

Xception算法解析-鸟类识别实战-Paddle实战
今天详解以下Xception算法,同时应用它做一个鸟类识别。Xception模型在极大的减少了网络参数量和计算复杂度的同时仍然可以保持卓越的性能表现。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
项目背景
今天详解以下Xception算法,同时应用它做一个鸟类识别。由于Xception模型在极大的减少了网络参数量和计算复杂度的同时,可以保持卓越的性能表现。因此,Xception模型已经被广泛地应用与图像分类、目标检测等任务中。
本次实战案例就是一个典型的图像分类。
本次项目实战鸟类数据集主要分为4类,分别为bananaquit(蕉林莺)、Black Skimmer (黑燕鸥类)、Black Throated Bushtiti (黑喉树莺)、Cockatoo (凤头鹦鹉或葵花鹦鹉),总计565张。
一、理论基础
1.前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如GoogLenet,VGG-16,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),进而训练出更深的CNN网络。
随着图像分类的准确率不断提高,网络的深度越来越深,图像分类的错误率也越来越低,从2012的AlexNet,2013年的ZFNet,2014年的GoogLeNet,再到后面2015年的ResNet,准确率已经超过了人类的水平,所以单纯从准确率方面考虑的话已经很难提升了;因此人们就开始从其他方面考虑,比如参数量和计算量,软硬件协同等。
今天我们要介绍的是Xception模型,Xception是Google继Inception后提出的对Inception V3的另一种改进,主要是采用深度可分离卷积(Depthwise Separable Convolution)来替换原来Inception V3中的卷积操作。
2.设计理念
前面说了,由于CNN模型的精度已经很难进一步提升,所以研究者们就把注意力放到了减少模型参数量和计算量上,因此Xception应运而生。而Xception就是研究者们在Inception V3模型上的进一步改进,通过用Depthwise Separable Convolution(深度可分离卷积)替换Inception V3中的多尺寸卷积核特征响应操作,最终达到了精度的略微提升和参数量的减少。在讲解Xception之前,我们先对它的前身Inception进行一番了解,然后再一步步往Xception方面讲述。
2.1 多尺寸卷积核
Inception 最初提出的版本,其核心思想就是使用多尺寸卷积核去观察输入数据。
举个例子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图:

于是我们的网络就变胖了,增加了网络的宽度,同时也提高了对于不同尺度的适应程度。
2.2 点卷积
但是我们的网络变胖了的同时,计算量也变大了,所以我们就要想办法减少参数量来减少计算量,于是在 Inception v1 中的最终版本加上了 1x1 卷积核。
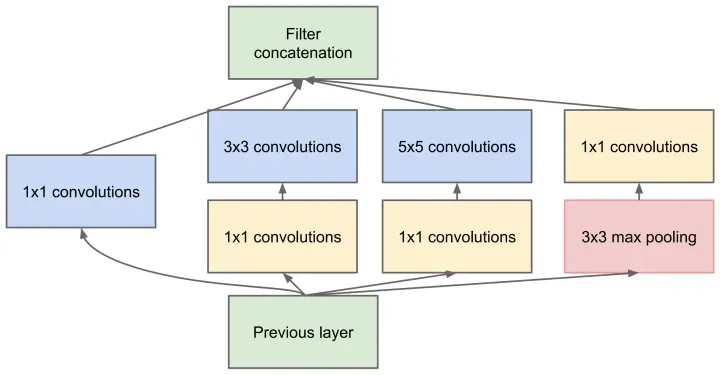
使用 1x1 卷积核对输入的特征图进行降维处理,这样就会极大地减少参数量,从而减少计算。
举个例子,输入数据的维度是 256 维,经过 1x1 卷积之后,我们输出的维度是 64 维,参数量是原来的 1 4 \frac{1}{4} 41 。
这就是 Pointwise Convolution,俗称叫做 1x1 卷积,简写为 PW,主要用于数据降维,减少参数量。
也有使用 PW 做升维的,在 MobileNet v2 中就使用 PW 将 3 个特征图变成 6 个特征图,丰富输入数据的特征。
想深入了解 MobileNet v2 的可以看看原文 MobileNet V2 - arxiv.org ,再对照地读这篇MobileNet V2 论文初读 - Michael Yuan。
2.3 卷积核替换
