
AdaBoost算法(python实现)
AdaBoost自适应提升算法是boosting提升算法的一种集成学习算法,主要是应用弱分类器来组合构造强分类器
AdaBoost算法
1.基本概念
AdaBoost自适应提升算法是boosting提升算法的一种集成学习算法,主要是应用弱分类器来组合构造强分类器

训练流程:在训练数据集中的每个数据样本赋予一个权重,刚开始权重值都是相等的,用向量D来存储这些权重,首先在第一个弱分类器上训练训练集,并根据训练结果计算在该弱分类器上面的错误率 ε \varepsilon ε,根据分类错误情况对权重向量D进行更新,这个更新针对分类错误的样本数据权重提高,分类正确的样本数据的权重降低,然后根据权重向量对同样的训练集数据在另一个弱分类器进行训练,根据分类结果再同样计算更新权重向量。依次反复再各个弱分类器上进行训练。为了从所有弱分类器中得到最终分类结果,需要对每一个弱分类器赋予一个权重值 α \alpha α,这个权重值也基于弱分类器错误率进行运算的。
错误率计算公式
ε
=
分类错误的样本数
分类正确的样本数
(
1.1
)
\varepsilon=\frac{分类错误的样本数}{分类正确的样本数}\quad\quad\quad(1.1)
ε=分类正确的样本数分类错误的样本数(1.1)
最终预测结果
F
(
x
)
=
∑
i
=
1
m
α
i
f
(
x
)
(
1.2
)
F(x)=\sum_{i=1}^m\alpha_if(x)\quad\quad\quad(1.2)
F(x)=i=1∑mαif(x)(1.2)
其中
α
i
\alpha_i
αi为弱学习器的权重,
f
(
x
)
f(x)
f(x)是弱学习器分类后的结果。
在AdaBoost算法中的损失函数定义为指数损失函数
L
(
y
,
f
(
x
)
)
=
e
−
y
F
(
x
)
(
1.3
)
L(y,f(x))=e^{-yF(x)}\quad\quad\quad(1.3)
L(y,f(x))=e−yF(x)(1.3)
在第
m
m
m次的迭代过程中,前
m
−
1
m-1
m−1次的系数
α
m
−
1
\alpha_{m-1}
αm−1和弱学习器组合分类结果
F
m
−
1
(
x
)
F_{m-1}(x)
Fm−1(x)都是已知的,则
F
m
(
)
=
F_m()=
Fm()=
F
m
−
1
(
x
)
+
α
m
∗
f
m
(
x
)
F_{m-1}(x)+\alpha_m*f_m(x)
Fm−1(x)+αm∗fm(x),在第
m
m
m次迭代过程中,只需就
α
m
和
f
m
(
x
)
\alpha_m和f_m(x)
αm和fm(x)最小化损失函数
a
r
g
(
α
,
f
)
m
i
n
∑
i
=
1
m
e
−
y
i
f
m
(
x
i
)
=
a
r
g
(
α
,
f
)
m
i
n
∑
i
=
1
m
e
−
y
i
(
F
m
−
1
(
x
i
)
+
α
m
f
(
x
i
)
)
=
a
r
g
(
α
,
f
)
m
i
n
∑
i
=
1
m
e
−
y
i
∗
F
m
−
1
e
−
y
i
α
m
f
(
x
i
)
(
1.4
)
arg_{(\alpha,f)}min\sum_{i=1}^me^{-yif_m(x_i)}=arg_{(\alpha,f)}min\sum_{i=1}^me^{-y_i(F_{m-1}(x_i)+\alpha_m f(x_i))}\\=arg_{(\alpha,f)}min\sum_{i=1}^me^{-y_i*F_{m-1}}e^{-y_i\alpha_mf(x_i)}\quad\quad\quad(1.4)
arg(α,f)mini=1∑me−yifm(xi)=arg(α,f)mini=1∑me−yi(Fm−1(xi)+αmf(xi))=arg(α,f)mini=1∑me−yi∗Fm−1e−yiαmf(xi)(1.4)
对于上式中
e
−
y
i
∗
F
m
−
1
e^{-y_i*F_{m-1}}
e−yi∗Fm−1为常数,可以看作认为是每一个样本数据的权重D,它不依赖于
α
\alpha
α和
f
(
x
)
f(x)
f(x),依赖于
y
i
∗
F
m
−
1
y_i*F_{m-1}
yi∗Fm−1,所以在每个弱分类器训练结束后他都会发生改变。
将公式1.4进一步简化有
a
r
g
(
α
,
f
)
m
i
n
∑
i
=
1
m
D
i
(
m
)
e
−
y
i
α
m
f
(
x
i
)
=
a
r
g
(
α
,
f
)
m
i
n
e
−
α
∗
∑
y
i
=
f
(
x
i
)
D
i
(
m
−
1
)
+
e
α
∗
∑
y
i
≠
f
(
x
i
)
D
i
(
m
−
1
)
(
1.5
)
arg_{(\alpha,f)}min\sum_{i=1}^mD_i^{(m)}e^{-y_i\alpha_m f(x_i)}\\=arg_{(\alpha,f)}min\quad e^{-\alpha}*\sum_{y_i=f(x_i)}D_i^{(m-1)}+e^{\alpha}*\sum_{y_i\neq f(x_i)}D^{(m-1)}_i\quad(1.5)
arg(α,f)mini=1∑mDi(m)e−yiαmf(xi)=arg(α,f)mine−α∗yi=f(xi)∑Di(m−1)+eα∗yi=f(xi)∑Di(m−1)(1.5)
现在将目标函数转换为只含有变量
α
\alpha
α的函数,对上式求导并令其等于0
(
e
α
+
e
−
α
)
∗
∑
y
i
≠
f
(
x
i
)
D
i
(
m
−
1
)
−
e
α
∗
∑
i
=
1
)
m
D
i
(
m
−
1
)
=
0
=
>
(
e
α
+
e
−
α
)
∗
ε
−
e
α
=
0
=
>
α
=
1
2
l
n
1
−
ε
ε
(
1.6
)
