
LightViT:迈向轻量无卷积视觉Transformer
LightViT: Towards Light-Weight Convolution-Free Vision Transformers论文浅析
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
摘要
视觉Transformer由于缺少归纳偏置通常被认为比卷积神经网络(CNNs)更重。 因此,最近的工作将卷积作为一个即插即用的模块,并将其嵌入到各种ViT对应项中。 在本文中,我们认为卷积核执行信息聚合来连接所有的令牌; 然而,如果这种显式聚合能够以更相同的方式运行,那么对于轻量级ViTs来说,它们实际上是不必要的。 受此启发,我们提出LightViT作为一个新的轻量ViTs家族,以实现更好的精度-效率平衡的纯Transformer架构。 具体地说,我们在ViTS的自注意力和前馈网络(FFN)中引入了一个全局的但是有效的聚合方案,其中引入了额外的可学习令牌来捕获全局依赖; 同时,对令牌嵌入进行了二维通道和空间注意。 实验表明,该模型在图像分类、目标检测和语义分割等方面都有显著的改进。 例如,我们的LightViT-T在ImageNet上仅用0.7G的Flops就实现了78.7%的准确率,比PVTv2-B0高出8.2%,而在GPU上则快了11%。
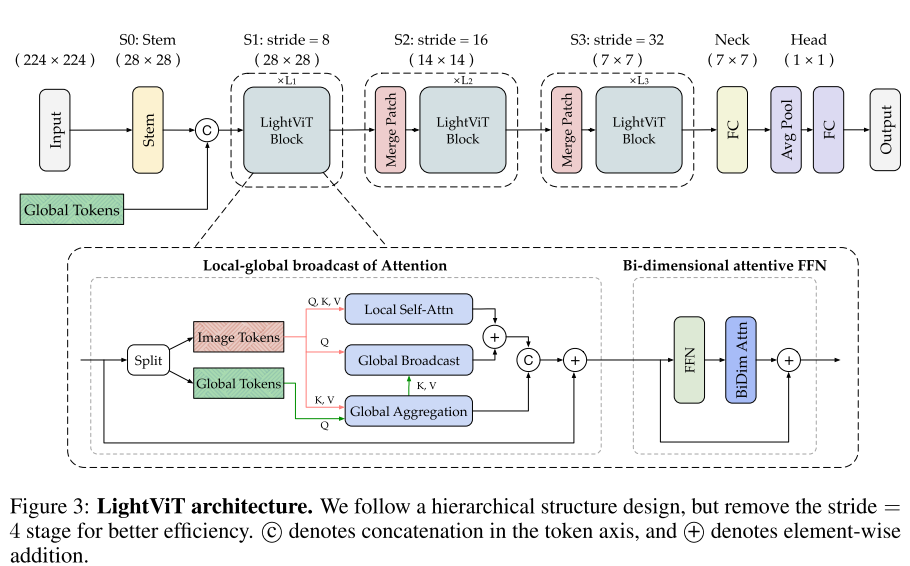
1. LightViT
本文针对卷积对于轻量化ViTs是否真的必要以及是否可以设计一个无卷积的轻量化ViTs这两个问题进行深入的研究并对注意力和前馈网络进行相应的改进:
- 针对自注意力机制,首先使用窗口注意力使得计算复杂度下降为线性。其次,使用一个全局可学习的token,这个token是全局伴随的,通过与特征层做自注意力运算和广播来融合全局信息。
- 针对前馈神经网络,受CNN中的注意力机制启发,参考SE机制,设置了空间注意力和通道注意力机制,来增强网络的表达能力。
基于这两个模块,本文提出了一个轻量化的Transformer——LightViT,模型的整体架构如图3所示:
1.1 局部-全局广播的聚合自注意力机制
如图2(a)所示,局部-全局广播的聚合自注意力机制主要包括三部分:
- 局部自注意力。对于图像标记,本文将其划分为窗口,并在每个窗口中使用局部自注意力,具体操作如下公式所示:
X local = Attention ( X q , X k , X v ) : = SoftMax ( X q X k ⊤ ) X v , \boldsymbol{X}_{\text {local }}=\operatorname{Attention}\left(\boldsymbol{X}_{q}, \boldsymbol{X}_{k}, \boldsymbol{X}_{v}\right):=\operatorname{SoftMax}\left(\boldsymbol{X}_{q} \boldsymbol{X}_{k}^{\top}\right) \boldsymbol{X}_{v}, Xlocal =Attention(Xq,Xk,Xv):=SoftMax(XqXk⊤)Xv, - 全局聚合。将全局标记作为查询,图像标记作为键和值进行全局聚合,具体操作如下公式所示:
G ^ = Attention ( G q , X k , X v ) \hat{\boldsymbol{G}}=\operatorname{Attention}\left(\boldsymbol{G}_{q}, \boldsymbol{X}_{k}, \boldsymbol{X}_{v}\right) G^=Attention(Gq,Xk,Xv) - 全局传播。将聚合后的全局标记作为键和值,图像标记作为查询,将全局信息传递给局部窗口,具体操作如下所示:
X global = Attention ( X q , G ^ k , G ^ v ) \boldsymbol{X}_{\text {global }}=\operatorname{Attention}\left(\boldsymbol{X}_{q}, \hat{\boldsymbol{G}}_{k}, \hat{\boldsymbol{G}}_{v}\right) Xglobal =Attention(Xq,G^k,G^v)
1.2 具有二维注意力的聚合前馈网络
前馈网络作为Transformer模块中唯一的非线性部分,在特征提取中起着重要的作用。由于所有令牌被逐点创博并且在FFN中共享相同线性层,所以非线性激活通常在由线性层产生的扩大的信道维度上进行以充分有效地捕获特征模式。然而,在轻量级模型中,通道的维数仍然不足,其中通道被限制为小通道以减少计算成本,因此它们的性能受到严重限制。普通FFN的另一个缺点是缺乏空间级别上的显式依赖建模,这对视觉任务非常重要。虽然空间特征聚合可以通过令牌之间的权重共享来隐式地执行,但是对于轻量级ViT来说,捕获这些含义仍然具有挑战性。如图2(b)所示,本文提出了一个新的前馈网络,同时进行空间注意力和通道注意力。
- 通道注意力:采用与SE Layer相同的架构
- 空间注意力:与SE Layer也相似,只不过没有进行全局平均池化,并将通道压缩后的特征图与空间压缩后的特征图合并起来使用全连接层以预测最终的空间注意力

1.3 关于设计更有效的轻量ViT的一些经验性设计
本文通过实验制定LightViT的设计选择。经验性发现,对模型组件的几个改进可以导致更好的性能和效率,从而使LightViTs更高效。
- 更少阶段的分层结构
- 残差Patch合并的下采样,如图5(c)所示:
- 重叠的Patch嵌入

2. 代码复现
2.1 下载并导入所需的库
!pip install einops-0.3.0-py3-none-any.whl
