
【翻译】分布式系统
介绍我希望有一本文本能够汇集许多最新分布式系统背后的理念 - 例如亚马逊的Dynamo, 谷歌的BigTable和MapReduce, Apache的Hadoop等等。在这段文字中,我试图提供一个更易理解的分布式系统简介。对我来说,这意味着两件事情:介绍你需要了解的关键概念,以便在阅读更深入的文本时能够愉快度过,同时提供一个涵盖足够详细内容的叙述,以便你能够大致理解发生的事情,而不会陷入...
原文链接:Distributed systems
介绍
我希望有一本文本能够汇集许多最新分布式系统背后的理念 - 例如亚马逊的Dynamo, 谷歌的BigTable和MapReduce, Apache的Hadoop等等。
在这段文字中,我试图提供一个更易理解的分布式系统简介。对我来说,这意味着两件事情:介绍你需要了解的关键概念,以便在阅读更深入的文本时能够愉快度过,同时提供一个涵盖足够详细内容的叙述,以便你能够大致理解发生的事情,而不会陷入细节之中。现在是2013年,你拥有互联网,可以选择性地阅读你最感兴趣的主题。
在我看来,分布式编程的很大一部分是处理分布的两个后果的影响:
- 信息以光速传播
- 独立的事物独立失败
换句话说,分布式编程的核心是处理距离(嗯!)和拥有多个事物(嗯!)。这些约束条件定义了可能的系统设计空间,我希望在阅读完本文后,你能更好地理解距离、时间和一致性模型的相互作用。
这段文字专注于分布式编程和系统概念,这些是您需要了解数据中心中商业系统所需的。试图覆盖所有内容是不可能的。您将学习到许多关键的协议和算法(例如,涵盖了该学科中最常引用的论文之一),包括一些新的令人兴奋的方式来看待最终一致性,这些方式尚未被收录到大学教材中,例如 CRDTs 和 CALM 定理。
我希望你喜欢它!如果你想说谢谢,请在Github(或者 Twitter)上关注我。如果你发现错误,请在Github上提交一个拉取请求。
1. 基础
第一章概述了分布式系统的高层次内容,介绍了一些重要的术语和概念。它涵盖了高层次的目标,如可扩展性、可用性、性能、延迟和容错性;以及这些目标是如何难以实现的,以及抽象和模型以及分区和复制是如何发挥作用的。
2. 抽象层次的上下
第二章深入探讨抽象和不可能性结果。它以尼采的一句名言开头,然后介绍了系统模型以及在典型系统模型中所做的许多假设。然后讨论了CAP定理并总结了FLP不可能性结果。然后转向CAP定理的含义之一,即人们应该探索其他一致性模型。随后讨论了一些一致性模型。
3. 时间和顺序
理解分布式系统的一个重要部分是理解时间和顺序。在我们无法理解和建模时间的程度上,我们的系统将会失败。第三章讨论了时间和顺序,以及时钟和时间、顺序和时钟的各种用途(例如向量时钟和故障检测器)。
4. 复制:防止分歧
第四章介绍了复制问题,并介绍了两种基本的执行方法。事实证明,大部分相关特性都可以用这个简单的描述来讨论。然后,从最不容错的方法(2PC)到Paxos,讨论了用于维护单一副本一致性的复制方法。
5. 复制:接受分歧
第五章讨论了具有弱一致性保证的复制。它介绍了一个基本的协调场景,其中分区副本尝试达成一致。然后,它讨论了亚马逊的Dynamo作为一个具有弱一致性保证的系统设计的例子。最后,讨论了两种关于无序编程的观点:CRDTs和CALM定理。
附录
附录包括了进一步阅读的建议。
*:这是一个谎言。Jay Kreps 的这篇文章详细阐述了。
1. 高级别的分布式系统
分布式编程是使用多台计算机解决可以在一台计算机上解决的相同问题的艺术。
任何计算机系统都需要完成两个基本任务:
- 存储和
- 计算
分布式编程是通过多台计算机解决在单台计算机上可以解决的同一问题的艺术 - 通常是因为该问题不再适合单台计算机。
没有真正要求您使用分布式系统。如果有无限的资金和无限的研发时间,我们将不需要分布式系统。所有的计算和存储都可以在一个神奇的盒子上完成 - 一个单一的、极其快速和极其可靠的系统 您付给别人设计的。
然而,很少有人拥有无限的资源。因此,他们必须在一些现实世界的成本效益曲线上找到合适的位置。在小规模上,升级硬件是一种可行的策略。然而,随着问题规模的增加,你会达到一个点,要么不存在能够在单个节点上解决问题的硬件升级,要么升级硬件的成本太高。在那时,欢迎来到分布式系统的世界。
目前的现实是,最好的价值在于中档,商品化的硬件 - 只要通过容错软件保持维护成本的降低。
计算机主要受益于高端硬件,可以通过替换慢速网络访问来进行内存访问。在需要节点之间大量通信的任务中,高端硬件的性能优势有限。

正如上图所示,来自Barroso, Clidaras和Hölzle的数据显示,假设在所有节点上存在均匀的内存访问模式,高端硬件和普通硬件之间的性能差距会随着集群规模的增加而减小。
理想情况下,添加一台新机器将线性增加系统的性能和容量。但当然这是不可能的,因为由于有独立的计算机,会产生一些开销。数据需要在计算机之间复制,计算任务需要协调等等。这就是为什么研究分布式算法是值得的 - 它们提供了针对特定问题的高效解决方案,以及关于什么是可能的,正确实现的最低成本是多少以及什么是不可能的指导。
这段文字的重点是分布式编程和系统,它们发生在一个平凡但商业相关的环境中:数据中心。例如,我不会讨论由于具有奇特网络配置而产生的专门问题,或者在共享内存环境中产生的问题。此外,重点是探索系统设计空间,而不是优化任何特定设计 - 后者是一个更专门的主题。
我们想要实现的目标:可扩展性和其他好的东西
我认为,一切都始于需要处理尺寸。
大多数事物在小规模时是琐碎的 - 但是一旦你超过一定的规模、体积或其他物理限制,同样的问题就会变得更加困难。举起一块巧克力很容易,举起一座山很难。数一下房间里有多少人很容易,数一下国家里有多少人很难。
所以一切都始于尺寸 - 可伸缩性。简单来说,在一个可伸缩的系统中,当我们从小到大进行移动时,事物不应该逐渐变得更糟。以下是另一个定义:
是指系统、网络或流程处理不断增长的工作量的能力,以及它能够扩大以适应这种增长的能力。
是什么在增长?嗯,你可以用几乎任何衡量标准来衡量增长(人数、电力使用等)。但有三件特别有趣的事情值得关注:
- 大小可扩展性:增加更多节点应该使系统线性加快;增加数据集不应增加延迟
- 地理可扩展性:应该能够使用多个数据中心来减少响应用户查询所需的时间,同时以某种明智的方式处理跨数据中心的延迟。
- 管理可扩展性:增加更多节点不应增加系统的管理成本(例如,管理员与机器的比率)。
当然,在真实的系统中,增长是同时在多个不同的方向上发生的;每个指标只能捕捉到增长的某些方面。
可扩展系统是指随着规模的增长,能够继续满足用户需求的系统。有两个特别相关的方面 - 性能和可用性 - 可以通过多种方式来衡量。
性能(和延迟)
是指计算机系统在使用的时间和资源相比所完成的有用工作的量。
根据上下文,这可能涉及实现以下一个或多个目标:
- 对于给定的工作,响应时间短/延迟低
- 高吞吐量(处理工作的速率)
- 计算资源利用率低
优化任何一种结果都会涉及权衡。例如,一个系统可以通过处理更大的工作批次来实现更高的吞吐量,从而减少操作开销。这种权衡会导致单个工作项的响应时间变长,因为需要进行批处理。
我发现低延迟 - 实现短响应时间 - 是性能中最有趣的方面,因为它与物理(而不是财务)限制有着紧密的联系。使用财务资源来解决延迟问题比解决性能的其他方面更困难。
有很多非常具体的关于延迟的定义,但我非常喜欢这个词的词源所唤起的理念:
延迟
潜伏状态; 延迟,即某事物开始和发生之间的时间段。
而“latent”是什么意思呢?
潜在的
源自拉丁语 latens, latentis, lateo 的现在分词形式,表示“隐藏”。存在或出现但是被隐藏或处于不活动状态。
这个定义非常棒,因为它强调了延迟实际上是某件事情发生和产生影响或变得可见之间的时间。
例如,想象一下,你被一种空气传播的病毒感染,这种病毒会将人们变成僵尸。潜伏期是指从你被感染到变成僵尸之间的时间。这就是潜伏期:已经发生的事情在这段时间内被隐藏起来。
让我们暂时假设我们的分布式系统只执行一个高级任务:给定一个查询,它将获取系统中的所有数据并计算出一个单一的结果。换句话说,将分布式系统视为一个具有能力在其当前内容上运行单一确定性计算(函数)的数据存储:
result = 查询(系统中的所有数据)
然后,对于延迟而言,重要的不是旧数据的数量,而是新数据在系统中“生效”的速度。例如,延迟可以通过写入数据后多长时间才能对读取者可见来进行衡量。
根据这个定义,另一个关键点是,如果没有任何事件发生,就没有"潜伏期"。数据不发生变化的系统不应该有延迟问题。
在一个分布式系统中,存在无法克服的最小延迟:光的速度限制了信息传输的速度,硬件组件每个操作都有一个最小延迟成本(例如内存和硬盘,还有 CPU)。
最小延迟对您的查询产生的影响取决于这些查询的性质以及信息需要传输的物理距离。
可用性(以及容错性)
可扩展系统的第二个方面是可用性。
系统处于正常运行状态的时间比例。如果用户无法访问该系统,则称其为不可用。
分布式系统使我们能够实现单个系统难以实现的理想特性。例如,单个机器无法容忍任何故障,因为它要么失败,要么不失败。
分布式系统可以利用一堆不可靠的组件,在其之上构建一个可靠的系统。
没有冗余的系统只能与其基础组件一样可用。具有冗余的系统可以容忍部分故障,因此更可用。值得注意的是,“冗余”可以根据你的观察角度而有不同的含义 - 组件、服务器、数据中心等等。
从公式上来说,可用性是:可用性 = 正常运行时间 / (正常运行时间 + 停机时间)。
从技术角度来看,可用性主要是指容错性。因为组件数量增加,故障发生的概率也增加,系统应该能够进行补偿,以保证在组件数量增加时不会变得不可靠。
举个例子:
| 可用性 % | 每年允许的停机时间有多少? |
| 90%("一个九") | 超过一个月 |
| 99%("两个九") | 少于4天 |
| 99.9%("三个九") | 少于9小时 |
| 99.99%("四个九") | 少于一小时 |
| 99.999%("五个九") | 约5分钟 |
| 99.9999%("六个九") | 约31秒 |
可用性在某种意义上比正常运行时间更广泛,因为服务的可用性还可能受到网络故障或拥有该服务的公司破产等因素的影响(这些因素与容错能力无关,但仍会影响系统的可用性)。但是,如果不了解系统的每一个具体方面,我们所能做的就是为容错设计。
何为容错性?
容错性
系统在发生故障后以明确定义的方式运行的能力
容错性归结为以下几点:定义您期望的故障,然后设计一种能够容忍这些故障的系统或算法。您无法容忍您未考虑过的故障。
什么阻止我们实现好事?
分布式系统受两个物理因素的限制:
- 节点的数量(随所需的存储和计算能力而增加)
- 节点之间的距离(信息传输的速度在最佳情况下是光速)
在这些限制下工作:
- 独立节点数量的增加会增加系统故障的概率(降低可用性和增加管理成本)
- 独立节点数量的增加可能会增加节点间的通信需求(随着规模的增加降低性能)
- 地理距离的增加会增加远程节点之间的最小延迟(对某些操作降低性能)
除了这些倾向 - 这些倾向是物理限制的结果 - 还有系统设计选项的世界。
性能和可用性都由系统提供的外部保证来定义。在高层次上,您可以将这些保证视为系统的服务级别协议(SLA):如果我写入数据,我可以多快地在其他地方访问它?在数据写入之后,我对持久性有什么保证?如果我要求系统运行计算,它会多快返回结果?当组件发生故障或停止运行时,这对系统会有什么影响?
