
MySQL数据库增删改查及聚合查询SQL语句学习汇总
详细介绍MySQL数据库的SQL语句的学习,保你掌握SQL语句的使用
目录
数据库增删改查SQL语句
userlogin为表的名字
增:insert into userlogin values ('5','5');
删:delete from userlogin where username ='3';
改:update userlogin set username ='3' ,age = 12 where pwd ='2';
查:select * from userlogi;
注意点:查询语句中的通配符 * 尽量不要使用,原因:数据量大时会降低查询效率,使用列名代替*,平时养成好习惯
MySQL数据库指令
1.查询数据库
show databases;(多个数据库用复数)
2.创建数据库
create database 数据库名 charset utf8;
(数据库名由字母、数字、下划线组成,数字不能在最前面)
注意:此处为database,后面没有s,创建数据库增加 charset utf8 可以使数据库插入中文,否则插入中文会报错
报错案例:

3.删除数据库
drop database 数据库名;
4.选择数据库
use 数据库名;
创建表table
注意点(创建表前先选中具体某个数据库)
查看所有表
show tables;
创建表
create table 表名(列名 类型,列名 类型,列名 类型);
注意点:类型有int,varchar(),decimal(m,n) m指有m位有效数字,n指在小数点后有n位数字
查看指定表的结构
desc 表名;
删除表
drop table 表名;
数据库命令进行注释
在SQL中可以使用“--空格+描述”来表示注释说明
增删改查(CRUD)详细说明
增加
Insert into 表名 (id,name,age) values(1, ‘小红’,111) 注意点:插入字符串时记得用分号’ ’隔开
注意点:一次插入多个记得用逗号,隔开


SQL库提供了关于时间的函数:now()

查询
Select * from 表名;
Select 列名,列名 from 表名;
查询表作列与列之间进行运算
select 列名, 列名+列名+列名 from 表名;
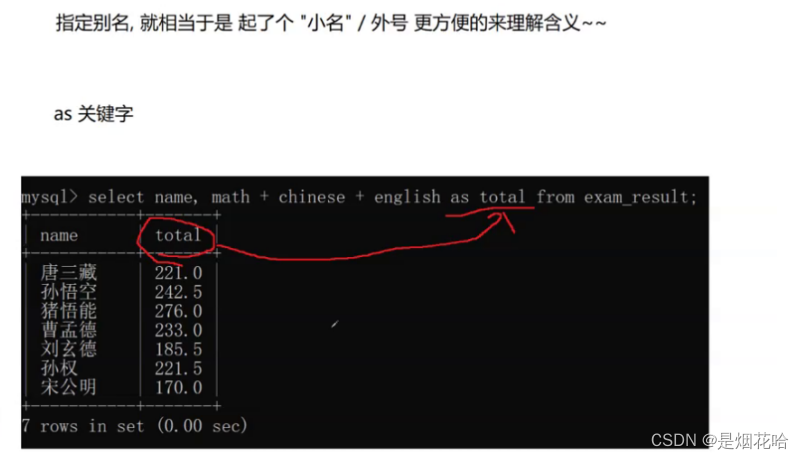
查询指定某列作为别名,使用关键字as
