
支持向量机SVM代码详解——多分类/降维可视化/参数优化【python】
主要介绍数学建模以及大数据比赛中常用的SVM支持向量机模型算法,并使用python实现实例二分类、多分类、可视化以及参数优化。
篇1:SVM原理及多分类python代码实例讲解(鸢尾花数据)
SVM原理
支持向量机(Support Vector Machine,SVM),主要用于小样本下的二分类、多分类以及回归分析,是一种有监督学习的算法。基本思想是寻找一个超平面来对样本进行分割,把样本中的正例和反例用超平面分开,其原则是使正例和反例之间的间隔最大。
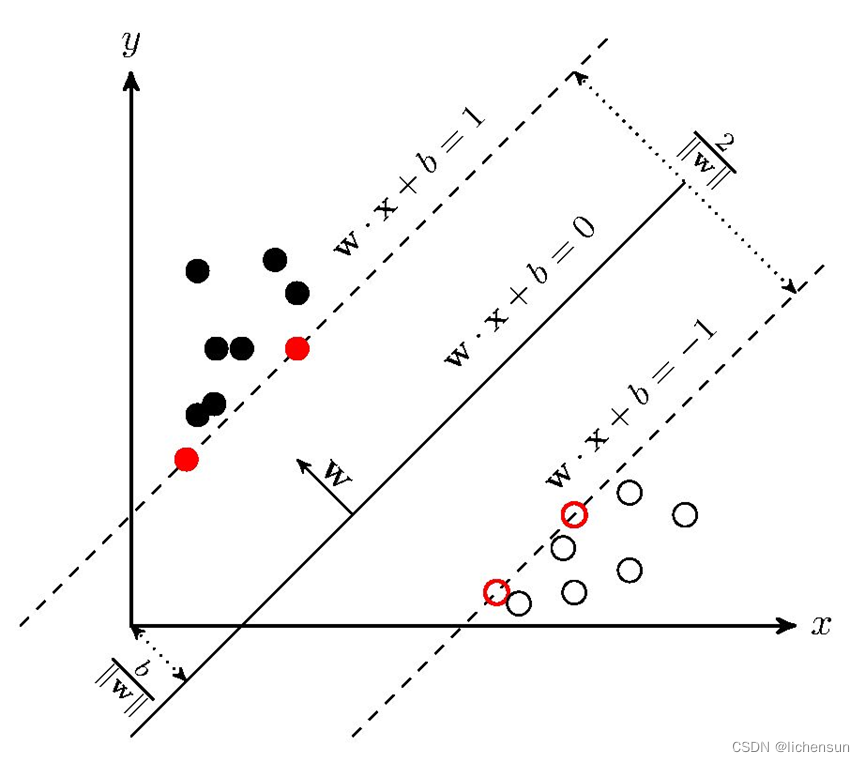
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示,wx+b=0即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
SVM实现分类代码
1.数据集介绍——鸢尾花数据集
下载方式:通过UCI Machine Learning Repository下载或者直接使用代码
from sklearn.datasets import load_iris
数据展示与介绍(iris.data)
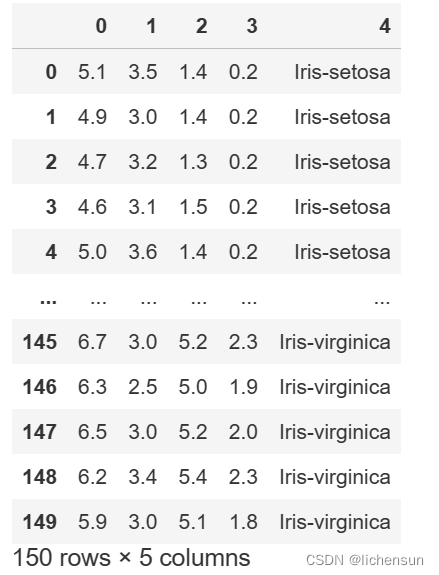
Iris.data中有5个属性,包括4个预测属性(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和1个类别属性(Iris-setosa、Iris-versicolor、Iris-virginica三种类别)。首先,需要将第五列类别信息转换为数字,再选择输入数据和标签。
2.多分类python代码(二分类可看做只有两类的多分类)
from sklearn import svm #引入svm包
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.model_selection import train_test_split
#定义字典,将字符与数字对应起来
def Iris_label(s):
it={b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2}
return it[s]
#读取数据,利用np.loadtxt()读取text中的数据
path='iris.data' #将下载的原始数据放到项目文件夹,即可不用写路径
data= np.loadtxt(path, dtype=float, delimiter=',', converters={4:Iris_label}) #分隔符为‘,'
#确定输入和输出
x,y=np.split(data,(4,),axis=1) #将data按前4列返回给x作为输入,最后1列给y作为标签值
x=x[:,0:2] #取x的前2列作为svm的输入,为了便于可视化展示
#划分数据集和标签:利用sklearn中的train_test_split对原始数据集进行划分,本实验中训练集和测试集的比例为7:3。
train_data,test_data,train_label,test_label=train_test_split(x,y,random_state=1,train_size=0.7,test_size=0.3)
#创建svm分类器并进行训练:首先,利用sklearn中的SVC()创建分类器对象,其中常用的参数有C(惩罚力度)、kernel(核函数)、gamma(核函数的参数设置)、decision_function_shape(因变量的形式),再利用fit()用训练数据拟合分类器模型。
'''C越大代表惩罚程度越大,越不能容忍有点集交错的问题,但有可能会过拟合(defaul C=1);
