
Inception Transformer:带有高低频混合注意力的视觉Vi
Inception Transformer论文浅析
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
摘要
近年来的研究表明,Transformer具有很强的远距离的建模能力,但不能捕捉主要传递局部信息的高频。 为了解决这个问题,我们提出了一种新的通用的Inception Transformer,简称iformer,它可以有效地学习视觉数据中的高频和低频信息的综合特征。 具体来说,我们设计了一个Inception Mixer,将卷积和最大池化捕捉高频信息的优点显式地嫁接到Transformer上。 与最近的混合框架不同,Inception Mixer通过通道划分机制带来更大的效率,采用并行卷积/最大池路径和自注意力路径作为高低频混合器,同时具有对分散在宽频率范围内的可判别信息建模的灵活性。 考虑到底层更多的是捕捉高频细节,而顶层更多的是建模低频全局信息,我们进一步引入了频率斜坡结构,即逐渐减小馈入高频混合器的维数,增加馈入低频混合器的维数,可以有效地在不同层之间权衡高频和低频分量。 我们在一系列视觉任务上对iFormer进行了基准测试,并展示了它在图像分类、COCO检测和ADE20K分割方面取得了令人印象深刻的性能。 例如,我们的iformer-S在ImageNet-1K上达到了83.4%的Top-1精度,远远高于DeiT-S的3.6%,甚至略好于更大的Swin-B模型(83.3%),只有1/4的参数和1/3的FLOPs。
1. Inception Transformer
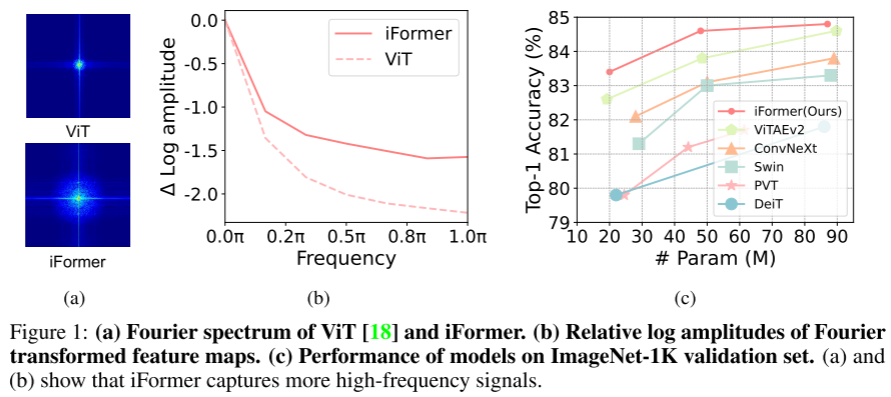
ViT 及其变体能够捕获视觉数据中的低频信息,主要包括场景或对象的全局形状和结构,但对于学习高频信息(主要包括局部边缘和纹理)的能力不是很强。这可以直观地解释:ViTs 中用于在非重叠 patch token 之间交换信息的主要操作 self-attention 是一种全局操作,比起局部信息(高频),它更适合捕获全局信息(低频)。
如图 1(a)和 1(b)所示,傅里叶频谱和傅里叶的相对对数振幅表明,ViT倾向于很好地捕捉低频信号,但很少捕捉高频信号。这表明ViT呈现出低通滤波器的特征。这种低频偏好性会损害 VIT 的性能,因为:1)所有层中的低频信息填充可能会恶化高频成分,例如局部纹理,并削弱 VIT 的建模能力;2) 高频信息也是有区别的,可以帮助完成许多任务,例如(细粒度)分类。实际上,人类视觉系统以不同的频率提取视觉基本特征:低频率提供有关视觉刺激的全局信息,高频率传达图像中的局部空间变化(例如,局部边缘/纹理)。因此,有必要开发一种新的ViT结构,用于捕获视觉数据中的高频和低频。CNN 是一般视觉任务最基本的支柱。与 VIT 不同,它们通过感受野内的局部卷积覆盖更多的局部信息,从而有效地提取高频表示。最近的研究考虑到 CNN 和 VIT 的互补优势,将其整合在一起。一些方法以串行方式堆叠卷积和注意层,以将局部信息注入全局上下文。不幸的是,这种串行方式仅在一个层中对一种类型的依赖项(全局或局部)进行建模,并在局部建模期间丢弃全局信息,反之亦然。其他的工作采用平行注意和卷积来同时学习输入的全局和局部依赖性。然而,一部分通道用于处理局部信息,另一部分用于全局建模,这意味着如果处理每个分支中的所有通道,则当前的并行结构具有信息冗余。
为了解决这个问题,作者提出了一种简单有效的 Inception Transformer(iFormer),它将 CNN 捕捉高频的优点移植到 ViT 上。iFormer 中的关键组件是 Inception token mixer。该 Inception mixer 旨在通过捕获数据中的高频和低频来增强 VIT 在频谱中的感知能力。为此,Inception mixer 首先沿通道维度拆分输入特征,然后将拆分后的分量分别送入高频混频器和低频混频器。在这里,高频混频器由最大池化操作和并行卷积操作组成,而低频混频器由 ViTs 中的自注意力实现。通过这种方式,本文的 iFormer 可以有效地捕获相应通道上的特定频率信息,从而在较宽的频率范围内学习比 ViT 更全面的特征。此外,作者发现,较低层通常需要更多的局部信息,而较高层需要更多的全局信息。这是因为,与人类视觉系统一样,高频成分中的细节有助于较低层捕捉视觉基本特征,并逐渐收集局部信息,以便对输入进行全局理解。受此启发,作者设计了一种频率斜坡结构(frequency ramp structure)。具体来说,从低层到高层,作者逐渐将更多的通道尺寸馈送到低频混频器和更少的通道送入到高频混频器。这种结构可以在所有层之间权衡高频和低频分量。