就算有了 PW ,由于 5x5 和 7x7 卷积核直接计算参数量还是非常大,训练时间还是比较长,我们还要再优化。
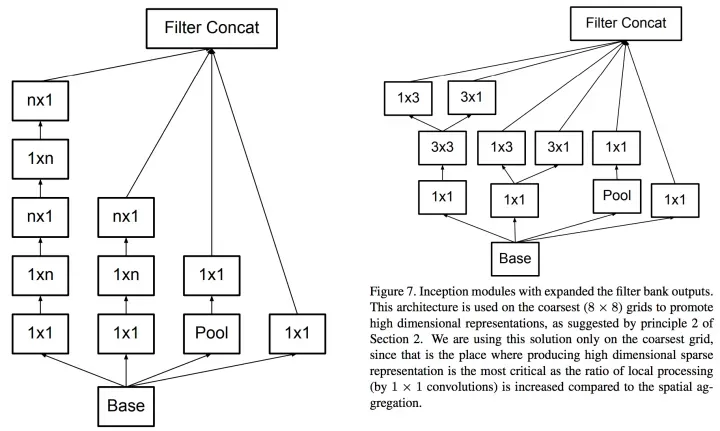
人类的智慧是无穷的,于是就想出了使用多个小卷积核替代大卷积核 的方法,这就是 Inception v3,如下图所示:

使用两个 3x3 卷积核来代替 5x5 卷积,效果上差不多,但参数量减少很多,达到了优化的目的。不仅参数量少,层数也多了,深度也变深了。
除了规整的的正方形,我们还有分解版本的 3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好。
我们假设输入 256 维,输出 512 维,计算一下参数量:
5x5 卷积核
256
×
5
×
5
×
512
=
3276800
256\times5\times5\times512=3276800
256×5×5×512=3276800
两个 3x3 卷积核
256
×
3
×
3
×
256
+
256
×
3
×
3
×
512
=
589824
+
1179648
=
1769472
256\times3\times3\times256+256\times3\times3\times512=589824+1179648=1769472
256×3×3×256+256×3×3×512=589824+1179648=1769472
结果对比
1769472
3276800
=
0.54
\frac{1769472}{3276800}=0.54
32768001769472=0.54
我们可以看到参数量对比,两个 3x3 的卷积核的参数量是 5x5 一半,可以大大加快训练速度。
2.4 Bottleneck
我们发现就算用了上面的结构和方法,我们的参数量还是很大,于是乎我们结合上面的方法创造出了 Bottleneck 的结构降低参数量。
Bottleneck 三步走是先 PW卷积 对数据进行降维,再进行常规卷积核的卷积,最后 PW 卷积对数据进行升维。我们举个例子,方便我们了解:
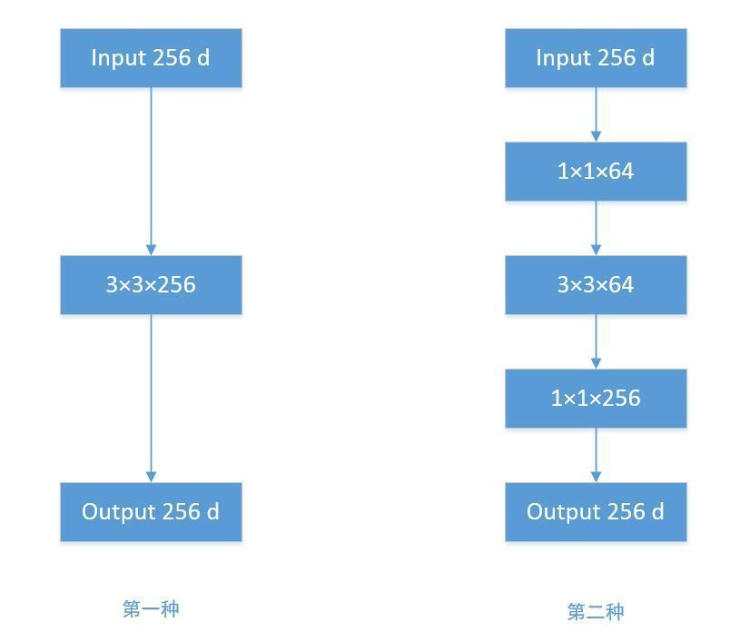
根据上图,我们来做个对比计算,假设输入 feature map 的维度为 256 维,要求输出维度也是 256 维。有以下两种操作:
● 直接使用 3x3 的卷积核。256 维的输入直接经过一个 3×3×256 的卷积层,输出一个 256 维的 feature map ,那么参数量为:256×3×3×256 = 589,824 。
● 先经过 1x1 的卷积核,再经过 3x3 卷积核,最后经过一个 1x1 卷积核。 256 维的输入先经过一个 1×1×64 的卷积层,再经过一个 3x3x64 的卷积层,最后经过 1x1x256 的卷积层,则总参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69,632 。
经过两种方式的对比,我们可以很明显的看到后者的参数量远小于前者的。Bottleneck 的核心思想还是利用多个小卷积核替代一个大卷积核,利用 1x1 卷积核替代大的卷积核的一部分工作。
2.5 深度可分离卷积(Depthwise Separable Conv)
我们发现参数量还是很多,于是人们又想啊想,得出了 Depthwise Separable Conv 。这个idea最早是来自这篇论文 Design of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial “Bottleneck” Structure,后面被 Google 用在 MobileNet 和 Xception 中发扬光大。
这个卷积的的大致意思是对每一个深度图分别进行卷积再融合,步骤是先 Depthwise Conv 再 Pointwise Conv,大大减少了参数量。下图是 Xception 模块的结构:
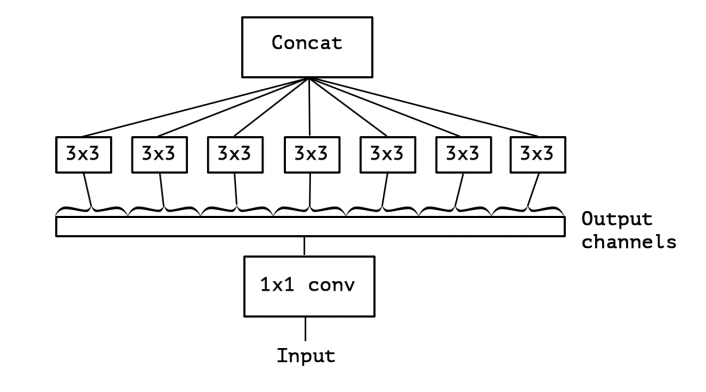
大致的步骤是这样的:
● 分别按不同通道进行一次卷积(生成 输入通道数 张 Feature Maps)- DW