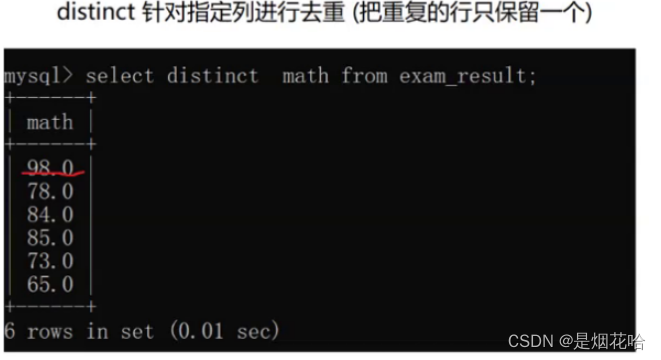
进行查询数据去重操作,使用关键字distinct
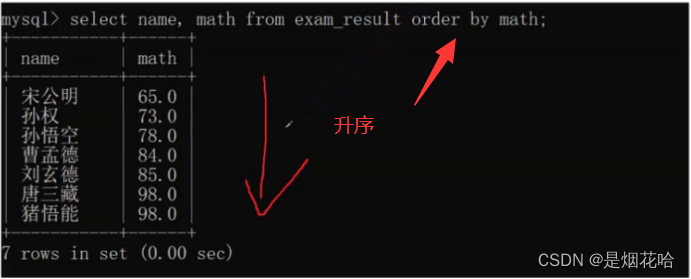
查询结果排序
对查询的结果需要进行排序时,可以使用order by asc(asc 可以默认不写) 即order by
对结果进行升序操作(由小到大):order by
对结果进行降序操作(由大到小):order by desc
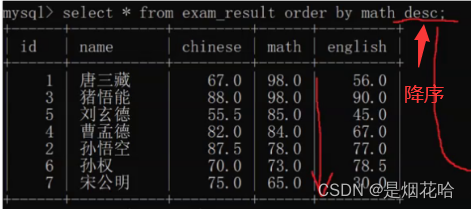
注意点:(orde by 可以后面接别名,比如计算总和时,前面有as total ,后面可以order by total),Where 不能后面接别名
指定条件查询 where
条件查询,可以直接拿两个列进行比较
示例:查询 语文成绩大于数学成绩的学生名单
select name from table where chinese > math;
范围查找区别:between A and B (前闭后闭)
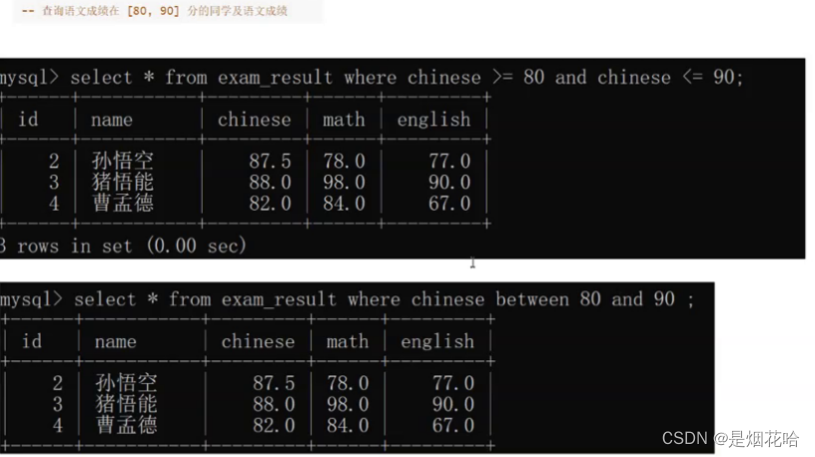
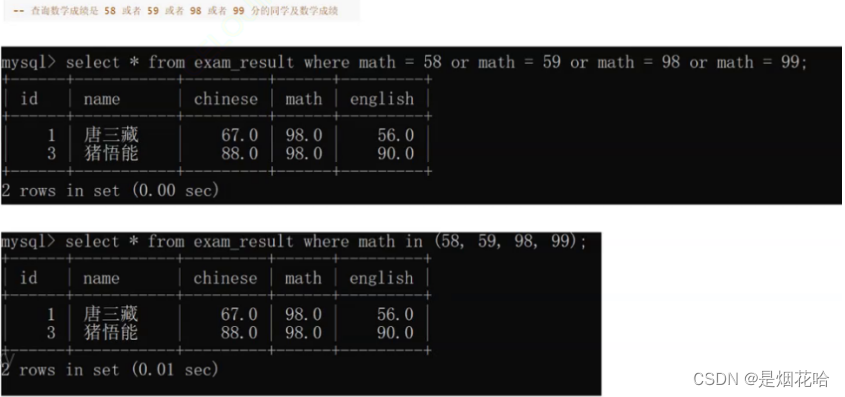
查询某个具体的数值:使用in来表示
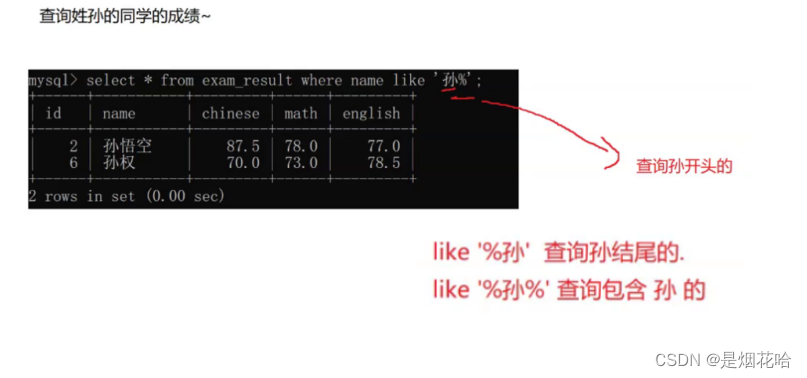
模糊查找某个字符:使用like
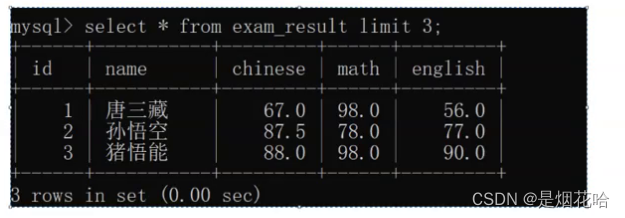
分页查询,使用limit来查询
举例:查询表前3条数据(此时默认从第一页查询)
如果想自定义从某一页查询,就使用offset
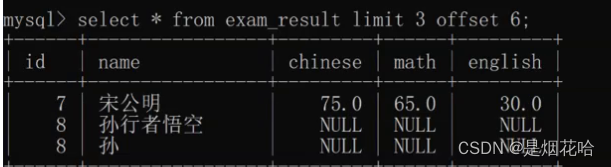
查询结果作为表新增的数据

SQL查询结果进行字符串截取:substring
用法:substring(字符串,截取起始位置,截取字符数)
SQL查询结果进行字符串拼接:concat
用法:concat(字符串1,字符串2,字符串3,......)
SQL查询结果进行字符大写:upper
用法:upper(字符串)
SQL查询结果进行保留小数点位数:round()
使用 Round() 函数,如 Round(number,2) ,其中参数2表示保留小数点后两位有效数字,四舍五入到两位小数。
ROUND(3.141592653, 2) 结果为3.14
聚合查询