1.1 Inception token mixer
本文提出了一种 Inception mixer,将 CNN 提取高频表示的强大功能移植到 Transformer 中。其详细架构如下图所示。Inception mixer 不是直接将图像 token 输入MSA混合器,而是首先沿通道维度拆分输入特征,然后分别将拆分后的分量输入高频混合器和低频混合器。这里,高频混合器由最大池化操作和并行卷积操作组成,而低频混频器由自注意力实现。

1.1.1 高频混合器
考虑到最大滤波器的灵敏度和卷积运算的细节感知,作者提出了一种并行结构来学习高频组件,主要包含两个分支:1. 最大池化和线性层;2. 线性层和深度可分离卷积。具体公式如下所示:
Y
h
1
=
F
C
(
MaxPool
(
X
h
1
)
)
Y
h
2
=
DwConv
(
FC
(
X
h
2
)
)
\begin{array}{l} \boldsymbol{Y}_{h 1}=\mathrm{FC}\left(\operatorname{MaxPool}\left(\boldsymbol{X}_{h 1}\right)\right) \\ \boldsymbol{Y}_{h 2}=\operatorname{DwConv}\left(\operatorname{FC}\left(\boldsymbol{X}_{h 2}\right)\right) \end{array}
Yh1=FC(MaxPool(Xh1))Yh2=DwConv(FC(Xh2))
1.1.2 低频混合器
本文使用原始多头注意力在低频混合器的所有 token 之间传递信息。尽管注意力机制的全局表示能力很强,但特征图的分辨率较大会在较低层带来较大的计算开销。因此,需在注意力操作之前使用一个平均池化层来减小空间尺度,并在注意力操作之后使用一个上采样层来恢复原始的空间维度。这种设计大大减少了计算开销,并使注意力操作集中于嵌入全局信息。具体公式如下:
Y
l
=
Upsample
(
MSA
(
AvePooling
(
X
l
)
)
)
\boldsymbol{Y}_{l}=\operatorname{Upsample}\left(\operatorname{MSA}\left(\text { AvePooling }\left(\boldsymbol{X}_{l}\right)\right)\right)
Yl=Upsample(MSA( AvePooling (Xl)))
1.1.3 多分支融合
本文设计了一个融合模块,将三个分支合并起来,在 patch 之间进行深度卷积交换信息,同时加入一个跨通道线性层。具体操作如下公式所示:
Y c = Concat ( Y l , Y h 1 , Y h 2 ) Y = F C ( Y c + DwConv ( Y c ) ) \begin{array}{l} \boldsymbol{Y}_{\boldsymbol{c}} = \operatorname{Concat}\left(\boldsymbol{Y}_{l}, \boldsymbol{Y}_{h 1}, \boldsymbol{Y}_{h 2}\right)\\ \boldsymbol{Y} = \mathrm{FC}\left(\boldsymbol{Y}_{\boldsymbol{c}}+\operatorname{DwConv}\left(\boldsymbol{Y}_{\boldsymbol{c}}\right)\right) \end{array} Yc=Concat(Yl,Yh1,Yh2)Y=FC(Yc+DwConv(Yc))
1.1.4 Inception Transformer Block
本文跟原始的Transformer架构类似,只不过将自注意力机制换成了本文提出的Inception token mixer,具体操作如下公式所示:
Y
=
X
+
ITM
(
L
N
(
X
)
)
H
=
Y
+
FFN
(
LN
(
Y
)
)
.