● 再将这些 Feature Maps 一起进行第二次卷积 - PW
文字看起来有点抽象,我们用例子来理解一下。
输入的是 2 维的数据,我们要进行 3x3 卷积并输出 3 维的数据,与正常卷积对比:
常规卷积运算

标准卷积的参数量计算公式(不带偏置)为:
输入特征图:
W
i
n
p
u
t
×
H
i
n
p
u
t
×
C
i
n
p
u
t
W_{input}\times H_{input}\times C_{input}
Winput×Hinput×Cinput
卷积核:
K
h
×
K
w
K_h\times K_w
Kh×Kw
输出特征图:
W
o
u
t
p
u
t
×
H
o
u
t
p
u
t
×
C
o
u
t
p
u
t
W_{output}\times H_{output}\times C_{output}
Woutput×Houtput×Coutput
参数量(既卷积核的参数):
C
i
n
p
u
t
×
K
h
×
K
w
×
C
o
u
t
=
3
×
3
×
3
×
4
=
108
C_{input}\times K_h\times K_w\times C_{out}=3\times3\times3\times4=108
Cinput×Kh×Kw×Cout=3×3×3×4=108
其中 W i n p u t W_{input} Winput表示输入特征图的宽, H i n p u t H_{input} Hinput表示输入特征图的高, C i n p u t C_{input} Cinput表示输入特征图的通道数。而 K h 和 K w K_h 和K_w Kh和Kw则表示卷积核高和宽的尺寸大小, W o u t p u t W_{output} Woutput表示输出特征图的宽, H o u t p u t H_{output} Houtput表示输出特征图的高, C o u t p u t C_{output} Coutput表示输出特征图的通道数。
DW卷积
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
对于一张 5 × 5 5\times5 5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为 5 × 5 5\times5 5×5)。
一个大小为 64 × 64 64\times64 64×64像素、三通道彩色图片首先经过第一次卷积运算,不同之处在于此次的卷积完全是在二维平面内进行,且卷积核(Filters)的数量与上一层的通道数相同。所以一个三通道的图像经过运算后生成了3个Feature map,如下图所示。

参数量为:
C
i
n
p
u
t
×
K
h
×
K
w
×
1
=
3
×
3
×
3
×
1
=
27
C_{input}\times K_h\times K_w\times 1=3\times3\times3\times 1=27
Cinput×Kh×Kw×1=3×3×3×1=27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,没有有效的利用不同Feature map在相同空间位置上的信息。因此需要增加另外一步操作来将这些Feature map进行组合生成新的Feature map,即接下来的Pointwise Convolution。
PW卷积
Pointwise Convolution的运算与常规卷积运算非常相似,不同之处在于卷积核的尺寸为 1 × 1 × M 1\times1\times M 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的Feature map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核(Filters)就有几个Feature map。如下图所示。

参数量为:
C
i
n
p
u
t
×
1
×
1
×
C
o
u
t
p
u
t
=
3
×
1
×
1
×
4