还有另一个标准,虽然没有明确提到但是隐含其中:可理解性。所做的保证有多容易理解呢?当然,对于什么是可理解的,没有简单的衡量标准。
我有点想把“可理解性”归类为物理限制。毕竟,对于我们这些人来说,理解涉及比我们的手指更多移动物体的任何事情都很困难。这就是错误和异常之间的区别-错误是不正确的行为,而异常是意外的行为。如果你更聪明,你会预料到异常的发生。
抽象与模型
这就是抽象和模型发挥作用的地方。通过去除与解决问题无关的现实世界方面,抽象使事物更易于管理。模型以精确的方式描述了分布式系统的关键属性。在下一章中,我将讨论许多种模型,例如:
- 系统模型(异步/同步)
- 故障模型(崩溃故障,分区,拜占庭)
- 一致性模型(强一致性,最终一致性)
一个良好的抽象使得使用系统更容易理解,同时捕捉到与特定目的相关的因素。
存在一个紧张关系,即存在许多节点与我们渴望“像一个单一系统一样工作”的系统之间的现实。通常,最熟悉的模型(例如,在分布式系统上实现共享内存抽象)过于昂贵。
一个提供较弱保证的系统具有更大的行动自由,因此潜在的性能更高 - 但这也可能难以推理。人们更擅长推理像单个系统一样工作的系统,而不是节点的集合。
一个常见的做法是通过暴露系统内部的更多细节来提高性能。例如,在列存储中,用户可以(在某种程度上)推断系统内部键值对的局部性,并因此做出影响典型查询性能的决策。隐藏这些细节的系统更容易理解(因为它们更像单个单元,需要考虑的细节更少),而暴露更多真实世界细节的系统可能更具性能(因为它们更接近现实)。
写作分布式系统,使其表现得像一个单一系统一样,有几种类型的故障是困难的。网络延迟和网络分区(例如某些节点之间的完全网络故障)意味着系统有时需要在这些故障发生时做出艰难的选择,即是保持可用性但失去一些无法强制执行的重要保证,还是安全起见拒绝客户端。
CAP 定理 - 我将在下一章讨论 - 概括了其中的一些紧张关系。最终,理想的系统满足程序员需求(清晰的语义)和业务需求(可用性/一致性/延迟)。
设计技术:分割和复制
数据集在多个节点之间分布的方式非常重要。为了进行任何计算,我们需要找到数据,然后对其进行操作。
有两种基本技术可以应用于数据集。可以将其分割到多个节点上(分区),以便进行更多的并行处理。也可以将其复制或缓存到不同的节点上,以减少客户端和服务器之间的距离,并提供更高的容错性(复制)。
分而治之 - 我的意思是,划分和复制。
下图说明了这两个概念的区别:分区数据(如下的 A 和 B)被划分为独立的集合,而复制数据(如下的 C)则被复制到多个位置。
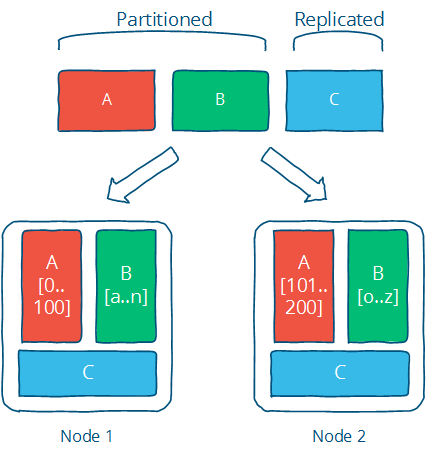
这是解决任何涉及分布式计算的问题的绝佳方法。当然,关键在于选择适合您具体实现的正确技术;有许多实现复制和分区的算法,每个算法都有不同的限制和优势,需要根据您的设计目标进行评估。
分区
划分是将数据集划分为较小的独立集合;这是为了减少数据集增长的影响,因为每个划分是数据的子集。
- 分区通过限制要检查的数据量并将相关数据定位在同一个分区中,提高了性能。
- 分区通过允许分区独立故障,增加了需要失败的节点数量,从而提高了可用性。
分区也是非常特定于应用程序的,所以在不了解具体情况的情况下很难对其进行详细说明。这就是为什么大多数文本,包括本文,都侧重于复制。
分区主要是根据您认为的主要访问模式来定义分区,并处理由于具有独立分区而产生的限制(例如,跨分区的低效访问,不同的增长速度等)。
复制
复制是将相同的数据复制到多台机器上;这样可以使更多的服务器参与计算。
让我不准确地引用霍马·辛普森:
对复制!生活中所有问题的原因和解决方案。
复制 - 复制或再现某物 - 是我们可以对抗延迟的主要方式。
- 复制通过将额外的计算能力和带宽应用于数据的新副本来提高性能
- 复制通过创建数据的额外副本,增加了需要失败的节点数量,从而提高可用性
复制是关于提供额外的带宽和在关键位置进行缓存。它还涉及根据某种一致性模型来维护一致性。
复制允许我们实现可扩展性、性能和容错性。害怕可用性的丧失或性能的降低?将数据复制以避免瓶颈或单点故障。计算慢?在多个系统上复制计算。I/O 慢?将数据复制到本地缓存以减少延迟或复制到多台机器以增加吞吐量。
复制也是许多问题的根源,因为现在有多个独立的数据副本必须在多台机器上保持同步 - 这意味着要确保复制遵循一致性模型。
一致性模型的选择非常重要:一个良好的一致性模型为程序员提供清晰的语义(换句话说,它所保证的属性易于推理),并满足高可用性或强一致性等商业/设计目标。
只有一种复制的一致性模型 - 强一致性 - 允许您编程,就好像底层数据没有被复制一样。其他一致性模型向程序员公开了复制的一些内部细节。然而,较弱的一致性模型可以提供更低的延迟和更高的可用性 - 并且不一定更难理解,只是不同而已。
进一步阅读
- 数据中心作为计算机 - 仓库规模机器设计导论 - Barroso & Hölzle,2008
- 分布式计算的谬误
- 年轻人的分布式系统笔记 - Hodges,2013
2. 抽象层次的升降
在本章中,我们将在抽象级别上上下下地旅行,看一些不可能的结果(CAP和FLP),然后为了性能再次下降。
如果你做过任何编程,对于抽象级别的概念可能已经很熟悉了。你总是在某个抽象级别上工作,通过某个 API 与一个较低级别的层进行接口交互,并可能为你的用户提供一些更高级别的 API 或用户界面。计算机网络的七层OSI 模型是一个很好的例子。
分布式编程,我敢断言,很大程度上是处理分布的后果(显然!)。也就是说,现实中存在着许多节点,而我们又希望系统“像一个单一的系统”一样工作。这意味着需要找到一个好的抽象,平衡可能性与可理解性和性能。
当我们说 X 比 Y 更抽象时,我们指的是什么?首先,X 不引入任何与 Y 本质上不同的新事物。事实上,X 可能会移除 Y 的某些方面或以更易处理的方式呈现它们。 其次,假设 X 从 Y 中移除的东西对于手头的问题不重要,那么 X 在某种意义上比 Y 更容易理解。
正如尼采所写:
每个概念都是通过我们将不相等的事物等同起来而产生的。没有一片叶子能完全等同于另一片叶子,而“叶子”这个概念是通过对这些个体差异的任意抽象而形成的,通过忘记这些区别;现在它引发了这样一个想法,即在自然界中可能存在除了叶子之外的“叶子” - 一种原始形态,所有的叶子都是由它编织、标记、复制、上色、卷曲和绘制的,但是由于技术不精,没有一份复制品能成为原始形态的正确、可靠和忠实的影像。
抽象,从根本上来说,是虚假的。每个情况都是独特的,每个节点也是如此。但是抽象使世界变得可管理:更简单的问题陈述-摆脱现实-更易于分析,并且只要我们没有忽略任何重要的东西,解决方案就是广泛适用的。
事实上,如果我们留下的东西是必要的,那么我们可以得出的结果将是广泛适用的。这就是为什么不可能性结果如此重要的原因:它们采用了问题的最简单可能的表述,并证明在某些约束或假设下无法解决。
所有的抽象都会忽略一些东西,而将现实中独特的事物等同起来。关键是要摆脱一切非必要的东西。你如何知道什么是必要的?嗯,你可能不会事先知道。
每次我们在系统的规范中排除某个方面时,我们都有可能引入错误和/或性能问题的源头。这就是为什么有时我们需要朝相反的方向进行,并有选择性地引入一些真实硬件和真实世界问题的方面。重新引入一些特定的硬件特性(例如物理顺序)或其他物理特性可能足以获得一个性能足够好的系统。
考虑到这一点,我们能保留的最少的现实是什么,同时仍然能够处理一个仍然被认可为分布式系统的东西?系统模型是我们认为重要的特性的规范;一旦指定了一个系统模型,我们就可以看一下一些不可能的结果和挑战。
一个系统模型
分布式系统的一个关键属性是分布。更具体地说,分布式系统中的程序有:
- 在独立的节点上并发运行...
- 通过可能引入不确定性和消息丢失的网络进行连接...
- 并且没有共享内存或共享时钟。
有很多含义:
- 每个节点同时执行一个程序
- 知识是局部的:节点只能快速访问它们的局部状态,并且任何有关全局状态的信息都可能过时
- 节点可以独立故障和恢复
- 消息可能会延迟或丢失(与节点故障无关;很难区分网络故障和节点故障)
- 时钟在节点之间不同步(本地时间戳不对应全局实时顺序,无法轻易观察)
一个系统模型列举了与特定系统设计相关的许多假设。
系统模型
关于分布式系统实现所依赖的环境和设施的一组假设
系统模型在对环境和设施的假设上存在差异。这些假设包括:
- 节点具有什么功能以及它们可能如何失败
- 通信链路如何运作以及它们可能如何失败
- 整个系统的属性,例如对时间和顺序的假设
一个强大的系统模型是指做出最弱的假设:为这样一个系统编写的任何算法对不同的环境都非常容忍,因为它只做很少且非常弱的假设。
另一方面,我们可以通过做出强硬的假设来创建一个易于推理的系统模型。 举个例子,假设节点不会出现故障意味着我们的算法不需要处理节点故障。 然而,这样的系统模型是不现实的,因此很难应用到实际中。
让我们更详细地看一下节点、链接、时间和顺序的属性。
我们系统模型中的节点
节点作为计算和存储的主机。它们具有:
- 执行程序的能力
- 将数据存储到易失性内存(在故障时可能会丢失)和稳定状态(故障后可以读取)的能力
- 时钟(可以或不可以假设为准确)
节点执行确定性算法:计算后的本地状态以及发送的消息是由接收到的消息和接收到消息时的本地状态唯一确定的。
有许多可能的故障模式描述了节点可能发生故障的方式。在实践中,大多数系统假设崩溃恢复故障模式:也就是说,节点只能通过崩溃来发生故障,并且可以在某个后续时间点(可能)恢复。
另一种选择是假设节点可能以任何任意方式失效。这被称为拜占庭容错。在现实世界的商业系统中,很少处理拜占庭故障,因为对任意故障具有弹性的算法运行成本更高,实现更复杂。我在这里不讨论它们。
我们系统模型中的通信链接
通信链路将各个节点相互连接,并允许消息在任何方向上发送。许多讨论分布式算法的书籍都假设每对节点之间都有单独的链路,这些链路为消息提供了先进先出(FIFO)的顺序,它们只能传递已发送的消息,并且发送的消息可能会丢失。
一些算法假设网络是可靠的:即消息不会丢失,也不会无限期延迟。对于某些现实世界的设置,这可能是一个合理的假设,但一般来说,我们更倾向于将网络视为不可靠的,并受到消息丢失和延迟的影响。
网络分区是指在节点本身保持运行状态的情况下,网络发生故障。当发生这种情况时,消息可能会丢失或延迟,直到网络分区被修复。分区节点可能对某些客户端是可访问的,因此必须与崩溃节点进行区别对待。下图说明了节点故障与网络分区的区别:

很少有人对通信链路做更进一步的假设。我们可以假设链接仅在一个方向上工作,或者我们可以为不同的链接引入不同的通信成本(例如,由于物理距离而导致的延迟)。然而,在商业环境中,除了远距离链接(WAN延迟)之外,这些很少成为问题,因此我在这里不讨论它们;成本和拓扑的更详细模型可以在复杂性的代价下实现更好的优化。
时间/顺序假设
物理分布的一个后果是,每个节点以独特的方式体验这个世界。 这是不可避免的,因为信息只能以光速传播。如果节点之间的距离不同,那么从一个节点发送到其他节点的任何消息将以不同的时间到达并且有可能以不同的顺序到达其他节点。
定时假设是一种方便的简写方式,用于捕捉我们在多大程度上考虑这个现实的假设。两种主要的替代方案是:
同步系统模型
进程同步执行;消息传输延迟存在已知的上限;每个进程拥有一个准确的时钟
异步系统模型
没有时间假设 - 例如,进程以独立的速率执行;消息传输延迟没有上限;不存在有用的时钟
同步系统模型对时间和顺序施加了许多限制。它基本上假设节点具有相同的体验:发送的消息始终在特定的最大传输延迟内接收,并且进程以锁步方式执行。这很方便,因为它允许您作为系统设计师对时间和顺序做出假设,而异步系统模型则不允许。
异步性是一种非假设:它仅假设您不能依赖于时间(或“时间传感器”)。
在同步系统模型中解决问题更容易,因为对于执行速度、最大消息传输延迟和时钟精确度的假设都有助于解决问题,因为你可以基于这些假设进行推理,并通过假设它们永远不会发生来排除不方便的故障场景。
当然,假设同步系统模型并不特别现实。现实世界中的网络会遭受故障,消息延迟没有硬性边界。现实世界中的系统充其量是部分同步的:它们可能偶尔能正常工作并提供一些上界,但也会有消息无限期延迟和时钟不同步的时候。我在这里不会真正讨论同步系统的算法,但在许多其他入门书籍中,你可能会遇到它们,因为它们在分析上更容易(但不现实)。
共识问题
在接下来的文本中,我们将改变系统模型的参数。接下来,我们将研究如何改变两个系统属性:
- 网络分区是否包含在故障模型中,以及
- 同步与异步的时间假设
通过讨论两个不可能结果(FLP和CAP),影响系统设计选择。
当然,为了展开讨论,我们还需要提出一个需要解决的问题。我要讨论的问题是一致性问题。
如果几台计算机(或节点)对某个值达成一致,那么它们就实现了共识。更正式地说:
- 一致性: 每个正确的进程都必须对同一个值达成一致。
- 完整性: 每个正确的进程最多决定一个值,并且如果它决定了某个值,那么它必须是由某个进程提出的。
- 终止性: 所有的进程最终都会达成决策。
- 有效性: 如果所有正确的进程提出相同的值 V,那么所有正确的进程都会决定 V。
共识问题是许多商业分布式系统的核心。毕竟,我们希望在不必处理分布(例如节点之间的分歧/背离)的后果的情况下,获得分布式系统的可靠性和性能,并解决共识问题可以解决一些相关的更高级问题,如原子广播和原子提交。
两个不可能的结果
第一个不可能性结果,被称为FLP不可能性结果,是一个对设计分布式算法的人特别相关的不可能性结果。第二个 - CAP定理 - 是一个相关的结果,对于实际操作者更为相关;那些需要在不同系统设计之间进行选择但不直接涉及算法设计的人。
FLP不可能性结果
我将简要总结FLP 不可能性结果,尽管在学术界被认为更为重要。FLP 不可能性结果(以作者 Fischer、Lynch 和 Patterson 命名)研究了异步系统模型下的共识问题(严格来说,是共识问题的一种非常弱的形式,即协议一致性问题)。假设节点只能通过崩溃来失败;网络是可靠的,并且异步系统模型的典型时间假设成立:例如,消息延迟没有上界。
在这些假设下,FLP 结果指出:"在一个异步系统中,即使消息永远不会丢失,最多只有一个进程可能会失败,并且它只能通过崩溃(停止执行)来失败,也不存在一个(确定性的)算法能够解决共识问题。"
这个结果意味着在一个非常简化的系统模型下,没有办法解决共识问题而不会永远延迟。论证是如果存在这样的算法,那么可以设计一个执行该算法的过程,在这个过程中通过延迟消息传递的方式使其保持未决状态("bivalent")任意长的时间 - 这在异步系统模型中是允许的。因此,这样的算法是不存在的。
这个不可能性结果很重要,因为它强调,在假设异步系统模型的情况下,解决共识问题的算法必须在消息传递的界限不可保证时,要么放弃安全性,要么放弃活性。
这个见解对于设计算法的人来说尤为重要,因为它对我们知道在异步系统模型中可解决的问题施加了严格的限制。CAP定理是一个相关的定理,对于从业者来说更为相关:它做出稍微不同的假设(网络故障而不是节点故障),并且对于从业者在选择系统设计时有更明确的影响。
CAP 定理
The CAP theorem was initially a conjecture made by computer scientist Eric Brewer. It's a popular and fairly useful way to think about tradeoffs in the guarantees that a system design makes. It even has a formal proof by Gilbert and Lynch and no, Nathan Marz didn't debunk it, in spite of what a particular discussion site thinks.
