能弄出来。我们就缺这样的人才。”
至此,市场上大致上有四批雇主在抢“白金”:互联网科技公司,大模型创业公司,有创新能力的甲方公司,老牌IT服务厂商。
前两者尤其抢得厉害,后两者似乎没有什么胜算。
有些创业公司的核心竞争力是王者和白金两个段位共同产生的合力。一些王者本身就是知名学者,悉心培养高业弟子,无论从信任,还是技术传承方面都颇有默契,一些白金段位的人才之间,还是师兄弟。
况且,“白金”的需求就是有高手指导,大师指点,让能力更上层楼。收入重要,但不是全部。
因此,“白金”高价难求。
说到底,好公司里,骨干的薪酬一定会有竞争力,他们给企业贡献的价值也是实打实。
“实线带人”要发挥带着跑的能力,既关注技术细节,又保证组织效率。
众所周知,团队素质高则研发效率高,研发周期短。反之,小伙伴们水平有限,压力就给到白金段位这一边。
任务布置需讲得更为详细,安排更为具体,劳力费心。这样,对“白金”的要求更高,不仅技术高,还要心(脾)胸(气)广(好)。
这一轮大模型的竞争,比较起上一轮CV独角兽的竞争,竞争不可同日语,那时候的独角兽虽然也是跑步前进,但也是小几年做大的。而这一轮,瞬间集结,月余红海,家家有大佬,司司都加班,卡卡都烧钱。
谭老师我私下笑谈:“大模型创业公司拿出北京海淀区虎妈鸡娃的方法疯狂鸡团队。”
毕竟,“独角兽创业上市未半,而中道崩殂”的案例在前,这一轮创业者水平更显成熟。
另一方面,在与一家垂直行业头部企业(安防)的CTO交流后,我观察到,他们很清楚自身状况。作为“场景”的所有者,虽然技术水平难争一流,说是“积极跟进”都不够准确,而是“唯恐落后”。
毕竟,一旦技术较力的平衡被打破,很快会带动市场形势变化。那些谙熟多次数字化和AI技术迭代的老兵,不会弛懈。谈话间,海康卫视GPU卡的购买量就给脱口而出了。
谭老师观察身边的“白金”,若有机会在通用大模型团队中负责无监督的预训练,则炼“行业垂直大模型” 的意愿会较低。原因之一是通用大模型的实战经验难得,在通用大模型团队对个人价值提升更大。
“行业大模型”团队中的行业专家多,大模型专家少,缺少相互探讨精进技术的氛围。
有些公司,怎么做还没有想好就招人,还被有经验的面试者发现了,怪尴尬的。
我的结论是:抢“白金”最激烈的竞争,发生在互联网头部和大模型创业公司之间。白金段位的人才在这个阶段很难被垂直行业头部企业的吸引。
当然,这是一个摆在所有人面前的问题,白金段位的人才格外稀少。
所以,才会有“不设上线”的说法。
在白金段位中,还有一批隐藏高手,他们是AI infra的资深技术和架构。
人家本身在互联网大厂的起点年薪就很高,部分优秀人才年薪甚至可达150-200万。市场上牛人AI Infra的年薪,达300-400万或者更高,但是给出这个薪酬价格的厂商名字不能说。
另一方面,现在头部大模型创业公司的估值急增,拿到的早期股权激励会相当可观。
此外,除了四类厂商不断出价举牌之外,量化头部企业也出其不意杀了进来,尤其像幻方和九坤这类技术驱动的量化投资公司,也对此类人才也钟爱有加。
某一家量化公司技术高管对我说的原话是:
“我心仪的候选人不是被大模型创业公司挖走,就是被大厂大模型团队挖走,如果大模型遇冷,AI Infra同学们的薪酬溢价就没这么高了。”
可惜,大模型不仅没凉,还在抢人。
谭老师我认为:AI Infra这类隐藏高手的收入确实应该高,厉害人物不仅节省大量训练经费,也能极大地缩短训练周期。
我长期看AI Infra条线,前两年AI遇冷时期,AI算法收入缩水,而AI Infra的收入在头部AI企业是只涨不跌,只是较少人关注。不过,AI Infra还是美国那边高手更多。
同样重要,又往往易被忽略的是数据团队负责人,高端人才,非常核心。大模型数据组的功能大致分为采集、清洗和配比。其中配比的技术含量还高些。
虽然数据配比不属于算法技能,但是多数时候极为考验洞察力和经验。
对于互联网大厂来说,因为人才储备足,白金段位人才多,且较为稳定。不过,大厂也怕被挖角。原阿里达摩院大模型团队在几个月前“通义千问”没有发布的时候,就重新签了一遍竞业协议。百度亦是如此。
(二)黄金段位:极致性价比

这一段位可被称为在研发管理层领导下的开发主力
分两种情况:
第一种,非常幸运,有过大模型训练经验,跳槽的红利期来了。
第二种,雇主内部组建大模型团队,原地转型。
第一种情况下,人才的技术能力不一定覆盖大模型开发全周期,或许某一具体环节可独当一面,比如Instruction 指令微调,RLHF训练, Reward Model训练等等。
第一批的跳槽高峰早在三个月前就已经结束。
那些经历过的人说,谁不是脱一层皮呢?