\begin{aligned} \boldsymbol{Y} & =\boldsymbol{X}+\operatorname{ITM}(\mathrm{LN}(\boldsymbol{X})) \\ \boldsymbol{H} & =\boldsymbol{Y}+\operatorname{FFN}(\operatorname{LN}(\boldsymbol{Y})) . \end{aligned}
YH=X+ITM(LN(X))=Y+FFN(LN(Y)).

1.2 频率斜坡结构
在一般的视觉框架中,底层在捕捉高频细节方面发挥着更多的作用,而顶层在建模低频全局信息方面发挥着更多的作用。与人类一样,通过捕获高频成分中的细节,较低层可以捕获视觉基本特征,并逐渐收集局部信息,以实现对输入的全局理解。受此启发,本文设计了一种频率斜坡结构,它将更多的通道尺寸从较低层到较高层逐渐分到低频混频器,从而将更少的通道尺寸留给高频混频器。
2. 代码复现
2.1 下载并导入所需的库
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
import itertools
from functools import partial
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 iFormer模型的创建
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class HighMixer(nn.Layer):
def __init__(self, dim, kernel_size=3, stride=1, padding=1):
super().__init__()
self.cnn_in = cnn_in = dim // 2
self.pool_in = pool_in = dim // 2
self.cnn_dim = cnn_dim = cnn_in * 2
self.pool_dim = pool_dim = pool_in * 2
self.conv1 = nn.Conv2D(cnn_in, cnn_dim, kernel_size=1, stride=1, padding=0, bias_attr=False)
self.proj1 = nn.Conv2D(cnn_dim, cnn_dim, kernel_size=kernel_size, stride=stride, padding=padding, bias_attr=False, groups=cnn_dim)
self.mid_gelu1 = nn.GELU()
self.Maxpool = nn.MaxPool2D(kernel_size, stride=stride, padding=padding)
self.proj2 = nn.Conv2D(pool_in, pool_dim, kernel_size=1, stride=1, padding=0)
self.mid_gelu2 = nn.GELU()
def forward(self, x):
# B, C H, W
cx = x[:,:self.cnn_in,:,:]
cx = self.conv1(cx)
cx = self.proj1(cx)
cx = self.mid_gelu1(cx)
px = x[:,self.cnn_in:,:,:]
px = self.Maxpool(px)
px = self.proj2(px)
px = self.mid_gelu2(px)
hx = paddle.concat((cx, px), axis=1)
return hx
class LowMixer(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., pool_size=2):
super().__init__()
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.dim = dim
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.pool = nn.AvgPool2D(pool_size, stride=pool_size, padding=0) if pool_size > 1 else nn.Identity()
self.uppool = nn.Upsample(scale_factor=pool_size) if pool_size > 1 else nn.Identity()
def att_fun(self, q, k, v, B, N, C):
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 1, 3, 2]).reshape((B, C, N))
return x
def forward(self, x):
# B, C, H, W
B, _, _, _ = x.shape
xa = self.pool(x)
xa = xa.transpose([0, 2, 3, 1]).reshape((B, -1, self.dim))
B, N, C = xa.shape
qkv = self.qkv(xa).reshape((B, N, 3, self.num_heads, C // self.num_heads)).transpose([2, 0, 3, 1, 4])
q, k, v = qkv[0], qkv[1], qkv[2]
xa = self.att_fun(q, k, v, B, N, C)
xa = xa.reshape((B, C, int(N**0.5), int(N**0.5)))
xa = self.uppool(xa)
return xa
class Mixer(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0., attention_head=1, pool_size=2):
super().__init__()
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
self.low_dim = low_dim = attention_head * head_dim
self.high_dim = high_dim = dim - low_dim
self.high_mixer = HighMixer(high_dim)
self.low_mixer = LowMixer(low_dim, num_heads=attention_head, qkv_bias=qkv_bias, attn_drop=attn_drop, pool_size=pool_size,)