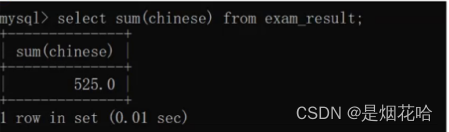
数据求和:sum
sum求和只针对数字有效,无法对字符串进行求和,在对列进行求和时会自动跳过结果为null的行
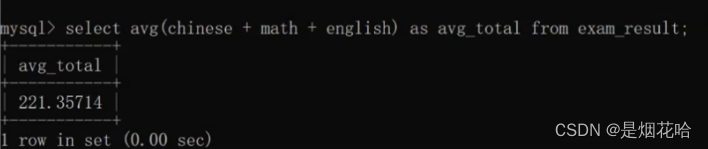
计算平均值:avg
avg能够计算某一列的平均值,使用方法和sum一样

avg还能搭配表达式一起使用
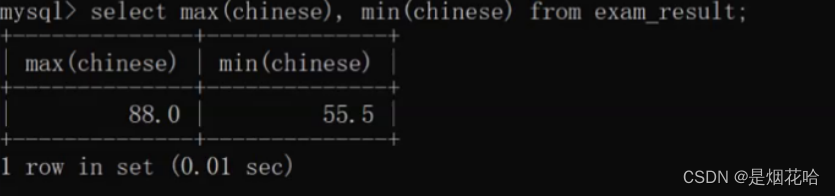
求某列的最大值和最小值 :max \ min
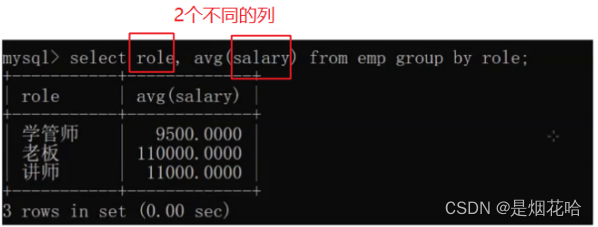
分组查询:group by
分组查询会把相同的列分在同一组中。
比如说如果需要计算某一个岗位的工资就需要把每一个岗位分在同一个组中,再来计算这个岗位的平均工资
条件过滤:having \ where
where: 过滤指定的行
having: 过滤分组,与group by 连用
注意:group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having
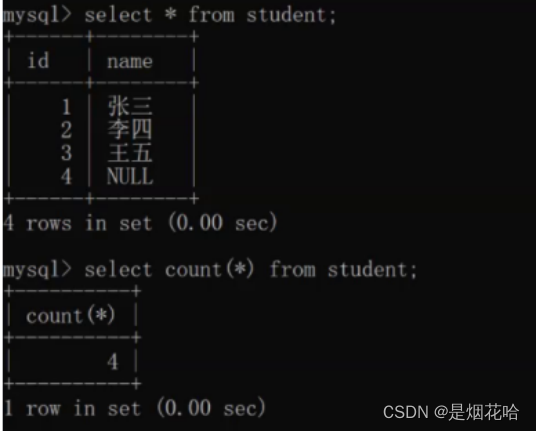
计算表中行的数量:count
select count(*) from 表名;
注意:当涉及到多个数据计算时,使用count记得使用分组group by
多表查询:join on
从多个表中查询不同列数据时,此时就需要使用多表查询语句join on
语句用法:select *from 表1 join 表2 on 条件1 join 表3 on 条件2
示例:
select * from student join score on student.id = score.id join course on course.id = score.course_id;
先考虑 左表 和 中表 进行外连接,得到一个表“临时”,再拿这个“临时”表和 右表 进行外连接
左外连接:left join 表 on
left join ---- 左连接,以左边表的列为主,取两列的交集,如果右表中没有与左表匹配的记录,那么对应的列将填充为 NULL 值
左外连接:表1 left join 表2 on 连接条件,右边表(表2)返回与连接条件完全匹配的数据,左边表(表1)除了返回与连接条件匹配的数据以外,不匹配的数据也会返回;