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from functools import partial
from einops import rearrange
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.5, 1.0)),
transforms.ColorJitter(brightness=0.5,contrast=0.5, saturation=0.5),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 LightViT模型的创建
class ConvStem(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.patch_size = patch_size
stem_dim = embed_dim // 2
self.stem = nn.Sequential(
nn.Conv2D(in_chans, stem_dim, kernel_size=3,
stride=2, padding=1, bias_attr=False),
nn.BatchNorm2D(stem_dim),
nn.GELU(),
nn.Conv2D(stem_dim, stem_dim, kernel_size=3,
groups=stem_dim, stride=1, padding=1, bias_attr=False),
nn.BatchNorm2D(stem_dim),
nn.GELU(),
nn.Conv2D(stem_dim, stem_dim, kernel_size=3,
groups=stem_dim, stride=1, padding=1, bias_attr=False),
nn.BatchNorm2D(stem_dim),
nn.GELU(),
nn.Conv2D(stem_dim, stem_dim, kernel_size=3,
groups=stem_dim, stride=2, padding=1, bias_attr=False),
nn.BatchNorm2D(stem_dim),
nn.GELU(),
)
self.proj = nn.Conv2D(stem_dim, embed_dim,
kernel_size=3,
stride=2, padding=1)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
x = self.proj(self.stem(x))
_, _, H, W = x.shape
x = x.flatten(2).transpose([0, 2, 1])
x = self.norm(x)
return x, (H, W)
class BiAttn(nn.Layer):
def __init__(self, in_channels, act_ratio=0.25, act_fn=nn.GELU, gate_fn=nn.Sigmoid):
super().__init__()
reduce_channels = int(in_channels * act_ratio)
self.norm = nn.LayerNorm(in_channels)
self.global_reduce = nn.Linear(in_channels, reduce_channels)
self.local_reduce = nn.Linear(in_channels, reduce_channels)
self.act_fn = act_fn()
self.channel_select = nn.Linear(reduce_channels, in_channels)
self.spatial_select = nn.Linear(reduce_channels * 2, 1)
self.gate_fn = gate_fn()
def forward(self, x):
ori_x = x
x = self.norm(x)
x_global = x.mean(1, keepdim=True)
x_global = self.act_fn(self.global_reduce(x_global))
x_local = self.act_fn(self.local_reduce(x))
c_attn = self.channel_select(x_global)
c_attn = self.gate_fn(c_attn) # [B, 1, C]
s_attn = self.spatial_select(paddle.concat([x_local, x_global.expand((-1, x.shape[1], -1))], axis=-1))
s_attn = self.gate_fn(s_attn) # [B, N, 1]
attn = c_attn * s_attn # [B, N, C]
return ori_x * attn
class BiAttnMlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.attn = BiAttn(out_features)
self.drop = nn.Dropout(drop) if drop > 0 else nn.Identity()
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.attn(x)
x = self.drop(x)
return x
def get_relative_position_index(win_h, win_w):
coords = paddle.stack(paddle.meshgrid([paddle.arange(win_h), paddle.arange(win_w)]))