kernel常规的有‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ,默认的是rbf;
gamma是核函数为‘rbf’, ‘poly’ 和 ‘sigmoid’时的参数设置,其值越小,分类界面越连续,其值越大,分类界面越“散”,分类效果越好,但有可能会过拟合,默认的是特征个数的倒数;
decision_function_shape='ovr'时,为one v rest(一对多),即一个类别与其他类别进行划分,等于'ovo'时,为one v one(一对一),即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
'''
model=svm.SVC(C=2,kernel='rbf',gamma=10,decision_function_shape='ovo')
model.fit(train_data,train_label.ravel()) #ravel函数在降维时默认是行序优先
#利用classifier.score()分别计算训练集和测试集的准确率。
train_score = model.score(train_data,train_label)
print("训练集:",train_score)
test_score = model.score(test_data,test_label)
print("测试集:",test_score)
#决策函数的查看(可省略)
#print('train_decision_function:\n',model.decision_function(train_data))#(90,3)
输出结果:

分类结果的可视化(由于只选取了2个维度的输入数据,所以可视化可直接进行二维平面作图)
#训练集和测试集的预测结果
trainPredict = (model.predict(train_data).reshape(-1, 1))
testPredict = model.predict(test_data).reshape(-1, 1)
#将预测结果进行展示,首先画出预测点,再画出分类界面
#预测点的画法,可参考https://zhuanlan.zhihu.com/p/81006952
#画图例和点集
x1_min,x1_max=x[:,0].min(),x[:,0].max() #x轴范围
x2_min,x2_max=x[:,1].min(),x[:,1].max() #y轴范围
matplotlib.rcParams['font.sans-serif']=['SimHei'] #指定默认字体
cm_dark=matplotlib.colors.ListedColormap(['g','r','b']) #设置点集颜色格式
cm_light=matplotlib.colors.ListedColormap(['#A0FFA0','#FFA0A0','#A0A0FF']) #设置边界颜色
plt.xlabel('length',fontsize=13) #x轴标注
plt.ylabel('width',fontsize=13) #y轴标注
plt.xlim(x1_min,x1_max) #x轴范围
plt.ylim(x2_min,x2_max) #y轴范围
plt.title('SVM result') #标题
plt.scatter(x[:,0],x[:,1],c=y[:,0],s=30,cmap=cm_dark) #画出测试点
plt.scatter(test_data[:,0],test_data[:,1],c=test_label[:,0],s=30,edgecolors='k',zorder=2,cmap=cm_dark) #画出预测点,并将预测点圈出
#画分类界面
x1,x2=np.mgrid[x1_min:x1_max:200j,x2_min:x2_max:200j]#生成网络采样点
