嵩天《 python网络爬虫于信息提取》之最好大学的排名爬虫
前文:一个信安小趴菜,感觉爬虫挺重要的,也比较帅,最近学习Mooc的北京理工大学的嵩天老师的《python爬虫于信息爬取 ,老师讲的特别好,就是版本有点久远。之后会出关于老师讲解的练习实例。
·
前文:
一个信安小趴菜,感觉爬虫挺重要的,也比较帅,最近学习Mooc的北京理工大学的嵩天老师的《python爬虫于信息爬取 ,老师讲的特别好,就是版本有点久远。之后会出关于老师讲解的练习实例。
python 说明:爬虫练习仅为学习,不做商用,如有侵权,烦请联系删除!
练习一
最好大学网站排名爬取
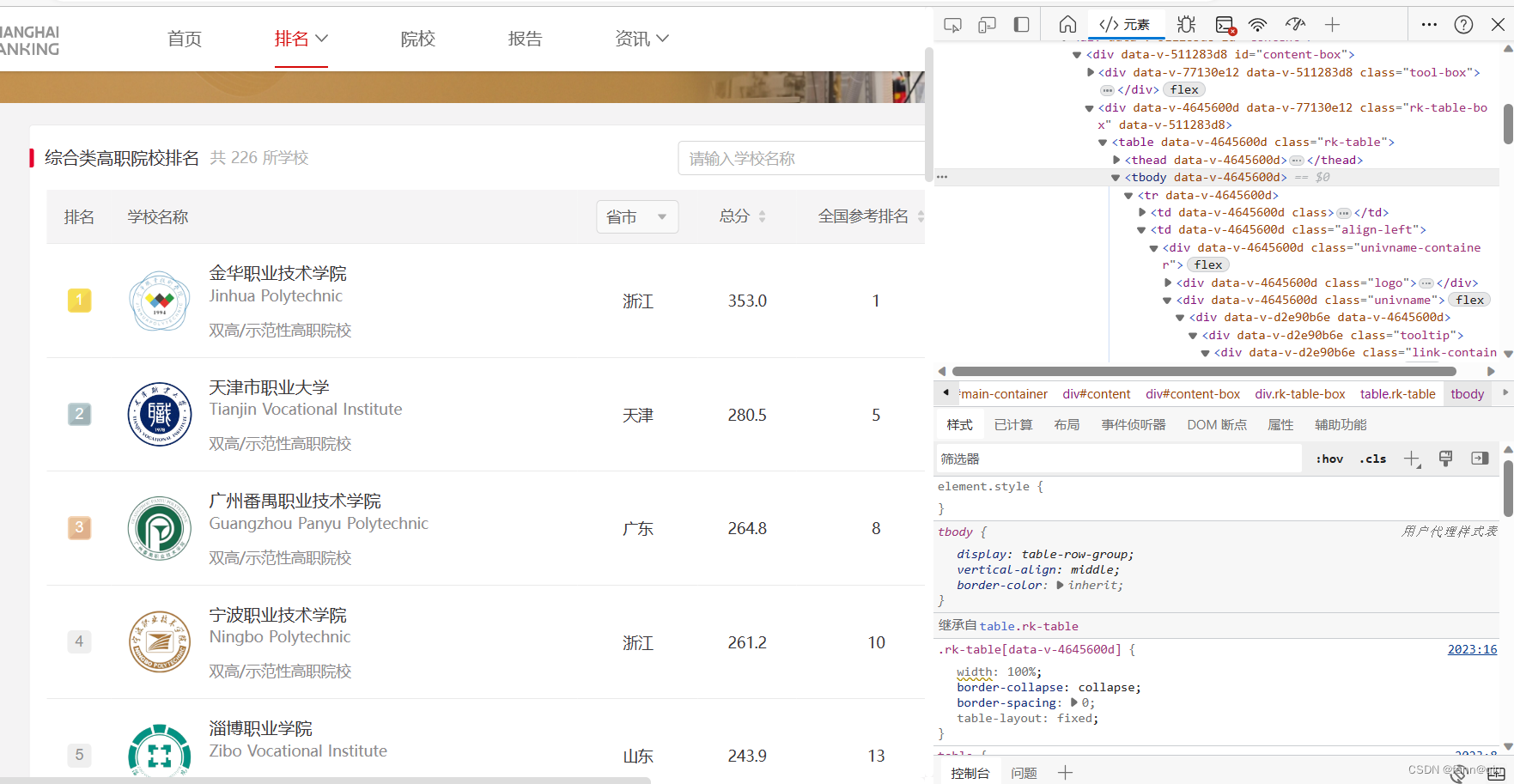
本次目标网站:https://www.shanghairanking.cn/rankings/bcvcr/2023
爬取目标:爬取上海软科官网提供的中国最好大学排名,并在IDLE页面打印输出大学名称、排名、省市、总分信息
相关库名:requests/BeautifulSoup/bs4
我们把本次实验分成三个部分,访问页面,分析页面并提取,打印出我们需要的信息
首先, 我们先引用库
import bs4
import requests
from bs4 import BeautifulSoup
我们把三个功能写出三个函数,然后写主函数
把进行程序的编写时,我们应完成整体框架,再进行补充,而不应该直接写代码
def main():
url='https://www.shanghairanking.cn/rankings/bcvcr/2023' ##这个是我们要访问的网站
ulist=[] ##这个是用来存储我们需要的信息的列表
html=gethtmltext(url)
jiexihtml(ulist,html)
printhtml(ulist,30) ##这三个函数我们用来进行程序
然后 我们开始编写我们第一个函数
def gethtmltext(url):
try: ##我们一般用 try ,except的结构来进行爬虫的框架
r=requests.get(url) ##这里面引用request.get的函数来进行获取网站的信息
