
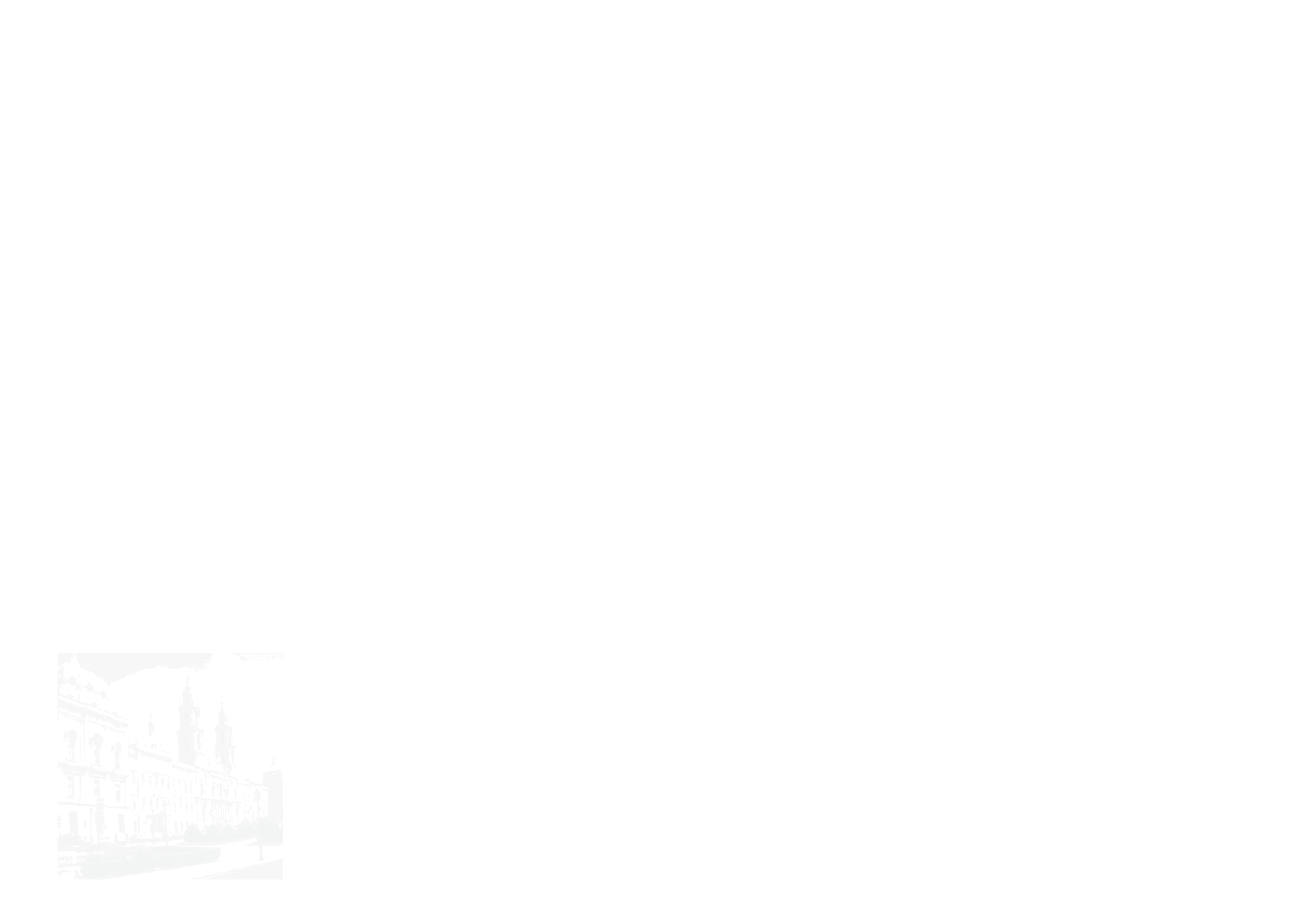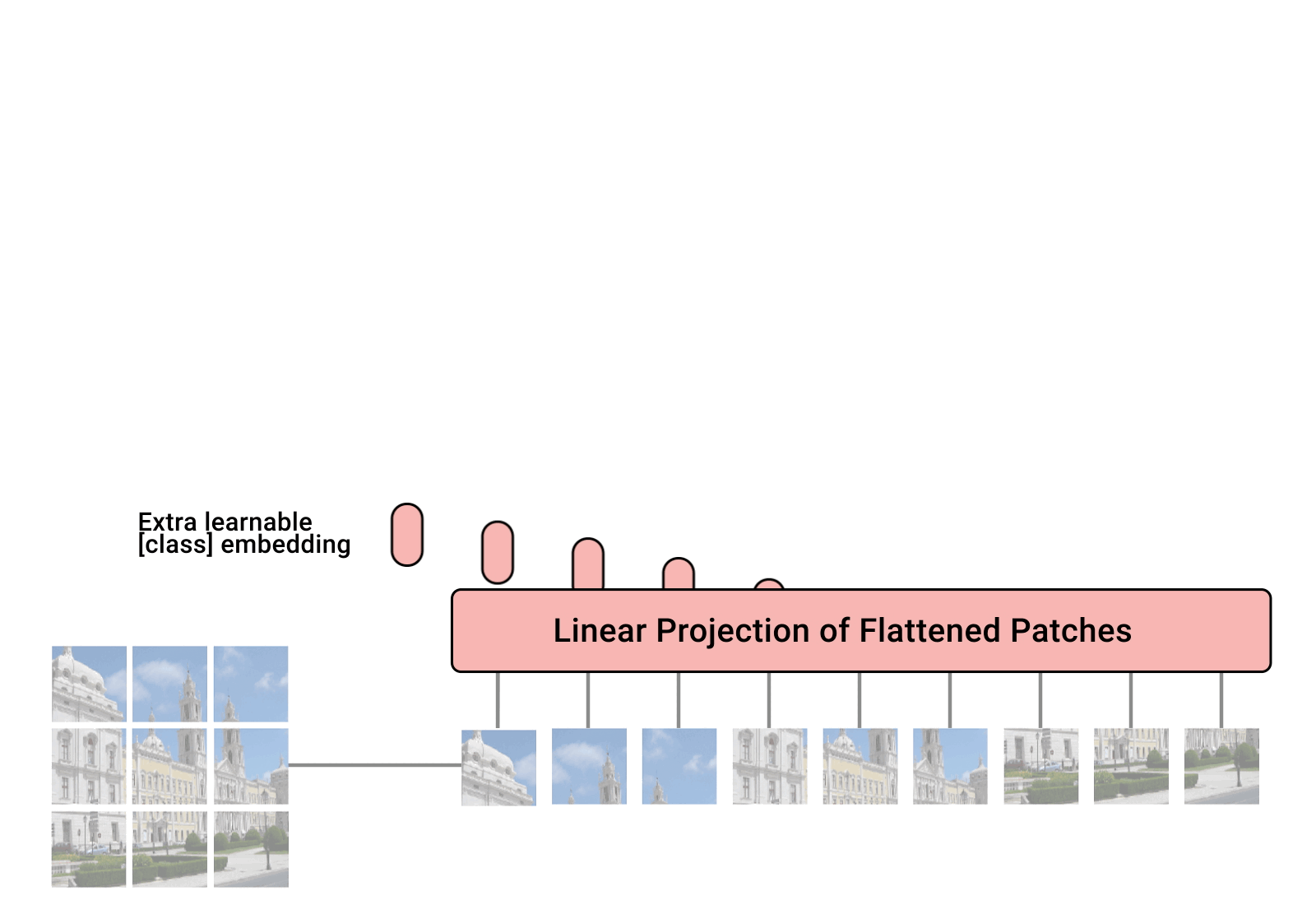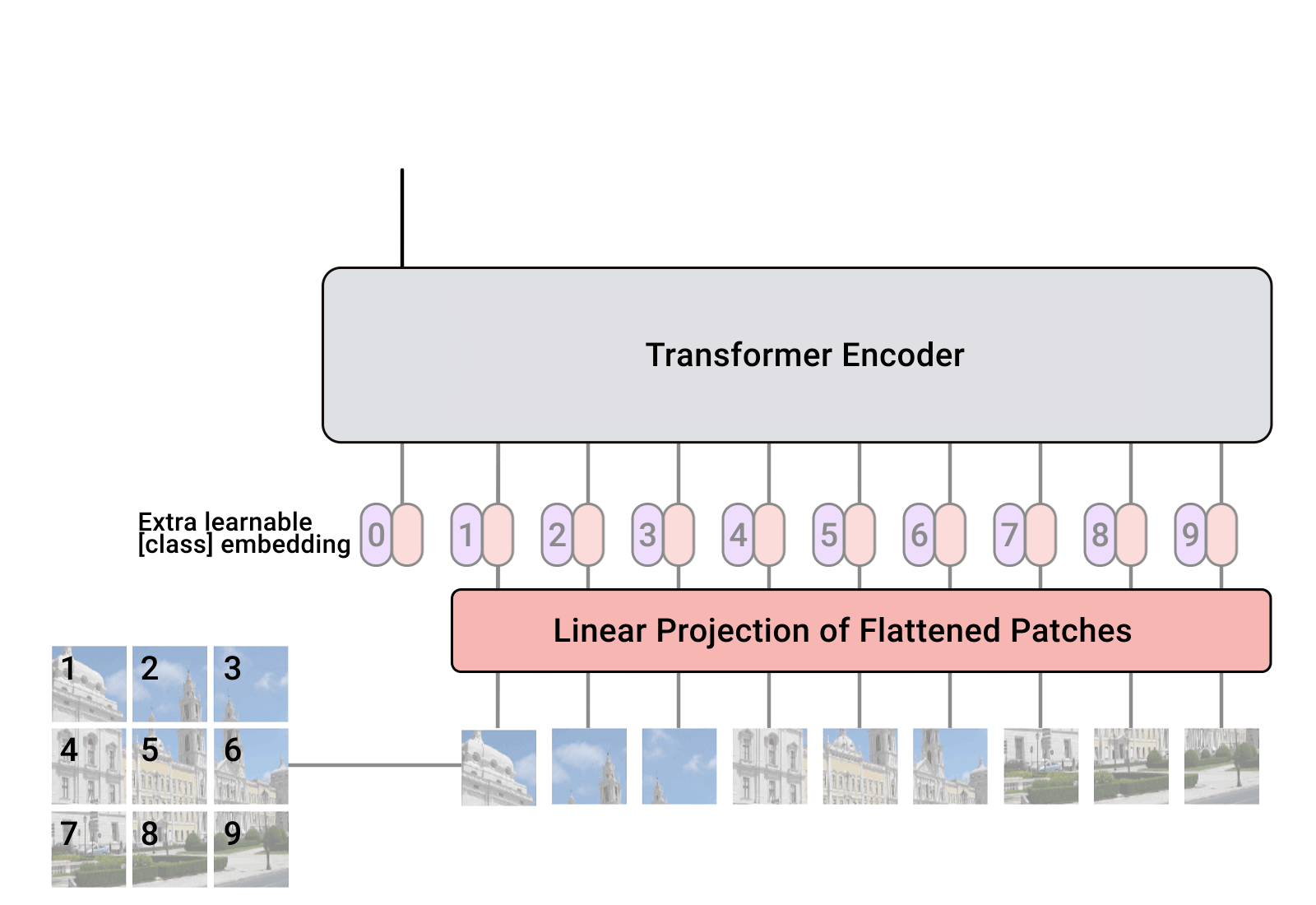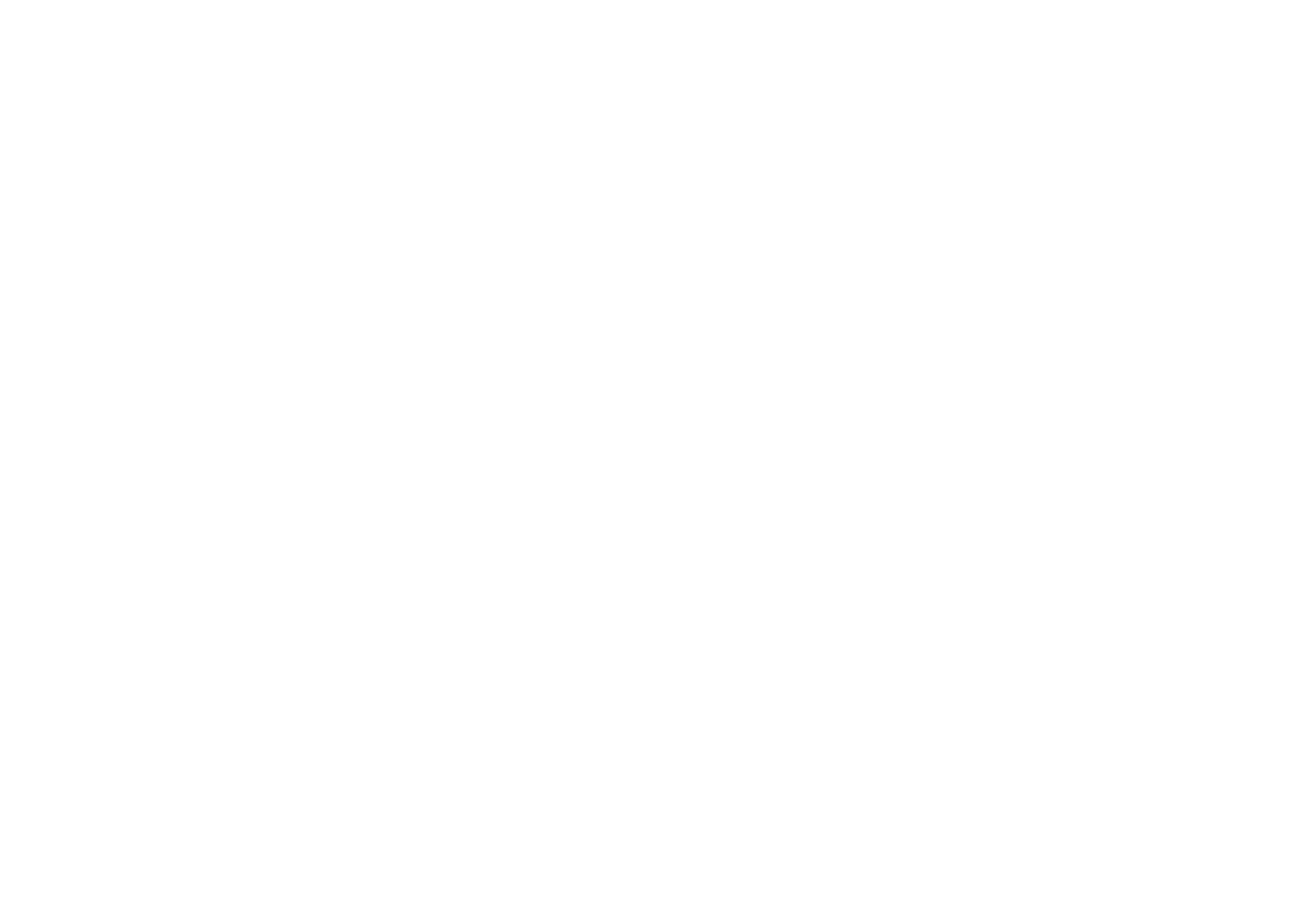