右外连接:right join 表 on
right join ---- 右连接,以右边表的列为主,取两列的交集,如果左表中没有与右表匹配的记录,那么对应的列将填充为 NULL 值
右外连接:表1 right join 表2 on 连接条件,左边表(表1)返回与连接条件完全匹配的数据,右边表(表2)除了返回与连接条件匹配的数据以外,不匹配的数据也会返回
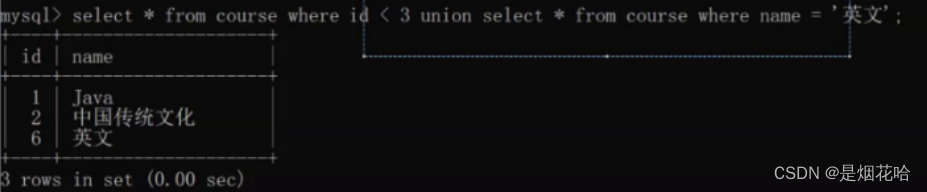
合并多表查询结果:union \ union all
union 可以把多个表的查询结果进行合并,前提条件是多个结果列必须得一一对应。
union:对两个查询结果进行并集操作,自动进行去重,不包括重复行,即去掉重复结果后再显示
union all : 对两个查询结果进行并集操作,不会进行去重,包括重复行,即所有查询结果都会显示
数据库索引
查看索引
show index from 表名;

创建索引
create index 索引名 on 表名(列名);


删除索引
drop index 索引名 on 表名;
窗口排序函数
row_number():连续不重复; 例:1234567
rank() :重复不连续; 例:1222567
dense_rank():重复且连续; 例:1222345
ntile():平均分组; 例:1122334
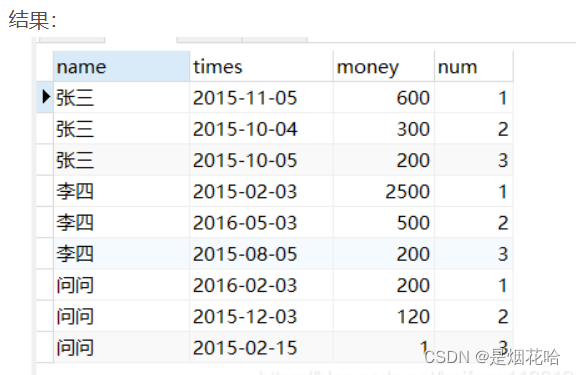
1.row_number()函数:连续不重复
特点: row_number()函数可以为每条记录添加递增的顺序数值序号,即使值完全相同也依次递增序号,不会重复。
语法:row_number() over(partition by fieldname order by fieldname desc/asc)
Select name,times ,money,ROW_NUMBER() over(PARTITION by name ORDER BY money desc) num
From syc
Group by name,times
partition by 用来限定排序的范围,如果不写,则直接在全表中排序。在over中设定以某一列排序,注意,这里的order by,与sql语句中的order by并不冲突,序列按照 over中的 order by排序,但是整个结果集,依然按照sql中的order by排序;