刷Leedcode,投简历,接触猎头,一二三面,谈薪酬,打印收入流水,到岗,很费一番功夫。
创业公司招聘周期短,决策快,能较快到岗;互联网大厂的速度次之;而有些企业招聘程序冗长,比如AWS(不过面试官态度很好)。
“黄金”大多会面试一定数量的企业,甚至我听说有一个“卷王”一天面试高达7场。
面试了一堆公司,包括但不限于:
智谱华章,百川智能,澜舟科技,面壁智能,月之暗面,智源研究院,深言科技,爱诗科技,生数科技,衔远科技;
阿里,蚂蚁,百度,字节跳动,AWS,贝壳,网易伏羲,小红书。
为什么说有实战经验的人幸运?
大模型创业公司的需求急,竞争窗口期小。
没时间培养,先录用“已有大模型经验”。
俗称,来了就能干活。
三十年河东西,此前,大模型技术枯做板凳,有的企业抠门起来,恨不得一张卡都扣住不给大模型研发团队用。若没有ChatGPT,恐怕岗位和预算都保持不住。
一些营销号鼓吹“早有布局”“多年投入”,听的我直苦笑。
有点跑题,拉回主题。
后面,和HR大大们再来一番博弈。
辛辣式提问:“你目前手上几个Offer?”
有的大模型创业公司会有北京户口指标,画饼式提问:
“今年北京户口名额满了,明年可能轮到你。”
不出意外的话,意外就该来了。
猎头说,有估值靠前的创业公司的面试现场,候选人和面试官激烈争吵。
我的理解可能是因为大模型技术较为前沿,对同一个技术问题的认知和观点会不一样,面试官和候选人在面试问题的答案上有分歧实属正常,都不容易。
不过,一位多家公司Offer在手,原供职于小冰Research组的技术小哥哥也向我真诚吐露,他更喜欢文化包容的团队。
他还告诉我一件事情:
因为小冰管理扁平化,项目制,有时候无法提供绩效,他在面试时正欲解释,结果对方HR说:“你们小冰的情况,我们都比较清楚。”
可见已经面试了不少小冰的人。
相信大家也看出来了,为了这篇文章,谭老师我和不少跳槽技术同学大摆龙门阵,但薪酬信息较为敏感,也无法做大规模详尽调研。
情况大致是:
拿到30%涨幅者居多。也有互联网头部企业的资深算法去往大模型创业公司头部的一名同学,100%涨幅,只此一位,我暂时没有听说有更高涨幅。
假如你问我,文章标题提出的问题。
我的答案是:在黄金这个段位,并不是。
我做了一个对比。
先说结论:对比下来,大模型黄金段位涨幅并不出众。
我的对比参照物是此前阿里跳槽字节跳动那批人员的涨幅。
这里的此前是2022年底到2023年初。
一位前阿里云P9大佬告诉我:“参考在前一阵子从阿里跳槽字节跳动的那批人,涨幅30%。”
为此,我又找到其中一位已经入职字节跳动,原来供职于阿里云AIS(基础设施服务部)的技术小哥哥聊了聊。
他告诉我,字节跳动挖人的目标人群是其他互联网头部大厂的开发主力,基本涨薪在30%,只高不低。
我问:什么情况下会有高于30%的涨幅?