=
12
C_{input}\times1\times 1\times C_{output}=3\times1\times1\times4=12
Cinput×1×1×Coutput=3×1×1×4=12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
Depthwise Separable Conv 卷积
标准的深度可分离卷积如下图所示:
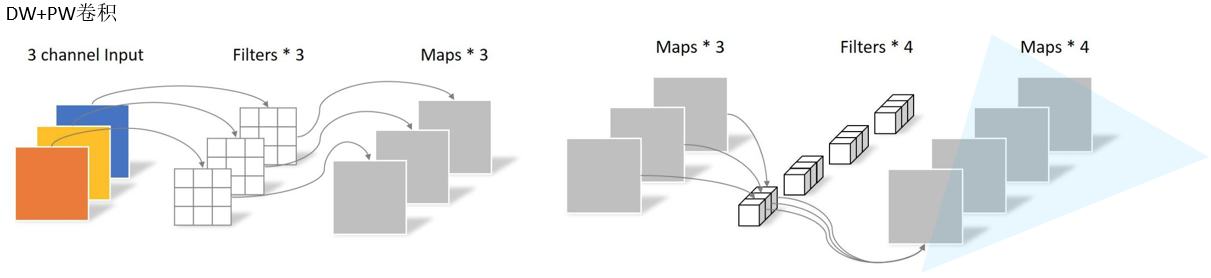
深度可分离卷积分为DW卷积和PW卷积,因此要分开计算再相加,参数量计算公式如下(不带偏置):
参数量公式: K h × K w × 1 × C i n p u t + 1 × 1 × C i n p u t × C o u t p u t K_{h}\times K_{w}\times1 \times C_{input} +1\times1\times C_{input}\times C_{output} Kh×Kw×1×Cinput+1×1×Cinput×Coutput
DW卷积参数量:
C
o
u
n
t
D
W
=
C
i
n
p
u
t
×
K
h
×
K
w
×
1
=
3
×
3
×
3
×
1
=
27
Count_{DW}=C_{input}\times K_h\times K_w\times 1=3\times3\times3\times 1=27
CountDW=Cinput×Kh×Kw×1=3×3×3×1=27
PW卷积参数量:
C
o
u
n
t
P
W
=
C
i
n
p
u
t
×
1
×
1
×
C
o
u
t
p
u
t
=
3
×
1
×
1
×
4
=
12
Count_{PW}=C_{input}\times1\times 1\times C_{output}=3\times1\times1\times4=12
CountPW=Cinput×1×1×Coutput=3×1×1×4=12
总的参数量:
C
o
u
n
t
D
W
+
C
o
u
n
t
P
W
=
3
×
3
×
3
×
1
+
3
×
1
×
1
×
4
=
27
+
12
=
39
Count_{DW}+Count_{PW}=3\times3\times3\times1+3\times1\times1\times4=27+12=39
CountDW+CountPW=3×3×3×1+3×1×1×4=27+12=39
参数量对比
39
108
=
0.36
\frac{39}{108}=0.36
10839=0.36
我们可以看到,参数量是正常卷积的将近一半,但实际上可以更少,只不过在输入输出维度相差不大的情况下,效果没那么明显。
理论计算
P
D
W
=
I
×
D
k
×
D
k
+
I
×
O
P_{DW}=I\times D_k\times D_k +I\times O
PDW=I×Dk×Dk+I×O
P
N
o
r
m
a
l
=
I
×
D
k
×
D
k
×
O
P_{Normal}=I\times D_k\times D_k \times O
PNormal=I×Dk×Dk×O
P
D
W
P
N
o
r
m
a
l
=
1
O
+
1
D
k
2
≈
1
D
k
2
\frac{P_{DW}}{P_{Normal}}=\frac{1}{O}+\frac{1}{D^{2}_{k}}\approx \frac{1}{D^{2}_{k}}
PNormalPDW=O1+Dk21≈Dk21
其中 I I I为输入通道数, O O O 是输出通道数, D k D_k Dk 是标准卷积核大小。
我们可以看到,当我们使用 3x3 卷积核的时候,参数量约等于标准卷积核的 1 9 \frac{1}{9} 91 ,大大减少参数量,从而加快训练速度。因此,在理论上普通卷积参数量是深度可分离卷积的9倍左右。