2.rank()函数:重复不连续
特点: rank()函数也是返回每条记录的排名序号,但当值相同时,序号也将相同,同时跳跃排序(比如:第一名、第一名、第三名)
语法:rank() over(partition by fieldname order by fieldname desc/asc)
selkect *, rank() over( order by score desc) num
from sc
where cno ='01’or cno=‘02’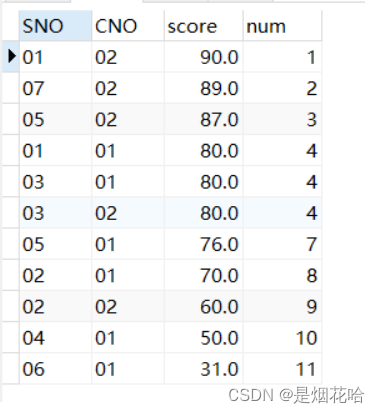
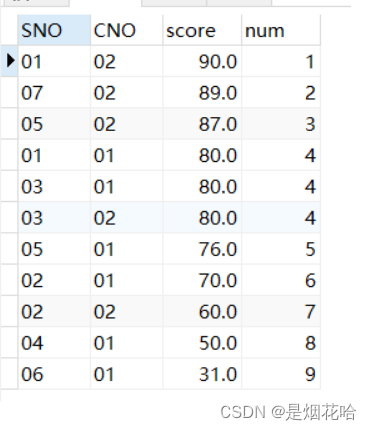
3.dense_rank()函数:重复且连续
特点: dense_rank()函数进行排序时,也会将值相同的数据赋予同一个序号,但与rank()函数不同的是,dense_rank()函数为重复且连续排序(比如第一名、第一名、第二名)。
语法:dense_rank() over(partition by fieldname order by fieldname desc/asc)
select *, dense_rank() over( ORDER BY score desc) num
from sc
where cno ='01'or cno='02'
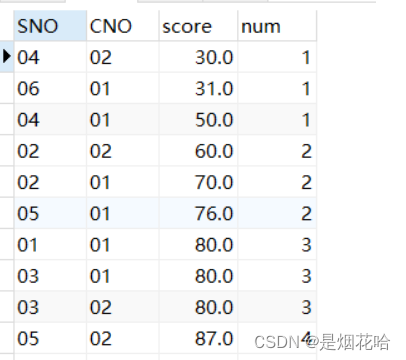
4.ntile(n)函数:平均分组
特点: ntile(n)函数会将数据分为n组,自动进行分组 (每组数量大致相等,若无法均分为n组,则每组的记录数不能大于它上一组的记录数),每组将会分配同一个序号(组号为1-n)。
语法:ntile(n) over(order by fieldname desc/asc)
select *, ntile(4) over( ORDER BY score asc) num
from sc
where cno ='01'or cno='02'
窗口函数参考文章:https://blog.csdn.net/momomuabc/article/details/127902127
https://blog.csdn.net/haifeng112612/article/details/114977365
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)