grid_test=np.stack((x1.flat,x2.flat),axis=1)#测试点
grid_hat=model.predict(grid_test)# 预测分类值
grid_hat=grid_hat.reshape(x1.shape)# 使之与输入的形状相同
plt.pcolormesh(x1,x2,grid_hat,cmap=cm_light)# 预测值的显示
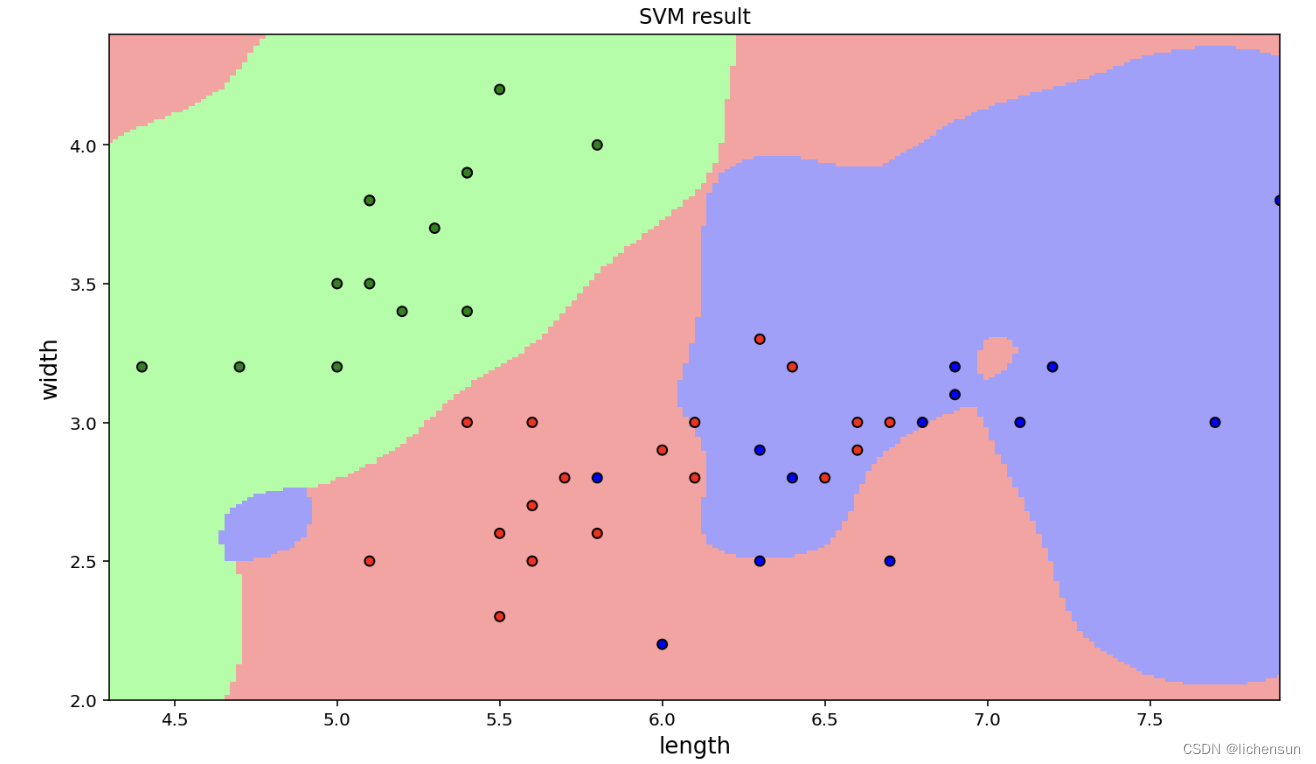
plt.show()可视化绘图结果:
根据结果,发现分类的效果并不好。接着,将输入鸢尾花的所有特征进行训练,并将分类结果降维后可视化展示。
篇2:SVM实现高维数据多分类及其可视化
多维特征svm的python代码实现
多特征的SVM代码实现只需要将前述代码中的
#x=x[:,0:2] #取x的前2列作为svm的输入,为了便于可视化展示此句注释掉即可
训练输出结果如下:

由于全部的特征共有四个维度,不方便直接进行可视化展示,所以需要利用PCA降维后再绘制可视化图。
PCA——主成分分析法
PCA设法将原来众多具有一定相关性的属性(比如p个属性),重新组合成一组相互无关的综合属性来代替原属性。通常数学上的处理就是将原来p个属性做线性组合,作为新的综合属性。
PCA 中的线性变换等价于坐标变换,变换的目的是使n个样本点在新坐标轴 y 1上的离散程度(方差)最大,这样变量 y 1就代表了原始数据的绝大部分信息,即使忽略 y 2也无损大局,从而把两个指标压缩成一个指标。从几何上看,找主成分的问题就是找出 N 维空间中椭球体的主轴问题。从数学上也可以证明,它们分别是相关矩阵的 k 个较大的特征值所对应的特征向量。
Python实现代码
#pca降维
#直接使用sklearn中的PCA进行降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(x)
xx=pca.transform(x) # 降维后的结果
train_data_2,test_data_2,train_label_2,test_label_2=train_test_split(xx,y,random_state=1,train_size=0.7,test_size=0.3)#降维后的测试集划分降维后的分类训练结果可视化展示
#训练集和测试集的预测结果
trainPredict = (model.predict(train_data).reshape(-1, 1))
testPredict = model.predict(test_data).reshape(-1, 1)
#将预测结果进行展示,首先画出预测点,再画出分类界面
#预测点的画法,可参考https://zhuanlan.zhihu.com/p/81006952
#画图例和点集
xx1_min,xx1_max=xx[:,0].min(),xx[:,0].max() #x轴范围
xx2_min,xx2_max=xx[:,1].min(),xx[:,1].max() #y轴范围
matplotlib.rcParams['font.sans-serif']=['SimHei'] #指定默认字体
cm_dark=matplotlib.colors.ListedColormap(['g','r','b']) #设置点集颜色格式
cm_light=matplotlib.colors.ListedColormap(['#A0FFA0','#FFA0A0','#A0A0FF']) #设置边界颜色
plt.xlabel('fea1',fontsize=13) #x轴标注
plt.ylabel('fea2',fontsize=13) #y轴标注
plt.xlim(xx1_min,xx1_max) #x轴范围
plt.ylim(xx2_min,xx2_max) #y轴范围