r.raise_for_status() ##这个函数r.raise_for_status() 如果状态码非200 返回httpe异常,并转到except的语句中
r.encoding=r.apparent_encoding ##这个是将网页的编码格式换成从内容中分析出的响应内容格式
return r.text ##返回 页面的信息
except:
return '' ##这里是返回空
然后是我们第二个函数
我英文不咋好,之间用中文代替了
def jiexihtml(ulist,html): ##这里我们需要将存储的列表写进函数里 ,注意url已经经过第一个函数的转变,变成html
soup=BeautifulSoup(html,'html.parser') ##我们这里用BeautifulSoup做一锅汤,将传入的html,用html.parser的方法转换为html的格式
for tr in soup.find('tbody').children: ##我们这里首先找到tbody的标签,至于为什么看网页源码,然后我们用.chilren来访问它的下级标签,我们叫这个下级遍历
if isinstance(tr,bs4.element.Tag): ##这里是用来判断这个循环的tr是否是bs4的标签
tds = tr('td') ##然后赋值
a = tr('a','name-cn')
##由于是新版,所以把大学的名称给放进了a标签
ulist.append([tds[0].string.strip(), a[0].string.strip(), tds[2].text.strip(), tds[3].string.strip()])
##然后我们用string.strip 返回字符串,并删掉空格然后添加进列表,这里的tds[]里面的下标是你要打印的信息在哪里,从tbody开始数到你要找的信息的tr数
def printhtml(ulist,num): ##这里就是一些格式的打印
print("{:^10}\t{:^20}\t{:^28}\t{:^15}".format("排名", "区域", "学校", "总分"))
for i in range(num): ##这里表示你要打印多少学校的信息,我这里好像只能30个