该定理表明这三个属性中的:
- 一致性:所有节点在同一时间看到相同的数据。
- 可用性:节点故障不会阻止幸存节点继续运行。
- 分区容错性:尽管由于网络和/或节点故障导致消息丢失,系统仍然可以继续运行。
只有两个可以同时满足。我们甚至可以将其绘制成漂亮的图表,从三个属性中选择两个属性,我们可以得到与不同交集相对应的三种系统类型:

请注意,定理指出中间的部分(具有所有三个特性)是无法实现的。然后我们得到三种不同的系统类型:
- 一致性 + 可用性 (CA)。例如,全严格法定协议,如两阶段提交。
- 一致性 + 分区容错性 (CP)。例如,使用多数法定协议,其中少数分区不可用,如Paxos。
- 可用性 + 分区容错性 (AP)。例如,使用冲突解决的协议,如Dynamo。
CA 和 CP 系统设计都提供相同的一致性模型:强一致性。唯一的区别是,CA 系统无法容忍任何节点故障;而 CP 系统可以容忍在非拜占庭失效模型下的至多 f 个故障,即只要大多数节点 f+1 保持正常运行,它可以容忍少数 f 个节点的故障。原因很简单:
- 一个 CA 系统无法区分节点故障和网络故障,因此必须停止在所有地方接受写入以避免引入分歧(多个副本)。它无法判断远程节点是宕机还是仅网络连接中断:所以唯一安全的做法是停止接受写入。
- 一个 CP 系统通过在分区的两侧强制不对称行为来防止分歧(例如保持单一副本的一致性)。它只保留多数分区,并要求少数分区变为不可用(例如停止接受写入),这样保持了一定程度的可用性(多数分区)并仍然确保单一副本的一致性。
我将在关于复制的章节中详细讨论这个问题,当我讨论 Paxos 时。重要的是,CP 系统将网络分区纳入其故障模型,并使用像 Paxos、Raft 或视图戳复制这样的算法来区分多数分区和少数分区。CA 系统不具备分区感知能力,并且历史上更常见:它们通常使用两阶段提交算法,并在传统分布式关系数据库中常见。
假设发生分区,该定理将简化为可用性和一致性之间的二元选择。

我认为从 CAP 定理中可以得出四个结论:
首先,早期分布式关系数据库系统中使用的许多系统设计没有考虑到分区容错性(例如,它们是 CA 设计)。对于现代系统来说,分区容错性是一个重要的属性,因为如果系统在地理上分布(如许多大型系统),网络分区的可能性会大大增加。
其次,在网络分区期间,强一致性和高可用性之间存在紧张关系。CAP 定理是对强保证和分布式计算之间权衡的一个阐述。
从某种意义上说,承诺一个由相互连接的不可预测网络的独立节点组成的分布式系统“表现出与非分布式系统无法区分的方式”是相当疯狂的。

强一致性保证要求我们在分区期间放弃可用性。这是因为在分区的两个副本无法相互通信的情况下,无法防止两个副本之间的分歧,同时继续接受分区两侧的写入操作。
我们如何解决这个问题?通过加强假设(假设没有分区)或降低保证。一致性可以与可用性(以及离线访问和低延迟的相关能力)进行权衡。如果“一致性”被定义为“所有节点同时看到相同的数据”以下的某种程度,那么我们可以同时拥有可用性和一些(较弱的)一致性保证。
第三,正常运行中强一致性和性能之间存在紧张关系。
强一致性/单副本一致性要求节点在每个操作上进行通信和达成一致。 这会导致正常操作期间的高延迟。
如果你可以接受一个不同于经典一致性模型的一致性模型,一个允许副本之间存在滞后或分歧的一致性模型,那么你可以在正常操作期间减少延迟并在存在分区的情况下保持可用性。
当涉及较少的消息和节点时,操作可以更快地完成。但实现这一点的唯一方法是放宽保证:让一些节点被较少地联系,这意味着节点可能包含旧数据。
这也使得异常情况成为可能。您不再保证获得最新的值。根据所做的保证类型,您可能读取一个比预期更旧的值,甚至会丢失一些更新。
第四点 - 并且在某种程度上间接地 - 如果我们不想在网络分区期间放弃可用性, 那么我们需要探索除强一致性之外的一致性模型是否适合我们的目的。
例如,即使用户数据被复制到多个数据中心,并且这两个数据中心之间的链接暂时中断,我们在许多情况下仍然希望允许用户使用网站/服务。这意味着稍后需要协调两个不同的数据集,这既是一个技术挑战,也是一个业务风险。但通常情况下,技术挑战和业务风险都是可管理的,因此最好提供高可用性。
一致性和可用性并不是真正的二元选择,除非你将自己限制在强一致性上。 但是强一致性只是一种一致性模型:在这种模型中,你必须放弃可用性,以防止数据有多个副本同时处于活动状态。正如Brewer本人指出的,"2 out of 3"的解释是误导性的。
如果你从这次讨论中只带走一个观点,那就是:“一致性”不是一个单一、明确的属性。记住:
相反,一致性模型是数据存储给使用它的程序的任何保证。
一致性模型
程序员与系统之间的契约,其中系统保证,如果程序员遵循一些特定规则,对数据存储进行的操作的结果将是可预测的
CAP 中的 "C" 是 "强一致性",但是 "一致性" 不是 "强一致性" 的同义词。
让我们来看一些可替代的一致性模型。
强一致性与其他一致性模型
一致性模型可以分为两种类型:强一致性模型和弱一致性模型:
- 强一致性模型(能够维护单个副本)
- 线性一致性
- 顺序一致性
- 弱一致性模型(不强)
- 客户端中心的一致性模型
- 因果一致性:最强的可用模型
- 最终一致性模型
强一致性模型保证更新的表现顺序和可见性与非复制系统等效。而弱一致性模型则不提供这样的保证。
请注意,这绝不是一个详尽无遗的列表。再次强调,一致性模型只是程序员和系统之间的任意合约,因此可以是几乎任何东西。
强一致性模型
强一致性模型可以进一步分为两种相似但稍有不同的一致性模型:
- 线性一致性: 在线性一致性下,所有的操作似乎以和全局实时操作顺序一致的顺序被原子地执行。(Herlihy & Wing,1991)
- 顺序一致性: 在顺序一致性下,所有的操作似乎以在个体节点看到的顺序一致且在所有节点上相等的顺序被原子地执行。(Lamport,1979)
关键区别在于线性一致性要求操作生效的顺序等于操作的实际实时顺序。顺序一致性允许操作被重新排序,只要每个节点上观察到的顺序保持一致。只有当某人能够观察到系统中所有的输入和时序时,才能区分这两者;对于与节点进行交互的客户端来说,这两者是等价的。
这个差异似乎不重要,但值得注意的是,顺序一致性是不能组合的。
强一致性模型允许您作为程序员将单个服务器替换为一个分布式节点集群,而不会遇到任何问题。
所有其他一致性模型都存在异常(与保证强一致性的系统相比), 因为它们的行为与非复制系统有所区别。但是,通常这些异常是可以接受的,要么是因为我们不关心偶尔的问题,要么是因为我们已经编写了代码以某种方式处理发生的不一致性。
请注意,弱一致性模型没有普遍适用的分类法,因为“不是强一致性模型”(例如,“以某种方式与非复制系统有所区别”)几乎可以是任何事情。
客户端中心一致性模型
以客户为中心的一致性模型是涉及到客户端或会话概念的一致性模型。例如,一个以客户为中心的一致性模型可能保证客户端永远不会看到旧版本的数据项。通常,这是通过在客户端库中构建额外的缓存来实现的,这样,如果客户端移动到包含旧数据的副本节点上,客户端库将返回其缓存值,而不是副本中的旧值。
客户端可能仍然可以看到旧版本的数据,如果他们所在的复制节点不包含最新版本,但他们将永远不会看到旧版本的值再次出现的异常情况(例如,因为他们连接到不同的复制节点)。请注意,有许多种以客户为中心的一致性模型。
最终一致性
最终一致性模型表示,如果您停止更改值,那么在一段未定义的时间之后,所有副本将达成一致的值。这意味着在此之前,副本之间的结果以某种未定义的方式不一致。由于它是可以轻易满足的(只有活性属性),所以在没有补充信息的情况下是无用的。
说某事只是最终一致的,就像说“人们最终会死亡”。这是一个非常弱的限制条件,我们可能希望至少有一些更具体的描述:
首先,"eventually" 指的是多久?如果能有一个严格的最低界限,或者至少对系统收敛到相同值通常需要多长时间有个概念,这将会很有用。
其次,副本如何就一个值达成一致呢?一个总是返回"42"的系统最终一致:所有副本都同意相同的值。但它并不收敛于一个有用的值,因为它只是不断返回相同的固定值。相反,我们希望有一个更好的方法。例如,一种决定的方法是让具有最大时间戳的值始终获胜。
所以当供应商说“最终一致性”时,他们指的是一些更精确的术语,比如“最终最后写者获胜,并在此期间读取最新观察到的值”的一致性。 "如何?"很重要,因为不好的方法可能导致写入丢失-例如,如果一个节点上的时钟设置不正确并且使用时间戳。
我将在关于弱一致性模型的复制方法章节中更详细地研究这两个问题。
深入阅读
- Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services - Gilbert & Lynch, 2002
- Impossibility of distributed consensus with one faulty process - Fischer, Lynch and Patterson, 1985
- Perspectives on the CAP Theorem - Gilbert & Lynch, 2012
- CAP Twelve Years Later: How the "Rules" Have Changed - Brewer, 2012
- Uniform consensus is harder than consensus - Charron-Bost & Schiper, 2000
- Replicated Data Consistency Explained Through Baseball - Terry, 2011
- Life Beyond Distributed Transactions: an Apostate's Opinion - Helland, 2007
- If you have too much data, then 'good enough' is good enough - Helland, 2011
- Building on Quicksand - Helland & Campbell, 2009
3. 时间和顺序
什么是顺序,为什么它很重要?
你是什么意思“什么是顺序”?
我是说,我们为什么对顺序如此着迷呢?我们为什么关心 A 是否在 B 之前发生?为什么我们不关心其他属性,比如“颜色”呢?
好吧,我的疯狂朋友,让我们回到分布式系统的定义来回答这个问题。
正如你可能记得的那样,我将分布式编程描述为使用多台计算机解决与单台计算机相同问题的艺术。
这实际上是对秩序的着迷的核心。任何一种一次只能做一件事的系统都会创造一个完全的操作顺序。就像人们依次通过一个单一的门一样,每个操作都有一个明确定义的前任和后继。这基本上是我们努力保持的编程模型。
传统模型是:一个程序,一个进程,一个内存空间在一个 CPU 上运行。操作系统将可能存在多个 CPU 和多个程序的事实抽象化,以及计算机上的内存实际上是共享给许多程序的。我并不是说线程编程和事件驱动编程不存在;只是它们是建立在“一个/一个/一个”模型之上的特殊抽象。程序被编写成按顺序执行:从顶部开始,然后向底部走。
作为一种属性,"Order"之所以受到如此关注,是因为定义"正确性"的最简单方法就是说“它的工作方式与在单个机器上的工作方式相同”。而通常这意味着a)我们运行相同的操作并且b)以相同的顺序运行它们 - 即使有多台机器。
分布式系统中保持顺序(按照单一系统定义)的好处是它们是通用的。您不需要关心操作是什么,因为它们将被准确地执行,就像在单台机器上一样。这非常棒,因为您知道无论操作是什么,都可以使用相同的系统。
实际上,一个分布式程序在多个节点上运行;有多个 CPU 和多个操作流进来。您仍然可以分配一个总顺序,但这需要准确的时钟或某种形式的通信。您可以使用完全准确的时钟为每个操作分配时间戳,然后使用它来确定总顺序。或者您可能有某种通信系统,可以像总顺序一样分配连续的编号。
全序和偏序
在分布式系统中,自然状态是部分有序集合。无论是网络还是独立节点都不对相对顺序做出任何保证;但在每个节点上,你可以观察到一个本地顺序。
一个全序关系是一种二元关系,它为某个集合中的每个元素定义了一个排序。
当两个不同的元素中的一个大于另一个时,它们是可比较的。在一个偏序集中,一些元素对是不可比较的,因此一个偏序并不能指定每个项目的确切顺序。
总序和偏序都是传递关系和反对称关系。对于集合 X 中的所有 a、b 和 c,以下陈述在总序和偏序中成立:
如果 a ≤ b 并且 b ≤ a,那么 a = b(反对称性); 如果 a ≤ b 并且 b ≤ c,那么 a ≤ c(传递性);
然而,一个全序是全的:
对于 X 中的所有 a、b,a ≤ b 或 b ≤ a(全序关系)
当部分序只是反射关系时:
a ≤ a(自反性)对于 X 中的所有 a
请注意,全体性意味着自反性;因此,偏序是全序的一个较弱的变体。 对于偏序中的一些元素,全体性属性不成立-换句话说,有些元素是不可比较的。
Git 分支是偏序的一个例子。正如你可能知道的,git 版本控制系统允许你从一个基本分支(例如主分支)创建多个分支。每个分支代表了基于共同祖先的源代码变更历史:
[ 分支 A (1,2,0)] [ 主分支 (3,0,0) ] [ 分支 B (1,0,2) ]
[ 分支 A (1,1,0)] [ 主分支 (2,0,0) ] [ 分支 B (1,0,1) ]
\ [ 主分支 (1,0,0) ] /
分支 A 和 B 是从一个共同的祖先派生出来的,但它们之间没有确定的顺序:它们代表了不同的历史,不能简化为一个单一的线性历史而不需要额外的工作(合并)。当然,你可以将所有的提交按某种任意顺序排序(比如,首先按祖先排序,然后按 A 在 B 之前或 B 在 A 之前排序)- 但这样做会失去信息,因为强行制定了一个不存在的总顺序。
在一个只有一个节点的系统中,必然会出现一个总序:指令按照特定的可观察顺序执行,消息按照特定的可观察顺序处理在一个单独的程序中。我们已经依赖于这个总序 - 它使程序的执行可预测。这个顺序可以在分布式系统中保持,但代价很高:通信是昂贵的,时间同步是困难而脆弱的。
时间是什么?
时间是秩序的源泉 - 它使我们能够定义操作的顺序 - 这也具有人们可以理解的解释(一秒钟,一分钟,一天等等)。
在某种意义上,时间就像任何其他整数计数器一样。只是它恰好很重要,以至于大多数计算机都有专用的时间传感器,也称为时钟。它如此重要,以至于我们已经找出了如何使用一些不完美的物理系统(从蜡烛到铯原子)合成同样计数器的近似值。通过"合成",我指的是我们可以通过某些物理属性在物理上相距很远的地方近似计算整数计数器的值,而无需直接通信。
时间戳实际上是一种简略的值,用于表示从宇宙开始到当前时刻的世界状态 - 如果某个事件发生在特定的时间戳上,那么它可能受到之前发生的一切事情的影响。这个想法可以推广到一个因果时钟,它明确跟踪原因(依赖关系),而不仅仅是假设在时间戳之前发生的一切都是相关的。当然,通常的假设是我们只需要关心特定系统的状态,而不是整个世界的状态。
假设时间在任何地方都以相同的速率流逝-这是一个很大的假设,我马上会回到这个问题上-当在程序中使用时间和时间戳时,有几种有用的解释。这三种解释是:
- 订单
- 持续时间
- 解释
顺序。当我说时间是一种顺序的来源时,我指的是:
- 我们可以给无序事件附加时间戳以对它们进行排序
- 我们可以使用时间戳来强制执行操作的特定顺序或消息的传递(例如,如果操作到达顺序错误,可以延迟该操作)
- 我们可以使用时间戳的值来确定某件事情在某件事情之前按时间发生
解释 - 时间作为一个普遍可比较的值。时间戳的绝对值可以被解释为日期,对于人们来说很有用。根据日志文件中停机开始的时间戳,你可以知道它是上个星期六,在那时有一场雷暴。
持续时间 - 以时间为单位度量的持续时间与现实世界有一些关联。算法通常不关心时钟的绝对值或其作为日期的解释,但它们可能会使用持续时间来做出一些判断。特别是,等待的时间量可以提供关于系统是否被分区或仅仅是经历高延迟的线索。
根据其特性,分布式系统的组件不会以可预测的方式行为。它们不保证任何特定顺序、推进速度或缺乏延迟。每个节点都具有一定的本地顺序 - 执行是(大致上)顺序的 - 但这些本地顺序彼此独立。
强加(或假设)秩序是减少可能执行和可能发生的空间的一种方式。 人类在事物可以以任何顺序发生时很难进行推理 - 只是要考虑的排列组合太多了。
时间是否在各个地方以相同的速度推进?
我们都有基于个人经验的直觉时间概念。不幸的是,这种直觉的时间观念更容易形成完全顺序而不是部分顺序。更容易想象一种事物一个接一个地发生的顺序,而不是同时发生。更容易推理一种消息的单一顺序,而不是推理以不同顺序和不同延迟到达的消息。
然而,当实施分布式系统时,我们希望避免对时间和顺序做出过强的假设,因为假设越强,系统对于“时间传感器”或机载时钟的问题就越脆弱。此外,强制执行顺序是有成本的。我们能够容忍的时间的非确定性越多,就越能充分利用分布式计算的优势。
对于“时间是否在任何地方都以相同的速度流逝?”这个问题有三个常见的答案。它们是:
- "全球时钟": 是
- "本地时钟": 不是,但是
- "没有时钟": 不!
这些大致对应于我在第二章中提到的三种时间假设:同步系统模型具有全局时钟,部分同步模型具有本地时钟,而在异步系统模型中则无法使用时钟。让我们更详细地看看这些。
带有“全局时钟”假设的时间
全局时钟假设是存在一个完美精确的全局时钟,并且每个人都可以访问该时钟。这是我们通常对时间的思考方式,因为在人际互动中,时间上的微小差异并不真正重要。
全局时钟基本上是总体顺序的来源(即使那些节点从未进行过通信,也能确切地知道所有节点上的每个操作的顺序)。
然而,这只是对世界的理想化看法:在现实中,时钟同步只能达到有限的准确度。这受到商品计算机时钟准确度的限制,如果使用诸如NTP这样的时钟同步协议还会受到延迟的限制,而且根本上还受到时空的本质的影响。
假设分布式节点上的时钟完全同步,意味着假设时钟从相同的值开始,并且永远不会漂移。这是一个很好的假设,因为您可以自由地使用时间戳来确定全局的总顺序 - 受时钟漂移而不是延迟的限制 - 但这是一个非平凡的操作挑战和潜在的异常源。有许多不同的情况,例如用户意外更改机器上的本地时间,或者过时的机器加入集群,或者同步的时钟以稍微不同的速率漂移等等,这些都可能导致难以追踪的异常。
尽管如此,还是有一些现实世界的系统对此做出了假设。Facebook的Cassandra是一个假设时钟同步的系统的示例。它使用时间戳来解决写入冲突 - 拥有较新时间戳的写入将获胜。这意味着如果时钟漂移,新数据可能会被忽略或被旧数据覆盖;同样,这是一个运营上的挑战(据我所听到的,人们对此非常清楚)。另一个有趣的例子是Google的Spanner:论文描述了他们的TrueTime API,它不仅同步时间,还估计最坏情况下的时钟漂移。
基于"本地时钟"假设的时间
第二个,也许更合理的假设是每台机器都有自己的时钟,但没有全局时钟。这意味着你不能使用本地时钟来确定远程时间戳是在本地时间戳之前还是之后;换句话说,你不能有意义地比较来自两台不同机器的时间戳。

本地时钟假设更接近于现实世界。它赋予了一个部分顺序:每个系统上的事件是有序的,但仅仅使用时钟无法跨系统对事件进行排序。
然而,在单台机器上,您可以使用时间戳对事件进行排序;只要小心不让时钟跳来跳去,您可以在单台机器上使用超时。当然,在由最终用户控制的机器上,这可能假设过多:例如,用户在使用操作系统的日期控制查找日期时可能不小心更改其日期为不同的值。
没有时钟假设下的时间
最后,还有一个逻辑时间的概念。在这里,我们根本不使用时钟,而是以其他方式追踪因果关系。记住,时间戳只是对世界在那一点上的状态的简写 - 所以我们可以使用计数器和通信来确定某件事情是在之前、之后还是与其他事情同时发生。
这样,我们可以确定不同机器之间事件的顺序,但不能对时间间隔做任何假设,也不能使用超时(因为我们假设没有"时间传感器")。这是一个偏序:可以使用计数器和无通信在单个系统上对事件进行排序,但在系统之间对事件排序需要进行消息交换。
分布式系统中最常被引用的论文之一是 Lamport 关于时间、时钟和事件排序的论文。向量时钟是该概念的一种泛化(我将在更详细地介绍),它是一种在不使用时钟的情况下跟踪因果关系的方法。Cassandra 的表亲 Riak(Basho)和 Voldemort(Linkedin)使用向量时钟,而不是假设节点可以访问完全准确的全局时钟。这使得这些系统能够避免之前提到的时钟准确性问题。
当不使用时钟时,跨远程机器对事件进行排序的最大精度受通信延迟的限制。
时间在分布式系统中如何使用?