他答:“就算人力制度再健全,万人大厂也会有职级不能体现个人实力的情况。比如,也许入职时级别不高,但成长性强,又或者一直没有赶上好业绩或者好领导。经字节跳动入职资格审核认可后,涨幅会突破30%,大约在35-40%范围。”
这也算是,大家喜闻乐见的天道酬勤系列。
回到我们的主题,我的结论是黄金段位的大模型人才跳槽涨幅,没有超过头部互联网之间跳槽主力研发人员的薪酬涨幅。
当然,看法求同存异,欢迎补充, 欢迎文末留言。
在用人需求方面,武汉人工智能研究院院长王金桥博士告诉我:“大模型创业公司注重细节打磨,会有更多用人需求。”
我请他告诉我一个数字,他的答案是“百人规模”。
在“百人规模”这一点上,面壁智能商业化副总裁缪钧玮也表示同意。
他告诉我:“大模型创业公司打法讲究精兵强将,高端岗位的需求会持续旺盛,但是不倾向于把摊子铺得过大,和上一轮CV独角兽面对的算法碎片化场景的打法完全不同。这也是大模型通用性强的特点决定的,多个场景问题会被同一个大模型一举解决,工程量变小。”
在人才需求的流动上,他也给出了观点:“未来会出现高(牛)端(逼)客户自己微调的需求,黄金段位的人才会往客户技术团队自然流动。”
似乎当年“CV四小龙”商汤旷视依图的“千人研发规模”在大模型这个时代“盛况”不可能重现,而少数几家大模型头部创业公司规模也仍在壮大。
智谱华章成立较早,于2020年开始大模型业务研发与拓展,其团队规模相对较大,近期一位面试候选人告诉我:“当前团队规模在400人左右。”
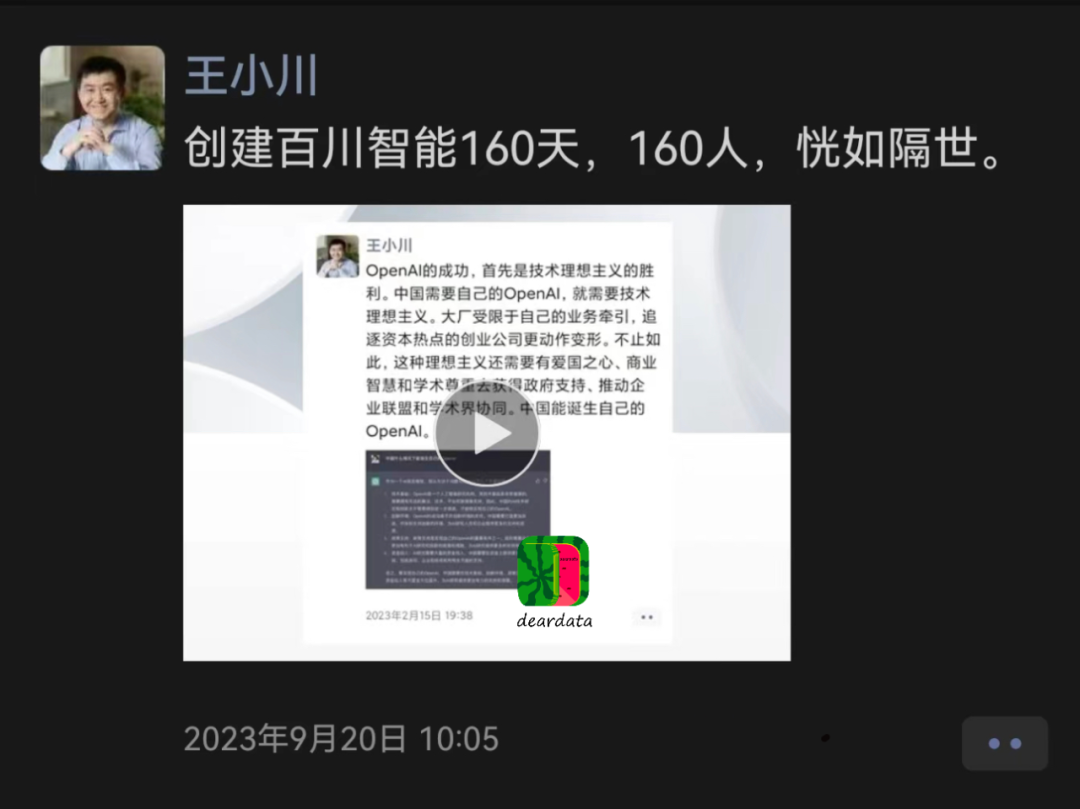
截止2023年9月20日,王小川微信朋友圈“秀出”160人团队规模,而第100位员工入职时间,仅在不久前的7月21日。
一位成功跳槽大厂的技术小哥哥告诉我,一家“中科”开头的老牌上市公司的HR和他商量:
“你可以在拿到所有的Offer之后,再来和我谈薪资。”HR似乎暗示可以出价比其他企业都高,拿出“最高竞价”策略来抢夺人才。
谭老师我一开始推想跳槽到知名创业公司,技术好,估值高,薪资慷慨。而实际观察到的是:这份慷慨似乎更倾向于留给“白金”。
在这一轮跳槽中,个别算法同学从知名公司平薪或者小幅降薪到生活宜居的二线城市。
结论是:
用人企业在人才满足职位要求的前提下,追求极致性价比。而且越是头部企业(互联网公司/大模型创业公司)越有谈判优势,将黄金段位薪酬磋商到最佳性价比。这也是这个章节小标题的由来。
第二种情况,原地转型。
有的公司研发人才储备扎实,鼓励员工原地转型。一方面公司用人成本不会增加,另一方面,技术人员也乐于跟上技术潮流。
另外,数据采集和清洗属于黄金段位。
一位朋友在求职过程中向我抱怨:“假如你想进入大厂,找工作的人又很多,根本不知道在三轮面试会出现什么幺蛾子,明星创业公司也不那么好进。”
对个体而言,如果不往“高精尖”的职级发展,你在大模型这一场人才的竞争当中,根本杀不出一条好路。
对公司而言,GPU卡买也好,租也好,要尽量多的算力,再尽量抢夺人才,赶在竞争对手之前,做出成熟有效的产品。多米诺骨牌会依次推到,时间成为最后的限制。
一位面试腾讯公司(CSIG)的候选人告诉我,面试官说了,年底出成果,不出成果,面试官自己都得走人。
怎么说呢?留给中国队的时间不多了。
(三)青铜:英雄不问出处

对于“青铜”来说,谭老师似乎没有带来好消息。
的确,这一轮,青铜段位普遍陷入焦虑。
大模型技术本来就难学,再加上大模型公司“精锐之师”的打法,入门和转行门槛比以往都高。
即使对于“原地转型”的人来说,上手难度也大。
前沿研究成果层出不穷,学习者大喊:“看不完,根本看不完”。
