登录社区云,与社区用户共同成长
邀请您加入社区
根级可以相互访问。
根级可以相互访问
欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
基于Python+SSM的新闻个性化采集推荐系统
【前沿模型解析】一致性模型CM 1 | 离散时间模型到连续时间模型数学推导
Llama3-Tutorial之LMDeploy高效部署Llama3实践
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。下面通过几个例子,来看一下调整--cache-max-entry-count参数的效果。Llama 3 近期重磅发布,
扫一扫分享内容
















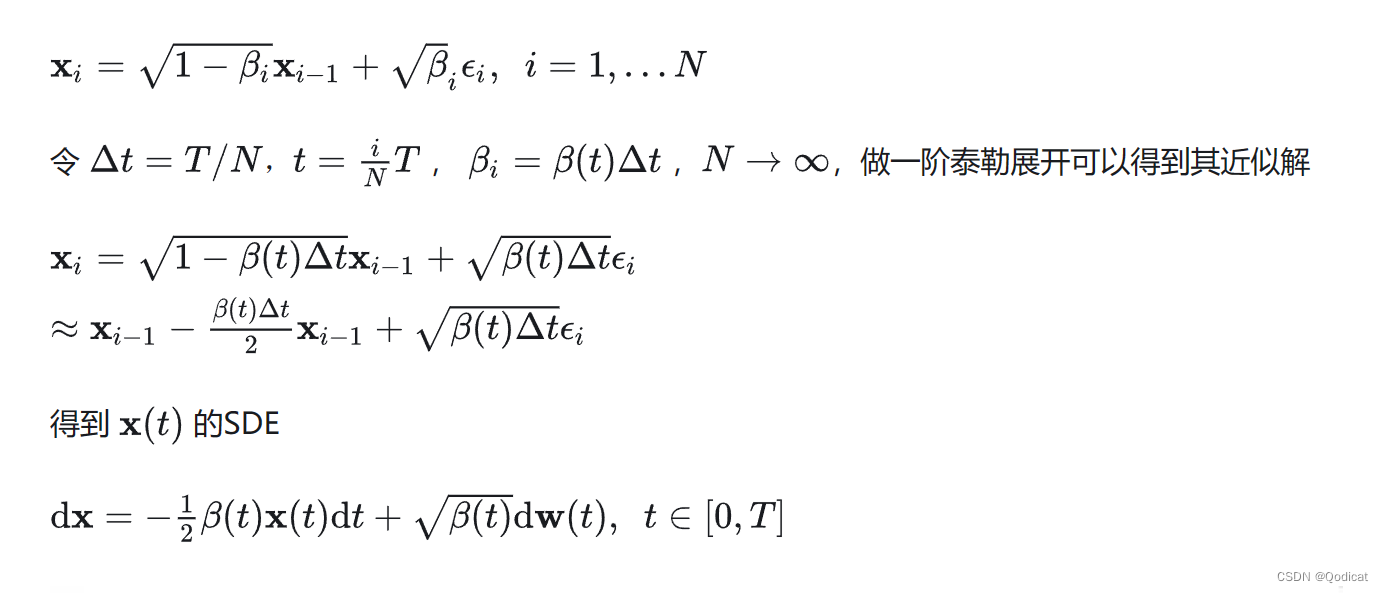





 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)