这里需要说明的是,Xception模型中的Depthwiss Separable Conv和传统的不太一样,传统的Depthwise Separable Conv是先进行 3 × 3 3\times3 3×3卷积,再进行 1 × 1 1\times1 1×1卷积操作(类似于mobileNet中的一样),而Xception模型中则是先进行 1 × 1 1\times1 1×1卷积,再进行 3 × 3 3\times3 3×3卷积操作,但中间为了保证数据不被破坏,没有添加Relu层,而mobileNet与它不同的是中间添加了Relu层。
3.网络结构
Xception的具体网络结构如图所示:

Xception包含三个部分:输入部分(Entry flow),中间部分(Middle flow)和结尾部分(Exit flow);其中所有卷积层和可分离卷积层后面都使用Batch Normalization处理,所有的可分离卷积层使用一个深度乘数1(深度方向并不进行扩充)。
- 对于Entry flow,首先使用了两个3x3卷积(conv1,conv2)降低特征图尺寸,同时增加了特征图个数;接着是3个含跳连的深度可分离卷积堆叠模块。
- 对于Middle flow,包含了8个一模一样的含跳连的深度可分离卷积堆叠模块。
- 对于Exit flow,首先是一个含跳连的深度可分离卷积堆叠模块,接着是一些深度可分离卷积层以及全局平均池化层,最后用全连接层输出分类结果。
4.评估分析
Xception论文中主要在JFT数据集与ImageNet数据集上与Inception V3模型做了比较,Xception和Inception V3模型的参数量大小如下图所示:

由此可以看出, 在参数量和速度,Xception参数量少于Inception V3,但速度更快。 同时与Inception V3相比,在分类性能上,Xception在ImageNet上领先较小,但在JFT上领先很多。
在ImageNet数据集下的测试结果如下图所示:
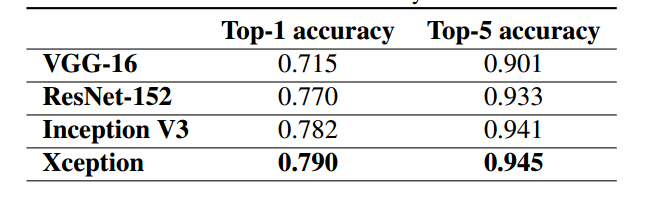
在JFT数据集下的测试结果如下图所示:

二、数据预处理
# 解压数据集
!unzip /home/aistudio/data/data223822/bird_photos.zip -d /home/aistudio/work/dataset
由于我们处理数据集文件的时候,里面多一个ipynb_checkpoints文件,因此需要通过以下命令删除以下。切记!一定要删除~
%cd /home/aistudio/work/dataset
!rm -rf .ipynb_checkpoints
/home/aistudio/work/dataset
# 划分数据集
import os
import random
train_ratio = 0.7
test_ratio = 1-train_ratio
rootdata = "/home/aistudio/work/dataset"
train_list, test_list = [],[]
data_list = []
class_flag = -1
for a,b,c in os.walk(rootdata):
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0, int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+' '+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c)*train_ratio),len(c)):
test_data = os.path.join(a,c[i])+' '+str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
random.shuffle(train_list)
random.shuffle(test_list)
with open('/home/aistudio/work/train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('/home/aistudio/work/test.txt', 'w', encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