coords_flatten = paddle.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.transpose([1, 2, 0])
relative_coords[:, :, 0] += win_h - 1
relative_coords[:, :, 1] += win_w - 1
relative_coords[:, :, 0] *= 2 * win_w - 1
return relative_coords.sum(-1)
def window_reverse(windows, original_size, window_size=(7, 7)):
# Get height and width
H, W = original_size
# Compute original batch size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
# Fold grid tensor
output = windows.reshape((B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1))
output = output.transpose([0, 1, 3, 2, 4, 5]).reshape((B, H * W, -1))
return output
class LightViTAttention(nn.Layer):
def __init__(self, dim, num_tokens=1, num_heads=8, window_size=7, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.num_tokens = num_tokens
self.window_size = window_size
self.attn_area = window_size * window_size
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.kv_global = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) if attn_drop > 0 else nn.Identity()
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) if proj_drop > 0 else nn.Identity()
# Define a parameter table of relative position bias, shape: 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = self.create_parameter(shape=((2 * window_size - 1) * (2 * window_size - 1), num_heads),
default_initializer=nn.initializer.TruncatedNormal(std=.02))
# Get pair-wise relative position index for each token inside the window
self.register_buffer("relative_position_index", get_relative_position_index(window_size,
window_size).flatten())
def _get_relative_positional_bias(self):
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index].reshape((self.attn_area, self.attn_area, -1))
relative_position_bias = relative_position_bias.transpose([2, 0, 1])
return relative_position_bias.unsqueeze(0)
def forward_global_aggregation(self, q, k, v):
"""
q: global tokens
k: image tokens
v: image tokens
"""
B, _, N, _ = q.shape
q = q * self.scale
attn = (q @ k.transpose([0, 1, 3, 2]))
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((B, N, -1))
return x
def forward_local(self, q, k, v, H, W):
"""
q: image tokens
k: image tokens
v: image tokens
"""
B, num_heads, N, C = q.shape
ws = self.window_size
h_group, w_group = H // ws, W // ws
# partition to windows
q = q.reshape((B, num_heads, h_group, ws, w_group, ws, -1)).transpose([0, 2, 4, 1, 3, 5, 6])
q = q.reshape((-1, num_heads, ws * ws, C))
k = k.reshape((B, num_heads, h_group, ws, w_group, ws, -1)).transpose([0, 2, 4, 1, 3, 5, 6])