plt.title('SVM result') #标题
plt.scatter(xx[:,0],xx[:,1],c=y[:,0],s=30,cmap=cm_dark) #画出测试点
plt.scatter(test_data_2[:,0],test_data_2[:,1],c=testPredict[:,0],s=80,edgecolors='k',marker='+',zorder=2,cmap=cm_dark) #画出测试点,并将预测点圈出(注意这里是测试集的预测标签值)
plt.show()输出结果
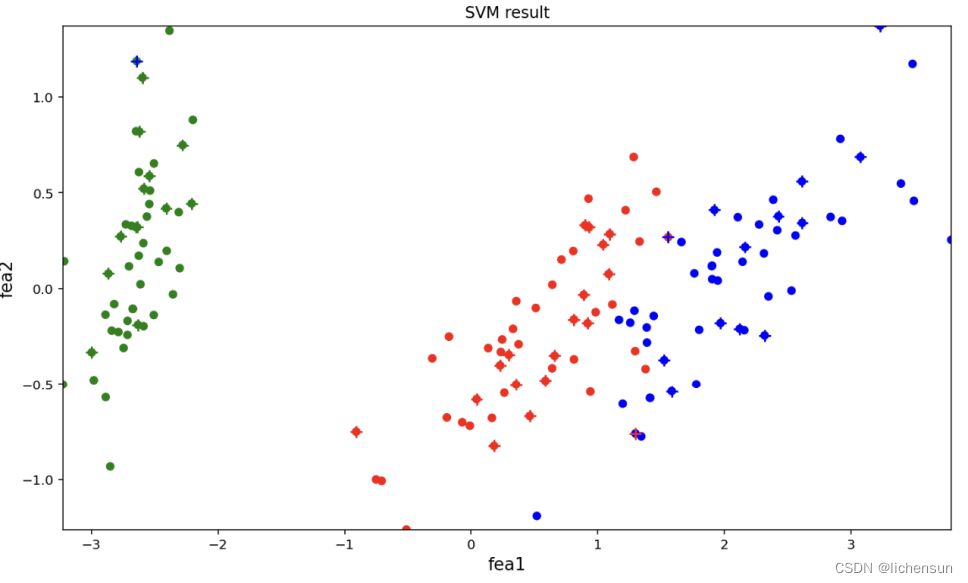
这里由于分类界面降维后难以直观展示,所以采用预测值和实际值点来展示分类效果。
其中,绿、红、蓝三种颜色代表花的三个品种,横纵坐标为pca降维后的两个特征维度,没有实际意义。圆点指真实分类,包含训练集和测试集。“+”形状的点为模型输出的预测值,仅含测试集。
从图中可以看出,降维后三类花的分布具有明显的聚类特性,而绝大多数测试集预测值都与真实值重合(即同颜色的圆点与十字形状重合),仅有少量样本出现预测误差。
总代码
from sklearn import svm #引入svm包
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.model_selection import train_test_split
#定义字典,将字符与数字对应起来
def Iris_label(s):
it={b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2}
return it[s]
#读取数据,利用np.loadtxt()读取text中的数据
path='iris.data' #将下载的原始数据放到项目文件夹,即可不用写路径
data= np.loadtxt(path, dtype=float, delimiter=',', converters={4:Iris_label}) #分隔符为‘,'
#确定输入和输出
x,y=np.split(data,(4,),axis=1) #将data按前4列返回给x作为输入,最后1列给y作为标签值
#划分数据集和标签:利用sklearn中的train_test_split对原始数据集进行划分,本实验中训练集和测试集的比例为7:3。
train_data,test_data,train_label,test_label=train_test_split(x,y,random_state=1,train_size=0.7,test_size=0.3)
#创建svm分类器并进行训练:首先,利用sklearn中的SVC()创建分类器对象,其中常用的参数有C(惩罚力度)、kernel(核函数)、gamma(核函数的参数设置)、decision_function_shape(因变量的形式),再利用fit()用训练数据拟合分类器模型。
'''C越大代表惩罚程度越大,越不能容忍有点集交错的问题,但有可能会过拟合(defaul C=1);
kernel常规的有‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ,默认的是rbf;
gamma是核函数为‘rbf’, ‘poly’ 和 ‘sigmoid’时的参数设置,其值越小,分类界面越连续,其值越大,分类界面越“散”,分类效果越好,但有可能会过拟合,默认的是特征个数的倒数;
decision_function_shape='ovr'时,为one v rest(一对多),即一个类别与其他类别进行划分,等于'ovo'时,为one v one(一对一),即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
'''