三、数据读取
首先我们先导入以下所需库。
import paddle
import paddle.nn.functional as F
import numpy as np
import math
import random
import os
from paddle.io import Dataset # 导入Datasrt库
import paddle.vision.transforms as transforms
import xception
from PIL import Image
然后使用 paddle.io.DataLoader 定义数据读取器
transform_BZ = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
class LoadData(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.RandomHorizontalFlip(), # 随机左右翻转图像
transforms.RandomVerticalFlip(), # 随机上下翻转图像
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些复杂变换操作
])
self.val_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些复杂变换操作
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img_path = os.path.join('',img_path)
img = Image.open(img_path)
img = img.convert("RGB")
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
加载训练集和测试集
train_data = LoadData("/home/aistudio/work/train.txt", True)
test_data = LoadData("/home/aistudio/work/test.txt", True)
#数据读取
train_loader = paddle.io.DataLoader(train_data, batch_size=16, shuffle=True)
test_loader = paddle.io.DataLoader(test_data, batch_size=16, shuffle=True)
四、导入模型
这里我们直接导入提前写好的xception文件,然后打印输出以下模型的参数信息。
import xception
import paddle
model = xception.Xception41(class_num=4)
params_info = paddle.summary(model,(1, 3, 224, 224))
print(params_info)
打印结果如下所示:
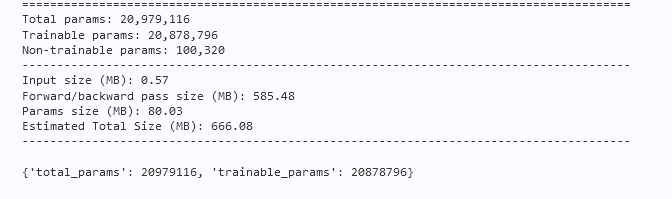
通过和Inception V3的参数量对比,我们发现确实降低了。
五、模型训练
epoch_num = 50 #训练轮数
batch_size = 16
learning_rate = 0.0001 #学习率
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
for epoch in range(epoch_num):
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
acc_train.append(acc.numpy())
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
avg_acc = np.mean(acc_train)