k = k.reshape((-1, num_heads, ws * ws, C))
v = v.reshape((B, num_heads, h_group, ws, w_group, ws, -1)).transpose([0, 2, 4, 1, 3, 5, 6])
v = v.reshape((-1, num_heads, ws * ws, v.shape[-1]))
q = q * self.scale
attn = (q @ k.transpose([0, 1, 3, 2]))
pos_bias = self._get_relative_positional_bias()
attn = F.softmax(attn + pos_bias, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((v.shape[0], ws * ws, -1))
# reverse
x = window_reverse(x, (H, W), (ws, ws))
return x
def forward_global_broadcast(self, q, k, v):
"""
q: image tokens
k: global tokens
v: global tokens
"""
B, num_heads, N, _ = q.shape
q = q * self.scale
attn = (q @ k.transpose([0, 1, 3, 2]))
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((B, N, -1))
return x
def forward(self, x, H, W):
B, N, C = x.shape
NT = self.num_tokens
# qkv
qkv = self.qkv(x)
q, k, v = qkv.reshape((B, N, 3, self.num_heads, C // self.num_heads)).transpose([2, 0, 3, 1, 4]).unbind(0)
# split img tokens & global tokens
q_img, k_img, v_img = q[:, :, NT:], k[:, :, NT:], v[:, :, NT:]
q_glb, _, _ = q[:, :, :NT], k[:, :, :NT], v[:, :, :NT]
# local window attention
x_img = self.forward_local(q_img, k_img, v_img, H, W)
# global aggregation
x_glb = self.forward_global_aggregation(q_glb, k_img, v_img)
# global broadcast
k_glb, v_glb = self.kv_global(x_glb).reshape((B, -1, 2, self.num_heads, C // self.num_heads)).transpose([2, 0, 3, 1, 4]).unbind(0)
x_img = x_img + self.forward_global_broadcast(q_img, k_glb, v_glb)
x = paddle.concat([x_glb, x_img], axis=1)
x = self.proj(x)
return x
class Block(nn.Layer):
def __init__(self, dim, num_heads, num_tokens=1, window_size=7, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, attention=LightViTAttention):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = attention(dim, num_heads=num_heads, num_tokens=num_tokens, window_size=window_size, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = BiAttnMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class ResidualMergePatch(nn.Layer):
def __init__(self, dim, out_dim, num_tokens=1):
super().__init__()
# Local Token
self.num_tokens = num_tokens
self.norm = nn.LayerNorm(4 * dim)
self.reduction = nn.Linear(4 * dim, out_dim, bias_attr=False)
# use MaxPool3d to avoid permutations
self.maxp = nn.MaxPool2D(kernel_size=2, stride=2)
self.res_proj = nn.Linear(dim, out_dim, bias_attr=False)
# Global Token
self.norm2 = nn.LayerNorm(dim)
self.proj = nn.Linear(dim, out_dim, bias_attr=False)
def forward(self, x, H, W):