时间的好处是什么?
- 时间可以在系统中定义顺序(无需通信)
- 时间可以为算法定义边界条件
事件的顺序在分布式系统中非常重要,因为分布式系统的许多属性都是根据操作/事件的顺序来定义的:
- 正确性取决于(对)正确事件顺序的一致性,例如在分布式数据库中的可序列化
- 当资源争用发生时,顺序可以作为一个决策因素,例如如果有两个对小部件的订单,先完成第一个订单,取消第二个订单
一个全局时钟可以让两台不同的机器上的操作按顺序进行,而无需两台机器直接通信。没有全局时钟,我们需要进行通信以确定顺序。
时间还可以用来定义算法的边界条件 - 具体来说,用于区分“高延迟”和“服务器或网络链路故障”。这是一个非常重要的用例;在大多数现实世界的系统中,超时用于确定远程机器是否失败,还是仅仅遇到了高网络延迟。做出这种判断的算法被称为故障检测器;我将很快讨论它们。
向量时钟(因果顺序的时间)
之前,我们讨论了分布式系统中时间进展速度的不同假设。假设我们无法实现准确的时钟同步 - 或者以我们的系统不应对时间同步问题敏感为目标,那么我们如何对事物进行排序呢?
兰波特时钟(Lamport clocks)和向量时钟(vector clocks)是用于替代依赖于计数器和通信的物理时钟的,在分布式系统中确定事件顺序的方法。这些时钟提供了一个可在不同节点之间进行比较的计数器。
兰波特时钟很简单。每个进程使用以下规则维护一个计数器:
- 每当一个进程执行工作时,增加计数器
- 每当一个进程发送消息时,包含计数器
- 当收到一条消息时,将计数器设置为
max(local_counter, received_counter) + 1
以代码形式表达:
function LamportClock() {
this.value = 1;
}
LamportClock.prototype.get = function() {
return this.value;
}
LamportClock.prototype.increment = function() {
this.value++;
}
LamportClock.prototype.merge = function(other) {
this.value = Math.max(this.value, other.value) + 1;
}
一个兰波特时钟可以在不同系统之间比较计数器,但有一个注意事项:兰波特时钟定义了一个偏序关系。如果时间戳(a) < 时间戳(b):
a可能在b之前发生,或者a可能与b无法比较
这被称为时钟一致性条件:如果一个事件在另一个事件之前发生,那么这个事件的逻辑时钟就在其他事件之前。如果 a 和 b 来自同一个因果历史,例如,两个时间戳值都是在同一进程上产生的;或者 b 是对在 a 中发送的消息的响应,那么我们知道 a 发生在 b 之前。
直观来说,这是因为 Lamport 时钟只能携带关于一个时间线/历史的信息;因此,比较从未相互通信的系统中的 Lamport 时间戳可能会导致并发事件在没有排序的情况下似乎被排序。
想象一个系统,在初始阶段分为两个相互独立的子系统,它们从未相互通信。
对于每个独立系统中的所有事件,如果 a 在 b 之前发生,则 ts(a) < ts(b);但是,如果你从不同的独立系统中选取两个事件(例如,不具有因果关系的事件),则无法对它们的相对顺序做出任何有意义的陈述。虽然系统的每个部分都给事件分配了时间戳,但这些时间戳彼此没有关联。两个事件可能看起来是有序的,尽管它们之间没有关联。
然而 - 而这仍然是一个有用的特性 - 从单个机器的角度来看,使用ts(a)发送的任何消息都将收到一个带有ts(b)的响应,其中> ts(a)。
一个向量时钟是 Lamport 时钟的扩展,它维护着一个 N 个逻辑时钟的数组[ t1, t2, ... ] - 每个节点一个。每个节点在内部事件上不是增加一个公共计数器,而是将自己的逻辑时钟向量递增一。因此,更新规则如下:
- 每当一个进程执行工作时,递增向量中节点的逻辑时钟值
- 每当一个进程发送消息时,包含完整的逻辑时钟向量
- 当接收到一条消息时:
- 更新向量中的每个元素为
max(本地时钟值, 接收到的时钟值) - 递增表示当前节点的逻辑时钟值
- 更新向量中的每个元素为
再次,以代码表示:
function VectorClock(value) {
// 表示为以节点 id 为键的哈希表:例如 { node1: 1, node2: 3 }
this.value = value || {};
}
VectorClock.prototype.get = function() {
return this.value;
};
VectorClock.prototype.increment = function(nodeId) {
if(typeof this.value[nodeId] == 'undefined') {
this.value[nodeId] = 1;
} else {
this.value[nodeId]++;
}
};
VectorClock.prototype.merge = function(other) {
var result = {}, last,
a = this.value,
b = other.value;
// 这个过滤器过滤掉哈希表中的重复键
(Object.keys(a)
.concat(b))
.sort()
.filter(function(key) {
var isDuplicate = (key == last);
last = key;
return !isDuplicate;
}).forEach(function(key) {
result[key] = Math.max(a[key] || 0, b[key] || 0);
});
this.value = result;
};
这幅插图(来源)展示了一个向量时钟:
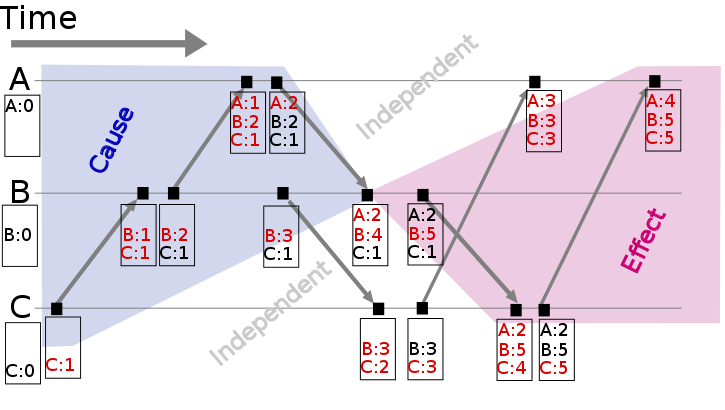
每个节点(A,B,C)都跟踪向量时钟。随着事件的发生,它们会被时间戳与向量时钟的当前值。检查像 { A: 2, B: 4, C: 1 } 这样的向量时钟,能够准确地识别那些(可能)影响到该事件的消息。
向量时钟的问题主要是它们需要每个节点一个条目,这意味着对于大型系统来说,它们可能会变得非常大。已经采用了各种技术来减小向量时钟的大小(通过定期进行垃圾回收或通过限制大小来降低准确性)。
我们已经看过了如何在没有物理时钟的情况下追踪顺序和因果关系。现在,让我们来看看如何使用时间长度进行截断。
故障检测器(截止时间)
正如我之前所说,等待时间的长短可以提供关于系统是否被分区或仅仅是遇到高延迟的线索。在这种情况下,我们不需要假设一个完美准确的全局时钟 - 只需要有一个足够可靠的本地时钟就足够了。
给定一个在一个节点上运行的程序,它如何知道远程节点已经失败了?在没有准确信息的情况下,我们可以推断,在经过一段合理的时间后,一个无响应的远程节点已经失败。
但是“合理的数量”是多少?这取决于本地节点和远程节点之间的延迟。与其明确指定具有特定值的算法(在某些情况下必然会出错),不妨使用适当的抽象来处理会更好。
故障检测器是一种抽象出确切时间假设的方法。故障检测器是使用心跳消息和定时器实现的。进程交换心跳消息。如果在超时发生之前未收到消息响应,则该进程怀疑另一个进程。
基于超时的故障检测器将存在过于主观(声明节点已失败)或过于保守(需要很长时间才能检测到崩溃)的风险。故障检测器需要多准确才能使用?
Chandra 等人(1996年)在解决共识问题的背景下讨论了故障检测器,这是一个特别相关的问题,因为它是大多数复制问题的基础,其中复制品需要在延迟和网络分区的环境中达成一致。
他们使用两个属性来描述故障监测器,完备性和准确性:
强完备性。
每个崩溃的进程最终都会被每个正确的进程怀疑。
弱完备性。
每个崩溃的进程最终都会被一些正确的进程怀疑。
强准确性。
没有一个正确的进程会被怀疑。
弱准确性。
一些正确的进程永远不会被怀疑。
完整性比准确性更容易实现;事实上,所有重要的故障检测器都可以实现它 - 你只需要不永远等待才怀疑某人。Chandra等人指出,具有弱完整性的故障检测器可以转化为具有强完整性的故障检测器(通过广播关于怀疑进程的信息),这使我们可以专注于准确性属性的范围。
避免错误地怀疑非故障进程是困难的,除非您能够假设消息延迟存在一个硬的最大值。这个假设可以在同步系统模型中进行 - 因此故障检测器在这样的系统中可以具有强大的准确性。在没有对消息延迟施加硬限制的系统模型下,故障检测最多只能最终准确。
Chandra等人表明,即使是一个非常弱的故障检测器 - 最终弱故障检测器⋄W(最终弱准确性+弱完备性)- 也可以用来解决共识问题。下面的图表(来自论文)说明了系统模型和问题可解性之间的关系:

正如您在上面所看到的,某些问题在异步系统中没有故障检测器是无法解决的。 这是因为在没有故障检测器(或对时间边界进行强假设,例如同步系统模型)的情况下,无法确定远程节点是崩溃了还是只是遇到了高延迟。这种区别对于任何追求单拷贝一致性的系统都很重要:失败的节点可以被忽略,因为它们不会导致分歧,但是分区节点不能安全地被忽略。
如何实现故障检测器?从概念上讲,简单的故障检测器并没有太多内容,只是在超时到期时检测故障。最有趣的部分与如何判断远程节点是否失败有关。
理想情况下,我们希望故障检测器能够适应不断变化的网络条件,并避免在其中硬编码超时值。例如,Cassandra使用了一种Phi累计故障检测器,它是一种输出可疑级别(介于0和1之间的值)而不是二进制的"up"或"down"判断的故障检测器。这使得使用故障检测器的应用程序可以根据准确检测和早期检测之间的权衡进行自主决策。
时间、顺序和性能
之前,我提到了需要为秩序支付代价。我是什么意思呢?
如果你正在编写一个分布式系统,那么你很可能拥有不止一台计算机。对于世界的自然(和现实)观点是一个偏序,而不是一个全序。你可以将偏序转换为全序,但这需要通信、等待,并且会施加限制,限制了在任何特定时间点可以工作的计算机数量。
所有的时钟都是近似值,受到网络延迟(逻辑时间)或物理学的限制。即使在多个节点之间保持一个简单的整数计数器同步也是一个挑战。
虽然时间和顺序经常一起讨论,但时间本身并不是一个特别有用的属性。算法并不真的关心时间,而更关心更抽象的属性:
- 事件的因果顺序
- 故障检测(例如,对消息传递的上界的近似)
- 一致的快照(例如,在某个时间点上检查系统状态的能力;这里不讨论)
施加总排序是可能的,但是代价很高。这需要你以普通(最低)速度进行操作。 通常确保事件按照某个定义的顺序传递的最简单方法是指定一个单一的(瓶颈)节点,所有的操作都通过该节点。
时间/顺序/同步性真的有必要吗?这取决于情况。在一些用例中,我们希望每个中间操作将系统从一个一致的状态移动到另一个一致的状态。例如,在许多情况下,我们希望从数据库中获取的响应代表所有可用的信息,并且我们希望避免处理系统可能返回不一致结果的问题。
但在其他情况下,我们可能不需要那么多的时间/顺序/同步。例如,如果您正在运行一个长时间运行的计算,并且在最后一刻之前并不真正关心系统做什么 - 那么只要您能保证答案是正确的,您就不需要太多的同步。
同步通常被应用于所有操作中,但实际上只有一部分情况对最终结果有影响。在何时需要顺序来保证正确性?CALM定理 - 我将在最后一章中讨论 - 提供了一个答案。
在其他情况下,只提供代表已知最佳估计的答案是可接受的,也就是说,它仅基于系统中包含的部分信息。特别是在网络分区期间,可能需要使用系统的一部分来回答查询。在其他用例中,最终用户无法真正区分相对较新且可以廉价获得的答案与保证正确且计算代价高昂的答案。例如,某个用户X的Twitter关注者数量是X还是X+1?或者电影A、B和C是否是某个查询的绝对最佳答案?进行更便宜、基本正确的“尽力而为”是可以接受的。
在接下来的两章中,我们将研究用于容错强一致性系统的复制 - 这些系统在越来越具有弹性的同时提供强有力的保证。这些系统为第一种情况提供解决方案:当您需要保证正确性并且愿意为此付费时。然后,我们将讨论具有弱一致性保证的系统,在面临分区时仍然可用,但只能给出“尽力而为”的答案。
进一步阅读
Lamport时钟,向量时钟
- 分布式系统中的时间、时钟和事件排序 - 莱斯利·兰波特,1978年
故障检测
- Unreliable failure detectors and reliable distributed systems - Chandra and Toueg
- Latency- and Bandwidth-Minimizing Optimal Failure Detectors - So & Sirer, 2007
- The failure detector abstraction, Freiling, Guerraoui & Kuznetsov, 2011
快照
- Consistent global states of distributed systems: Fundamental concepts and mechanisms, Ozalp Babaogly and Keith Marzullo, 1993
- Distributed snapshots: Determining global states of distributed systems, K. Mani Chandy and Leslie Lamport, 1985
因果关系
- Detecting Causal Relationships in Distributed Computations: In Search of the Holy Grail - Schwarz & Mattern, 1994
- Understanding the Limitations of Causally and Totally Ordered Communication - Cheriton & Skeen, 1993
4. 复制
复制问题是分布式系统中的众多问题之一。我选择把重点放在它上面,而不是其他问题,比如领导者选举、故障检测、互斥、一致性和全局快照,因为它往往是人们最感兴趣的部分。举个例子,并行数据库在复制特性方面有所区别。此外,复制为许多子问题提供了一个上下文,比如领导者选举、故障检测、一致性和原子广播。
复制是一个群体通信问题。什么样的安排和通信模式可以给我们带来期望的性能和可用性特性?在面对网络分区和同时节点故障时,我们如何确保容错性、持久性和非发散性?
再次强调,复制有很多种方法。这里我采用的方法只是从一个具有复制功能的系统可能的高层模式来看。从视觉上来看,这有助于使讨论集中在整体模式而不是具体的消息传递上。我在这里的目标是探索设计空间,而不是解释每个算法的具体细节。
首先让我们定义一下复制的样子。我们假设我们有一个初始数据库,并且客户端会发出请求来改变数据库的状态。

安排和通信模式可以分为以下几个阶段:
- (请求) 客户端向服务器发送请求
- (同步) 复制的同步部分发生
- (响应) 响应返回给客户端
- (异步) 复制的异步部分发生
This model is loosely based on this article. Note that the pattern of messages exchanged in each portion of the task depends on the specific algorithm: I am intentionally trying to get by without discussing the specific algorithm.
鉴于这些阶段,我们可以创建哪种类型的通信模式?我们选择的模式会对性能和可用性产生什么样的影响?