(e^{\alpha}+e^{-\alpha})*\sum_{y_i\ne f(x_i)}D_i^{(m-1)}-e^{\alpha}*\sum_{i=1)}^mD_i^{(m-1)}=0\\=>(e^{\alpha}+e^{-\alpha})*\varepsilon-e^{\alpha}=0\\ =>\alpha=\frac{1}{2}ln\frac{1-\varepsilon}{\varepsilon}\quad\quad(1.6)
(eα+e−α)∗yi=f(xi)∑Di(m−1)−eα∗i=1)∑mDi(m−1)=0=>(eα+e−α)∗ε−eα=0=>α=21lnε1−ε(1.6)
得到第m个弱分类器权重
α
\alpha
α后,可以得出前m个弱分类器组合得到的分类结果
F
m
(
x
)
=
F
m
−
1
+
α
m
∗
f
(
x
)
F_m(x)=F_{m-1}+\alpha_m*f(x)
Fm(x)=Fm−1+αm∗f(x),同时可以对各个样本的权重进行更新
D
i
m
+
1
=
D
i
m
∗
e
−
y
i
α
m
f
(
x
i
)
D_i^{m+1}=D_i^{m}*e^{-y_i\alpha_mf(x_i)}
Dim+1=Dim∗e−yiαmf(xi)
训练算法伪代码:
初始化样本所有权重值相等
迭代每一个弱分类器
训练每一个弱分类器f(x),并计算出错误率
计算每个弱分类器的权重
更新所有的样本权重
结束循环
计算所有弱分类器组合后分类结果
2.使用AdaBoost算法对病马死亡率的预测
1.决策树生成函数
#导入科学计算包
from numpy import *
#设置简单数据集
#根据阈值比较对数据进行分类
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
"""
:param dataMatrix: 训练数据集
:param dimen: 阈值比较的下标
:param threshVal:
:param threshIneq: 比较方式
:return: 数据集根据选定特征值比较阈值分类后的结果矩阵
"""
#定义并初始化返回根据阈值分类后结果矩阵(mX1)
retArray = ones((shape(dataMatrix)[0], 1))
#比较方式为小于
if threshIneq == 'lt':
#特征值小于阈值的样本被分为-1类
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
#比较方式为大于
else:
#特征值大于阈值的样本被分为-1类
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
#找到数据集上最佳的单层决策树
def buildStump(dataArr, classLabels, D):
"""
:param dataArr:数据集
:param classLabels: 数据集标签
:param D: 权重向量
:return: 返回最佳决策树信息,最小错误率,最佳决策树分类结果
"""
#将数据集转换为矩阵(mXn)
dataMatrix = mat(dataArr);
#将标签转换为矩阵并且转置(1Xm)
labelMat = mat(classLabels).T
#获取数据集的样本个数和特征个数
m, n = shape(dataMatrix)
#自定义变量,用来计算阈值
numSteps = 10.0
#定义一个字典用来存储在给定权重向量D时所得到的最佳决策树的信息
bestStump = {}
#定义并初始化根据最佳特征阈值划分后的结果
bestClasEst = mat(zeros((m, 1)))
#定义最小错误率并初始化为无穷大
minError = inf
#遍历数据集中所有的特征
for i in range(n): # loop over all dimensions
#获取在数据集于i特征值中的最小值
rangeMin = dataMatrix[:, i].min()
# 获取在数据集于i特征值中的最大值
rangeMax = dataMatrix[:, i].max()
#自定义用于计算阈值的步长
stepSize = (rangeMax - rangeMin) / numSteps
#在数据集于i特征值中按步长为stepSize遍历
for j in range(-1, int(numSteps) + 1):
#分别按照大于和小于分类
for inequal in ['lt', 'gt']:
#设置阈值,自定义阈值计算公式:min+j*stepSize
threshVal = (rangeMin + float(j) * stepSize)
#基于特征值阈值来分类,并返回分类结果
predictedVals = stumpClassify(dataMatrix, i, threshVal,inequal)
#定义并初始化错误率矩阵
errArr = mat(ones((m, 1)))
#判断根据阈值分类后的结果与实际结果,若分类结果一致,定义错误率矩阵为0,否则不变
errArr[predictedVals == labelMat] = 0
#自定义计算错误加权率,公式为:所有样本权重向量*是否分类结果错误的和
weightedError = D.T * errArr
#如果加权错误率小于最小错误率
# print ("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
#更新最小错误率
minError = weightedError
#存储按照这种特征的阈值划分的结果
bestClasEst = predictedVals.copy()
#存储最佳决策树信息
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
2.AdaBoost训练算法
#导入科学计算包
from numpy import *
#导入决策数生成函数
import 单决策树生成函数 as algriothm
#AdaBoost元算法训练过程
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