print("[train] accuracy: {}".format(avg_acc))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[test] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
train(model)
paddle.save(model.state_dict(), "model.pdparams")
六、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
epochs_range = range(epoch_num)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, val_acc_history, label='Val Accuracy')
plt.legend(loc='lower right')
plt.title('Val Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, val_loss_history, label='Val Loss')
plt.legend(loc='upper right')
plt.title('Val Loss')
plt.show()
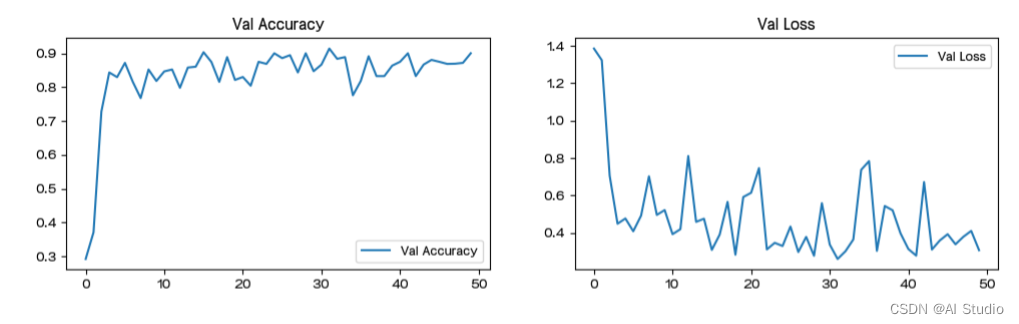
七、个体预测结果展示
data_transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
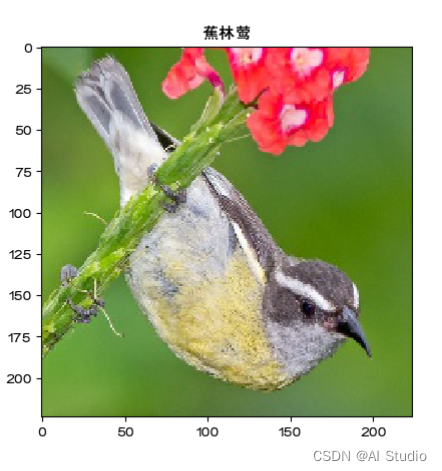
img = Image.open("/home/aistudio/work/dataset/Bananaquit/161.jpg")
plt.imshow(img)
image=data_transform(img)
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
name=['蕉林莺','黑喉树莺','黑燕鸥类','凤头鹦鹉']
image=paddle.reshape(image,[1,3,224,224])
model.eval()
predict=model(image)
print(predict.numpy()) #明显可以看出是第0个标签大
plt.title(name[predict.argmax(1)])
plt.show()
[[ 18.970772 -2.3022518 -18.097876 -5.1188602]]
]
总结
- Xception(又称为 Extreme Inception)是一种卷积神经网络架构,在 2016 年由 Google 提出,它的名字是由 ‘Extreme’ 和 ‘Inception’ 两个词汇组成的。Xception 采用了 Inception 模型的思想,使用深度可分离卷积来代替传统的卷积,从而更加有效地减少了模型的参数数量和计算复杂度。
- 在传统的 Inception 模型中,每个计算单元采用了两个卷积层,一个 1x1 的卷积层用于降低特征图的通道数,紧接着是一个 3x3 的卷积层用于进行特征提取。而 Xception 则将 1x1 和 3x3 卷积逐次分开,使用了深度可分离卷积作为基本的计算单元。深度可分离卷积将标准卷积分解为两部分,首先使用深度卷积来处理每个输入通道,然后再使用 1x1 的逐点卷积来融合通道,从而获得与标准卷积近似的特征提取效果。而深度可分离卷积相较于标准卷积而言,可以明显降低参数量和训练计算量。
- 而使用深度可分离卷积单元取代了传统的卷积操作之后,Xception模型在计算效率,模型大小上都相比 InceptionV3 有大幅的提升。
- 总之,Xception模型的优势是在极大的减少了网络参数量和计算复杂度的同时,可以保持卓越的性能表现。因此,Xception模型已经被广泛地应用与图像分类、目标检测等任务中。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)