同步复制
第一种模式是同步复制(也称为主动复制,或者急切复制,或者推送复制,或者悲观复制)。让我们来画出它的样子:

在这里,我们可以看到三个明显的阶段:首先,客户端发送请求。接下来,我们所谓的同步复制部分开始进行。这个术语指的是客户端被阻塞 - 等待系统的回复。
在同步阶段,第一个服务端联系另外两个服务端并等待直到收到所有其他服务端的回复。最后,它向客户端发送响应,通知其结果(例如成功或失败)。
所有这一切似乎都很简单。在不讨论同步阶段算法的细节的情况下,我们对这种特定的通信模式安排有什么说法?首先,观察到这是一种写 N - of - N 方法:在返回响应之前,每个服务器都必须看到并确认。
从性能的角度来看,这意味着系统的速度将取决于最慢的服务器。同时,系统对于网络延迟的变化非常敏感,因为它需要等待每个服务器回复后才能继续进行。
鉴于 N-of-N 的方法,系统无法容忍任何服务器的丢失。当一个服务器丢失时,系统无法再写入所有节点,因此无法继续进行。在这种设计中,可能能够提供对数据的只读访问,但在节点故障后不允许进行修改。
这种安排可以提供非常强的耐久性保证:当响应返回时,客户端可以确信所有 N 个服务器都已接收、存储并确认了请求。为了丢失一个已接受的更新,需要丢失所有 N 个副本,这是一个非常好的保证。
异步复制
让我们将其与第二种模式进行对比-异步复制(也称为被动复制,或拉取复制,或延迟复制)。正如你可能已经猜到的那样,这与同步复制相反:

在这里,主服务器(/领导者/协调者)立即向客户端发送回应。它可能会将更新存储在本地,但不会同步执行任何重要的工作,并且客户端不需要等待服务器之间进行更多通信的轮次。
在稍后的阶段,复制任务的异步部分开始进行。在这里,主服务器使用某种通信模式与其他服务器联系,并且其他服务器会更新其数据副本。具体的细节取决于所使用的算法。
关于这种特定的安排,我们在不涉及算法细节的情况下能说些什么呢?嗯,这是一种一写多读的方法:立即返回响应,稍后进行更新传播。
从性能角度来看,这意味着系统很快:客户端不需要花费额外的时间等待系统的内部执行工作。系统还更容忍网络延迟,因为内部延迟的波动不会导致客户端额外等待。
这种安排只能提供弱的或概率性的持久性保证。如果没有发生任何问题,数据最终会被复制到所有 N 台机器上。然而,如果包含数据的唯一服务器在此之前丢失,数据将永久丢失。
给定 1-of-N 的方法,只要至少一个节点处于运行状态,系统就可以保持可用(至少在理论上是如此,尽管在实践中负载可能会太高)。像这样的纯粹懒惰的方法不提供持久性或一致性的保证;你可能被允许向系统中写入,但如果发生任何故障,没有保证你能够读取你所写入的内容。
最后,值得注意的是,被动复制无法保证系统中的所有节点始终包含相同的状态。如果您在多个位置接受写入,并且不要求这些节点同步达成一致,那么您将面临分歧的风险:读取可能从不同的位置返回不同的结果(特别是在节点故障和恢复之后),并且无法强制执行全局约束(这需要与所有人进行通信)。
我并没有真正提到在读取(而不是写入)期间的通信模式,因为读取的模式实际上是根据写入的模式来确定的:在读取期间,您希望尽可能少地联系节点。在关于法定人数的上下文中,我们将更详细地讨论这个问题。
我们只讨论了两种基本的排列方式和没有具体算法。然而,我们已经能够弄清楚可能的通信模式以及它们的性能、可靠性保证和可用性特征。
主要复制方法的概述
在讨论了两种基本的复制方法:同步复制和异步复制之后,让我们来看一下主要的复制算法。
有许多不同的方法来分类复制技术。我想介绍的第二个区别(在同步与异步之后)是:
- 防止分歧的复制方法(单一副本系统)
- 有风险分歧的复制方法(多主系统)
第一组方法具有“像单一系统一样运行”的特性。特别是,在部分故障发生时,系统确保只有一个副本处于活动状态。此外,系统还确保副本始终保持一致。这被称为共识问题。
如果所有进程(或计算机)对某个值达成一致,则称为实现共识。更正式地说:
- 一致性:每个正确的进程都必须在相同的值上达成一致。
- 完整性:每个正确的进程最多决定一个值,如果它决定了某个值,则该值必须由某个进程提出。
- 终止性:所有进程最终都会达到一个决定。
- 有效性:如果所有正确的进程提出相同的值 V,则所有正确的进程都会决定 V。
互斥、领导者选举、组播和原子广播都是更一般的一致性问题的实例。维护单一副本一致性的复制系统需要以某种方式解决一致性问题。
维护单一副本一致性的复制算法包括:
- 1n 消息(异步主/备份)
- 2n 消息(同步主/备份)
- 4n 消息(2PC,多 Paxos)
- 6n 消息(3PC,Paxos 重复领导选举)
这些算法在它们的容错性上有所不同(例如,它们可以容忍的故障类型)。我将它们仅仅按照算法执行过程中交换的消息数量进行了分类,因为我认为尝试找到一个答案来回答“通过增加消息交换我们获得了什么?”这个问题是有趣的。
下面的图表,改编自来自Google的Ryan Barret, 描述了不同选项的一些方面:

在上图中,一致性、延迟、吞吐量、数据丢失和故障转移特性实际上可以追溯到两种不同的复制方法:同步复制(例如,等待响应)和异步复制。当您等待时,性能会变差,但可靠性更强。在我们讨论分区(和延迟)容忍性时,2PC和法定人数系统之间的吞吐量差异将变得明显。
在该图中,弱(/最终)一致性的算法被归为一类(“gossip”)。然而,我将更详细地讨论弱一致性的复制方法 - gossip和(部分)仲裁系统。"事务"行实际上更多地涉及全局谓词评估,这在具有弱一致性的系统中不受支持(尽管可以支持局部谓词评估)。
值得注意的是,弱一致性要求的系统具有较少的通用算法和更多可以选择性应用的技术。由于不强制执行单副本一致性的系统可以像由多个节点组成的分布式系统一样自由操作,因此修复的明显目标较少,重点更多地放在让人们能够推理系统特性的方式上。
举个例子:
- 以客户为中心的一致性模型试图提供更明晰的一致性保证,同时允许发生分歧。
- CRDTs(收敛和交换复制数据类型)利用某些状态和基于操作的数据类型的半格特性(结合律、交换律、幂等性)。
- 融合分析(如 Bloom 语言中的分析)利用计算的单调性信息来最大程度地利用无序性。
- PBS(概率上界陈旧度)利用模拟和从真实世界系统收集的信息来描述部分仲裁系统的预期行为。
我将在稍后详细讨论所有这些内容,首先让我们来看一下维护单一副本一致性的复制算法。
主/备份复制
主/备份复制(也称为主从复制或日志传送)可能是最常用的复制方法,也是最基本的算法。所有更新都在主服务器上执行,并将操作日志(或更改)通过网络传送到备份副本。有两种变体:
- 异步主/备份复制和
- 同步主/备份复制
同步版本需要两个消息("更新" + "确认收到"),而异步版本只需要一个消息("更新")。
P/B(主备)是非常常见的。例如,默认情况下,MySQL复制使用异步变体。MongoDB也使用P/B(还有一些额外的故障转移程序)。所有操作都在一个主服务器上执行,将它们序列化到本地日志,然后异步复制到备份服务器上。
正如我们之前在异步复制的背景下讨论的那样,任何异步复制算法只能提供弱一致性保证。在 MySQL 复制中,这表现为复制延迟:异步备份始终比主服务器落后至少一次操作。如果主服务器失败,则尚未发送到备份的更新将会丢失。
主/备份复制的同步变种确保在将写入返回给客户端之前已将其存储在其他节点上 - 但需要等待其他副本的响应,这是以代价换来的。然而,值得注意的是,即使这个变种也只能提供弱保证。考虑以下简单的故障场景:
- 主服务器接收写入操作并将其发送到备份服务器
- 备份服务器持久化并确认写入操作
- 然后,在向客户端发送确认前,主服务器发生故障
客户端现在假设提交失败了,但是备份已经提交了;如果将备份提升为主节点,将会是不正确的。可能需要手动清理来协调失败的主节点或者不一致的备份。
当然,我在这里进行了简化。虽然所有主/备份复制算法都遵循相同的一般消息模式,但它们在处理故障切换、副本长时间离线等方面存在差异。然而,在这种方案中,无法对主节点的不合时宜的故障具有弹性。
日志传送/主备方案中的关键是它们只能提供尽力而为的保证(例如,如果节点在不适当的时间发生故障,则容易丢失更新或错误更新)。此外,主备方案容易出现分裂脑,当由于临时网络问题而进行故障切换时,导致主服务器和备份服务器同时处于活动状态。
为了防止不适时的故障导致一致性保证被违反,我们需要添加另一轮的消息传递,这将带来两阶段提交协议(2PC)。
两阶段提交(2PC)
两阶段提交(2PC)是在许多经典关系型数据库中使用的协议。例如,MySQL Cluster(不要与常规的MySQL混淆)使用2PC提供同步复制。下面的图示说明了消息流程:
[ 协调员 ] -> 可以提交吗? [ 同行 ]
<- 是 / 否
[ 协调员 ] -> 提交 / 回滚 [ 同行 ]
<- 确认
在第一阶段(投票阶段)中,协调者将更新发送给所有参与者。每个参与者处理更新并投票决定是提交还是中止。当投票决定提交时,参与者将更新存储在临时区域(写前日志)中。在第二阶段完成之前,更新被视为临时的。
在第二阶段(决策)中,协调员决定结果并通知每个参与者。 如果所有参与者都投票决定提交,则更新将从临时区域获取并变为永久更新。
在提交变更之前设置第二阶段是有用的,因为它允许系统在节点失败时回滚更新。相比之下,在主/备份("1PC")中,没有回滚操作的步骤,当一些节点失败而其他节点成功时,副本可能会发生分歧。
2PC 容易出现阻塞的情况,因为单个节点的故障(参与者或协调者)会阻碍进展,直到节点恢复为止。恢复通常是通过第二阶段实现的,期间其他节点会被告知系统状态。请注意,2PC 假设每个节点的稳定存储中的数据永远不会丢失,并且没有节点永远崩溃。如果稳定存储中的数据在崩溃中被损坏,仍然可能会发生数据丢失。
节点故障期间的恢复过程的详细信息非常复杂,因此我不会涉及具体细节。主要任务包括确保对磁盘的写操作是持久的(例如,刷新到磁盘而不是缓存),并确保做出正确的恢复决策(例如,学习回合的结果,然后在本地重做或撤消更新)。
正如我们在有关 CAP 的章节中所学到的那样,2PC 是一个 CA - 它不支持分区容错。2PC 处理的故障模型不包括网络分区;从节点故障中恢复的规定方法是等待网络分区恢复。如果一个协调者失败了,没有安全的方法来提升一个新的协调者;而是需要手动干预。2PC 也非常敏感于延迟,因为它是一种写 N-of-N 方法,在最慢的节点确认之前,写操作无法进行。
2PC在性能和容错性之间取得了一个不错的平衡,这就是为什么它在关系型数据库中很受欢迎。然而,新的系统通常使用分区容忍的共识算法,因为这样的算法可以提供从临时网络分区中的自动恢复,以及更优雅地处理节点间延迟增加。
让我们来看一下分区容错共识算法。
分区容错一致性算法
分区容错一致性算法是我们在保持单副本一致性方面所能达到的最远的容错算法。还有一类容错算法:可以容忍任意(拜占庭)错误的算法;这些错误包括通过恶意行为导致的节点故障。这样的算法在商业系统中很少使用,因为运行成本更高,实现更复杂 - 因此我会忽略它们。
当涉及到分区容错一致性算法时,最著名的算法是 Paxos 算法。然而,它被广泛认为是难以实现和解释的,因此我将专注于 Raft 算法,这是一个最近(大约 2013 年初)设计得更易于教授和实现的算法。让我们首先来看一下网络分区和分区容错一致性算法的一般特性。
什么是网络分区?