self.conv_fuse = nn.Conv2D(low_dim + high_dim * 2, low_dim + high_dim * 2, kernel_size=3, stride=1, padding=1, bias_attr=False, groups=low_dim + high_dim * 2)
self.proj = nn.Conv2D(low_dim + high_dim * 2, dim, kernel_size=1, stride=1, padding=0)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
x = x.transpose([0, 3, 1, 2])
# HighMixer
hx = x[:,:self.high_dim,:,:]
hx = self.high_mixer(hx)
# LowMixer
lx = x[:,self.high_dim:,:,:]
lx = self.low_mixer(lx)
# Fuse
x = paddle.concat((hx, lx), axis=1)
x = x + self.conv_fuse(x)
x = self.proj(x)
x = self.proj_drop(x)
x = x.transpose([0, 2, 3, 1])
return x
class Block(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, attention_head=1, pool_size=2,
attn=Mixer, use_layer_scale=False, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = attn(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, attention_head=attention_head, pool_size=pool_size,)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.use_layer_scale = use_layer_scale
if self.use_layer_scale:
self.layer_scale_1 = self.create_parameter([dim], default_initializer=nn.initializer.Constant(layer_scale_init_value))
self.layer_scale_2 = self.create_parameter([dim], default_initializer=nn.initializer.Constant(layer_scale_init_value))
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2 * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Layer):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, kernel_size=16, stride=16, padding=0, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding )
self.norm = nn.BatchNorm2D(embed_dim)
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
x = x.transpose([0,2,3,1])
return x
class Stem(nn.Layer):
""" 2D Image to Patch Embedding
"""
def __init__(self, kernel_size=3, stride=2, padding=1, in_chans=3, embed_dim=768):
super().__init__()
self.proj1 = nn.Conv2D(in_chans, embed_dim//2, kernel_size=kernel_size, stride=stride, padding=padding)
self.norm1 = nn.BatchNorm2D(embed_dim // 2)
self.gelu1 = nn.GELU()
self.proj2 = nn.Conv2D(embed_dim//2, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)
self.norm2 = nn.BatchNorm2D(embed_dim)
def forward(self, x):
x = self.proj1(x)
x = self.norm1(x)
x = self.gelu1(x)
x = self.proj2(x)
x = self.norm2(x)
x = x.transpose([0,2,3,1])
return x
class InceptionTransformer(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=None, depths=None,
num_heads=None, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None, weight_init='',
attention_heads=None,
use_layer_scale=False, layer_scale_init_value=1e-5,
**kwargs,
):
super().__init__()
st2_idx = sum(depths[:1])
st3_idx = sum(depths[:2])
st4_idx = sum(depths[:3])
depth = sum(depths)
self.num_classes = num_classes
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
act_layer = act_layer or nn.GELU
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.patch_embed = Stem(in_chans=in_chans, embed_dim=embed_dims[0])
self.num_patches1 = num_patches = img_size // 4
self.pos_embed1 = self.create_parameter((1, num_patches, num_patches, embed_dims[0]), default_initializer=nn.initializer.TruncatedNormal(std=0.02))