动手实现之时又有大量工程问题,大坑踩不完,根本踩不完。
“逼人退学”,动不动Bug拖很久解决不了,用来学习核心知识的时间精力被白白消耗了。
不仅入门难,进阶难度也高。
想摸索参数大一些的模型训练,非个人资源所能及。
别说个人,很多企业和研究机构都因为卡不够用需要排队,或者压根排不上。
而理解模型结构和熟悉大模型的技术,很多时候都需要算力的支撑,前线吃紧,哪有多余的“卡”给你练手和实验。
有位读者在周五下班的时候向我感慨:“终于到周末了,我又可以学习大模型了。”
可见压力是有,社区学习气氛也是高涨的。
用武汉人工智能研究院副院长张家俊博士的观点结束这次讨论:
“人才要升级,眼界要超前一些,卷基础模型可能是比较短暂的一个周期,毕竟基础模型难以直接产生收入,而且基础模型也就训练那么几个,更加重要的是如何将基础大模型发挥最大潜力:做出超级应用的人,将是下一波弄潮儿。”
要我说,允许100分的努力,只有60分的收获。
反正,也没有哪家公司是完美的。
大不了终身学习。
在谭老师看来,那些内心热爱技术的人,从哪里出发都可以奔赴山海。
(完)
带货ing
《我看见了风暴》谭老师新书,京东有售


更多阅读
AI大模型与ChatGPT系列:
1. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
4. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
5. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
8. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
9. 深聊第四范式陈雨强丨如何用AI大模型打开万亿规模传统软件市场?
10. 深聊京东科技何晓冬丨一场九年前的“出发”:奠基多模态,逐鹿大模型
11. 老店迎新客:向量数据库选型与押注中,没人告诉你的那些事
12. 抢滩大模型,抢单公有云,Databricks和Snowflake用了哪些“阳谋”?
13. 大模型“搅局”,数据湖,数据仓库,湖仓选型会先淘汰谁?
14. 微调真香,漫画科技博主竟然在用国产大模型生成系列漫画女主角
15. 美国大模型风向速报(一)为何重视提示工程?LangChain+向量数据库+开源大模型真香
16. AI咆哮后,一个赚大钱的AI+Data公司估值居然430亿美元?
AI大模型与学术论文系列:
1.开源“模仿”ChatGPT,居然效果行?UC伯克利论文,劝退,还是前进?
2. 深聊王金桥丨紫东太初:造一个国产大模型,需用多少篇高质量论文?(二)
3. 深聊张家俊丨 “紫东太初”大模型背后有哪些值得细读的论文(一)
漫画系列
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
11. 强化学习:人工智能下象棋,走一步,能看几步?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
AI框架系列:
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)仅收录于《我看见了风暴》。


数据库是今天社会发展不可缺少的重要技术,它可以把大量的信息进行有序的存储和管理,为企业的数据处理提供了强大的保障。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)