global_token, x = x[:, :self.num_tokens], x[:, self.num_tokens:]
B, L, C = x.shape
x = x.reshape((B, H, W, C))
res = self.res_proj(self.maxp(x.transpose([0, 3, 1, 2])).transpose([0, 2, 3, 1]).reshape((B, -1, C)))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
x = x + res
global_token = self.proj(self.norm2(global_token))
x = paddle.concat([global_token, x], 1)
return x, (H // 2, W // 2)
class LightViT(nn.Layer):
def __init__(self, img_size=224, patch_size=8, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256], num_layers=[2, 6, 6],
num_heads=[2, 4, 8], mlp_ratios=[8, 4, 4], num_tokens=8, window_size=7, neck_dim=1280, qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., embed_layer=ConvStem, norm_layer=None,
act_layer=None, weight_init=''):
super().__init__()
self.num_classes = num_classes
self.embed_dims = embed_dims
self.num_tokens = num_tokens
self.mlp_ratios = mlp_ratios
self.patch_size = patch_size
self.num_layers = num_layers
self.window_size = window_size
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
self.global_token = self.create_parameter(shape=(1, self.num_tokens, embed_dims[0]), default_initializer=nn.initializer.TruncatedNormal(std=.02))
stages = []
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(num_layers))] # stochastic depth decay rule
for stage, (embed_dim, num_layer, num_head, mlp_ratio) in enumerate(zip(embed_dims, num_layers, num_heads, mlp_ratios)):
blocks = []
if stage > 0:
# downsample
blocks.append(ResidualMergePatch(embed_dims[stage-1], embed_dim, num_tokens=num_tokens))
blocks += [
Block(
dim=embed_dim, num_heads=num_head, num_tokens=num_tokens, window_size=window_size, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[sum(num_layers[:stage]) + i], norm_layer=norm_layer, act_layer=act_layer, attention=LightViTAttention)
for i in range(num_layer)
]
blocks = nn.Sequential(*blocks)
stages.append(blocks)
self.stages = nn.Sequential(*stages)
self.norm = norm_layer(embed_dim)
self.neck = nn.Sequential(
nn.Linear(embed_dim, neck_dim),
nn.LayerNorm(neck_dim),
nn.GELU()
)
self.head = nn.Linear(neck_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
zero = nn.initializer.Constant(0.0)
one = nn.initializer.Constant(1.0)
if isinstance(m, nn.Linear):
tn(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zero(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2D)):
zero(m.bias)
one(m.weight)
def forward_features(self, x):
x, (H, W) = self.patch_embed(x)
global_token = self.global_token.expand((x.shape[0], -1, -1))
x = paddle.concat((global_token, x), axis=1)