网络分区是指一个或多个节点与网络链接的失败。节点本身仍然保持活动状态,甚至可能能够接收来自网络分区一侧的客户端请求。正如我们之前学到的 - 在讨论 CAP 定理时 - 网络分区确实会发生,并且并非所有系统都能优雅地处理它们。
网络分区很棘手,因为在网络分区期间,无法区分远程节点故障和节点无法访问。如果发生网络分区但没有节点故障,则系统被划分为两个同时活动的分区。下面的两个示意图说明了网络分区如何与节点故障类似。
一个由2个节点组成的系统,其中一个节点故障与网络分区:
一个由3个节点组成的系统,出现故障或网络分区:
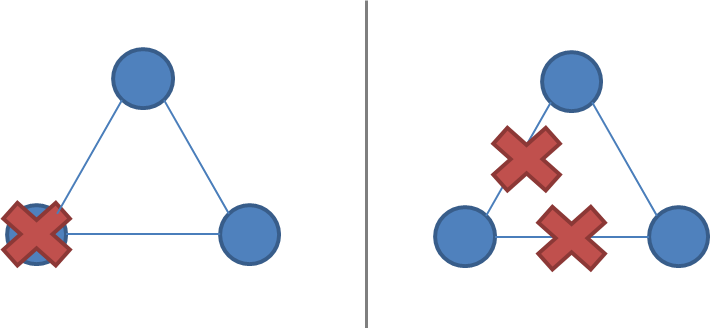
实施单副本一致性的系统必须具备一些打破对称性的方法:否则,它将分裂成两个独立的系统,这两个系统可以相互分歧,并且无法再维持单一副本的幻象。
在强制实行单副本一致性的系统中,网络分区容错要求在网络分区期间,系统只能保持一个分区处于活动状态,因为在网络分区期间无法防止发散(例如 CAP 定理)。
多数决策
这就是为什么容忍分区的一致性算法依赖于多数票。要求大多数节点 - 而不是所有节点(如2PC中) - 对更新达成一致意见,允许部分节点失效、变慢或由于网络分区而无法访问。只要有 (N/2 + 1)-of-N 个节点正常运行且可访问,系统就可以继续运行。
分区容忍的共识算法使用奇数个节点(例如3、5或7个)。仅有两个节点时,发生故障后无法达成明确的多数意见。例如,如果节点数为三,则系统能够容忍一个节点故障;如果节点数为五,则系统能够容忍两个节点故障。
当网络分区发生时,分区的行为是不对称的。一个分区将包含大多数节点。少数分区将停止处理操作,以防止在网络分区期间发生分歧,但是多数分区可以保持活动状态。这确保了系统状态的唯一副本保持活动。
多数派也很有用,因为它们可以容忍不同意见:如果存在干扰或失败,节点可以投票不同。然而,由于只能有一个多数决策,临时的不同意见最多只能阻止协议继续进行(放弃活跃性),但不能违反单一副本一致性准则(安全性属性)。
角色
有两种方式可以组织一个系统:所有节点可以拥有相同的责任,或者节点可以拥有独立的、不同的角色。
复制的共识算法通常选择为每个节点分配不同的角色。拥有一个单一的固定领导者或主服务器是一种优化,使系统更加高效,因为我们知道所有的更新都必须通过该服务器。不是领导者的节点只需要将他们的请求转发给领导者。
请注意,拥有不同的角色并不意味着系统无法从领导者(或任何其他角色)的故障中恢复。仅仅因为在正常操作期间角色是固定的,并不意味着在故障后不能通过重新分配角色来恢复(例如通过领导者选举阶段)。节点可以重复使用领导者选举的结果,直到发生节点故障和/或网络分区。
无论 Paxos 还是 Raft 都使用不同的节点角色。特别是,它们都有一个领导节点(在 Paxos 中被称为“提议者”),负责在正常操作期间进行协调。在正常操作期间,其余的节点都是追随者(在 Paxos 中被称为“接受者”或“选民”)。
时期
在 Paxos 和 Raft 中,每个正常操作的时期都被称为一个时期(在 Raft 中称为“术语”)。在每个时期中,只有一个节点被指定为领导者(日本也采用了类似的系统,在天皇更替时改变时代名称)。

在一次成功的选举之后,同一位领导人一直协调直到时代结束。如上图所示(取自 Raft 论文),有些选举可能会失败,导致时代立即结束。
纪元充当逻辑时钟,使其他节点能够识别出过时节点开始通信的时间 - 被分区或停止运行的节点的纪元号会比当前节点较小,它们的命令将被忽略。
通过决斗进行的领导人更迭
在正常操作期间,一个容错共识算法是相当简单的。正如我们之前所看到的,如果我们不关心容错性,我们可以简单地使用2PC。大部分复杂性实际上来自于确保一旦达成共识决策,它将不会丢失,并且协议可以处理由于网络或节点故障而引起的领导者更替。
所有节点最初都是跟随者;在开始时,选择一个节点作为领导者。在正常操作期间,领导者维持一个心跳,使得跟随者能够检测到领导者是否失败或被分割。
当一个节点检测到领导者变得无响应(或者在最开始的情况下,没有领导者存在),它会切换到一个中间状态(在 Raft 中称为 "候选人"),在这个状态中,它会将任期/纪元值增加一,发起领导者选举,并竞争成为新的领导者。
为了当选为领导者,一个节点必须获得大多数的选票。一种分配选票的方式是简单地按照先到先得的原则进行分配;这样一来,最终会选出一个领导者。在尝试当选时,加入随机的等待时间会减少同时尝试当选的节点数量。
时期内的编号提案
在每个时期中,领导者一次提议一个值供投票。在每个时期内,每个提议都用唯一的严格递增的数字进行编号。追随者(投票人/接受者)接受他们收到的特定提议编号的第一个提议。
正常运行
在正常运行期间,所有提案都通过领导节点进行。当客户端提交提案(例如更新操作)时,领导者联系协商组中的所有节点。如果不存在竞争提案(根据从跟随者节点得到的响应判断),领导者提出该值。如果大多数跟随者接受该值,则认为该值已被接受。
由于可能有其他节点也试图充当领导者,我们需要确保一旦一个提案被接受,其值就不能改变。否则,已经被接受的提案可能会被竞争的领导者撤销。Lamport将其陈述如下:
P2:如果选择了一个值为
v的提案,则选择的每个较高编号的提案都具有值v。
确保这个属性成立需要算法限制追随者和提议者永远不改变被大多数接受的值。注意,“值永远不会改变”是指协议的单次执行(或运行/实例/决策)的值。典型的复制算法会运行算法的多次执行,但大多数对算法的讨论都集中在单次运行上以保持简单。我们希望防止决策历史被修改或覆盖。
为了强制执行这个属性,提议者必须首先向跟随者询问他们(最高编号的)接受的提议和值。如果提议者发现已经存在一个提议,则它必须简单地完成协议的执行,而不是提出自己的提议。 Lamport将其陈述如下:
P2b. 如果选择了一个值为
v的提案,那么任何提案者发布的比该提案编号更高的提案都具有值v。
更具体地说:
P2c. 对于任意的
v和n,如果一个具有值为v和编号为n的提案被 [领导者] 发布,那么存在一个由大多数接受者 [追随者] 组成的集合S,使得以下情况之一成立:(a)S中的任何接受者都没有接受过编号小于n的任何提案,或者 (b)v是在S中的追随者们接受的所有编号小于n的提案中编号最高的提案的值。
这是 Paxos 算法的核心,以及从中派生的算法。要提出的值直到协议的第二阶段才会被选择。提议者有时必须简单地重传先前做出的决定以确保安全性(例如 P2c 中的条款 b),直到他们达到一个他们知道自己可以强加自己的提议值的点(例如条款 a)。
如果存在多个之前的提案,则提议最高编号的提案值。如果根本没有竞争提案,提议者只能尝试强制使用自己的值。
为了确保在提议者询问每个接受者其最新值的时间段内没有出现竞争性提议,提议者要求追随者不接受比当前提议号更低的提议。
将所有的碎片组合在一起,使用 Paxos 达成决策需要两轮通信:
[提议者] -> 准备(n) [跟随者]
<- 承诺(n; 上一个提议编号和上一个被接受的提议的值)
[提议者] -> 接受请求(n, 自身的值或者跟随者报告的最高提议编号对应的值) [跟随者]
<- 被接受(n, 值)
准备阶段允许提议者了解任何竞争或先前的提议。第二阶段是提议新值或先前接受的值。在某些情况下,比如同时有两个提议者活动(决斗),消息丢失,或者大多数节点失败,那么没有提议会被多数接受。但这是可以接受的,因为决定提议何值的规则会收敛到一个单一值(在先前尝试中具有最高提议编号的值)。
确实,根据 FLP 不可能性结果,这是我们能做到的最好的:解决共识问题的算法在消息传递边界不满足保证时,要么放弃安全性,要么放弃活跃性。Paxos 放弃了活跃性:它可能不得不无限期地延迟决策,直到没有竞争的领导者,以及大多数节点接受一个提议。这比违反安全性保证更可取。
当然,实现这个算法比听起来要困难得多。有许多小问题,即使在专家手中也会积累成相当大量的代码。这些问题包括:
- 实用优化:
- 通过使用领导租约(而不是心跳)避免重复进行领导选举
- 在稳定状态下避免重复提议消息,其中领导者身份不会改变
- 确保跟随者和提议者不会在稳定存储中丢失项目,并且存储在稳定存储中的结果不会受到微妙的损坏(例如磁盘损坏)
- 以安全方式启用集群成员身份的更改(例如,基于 Paxos 的方法依赖于多数节点始终相交,如果成员身份可以任意更改,则不成立)
- 在崩溃、磁盘丢失或新节点配置后,以安全且高效的方式将新副本更新至最新状态的程序
- 对于在一段合理的时间后保证安全性所需的数据进行快照和垃圾回收的程序(例如,平衡存储需求和容错需求)
Google's Paxos Made Live paper details some of these challenges.
分区容错一致性算法:Paxos, Raft, ZAB
希望这让你对分区容忍的共识算法如何工作有所了解。我鼓励你阅读进一步阅读部分的其中一篇论文,以掌握不同算法的具体细节。
Paxos。Paxos 是在编写强一致性分区容忍的复制系统时最重要的算法之一。它被用于许多谷歌的系统中,包括Chubby 锁管理器,被BigTable/Megastore使用,以及谷歌文件系统和Spanner。
Paxos是以希腊的帕科斯岛命名的,最初由莱斯利·兰波特在1998年的一篇名为《兼职议会》的论文中提出。人们普遍认为它很难实现,并且有一系列来自具有相当分布式系统专业知识的公司的论文进一步解释了实际细节(参见进一步阅读)。你可能想阅读兰波特对此问题的评论这里和这里。
这些问题主要涉及到 Paxos 在单轮共识决策中的描述,但实际工作中的实现通常希望以高效的方式运行多轮共识。这导致了许多核心协议的扩展的开发,任何希望构建基于 Paxos 的系统的人都需要理解这些扩展。此外,还存在其他实际挑战,比如如何促进集群成员的变更。
ZAB。ZAB - Zookeeper原子广播协议,用于Apache Zookeeper。Zookeeper是一个为分布式系统提供协调原语的系统,被许多以Hadoop为中心的分布式系统用于协调(例如HBase,Storm,Kafka)。Zookeeper基本上是开源社区版本的Chubby。从技术上讲,原子广播是与纯共识不同的问题,但它仍属于确保强一致性的容错算法类别。
漂流木。漂流木是这类算法的最新(2013年)添加。它的设计目标是比 Paxos 更易于教授,同时提供相同的保证。特别是,算法的不同部分更清晰地分离,并且该论文还描述了一种集群成员变更的机制。最近,它在etcd中得到了采用,受到了 ZooKeeper 的启发。
具有强一致性的复制方法
在这一章中,我们看了强一致性的复制方法。从同步工作和异步工作的对比开始,我们逐步介绍了越来越复杂故障容忍的算法。以下是每个算法的一些关键特点:
主/备份
- 单一,静态的主节点
- 复制日志,从节点不参与执行操作
- 复制延迟没有上限
- 不具备分区容错性
- 手动/临时故障转移,不具备容错性,"热备份"
两阶段提交
- 全体一致的投票:提交或中止
- 静态主节点
- 在提交期间,如果协调器和一个节点同时发生故障,2PC 无法生存
- 不具备分区容错性,对尾延迟敏感
Paxos协议
- 多数投票
- 动态主节点
- 作为协议的一部分,能够容忍 n/2-1 个同时故障
- 对尾部延迟不太敏感
进一步阅读
主备和2PC
- Replication techniques for availability - Robbert van Renesse & Rachid Guerraoui, 2010
- Concurrency Control and Recovery in Database Systems
Paxos(帕克索斯)
- The Part-Time Parliament - Leslie Lamport
- Paxos Made Simple - Leslie Lamport, 2001
- Paxos Made Live - An Engineering Perspective - Chandra et al
- Paxos Made Practical - Mazieres, 2007
- Revisiting the Paxos Algorithm - Lynch et al
- How to build a highly available system with consensus - Butler Lampson
- Reconfiguring a State Machine - Lamport et al - changing cluster membership
- Implementing Fault-Tolerant Services Using the State Machine Approach: a Tutorial - Fred Schneider
Raft 和 ZAB
- In Search of an Understandable Consensus Algorithm, Diego Ongaro, John Ousterhout, 2013
- Raft Lecture - User Study
- A simple totally ordered broadcast protocol - Junqueira, Reed, 2008
- ZooKeeper Atomic Broadcast - Reed, 2011
5. 复制:弱一致性模型协议
现在,我们已经对在越来越多的实际故障情况下可以强制实施单副本一致性的协议有了初步了解,让我们把注意力转向一旦放弃单副本一致性要求所打开的选择世界。
总的来说,很难找到一个单一的维度来定义或描述允许复制品分歧的协议。大多数这样的协议都是高度可用的,关键问题更多地是终端用户是否发现保证、抽象和应用程序接口对他们的目的有用,尽管当节点和/或网络故障发生时,复制品可能会发生分歧。
为什么弱一致性系统没有更受欢迎?
正如我在引言中所陈述的,我认为分布式编程的很大一部分是关于处理分布的两个后果的影响:
- 信息传输速度等于光速
- 独立的事物独立失败
信息传输速度的限制导致节点以不同且独特的方式体验世界。在单个节点上进行计算很容易,因为一切都按照可预测的全局总序发生。在分布式系统上进行计算很困难,因为没有全局总序。
在最长的一段时间内(例如几十年的研究),我们通过引入全局总顺序来解决这个问题。我已经讨论了许多方法,通过创建顺序(以容错的方式)来实现强一致性,在没有自然发生的总顺序的情况下。
当然,问题在于强制执行秩序是昂贵的。特别是在大规模的互联网系统中,系统需要保持可用性。一个强制执行强一致性的系统不像一个分布式系统:它表现得像一个单一的系统,在分区期间可用性较差。
此外,对于每个操作,通常需要联系大部分节点 - 而且通常不止一次,而是两次(正如你在 2PC 的讨论中所看到的)。这对于需要在全球用户基础上提供足够性能的地理分布式系统来说尤为痛苦。
因此,默认情况下表现得像一个单一系统可能并不理想。
也许我们想要的是一个不需要昂贵协调的代码编写系统,但是却能返回一个“可用”的值。我们不再拥有一个单一的真相,而是允许不同的复本相互分歧-既要保持效率,也要容忍分区-然后尝试找到一种处理分歧的方式。
最终一致性表达了这个观念:各个节点在某段时间内可能会出现分歧,但最终它们会达成一致的价值。
在提供最终一致性的系统集合中,有两种类型的系统设计:
概率保证的最终一致性。这种类型的系统可以在稍后的某个时间点检测到冲突的写入,但不能保证结果等同于某个正确的顺序执行。换句话说,冲突的更新有时会用旧值覆盖新值,并且在正常操作(或分区期间)可能会出现一些异常情况。
在近年来,最具影响力的单副本一致性系统设计是亚马逊的Dynamo,作为一个提供概率保证的最终一致性系统的例子,我将对其进行讨论。
具有强一致性保证的最终一致性。这种类型的系统保证结果会收敛到一个与某个正确的顺序执行等价的共同值。换句话说,这样的系统不会产生任何异常结果;在没有任何协调的情况下,您可以构建相同服务的副本,并且这些副本可以以任何模式进行通信并以任何顺序接收更新,并且只要它们都看到相同的信息,它们最终将就最终结果达成一致。
CRDT的(convergent replicated data types)是一种数据类型,它们保证在网络延迟、分区和消息重排序的情况下收敛到相同的值。它们经过验证是收敛的,但可以作为CRDT的数据类型是有限的。
CALM(一致性作为逻辑单调性)猜想是同一原理的另一种表达方式: 它将逻辑单调性等同于收敛。如果我们可以得出某个东西是逻辑单调的结论, 那么在没有协调的情况下运行也是安全的。收敛分析 - 特别是在应用于 Bloom编程语言时 - 可用于指导程序员在何时何地使用 来自强一致性系统的协调技术以及何时可以安全地执行 没有协调。
调和不同的操作顺序
不强制实施单副本一致性的系统是什么样子的?让我们通过看几个例子来更具体地了解一下。
也许最明显的非强制单一副本一致性系统的特性就是允许副本彼此分歧。这意味着没有严格定义的通信模式:副本可以相互分离,但仍然可用并接受写入。
让我们想象一个由三个副本组成的系统,每个副本都与其他副本分离。例如,这些副本可能位于不同的数据中心,并且由于某种原因无法进行通信。在分离期间,每个副本仍然可用,接受一些客户端的读取和写入操作:
[客户] - > [A] --- 分区 --- [客户] - > [B] --- 分区 --- [客户] - > [C]
经过一段时间,分区会恢复并且副本服务器会交换信息。它们从不同的客户端接收到不同的更新,彼此发生了分歧,所以需要进行某种形式的协调。我们希望发生的是所有的副本都收敛到相同的结果。
[A] \
--> [合并]
[B] / |
|
[C] ----[合并]---> 结果
另一种思考具有弱一致性保证的系统的方法是想象一组客户端按照某种顺序向两个副本发送消息。由于没有强制执行单个总顺序的协调协议,消息可以以不同的顺序传递到两个副本中:
[客户] --> [A] 1, 2, 3 [客户] --> [B] 2, 3, 1
从本质上讲,这就是我们需要协调协议的原因。例如,假设我们正在尝试连接一个字符串,而消息1、2和3中的操作是:
1: { 操作:连接('你好') }
2: { 操作:连接('世界') }
3: { 操作:连接('!') }
然后,没有协调,A将会产生"你好世界!",而B将会产生"世界!你好"。
A: concat(concat(concat('', '你好 '), '世界'), '!') = '你好 世界!'