self.blocks1 = nn.Sequential(*[
Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer, attention_head=attention_heads[i], pool_size=2)
for i in range(0, st2_idx)])
self.patch_embed2 = embed_layer(kernel_size=3, stride=2, padding=1, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.num_patches2 = num_patches = num_patches // 2
self.pos_embed2 = self.create_parameter((1, num_patches, num_patches, embed_dims[1]), default_initializer=nn.initializer.TruncatedNormal(std=0.02))
self.blocks2 = nn.Sequential(*[
Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer, attention_head=attention_heads[i], pool_size=2)
for i in range(st2_idx,st3_idx)])
self.patch_embed3 = embed_layer(kernel_size=3, stride=2, padding=1, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.num_patches3 = num_patches = num_patches // 2
self.pos_embed3 = self.create_parameter((1, num_patches, num_patches, embed_dims[2]), default_initializer=nn.initializer.TruncatedNormal(std=0.02))
self.blocks3= nn.Sequential(*[
Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer, attention_head=attention_heads[i], pool_size=1,
use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value)
for i in range(st3_idx, st4_idx)])
self.patch_embed4 = embed_layer(kernel_size=3, stride=2, padding=1, in_chans=embed_dims[2], embed_dim=embed_dims[3])
self.num_patches4 = num_patches = num_patches // 2
self.pos_embed4 = self.create_parameter((1, num_patches, num_patches, embed_dims[3]), default_initializer=nn.initializer.TruncatedNormal(std=0.02))
self.blocks4 = nn.Sequential(*[
Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer, attention_head=attention_heads[i], pool_size=1,
use_layer_scale=use_layer_scale, layer_scale_init_value=layer_scale_init_value)
for i in range(st4_idx,depth)])
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self.init_weights)
def init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
ones = nn.initializer.Constant(1.0)
zeros = nn.initializer.Constant(0.0)
if isinstance(m, (nn.Conv2D, nn.Linear)):
tn(m.weight)
if m.bias is not None:
zeros(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2D)):
zeros(m.bias)
ones(m.weight)
def get_classifier(self):
if self.dist_token is None:
return self.head
else:
return self.head, self.head_dist
def _get_pos_embed(self, pos_embed, num_patches_def, H, W):
if H * W == num_patches_def * num_patches_def:
return pos_embed
else:
return F.interpolate(
pos_embed.transpose([0, 3, 1, 2]),
size=(H, W), mode="bilinear").transpose([0, 2, 3, 1])
def forward_features(self, x):
x = self.patch_embed(x)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed1, self.num_patches1, H, W)
x = self.blocks1(x)
x = x.transpose([0, 3, 1, 2])
x = self.patch_embed2(x)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed2, self.num_patches2, H, W)
x = self.blocks2(x)
x = x.transpose([0, 3, 1, 2])
x = self.patch_embed3(x)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed3, self.num_patches3, H, W)