for stage in self.stages:
for block in stage:
if isinstance(block, ResidualMergePatch):
x, (H, W) = block(x, H, W)
elif isinstance(block, Block):
x = block(x, H, W)
else:
x = block(x)
x = self.norm(x)
x = self.neck(x)
return x.mean(1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def lightvit_tiny(pretrained=False, **kwargs):
model_kwargs = dict(patch_size=8, embed_dims=[64, 128, 256], num_layers=[2, 6, 6],
num_heads=[2, 4, 8, ], mlp_ratios=[8, 4, 4], num_tokens=8, **kwargs)
model = LightViT(**model_kwargs)
return model
def lightvit_small(pretrained=False, **kwargs):
model_kwargs = dict(patch_size=8, embed_dims=[96, 192, 384], num_layers=[2, 6, 6],
num_heads=[3, 6, 12, ], mlp_ratios=[8, 4, 4], num_tokens=16, **kwargs)
model = LightViT(**model_kwargs)
return model
def lightvit_base(pretrained=False, **kwargs):
model_kwargs = dict(patch_size=8, embed_dims=[128, 256, 512], num_layers=[3, 8, 6],
num_heads=[4, 8, 16, ], mlp_ratios=[8, 4, 4], num_tokens=24, **kwargs)
model = LightViT(**model_kwargs)
return model
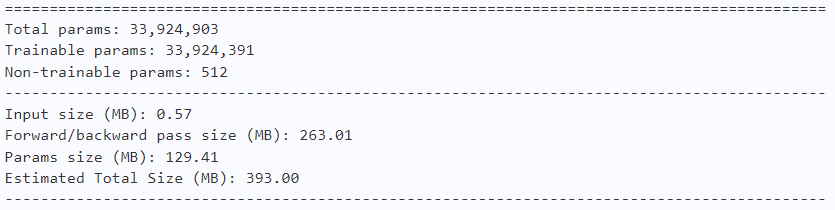
2.3.4 模型的参数
model = lightvit_tiny(num_classes=10)
paddle.summary(model, (1, 3, 224, 224))

model = lightvit_small(num_classes=10)
paddle.summary(model, (1, 3, 224, 224))

model = lightvit_base(num_classes=10)
paddle.summary(model, (1, 3, 224, 224))
2.4 训练
learning_rate = 0.0001
n_epochs = 100
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
# LightViT-Small
model = lightvit_small(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))

2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
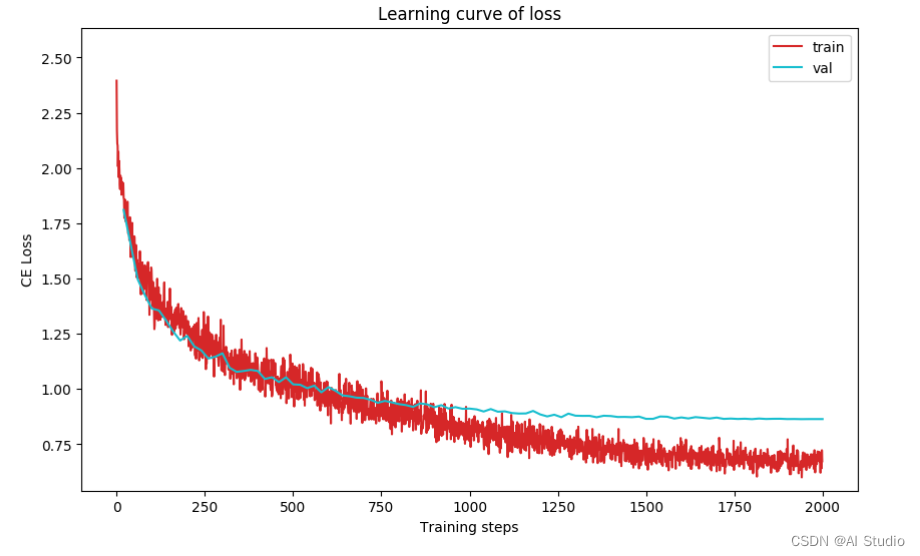
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
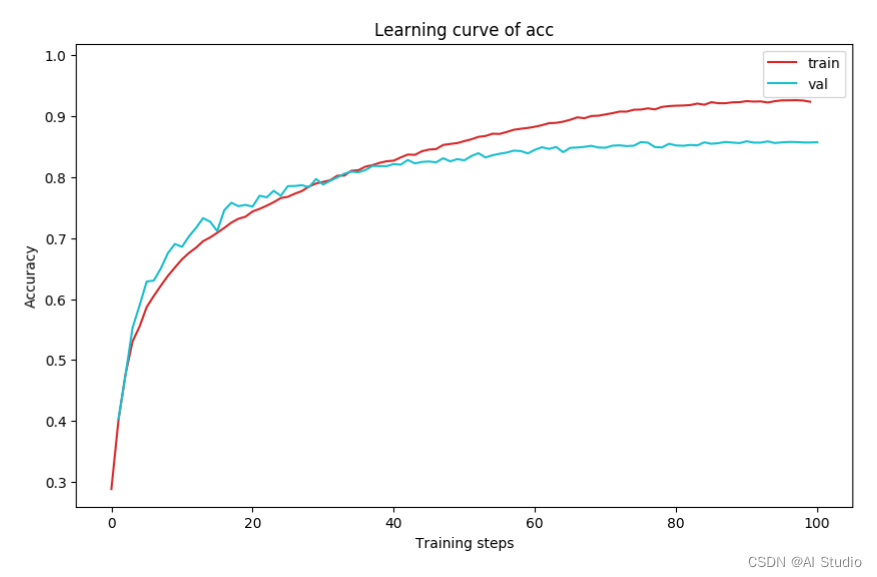
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = lightvit_small(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:656
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = lightvit_small(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

!pip install interpretdl
import interpretdl as it
work_path = 'work/model'
model = lightvit_small(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
lime = it.LIMECVInterpreter(model)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:58<00:00, 169.93it/s]
58<00:00, 169.93it/s]

总结
本文探究轻量化Transformer中卷积设计是否是必要的,并基于分析提出了一种无卷积的轻量化Transformer——LightViT。从大数据集(ImageNet)上可以看到性能与混合Transformer相当,但是在小数据(CIFAR10)由于归纳偏置的缺乏以及全连接层的使用,更易过拟合,同时精度不如混合Transformer。
参考文献
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 1
1 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)