B: concat(concat(concat('', '世界'), '!'), '你好 ') = '世界!你好 '
这当然是不正确的。我们希望发生的是副本收敛到相同的结果。
记住这两个例子,让我们首先看看亚马逊的 Dynamo 来建立一个基准,然后再讨论一些新颖的方法来构建具有弱一致性保证的系统,例如 CRDT 和 CALM 定理。
亚马逊的Dynamo
亚马逊的Dynamo系统设计(2007年)可能是最知名的提供弱一致性保证但高可用性的系统。它是许多其他现实世界系统的基础,包括LinkedIn的Voldemort,Facebook的Cassandra和Basho的Riak。
动力学是一种最终一致性、高可用的键-值存储。键值存储类似于一个大的哈希表:客户端可以通过set(key, value)设置值,并通过键使用get(key)检索值。一个动力学集群由N个对等节点组成;每个节点都有一组它负责存储的键。
Dynamo优先保证可用性而不是一致性;它不能保证单一副本的一致性。相反,当值被写入时,副本之间可能会发生分歧;当读取一个键时,会有一个读取协调阶段,试图在将值返回给客户端之前协调副本之间的差异。
对于亚马逊上的许多功能而言,避免故障比确保数据完全一致更为重要,因为故障可能导致业务损失和信誉丧失。此外,如果数据不是特别重要,那么弱一致性系统可以提供比传统关系型数据库更好的性能和更高的可用性,而且成本更低。
由于 Dynamo 是一个完整的系统设计,除了核心的复制任务外,还有很多不同的部分需要考虑。下面的图表说明了一些任务,特别是写入如何被路由到一个节点并写入多个副本。
[客户端] | (将键映射到节点) | V [节点A] | \ (同步复制任务: 最小耐久性) | \ [节点B] [节点C] A | (冲突检测; 异步复制任务: 确保分区/恢复节点能够恢复) | V [节点D]
在查看写操作的初始接受情况之后,我们将看一下如何检测冲突,以及异步的副本同步任务。由于高可用性设计,节点可能会暂时无法使用(宕机或分区),因此需要进行副本同步任务,以确保节点在故障后能够相对迅速地追赶上来。
一致性哈希
无论我们是阅读还是写作,首先需要做的是定位数据在系统中的存储位置。这需要一种键到节点的映射。
在 Dynamo 中,使用一种称为一致性哈希的哈希技术将键映射到节点(我不会详细讨论)。 主要思想是通过对客户端进行简单计算,将键映射到负责它的一组节点。这意味着客户端可以定位键,而无需查询系统的每个键的位置;这样可以节省系统资源,因为哈希通常比执行远程过程调用更快。
部分法定人数
一旦我们知道应该存储密钥的位置,我们需要做一些工作来保持值的持久性。这是一个同步任务;我们立即将值写入多个节点的原因是为了提供更高级别的耐久性(例如,防止节点的立即故障)。
就像 Paxos 或者 Raft 一样,Dynamo 使用 quorums 进行复制。然而,Dynamo 的 quorums 是松散的(部分的) quorums,而不是严格的(多数的) quorums。
非正式地说,严格的法定人数系统是具有以下属性的法定人数系统:任何两个法定人数(集合)在法定人数系统中是重叠的。在接受更新之前要求大多数人投票赞成可以确保只有一个历史记录被接受,因为每个大多数法定人数必须至少在一个节点上重叠。例如,Paxos 就依赖于这个属性。
部分法定人数没有这个特性;这意味着不需要多数,而且法定人数的不同子集可能包含相同数据的不同版本。用户可以选择要写入和读取的节点数量:
- 用户可以选择一些节点的数量 W-of-N,以满足写操作的要求;和
- 用户可以指定在读操作期间要联系的节点数量 (R-of-N)。
W和R指定需要参与写入或读取的节点数。 写入到更多的节点会使写入速度稍慢,但增加了值不丢失的概率; 从更多的节点读取增加了读取到最新值的概率。
通常的建议是 R + W > N,因为这意味着读取和写入的仲裁在一个节点上重叠 - 这样更不容易返回过时的值。一个典型的配置是 N = 3(例如每个值的总共三个副本);这意味着用户可以在以下选项之间选择:
R = 1,W = 3; R = 2,W = 2 或者 R = 3,W = 1
更一般地,再次假设 R + W > N:
R = 1,W = N:快速读取,慢速写入R = N,W = 1:快速写入,慢速读取R = N/2和W = N/2 + 1:对两者都有利
N 很少超过 3,因为保留这么多大量数据的副本会变得很昂贵!
正如我之前提到的,Dynamo 论文启发了许多其他类似的设计。它们都使用了相同的部分仲裁基于复制的方法,但是对于 N、W 和 R 的默认值不同:
- 芭蕉的Riak(N = 3,R = 2,W = 2默认)
- 领英的Voldemort(N = 2或3,R = 1,W = 1默认)
- Apache的Cassandra(N = 3,R = 1,W = 1默认)
还有一个细节:在发送读取或写入请求时,是要求所有 N 个节点都回应(Riak),还是只需要满足最低要求的节点数(例如 R 或 W;Voldemort)回应。"发送给所有"的方法更快,对延迟更不敏感(因为它只等待 N 个节点中最快的 R 或 W 节点),但效率较低;而"发送给最小要求"的方法对延迟更敏感(因为与单个节点通信的延迟会延迟操作),但效率更高(总的消息 / 连接更少)。
当读写的法定人数重叠时,例如 (R + W > N),会发生什么情况?具体来说,经常有人声称这会导致"强一致性"。
R + W > N 是否等同于“强一致性”?
编号
这并不完全没有道理:一个满足 R + W > N 条件的系统可以检测到读/写冲突,因为任何读取仲裁集和任何写入仲裁集都会共享一个成员。例如,至少有一个节点同时在两个仲裁集中:
1 2 N/2+1 N/2+2 N [...] [读] [读 + 写] [写] [...]
这保证了之前的写操作会被后续的读操作看到。然而,这仅在 N 中的节点不发生变化时才成立。因此,Dynamo 不符合要求,因为在 Dynamo 中,集群成员关系可能会发生变化,例如节点故障。
Dynamo 被设计为始终可写。它有一种机制,通过在原始服务器宕机时将一个不同的、不相关的服务器添加到负责某些键的节点集合中来处理节点故障。这意味着不再保证四分之一总数始终重叠。即使 R = W = N,也不符合要求,因为虽然四分之一大小等于 N,但在故障期间,这些四分之一中的节点可能会发生变化。具体来说,在分区期间,如果无法达到足够数量的节点,Dynamo 将从不相关但可访问的节点中添加新节点到四分之一中。
此外,Dynamo不像强一致性模型所要求的那样处理分区:即,允许在分区的两侧进行写操作,这意味着至少在某段时间内系统不会作为单一副本进行操作。因此,将 R + W > N 称为"强一致性"是具有误导性的;这个保证仅仅是概率性的 - 这不是强一致性所指的。
冲突检测和读修复
允许副本发散的系统必须有一种方法来最终协调两个不同的值。如部分法定人数方法中简要提到的,一种方法是在读取时检测冲突,然后应用一些冲突解决方法。但是这是如何实现的呢?
通常情况下,这是通过跟踪数据的因果历史并补充一些元数据来完成的。客户端在从系统中读取数据时必须保留元数据信息,并在写入数据库时返回元数据值。
我们已经遇到了一种实现这一目标的方法:向量时钟可以用来表示一个值的历史。事实上,这就是原始的Dynamo设计用于检测冲突的方法。
然而,使用向量时钟并不是唯一的选择。如果你看一下许多实际系统设计,你可以通过查看它们追踪的元数据,推断出它们的工作原理。
无元数据。当系统不跟踪元数据,并且仅返回值(例如通过客户端 API),它实际上无法对并发写操作做任何特殊处理。一个常见的规则是最后一个写入者获胜:换句话说,如果两个写入者同时写入,只保留最慢写入者的值。
时间戳。名义上,具有较高时间戳值的值将获胜。然而,如果时间没有被仔细同步,许多奇怪的事情可能会发生,其中来自具有有故障或快速时钟的系统的旧数据会覆盖较新的值。Facebook的Cassandra是Dynamo的一种变体,它使用时间戳而不是向量时钟。
版本号。版本号可能会避免使用时间戳相关的一些问题。请注意,当存在多个历史时,能够准确跟踪因果关系的最小机制是向量时钟,而不是版本号。
向量时钟。使用向量时钟,可以检测到并发和过时的更新。然后可以执行读修复,尽管在某些情况下(并发更改)我们需要要求客户端选择一个值。这是因为如果更改是并发的,并且我们对数据没有更多了解(如简单的键值存储),那么询问比随机丢弃数据更好。
当读取一个值时,客户端会联系R个N节点,并向它们请求最新的键值。它会接收所有的响应,并丢弃那些严格旧的值(使用向量时钟值来检测)。如果只有一个唯一的向量时钟+值对,它会返回该对。如果有多个同时被编辑的向量时钟+值对(例如不可比较),那么所有这些值都会被返回。
正如上文所示,读修复可能会返回多个值。这意味着客户端/应用开发者必须偶尔根据某些用例特定的标准选择一个值来处理这些情况。
此外,实用的向量时钟系统的一个关键组成部分是,时钟不能永远增长 - 因此需要有一个程序来定期以安全的方式垃圾回收时钟,以在容错性和存储要求之间保持平衡。
副本同步:传闻和默克尔树
考虑到 Dynamo 系统设计对节点故障和网络分区具有容错性,它需要一种处理节点重新加入集群的方法,无论是因为分区后重新加入,还是因为替换或部分恢复了失败的节点。
复制品同步用于在故障后将节点更新到最新状态,并定期将复制品互相同步。
八卦是一种用于同步副本的概率技术。通信的模式(例如,哪个节点联系哪个节点)不是事先确定的。相反,节点具有一定的概率 p 试图与彼此同步。每 t 秒,每个节点选择一个节点进行通信。这提供了一个额外的机制,超出了同步任务(例如,部分仲裁写入),使副本保持最新。
闲话传闻是可扩展的,并且没有单一的故障点,但只能提供概率性的保证。
为了使副本同步期间的信息交换更加高效,Dynamo使用一种称为Merkle树的技术,我将不会详细介绍。关键思想是数据存储可以以多个不同的粒度进行哈希:表示整个内容的哈希,一半的键的哈希,四分之一的键的哈希,以此类推。
通过保持这种相当细粒度的哈希,节点可以比使用简单技术更高效地比较其数据存储内容。一旦节点确定了哪些键具有不同的值,它们会交换必要的信息以使副本保持最新。
Dynamo实践中的概率有界陈旧度(PBS)
这基本上涵盖了 Dynamo 系统的设计:
- 一致性哈希算法用于确定键的位置
- 读取和写入的部分法定人数
- 通过向量时钟进行冲突检测和读取修复
- 使用八卦协议进行副本同步
我们如何描述这样一个系统的行为?Bailis等人(2012)最近的一篇论文中描述了一种叫做PBS(概率有界陈旧度)的方法,它利用模拟和从现实世界系统中收集的数据来描述这样一个系统的预期行为。
PBS 通过使用有关反熵(八卦)速率、网络延迟和本地处理延迟的信息来估计不一致性的程度,从而估计读取一致性的预期水平。它已经在 Cassandra 中实现,在其他消息上附加定时信息,并根据这些信息的样本计算出一个估计值,使用蒙特卡洛模拟进行计算。
根据这篇论文,在正常运行时,最终一致的数据存储通常更快,并且可以在数十或数百毫秒内读取一致的状态。下表说明了在 LinkedIn(SSD 和 15k RPM 磁盘)和 Yammer 的经验计时数据中,给定不同的 R 和 W 设置时,读取一致性的99.9%概率所需的时间:

例如,在 Yammer 案例中,从 R=1,W=1 变为 R=2,W=1 可以将不一致窗口减少从 1352 毫秒到 202 毫秒 - 同时保持读取延迟更低(32.6 毫秒),比最快的严格法定人数(R=3,W=1; 219.27 毫秒)。
更多细节,请查看PBS 网站和相关论文。
无序编程
让我们回顾一下我们希望解决的不同情况的示例。第一个场景包括在分区后的三个不同服务器上; 在分区恢复后,我们希望服务器收敛到相同的值。亚马逊的Dynamo通过从R个节点中读取数据,然后执行读取协调来实现这一点。
在第二个例子中,我们考虑了一个更具体的操作:字符串拼接。事实证明,没有已知的技术可以使字符串拼接在没有对操作施加顺序(例如,没有昂贵的协调)的情况下得到相同的值。然而,有些操作可以以任意顺序安全地应用,而简单的寄存器则无法做到这一点。正如Pat Helland所写:
...操作中心的工作可以通过正确的操作和正确的语义使其成为可交换的,而简单的读/写语义则不适合交换性。
例如,考虑一个实现简单会计系统的系统,其中使用两种不同的方式进行借方和贷方操作:
- 使用具有
读取和写入操作的寄存器,并且 - 使用具有本地
借方和贷方操作的整数数据类型
后一种实现方式更了解数据类型的内部情况,因此即使操作被重新排序,它仍然可以保留操作的意图。借记或贷记可以以任何顺序应用,最终结果是相同的:
100 + 信用(10) + 信用(20) = 130 and 100 + 信用(20) + 信用(10) = 130
然而,无法按任意顺序编写固定值:如果重新排序写入操作,其中一个写入操作将覆盖另一个写入操作:
100 + 写入(110) + 写入(130) = 130 但是 100 + 写入(130) + 写入(110) = 110
让我们来看一下本章开头的例子,但使用不同的操作。在这种情况下,客户端向两个节点发送消息,这两个节点以不同的顺序看到这些操作:
[客户] --> [A] 1, 2, 3 [客户] --> [B] 2, 3, 1
不是使用字符串连接,假设我们要找到一组整数的最大值(例如MAX())。消息1、2和3是:
1: { 操作:取最大值(前一个值,3) }
2: { 操作:取最大值(前一个值,5) }
3: { 操作:取最大值(前一个值,7) }
然后,没有协调,A和B都会收敛到7,例如:
A: 最大值(最大值(最大值(0, 3), 5), 7) = 7 B: 最大值(最大值(最大值(0, 5), 7), 3) = 7
在这两种情况下,两个副本以不同的顺序看到更新,但我们可以以一种方式合并结果,使其无论顺序如何都具有相同的结果。由于我们使用的合并过程(max),结果在这两种情况下都会收敛到相同的答案。
很可能不可能编写适用于所有数据类型的合并程序。在Dynamo中,一个值是一个二进制blob,所以最好的方法是将其公开,并要求应用程序处理每个冲突。
然而,如果我们知道数据是某种更具体的类型,处理这些冲突就成为可能。CRDT 是设计用来提供数据类型的数据结构,只要它们看到相同的操作集合(无论顺序如何),就可以始终收敛。
CRDTs:收敛复制数据类型
CRDTs(收敛复制数据类型)利用特定数据类型上特定操作的交换律和结合律的知识。
为了在仅偶尔通信的副本环境中,使一组操作收敛于相同的值,这些操作需要是无序的,并且对(消息)重复/重新传递不敏感。因此,它们的操作需要是:
- 关联性(
a+(b+c)=(a+b)+c),因此分组无关紧要 - 交换性(
a+b=b+a),因此应用顺序无关紧要 - 幂等性(
a+a=a),因此重复无关紧要
事实证明,这些结构在数学中已经被熟知;它们被称为“联合”或“交集”半格。
一个格是一个部分有序集合,具有明确的顶部(最小上界)和明确的底部(最大下界)。一个半格是一个类似于格的结构,但只具有明确的顶部或底部。一个上合半格是具有明确的顶部(最小上界)的半格,而一个下合半格是具有明确的底部(最大下界)的半格。
任何可以表示为半格(semilattice)的数据类型都可以作为一种数据结构来实现,并保证收敛。例如,计算一组值的 max() 将始终返回相同的结果,无论值的接收顺序如何,只要所有值最终都被接收到,因为 max() 操作是结合的、交换的和幂等的。
例如,这里有两个格子:一个是为集合绘制的,其中合并运算符是union(items),另一个是为严格递增的整数计数器绘制的,其中合并运算符是max(values):
{ a, b, c } 7
/ | \ / \
{a, b} {b,c} {a,c} 5 7
| \ / | / / | \
{a} {b} {c} 3 5 7
使用可以表示为半格的数据类型,您可以让副本以任何模式进行通信并以任何顺序接收更新,只要它们都看到相同的信息,它们最终将达成一致的结果。只要前提条件保持不变,这是一种可以保证的强大属性。
然而,将数据类型表示为半格通常需要一定程度的解释。许多数据类型实际上并不是无序的。例如,将项添加到集合中是可结合的、可交换的和幂等的。然而,如果我们也允许从集合中移除项,那么我们需要一些方法来解决冲突操作,比如add(A)和remove(A)。如果本地副本从未添加过元素,那么删除元素意味着什么?这种解决方案必须以无序的方式进行说明,并且有几种不同的选择,具有不同的权衡。
这意味着一些熟悉的数据类型作为CRDT的专用实现,以实现无序冲突解决的不同权衡。与仅处理寄存器(例如,系统角度看来是不透明的二进制大块)的键值存储不同,使用CRDT的人必须使用正确的数据类型来避免异常情况。
不同数据类型指定为CRDT的一些例子包括:
- 计数器
- 只增计数器(合并 = 最大值(values);有效负载 = 单个整数)
- 正负计数器(由两个增长计数器组成,一个用于增量,另一个用于减量)
- 寄存器
- 最后写入胜出寄存器(时间戳或版本号;合并 = 最大值(ts);有效负载 = 数据块)
- 多值寄存器(向量时钟;合并 = 同时获取两个值)
- 集合
- 只增集合(合并 = 并集(items);有效负载 = 集合;无删除操作)
- 两阶段集合(由两个集合组成,一个用于添加,另一个用于删除;元素只能添加一次和删除一次)
- 唯一集合(两阶段集合的优化版本)
- 最后写入胜出集合(合并 = 最大值(ts);有效负载 = 集合)
- 正负集合(每个集合项都有一个正负计数器)
- 观察删除集合
- 图形和文本序列(详见论文)
为了确保无异常操作,您需要为您特定的应用程序找到合适的数据类型 - 例如,如果您知道您只会删除一次项目,那么两阶段集合适用;如果您只会向集合中添加项目而不会删除它们,那么只增长的集合适用。