u= ulist[i] ##这个是在列表里面循环你输入的学校数目
print("{:^10}\t{:^20}\t{:^20}\t{:^25}".format(u[0], u[1], u[2], u[3]))
最后完整代码
import bs4
import requests
from bs4 import BeautifulSoup
def gethtmltext(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ''
def jiexihtml(ulist,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
a = tr('a','name-cn')
ulist.append([tds[0].string.strip(), a[0].string.strip(), tds[2].text.strip(), tds[3].string.strip()])
def printhtml(ulist,num):
print("{:^10}\t{:^20}\t{:^28}\t{:^15}".format("排名", "区域", "学校", "总分"))
for i in range(num):
u= ulist[i]
print("{:^10}\t{:^20}\t{:^20}\t{:^25}".format(u[0], u[1], u[2], u[3]))
def main():
url='https://www.shanghairanking.cn/rankings/bcvcr/2023'
ulist=[]
html=gethtmltext(url)
jiexihtml(ulist,html)
printhtml(ulist,30)
if __name__ == "__main__":
main()
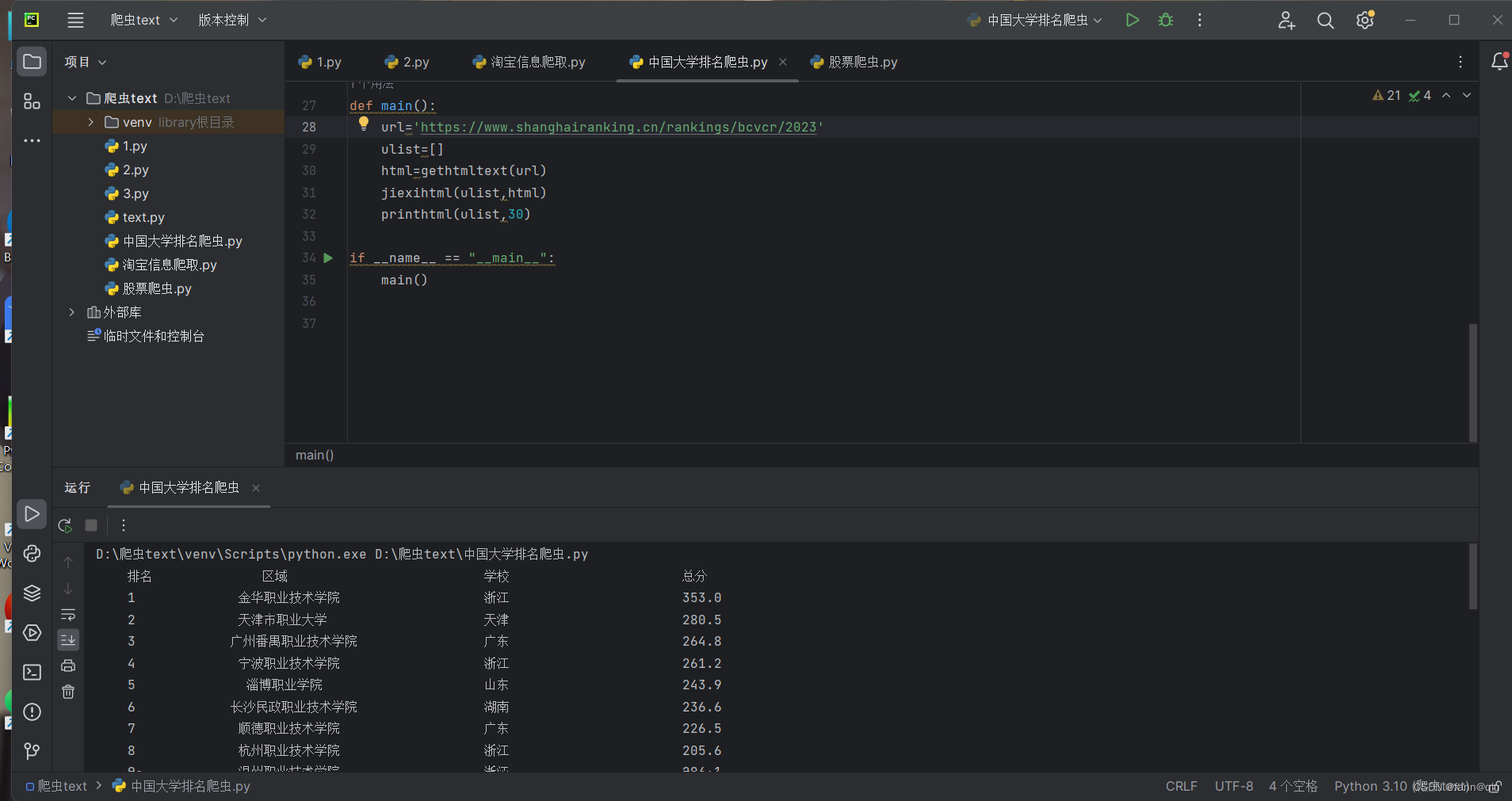
运行结果
刚学习爬虫的小白,大佬轻点喷!!!

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)