"""
:param dataArr: 数据集
:param classLabels: 标签数据集
:param numIt: 迭代次数
:return:
"""
#定义弱分类器
weakClassArr = []
#获取训练集样本个数
m = shape(dataArr)[0]
#初始化权重向量
D = mat(ones((m,1))/m)
#
aggClassEst = mat(zeros((m,1)))
loss_list=list()
j=1
for i in range(numIt):
j+=1
#获取最佳决策树
bestStump,error,classEst =algriothm.buildStump(dataArr,classLabels,D)
#计算alpha,max()函数防止最小错误率为0的情况
alpha = float(0.5*log((1.0-error[0,0])/max([error[0,0],1e-16])))
#在最佳决策树中存储alpha
bestStump['alpha'] = alpha
#向弱分类器中添加最佳决策树
weakClassArr.append(bestStump)
#print "classEst: ",classEst.T
#对于分类正确计算按照exp(-alpha)重新计算权重向量,对于分类错误的按照exp(alpha)重新计算权重
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#对分类器分类结果加上权重
aggClassEst += alpha*classEst
#计算加上权重之后分类错误数
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print(errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst,j,loss_list
#测试
3.使用AdaBoost算法预测分类
#导入科学计算包
from numpy import *
#导入单决策树生成函数
import 单决策树生成函数 as algriothm
#导入单决策树训练过程
import 单决策树元算法的训练过程 as adaboost
#导入matplotlib绘图包
import matplotlib.pyplot as plt
#元算法分类函数
def adaClassify(dataTestClass,classifier):
#将待分类数据集转换为数组
dataMatrix=mat(dataTestClass)
#统计待分类数据样本数
m=shape(dataMatrix)[0]
#初始化分裂结果数组
aagClassEst=mat(zeros((m,1)))
loss_list=list()
#根据弱分类器对待分类数据集进行分类
for i in range(len(classifier)):
classEst=algriothm.stumpClassify(dataMatrix,classifier[i]['dim'],classifier[i]['thresh'],classifier[i]['ineq'])
aagClassEst+=classifier[i]['alpha']*classEst
return sign(aagClassEst)
#读取文件并且获取数据集
def loadDataSet(fileName):
#获取数据集特征数目
numFat=len(open(fileName).readline().split('\t'))
#定义数据集,分类标签数据集
dataMat=[]
label=[]
f=open(fileName)
#从每行处理文本文件
for line in f.readlines():
lineArr=[]
curLine=line.strip().split('\t')
for i in range(numFat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
label.append(float(curLine[-1]))
return dataMat,label
#测试
if __name__=='__main__':
dataMat,labelMat=loadDataSet("D:\学习资料\机器学习实战\《机器学习实战》源代码\machinelearninginaction\Ch07/horseColicTraining2.txt")
# print(labelMat)
classfier,classEst,j,loss_list=adaboost.adaBoostTrainDS(dataMat,labelMat,100)
testData,teatLabel=loadDataSet("D:\学习资料\机器学习实战\《机器学习实战》源代码\machinelearninginaction\Ch07/horseColicTest2.txt")
prob=adaClassify(testData,classfier)
errArr=mat(ones((67,1)))
print(f"预测错误率是{errArr[prob!=mat(teatLabel).T].sum()/67.0}")
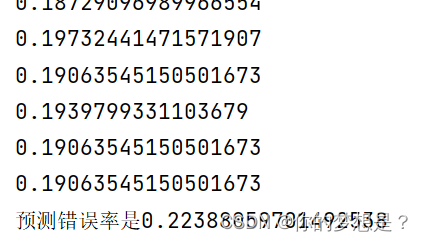
可以看到训练错误率是0.19,预测错误率是0.22,当然很大关系上在于数据集有30%的数据缺失,同时还有与迭代次数有很大关系。
3.总结
这里AdaBoost算法解决的是离散型AdaBoost算法,当然还有实数型AdaBoost算法,LogitBoost算法,Gentle型AdaBoost算法
参考博客:集成学习之Boosting —— AdaBoost原理 - 知乎 (zhihu.com)
参考书籍:《机器学习实战》

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)