x = self.blocks3(x)
x = x.transpose([0, 3, 1, 2])
x = self.patch_embed4(x)
B, H, W, C = x.shape
x = x + self._get_pos_embed(self.pos_embed4, self.num_patches4, H, W)
x = self.blocks4(x)
x = x.flatten(1, 2)
x = self.norm(x)
return x.mean(1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
num_classes = 10
def iformer_small():
"""
19.866M 4.849G 83.382
"""
depths = [3, 3, 9, 3]
embed_dims = [96, 192, 320, 384]
num_heads = [3, 6, 10, 12]
attention_heads = [1]*3 + [3]*3 + [7] * 4 + [9] * 5 + [11] * 3
model = InceptionTransformer(img_size=224, num_classes=num_classes,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads,
use_layer_scale=True, layer_scale_init_value=1e-6)
return model
def iformer_base():
"""
47.866M 9.379G 84.598
"""
depths = [4, 6, 14, 6]
embed_dims = [96, 192, 384, 512]
num_heads = [3, 6, 12, 16]
attention_heads = [1]*4 + [3]*6 + [8] * 7 + [10] * 7 + [15] * 6
model = InceptionTransformer(img_size=224, num_classes=num_classes,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads,
use_layer_scale=True, layer_scale_init_value=1e-6)
return model
def iformer_large():
"""
86.637M 14.048G 84.752
"""
depths = [4, 6, 18, 8]
embed_dims = [96, 192, 448, 640]
num_heads = [3, 6, 14, 20]
attention_heads = [1]*4 + [3]*6 + [10] * 9 + [12] * 9 + [19] * 8
model = InceptionTransformer(img_size=224,
depths=depths,
embed_dims=embed_dims,
num_heads=num_heads,
attention_heads=attention_heads, num_classes=num_classes,
use_layer_scale=True, layer_scale_init_value=1e-6)
return model
2.3.4 模型的参数
model = iformer_small()
paddle.summary(model, (1, 3, 224, 224))

model = iformer_base()
paddle.summary(model, (1, 3, 224, 224))

model = iformer_large()
paddle.summary(model, (1, 3, 224, 224))

2.4 训练
learning_rate = 0.001
n_epochs = 100
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
# Inception Former-S
model = iformer_small()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))

2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
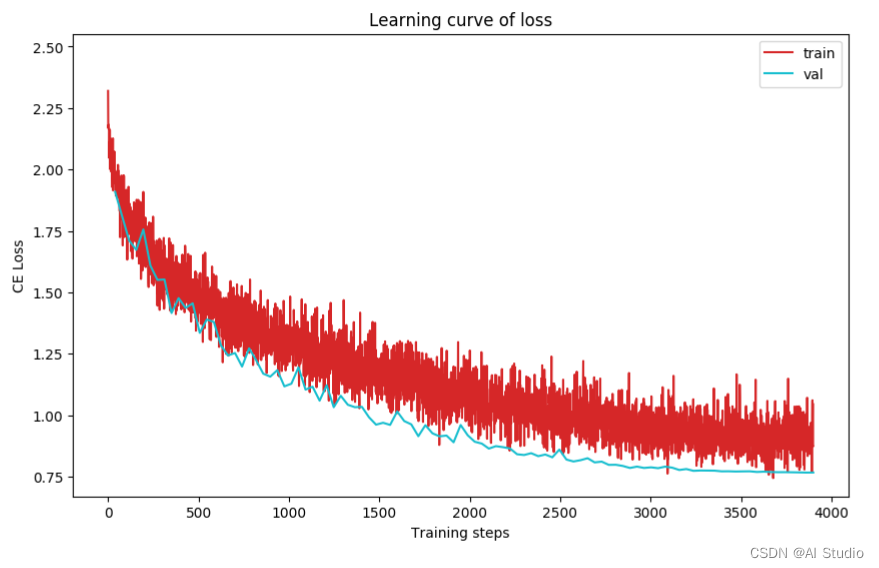
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
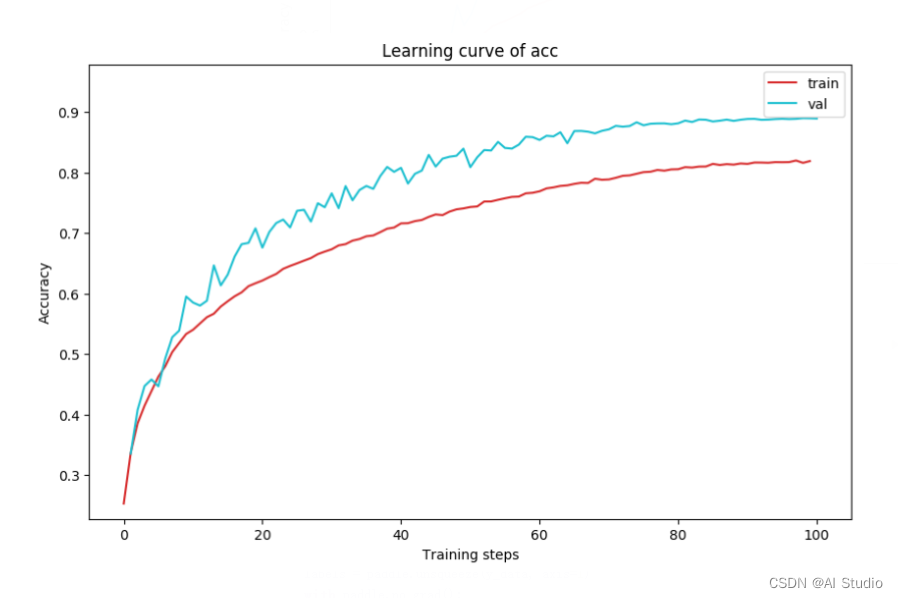
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = iformer_small()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:480
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = iformer_small()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

!pip install interpretdl
import interpretdl as it
work_path = 'work/model'
model = iformer_small()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
lime = it.LIMECVInterpreter(model)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [01:04<00:00, 155.55it/s]
04<00:00, 155.55it/s]

总结
在本文中,作者提出了一种 Inception Transformer(iFormer),这是一种新型的通用 Transformer 主干。iFormer 采用通道划分机制,简单有效地将卷积/最大化池化和自注意力耦合在一起,使其更专注于高频信息,并扩展了 Transformer 在频谱中的感知能力。基于灵活的 Inception token 混合器,作者进一步设计了一种频率斜坡结构,能够在所有层的高频和低频分量之间进行有效的权衡。本文的一个缺点是提出的 iFormer 的一个明显限制是,它需要在频率斜坡结构中手动定义通道比率,这需要丰富的经验来更好地定义不同任务。
参考文献
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)