并非所有的数据结构都有已知的 CRDT 实现,但是在最近(2011年)Shapiro等人的调研论文中,对于布尔值、计数器、集合、寄存器和图形的 CRDT 实现进行了介绍。
有趣的是,寄存器的实现直接对应于键值存储使用的实现:一个最后写入胜的寄存器使用时间戳或一些等价物,并且简单地收敛到最大的时间戳值;一个多值寄存器对应于 Dynamo 策略,即保留、暴露和协调并发更改。关于细节,我建议您查看本章的进一步阅读部分中的论文。
CALM 定理
CRDT 数据结构是基于一个认识,即可表达为半格的数据结构是收敛的。但编程不仅仅是关于状态的演化,除非你只是在实现一个数据存储。
显然,无序性是任何收敛计算的重要特性:如果数据项接收的顺序会影响计算结果,则无法在不保证顺序的情况下执行计算。
然而,在许多编程模型中,语句的顺序并不起重要作用。 例如,在MapReduce模型中,Map和 Reduce任务都被指定为无状态的元组处理任务,需要在数据集上运行。 数据如何以及以什么顺序路由到任务,不是明确指定的, 而是批处理作业调度程序负责将任务调度到集群上运行。
同样,在 SQL 中,我们指定了查询,但不指定查询的执行方式。查询只是任务的一种声明性描述,查询优化器的工作是找出一种高效的方式来执行查询(跨多个机器、数据库和表)。
当然,这些编程模型并不像通用编程语言那样宽容。 MapReduce 任务需要表达为无状态任务在无环数据流程序中;SQL 语句可以执行相当复杂的计算,但很多事情很难在其中表达。
然而,从这两个例子可以清楚地看出,有许多种数据处理任务适合用声明性语言表达,其中执行顺序没有明确指定。表达所需结果但将语句的确切顺序交给优化器决定的编程模型通常具有无序的语义。这意味着这样的程序可能可以在没有协调的情况下执行,因为它们依赖于接收到的输入,而不一定是输入接收的具体顺序。
关键点是这样的程序在没有协调的情况下可能是安全的执行。在没有明确界定什么是可以在没有协调的情况下安全执行的规则以及什么是不可以的情况下,我们不能实现一个程序并保持对结果正确性的确定。
这就是 CALM 定理的内容。CALM 定理基于对逻辑单调性和有用的最终一致性形式(例如,汇聚/收敛)之间关联的认识。它表明,在逻辑上单调的程序保证最终一致性。
然后,如果我们知道某个计算是逻辑上单调的,那么我们就知道它在没有协调的情况下执行也是安全的。
为了更好地理解这一点,我们需要将单调逻辑(或单调计算)与非单调逻辑(或非单调计算)进行对比。
单调性
如果句子 φ 是一组前提 Γ 的结果,那么它也可以从任何扩展 Γ 的前提集合 Δ 中推断出来
大多数标准逻辑框架都是单调的:在像一阶逻辑这样的框架中进行的推理,一旦在逻辑上有效,就不会被新信息否定。非单调逻辑是一种不具备这种特性的系统,换句话说,某些结论可以通过学习新知识被否定。
在人工智能领域,非单调逻辑与可废除推理相关联 - 这种推理是利用部分信息进行的,新的知识可以使得先前的断言无效。例如,如果我们得知小鸟是鸟类,我们会认为小鸟能够飞翔;但是如果我们后来得知小鸟是企鹅,那么我们就必须修正我们的结论。
单调性关注前提(或关于世界的事实)与结论(或关于世界的断言)之间的关系。在单调逻辑中,我们知道我们的结果是无撤回的:单调计算不需要重新计算或协调;答案会随着时间的推移变得更准确。一旦我们知道小鸟是鸟(并且我们正在使用单调逻辑进行推理),我们可以安全地得出结论,即小鸟可以飞,我们所学到的任何东西都不能否定这个结论。
虽然任何产生面向人类结果的计算都可以被解释为对世界的断言(例如,"foo"的值是"bar"),但很难确定基于冯·诺伊曼机编程模型的计算是否是单调的,因为事实和断言之间的关系以及这些关系是否是单调的并不完全清楚。
然而,有一些编程模型可以确定其单调性。特别是关系代数(例如 SQL 的理论基础)和Datalog提供了具有良好理解的高度表达性语言。
基本的Datalog和关系代数(即使有递归)都被认为是单调的。更具体地说, 使用一组特定的基本操作符表达的计算被认为是单调的(选择,投影,自然连接,笛卡尔积,并集和没有否定的递归Datalog),使用更高级的操作符引入了非单调性(否定,集合差异,除法,全称量词,聚合)。
这意味着在这些系统中使用大量操作符(例如map,filter,join,union,intersection)表示的计算是逻辑单调的;使用这些操作符的任何计算也是单调的,因此可以安全地在没有协调的情况下运行。另一方面,使用否定和聚合的表达式在没有协调的情况下运行是不安全的。
意识到非单调性与在分布式系统中执行昂贵操作之间的关联是很重要的。具体来说,分布式聚合和协调协议都可以被视为一种否定形式。正如Joe Hellerstein 所写:
为了在分布式环境中验证否定谓词的真实性,评估策略必须开始“计数到0”以确定是否为空,并等待分布式计数过程确切地终止。聚合是这个思想的泛化。
和:
这个想法也可以从另一个角度来看。协调协议本身就是聚合,因为它们涉及投票:两阶段提交需要全票通过,Paxos 共识需要多数票通过,拜占庭协议需要2/3多数票通过。等待需要计数。
如果我们能以一种能够测试单调性的方式来表达计算,那么我们就可以进行整个程序的静态分析,检测出哪些部分是最终一致且可以在没有协调的情况下运行的(即单调部分),以及哪些部分不是(非单调部分)。
请注意,这需要一种不同类型的语言,因为对于传统的编程语言来说,序列、选择和迭代是核心,很难进行这些推断。这就是为什么设计了 Bloom 语言。
非单调性有什么好处?
单调性和非单调性之间的区别很有趣。例如,添加两个数字是单调的,但计算包含数字的两个节点上的聚合不是。它们的区别是什么呢?其中一个是一个计算(添加两个数字),而另一个是一个断言(计算一个聚合)。
计算与断言有何不同?让我们考虑一下查询“披萨是蔬菜吗?”要回答这个问题,我们需要深入核心:什么时候可以推断出某件事是真实的(或不是真实的)?
有几个可以接受的答案,每个答案都对应着对我们所拥有的信息以及我们应该如何对其采取行动的不同假设集 - 而我们已经在不同的背景下接受了不同的答案。
在日常推理中,我们做出了所谓的开放世界假设:我们假设我们不知道一切,因此不能从缺乏知识中得出结论。也就是说,任何陈述都可能是真的、假的或未知的。
OWA + | OWA +
单调逻辑 | 非单调逻辑
可以推导出 P(true) | 可以断言 P(true) | 无法断言 P(true)
可以推导出 P(false) | 可以断言 P(false) | 无法断言 P(true)
无法推导出 P(true) | 未知 | 未知
或 P(false)
当做出开放世界的假设时,我们只能安全地断言从所知中可以推断出来的事情。 我们对世界的信息被假设为不完整的。
让我们首先看一下我们知道推理是单调的情况。在这种情况下,我们拥有的任何(可能不完整的)知识都不会因为学习新知识而失效。因此,如果我们可以根据一些推理,比如“含有两汤匙番茄酱的东西是蔬菜”和“比萨含有两汤匙番茄酱”,推断出一个句子是真的,那么我们可以得出“比萨是蔬菜”的结论。同样,如果我们可以推断出一个句子是假的,也是一样。
然而,如果我们无法推断出任何东西 - 例如,我们拥有的知识集包含客户信息,但没有关于比萨或蔬菜的信息 - 那么根据开放世界假设,我们必须说我们无法得出任何结论。
拥有非单调知识,我们现在所知道的任何事情都有可能被否定。因此,我们无法安全地得出任何结论,即使我们可以从我们当前知道的内容中推断出真或假。
然而,在数据库上下文中以及许多计算机科学应用中,我们更喜欢得出更确切的结论。这意味着假设所谓的封闭世界假设:即不能被证明为真的任何事物都被假设为假。这意味着不需要明确声明为假。换句话说,我们假设所拥有的事实数据库是完整的(最小的),因此可以假设不在其中的任何内容都是假的。
例如,在《清洁水法案》下,如果我们的数据库中没有旧金山到赫尔辛基的航班记录,那么我们可以安全地得出结论,没有这样的航班存在。
我们需要一个额外的东西才能够做出明确的断言:逻辑缩小。
缩小是一种推测的形式化规则。域缩小推测已知实体就是所有的实体。我们需要能够假设已知实体就是所有实体,以便得出明确的结论。
CWA + | CWA +
包含 + | 包含 +
单调逻辑 | 非单调逻辑
可以推导出 P(true) | 可以断言 P(true) | 可以断言 P(true)
可以推导出 P(false) | 可以断言 P(false) | 可以断言 P(false)
无法推导出 P(true) | 可以断言 P(false) | 可以断言 P(false)
或 P(false)
特别是,非单调推理需要这个假设。只有在我们假设我们拥有完整信息的情况下,我们才能做出自信的断言,因为额外的信息可能会使我们的断言无效。
这在实践中意味着什么?首先,单调逻辑一旦可以推导出一个句子是真(或假)的,就可以得出明确的结论。其次,非单调逻辑需要额外的假设:已知的实体就是全部。
所以为什么两个表面上相等的操作会不同呢?为什么将两个数字相加是单调的,但在两个节点上计算聚合不是呢? 因为聚合不仅仅计算总和,还要确保已经看到了所有的值。而确保这一点的唯一方法是在节点之间进行协作,确保执行计算的节点真正看到了系统中的所有值。
因此,为了处理非单调性,需要使用分布式协调来确保只在所有信息已知后才进行断言,或者在断言时附带一个警告,即结论可能在以后被否定。
处理非单调性对于表达能力来说非常重要。这意味着能够表达非单调的事物;例如,能够说某一列的总计是X是很好的。系统必须检测到这种计算需要全局协调边界,以确保我们已经看到了所有的实体。
纯单调系统很少见。似乎大多数应用程序都在封闭世界假设下运行,即使它们有不完整的数据,而我们人类对此也很满意。当一个数据库告诉你旧金山和赫尔辛基之间没有直飞航班时,你很可能会把它理解为“根据这个数据库,没有直飞航班”,但你并不排除在现实中可能仍然存在这样的航班。
事实上,只有在副本能够发生分歧时(例如在分区或正常运行期间由于延迟)这个问题才变得有趣。此时需要进行更具体的考虑:答案是基于当前节点还是整个系统的总体。
此外,由于非单调性是由于进行断言导致的,因此似乎很有可能许多计算可以在很长一段时间内进行,只在将某个结果或断言传递给第三方系统或最终用户的时候应用协调。当然,如果这些读取和写入操作只是长时间运行计算的一部分,那么并不需要在系统内的每个单个读取和写入操作都强制执行总排序。
布隆语言
这个 Bloom 语言 是一种旨在利用 CALM 定理的语言。它是一个基于叫做 Dedalus 的时间逻辑编程语言的 Ruby DSL。
在 Bloom 中,每个节点都有一个由集合和格构成的数据库。程序被表示为与集合(事实的集合)和格(CRDTs)进行交互的无序语句集合。语句默认情况下是无序的,但也可以编写非单调函数。
来看看Bloom 网站和教程以了解更多关于 Bloom 的信息。
更多阅读
CALM 定理,汇聚性分析和布隆过滤器
乔·赫勒斯坦在RICON 2012的演讲是该主题的一个很好的介绍,同样尼尔·康韦在Basho的演讲也是。对于布卢姆来说,可以参考彼得·阿尔瓦罗在微软的演讲。
- 声明式命令: 在分布式逻辑中的经验和猜测 - Hellerstein, 2010
- Bloom中的一致性分析: 一种 CALM 和有序的方法 - Alvaro 等,2011
- 逻辑和格子用于分布式编程 - Conway 等,2012
- Dedalus: 时间和空间中的 Datalog - Alvaro 等,2011
一致性复制数据类型
Marc Shapiro 在 Microsoft 的演讲是理解 CRDT 的一个很好的起点。
- CRDTs: 并发控制下的一致性 - Letitia等人,2009年
- 收敛和可交换复制数据类型的全面研究,Shapiro等人,2011年
- 优化的无冲突复制集 - Bieniusa等人,2012年
Dynamo; PBS; 乐观复制
- Dynamo: Amazon’s Highly Available Key-value Store - DeCandia et al., 2007
- PNUTS: Yahoo!'s Hosted Data Serving Platform - Cooper et al., 2008
- The Bayou Architecture: Support for Data Sharing among Mobile Users - Demers et al. 1994
- Probabilistically Bound Staleness for Practical Partial Quorums - Bailis et al., 2012
- Eventual Consistency Today: Limitations, Extensions, and Beyond - Bailis & Ghodsi, 2013
- Optimistic replication - Saito & Shapiro, 2005
6. 进一步阅读和附录
如果你已经走到这一步,谢谢你。
如果你喜欢这本书,可以在 Github(或者 Twitter)上关注我。我喜欢看到自己产生了一些积极的影响。"创造比你获得更多的价值"之类的。
非常感谢:logpath、alexras、globalcitizen、graue、frankshearar、roryokane、jpfuentes2、eeror、cmeiklejohn、 stevenproctor、eos2102和steveloughran提供的帮助!当然,任何遗漏和错误都是我的责任!
值得注意的是,我关于最终一致性的章节比较偏向伯克利;我想要改变这一点。我还跳过了一个突出的使用情况:一致性快照。还有一些主题我应该进一步扩展:即明确讨论安全性和活性属性以及一致性哈希的更详细讨论。不过,我要去参加Strange Loop 2013,所以无论如何。
如果这本书有第六章的话,它可能会讲述如何利用和处理大量数据的方法。似乎最常见的“大数据”计算是通过一个简单的程序处理一个大型数据集。 我不确定接下来的章节会是什么(也许是高性能计算,考虑到当前的重点是可行性),但我可能会在几年后知道。
关于分布式系统的书籍
分布式算法(Lynch)
这可能是关于分布式算法最经常推荐的书。我也会推荐它,但是有一点需要注意。它非常全面,但是是写给研究生读者的,所以在读到对从业者最有趣的内容之前,你会花费很多时间阅读关于同步系统和共享内存算法的内容。
可靠和安全的分布式编程简介(Cachin,Guerraoui和Rodrigues)
对于从业者来说,这是一个有趣的例子。它很简短,而且包含了实际算法的实现。
复制:理论与实践
如果你对复制感兴趣,这本书非常棒。关于复制的章节主要基于这本书的有趣部分的综合,以及更近期的阅读。
分布式系统:算法方法(高斯)
分布式算法简介 (电话)
事务性信息系统:理论、算法和并发控制与恢复实践 (Weikum & Vossen)
这本书是关于传统的事务性信息系统,例如本地关系型数据库。末尾有两章关于分布式事务的内容,但本书的重点在于事务处理。
事务处理:概念和技术(Gray 和 Reuter 编写)
一个经典。我发现 Weikum & Vossen 更加更新。
开创性论文
每年都会颁发 戴克斯特拉分布式计算奖,以表彰在分布式计算原理方面的杰出论文。点击链接查看完整列表,其中包括以下经典论文:
- "Time, Clocks and Ordering of Events in a Distributed System" - Leslie Lamport
- "Impossibility of Distributed Consensus With One Faulty Process" - Fisher, Lynch, Patterson
- "Unreliable failure detectors and reliable distributed systems" - Chandra and Toueg
微软学术搜索有一个按引用次数排序的分布式并行计算领域的顶级出版物列表 - 这可能是一个有趣的列表,可以浏览更多经典作品。
以下是一些推荐论文的额外列表:
- Nancy Lynch's recommended reading list from her course on Distributed systems.
- NoSQL Summer paper list - a curated list of papers related to this buzzword.
- A Quora question on seminal papers in distributed systems.
系统
- The Google File System - Ghemawat, Gobioff and Leung
- MapReduce: Simplified Data Processing on Large Clusters - Dean and Ghemawat
- Dynamo: Amazon’s Highly Available Key-value Store - DeCandia et al.
- Bigtable: A Distributed Storage System for Structured Data - Chang et al.
- The Chubby Lock Service for Loosely-Coupled Distributed Systems - Burrows
- ZooKeeper: Wait-free coordination for Internet-scale systems - Hunt, Konar, Junqueira, Reed, 2010

长江两岸老火锅,共聚山城开发者!We Want You!
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)