model=svm.SVC(C=2,kernel='rbf',gamma=10,decision_function_shape='ovo')
model.fit(train_data,train_label.ravel()) #ravel函数在降维时默认是行序优先
#利用classifier.score()分别计算训练集和测试集的准确率。
train_score = model.score(train_data,train_label)
print("训练集:",train_score)
test_score = model.score(test_data,test_label)
print("测试集:",test_score)
#决策函数的查看(可省略)
#print('train_decision_function:\n',model.decision_function(train_data))#(90,3)
#pca降维
#直接使用sklearn中的PCA进行降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(x)
xx=pca.transform(x) # 降维后的结果
train_data_2,test_data_2,train_label_2,test_label_2=train_test_split(xx,y,random_state=1,train_size=0.7,test_size=0.3)#降维后的测试集划分
#训练集和测试集的预测结果
trainPredict = (model.predict(train_data).reshape(-1, 1))
testPredict = model.predict(test_data).reshape(-1, 1)
#将预测结果进行展示,首先画出预测点,再画出分类界面
#预测点的画法,可参考https://zhuanlan.zhihu.com/p/81006952
#画图例和点集
xx1_min,xx1_max=xx[:,0].min(),xx[:,0].max() #x轴范围
xx2_min,xx2_max=xx[:,1].min(),xx[:,1].max() #y轴范围
matplotlib.rcParams['font.sans-serif']=['SimHei'] #指定默认字体
cm_dark=matplotlib.colors.ListedColormap(['g','r','b']) #设置点集颜色格式
cm_light=matplotlib.colors.ListedColormap(['#A0FFA0','#FFA0A0','#A0A0FF']) #设置边界颜色
plt.xlabel('fea1',fontsize=13) #x轴标注
plt.ylabel('fea2',fontsize=13) #y轴标注
plt.xlim(xx1_min,xx1_max) #x轴范围
plt.ylim(xx2_min,xx2_max) #y轴范围
plt.title('SVM result') #标题
plt.scatter(xx[:,0],xx[:,1],c=y[:,0],s=30,cmap=cm_dark) #画出测试点
plt.scatter(test_data_2[:,0],test_data_2[:,1],c=testPredict[:,0],s=80,edgecolors='k',marker='+',zorder=2,cmap=cm_dark) #画出测试点,并将预测点圈出(注意这里是测试集的预测标签值)
plt.show()
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 61
61 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)