『论文精读』Vision Transformer(VIT)论文解读
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型 “简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
一键AI生成摘要,助你高效阅读
问答
·
| 『论文精读』Vision Transformer(VIT)论文解读 |
文章目录
一. 简介
- ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型 “简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
- ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
- 但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形(translation equivariance), f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x)) ,其中 g g g代表卷积操作, f f f代表平移操作。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
二. 模型架构
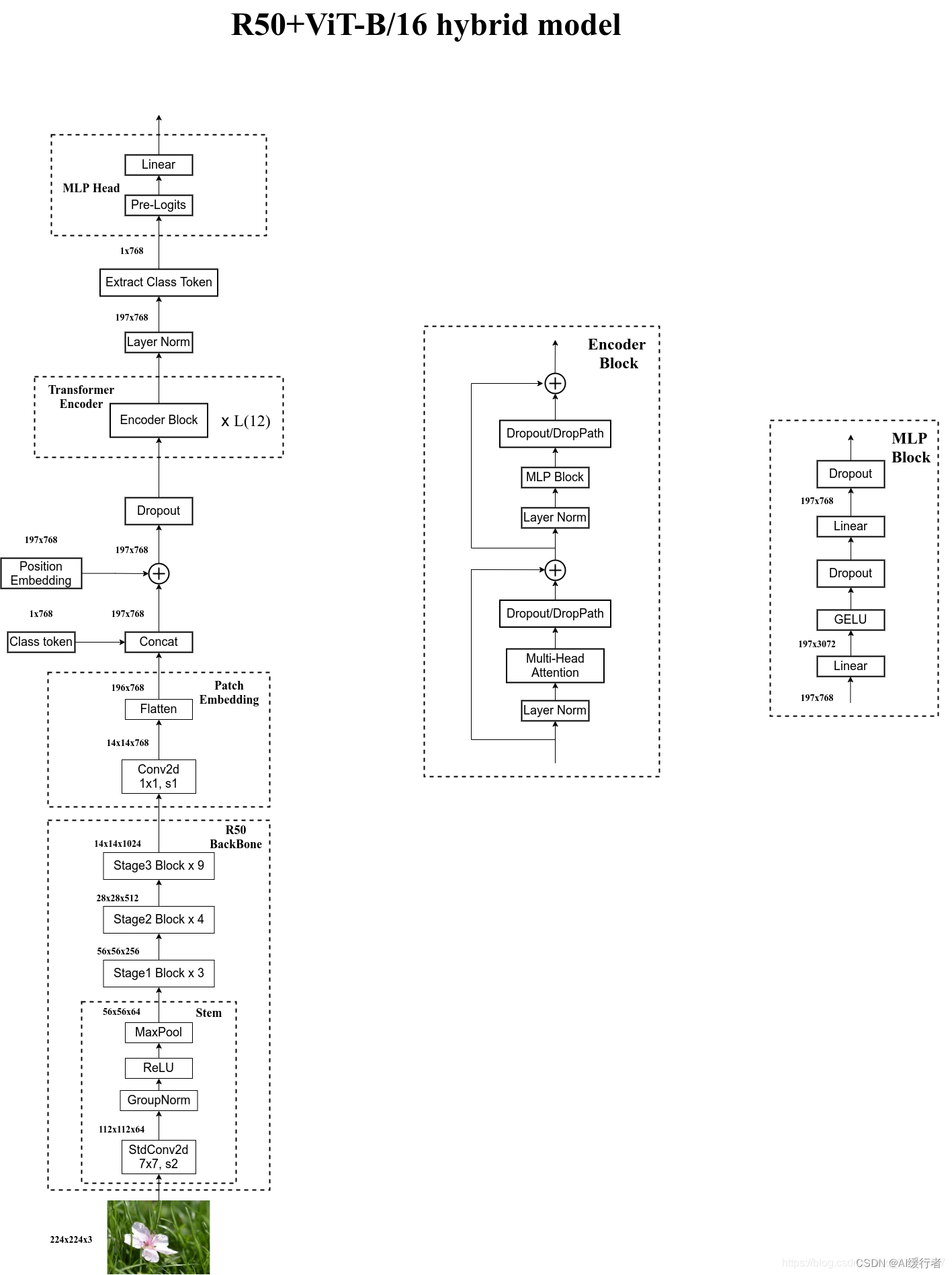
- 模型架构图:ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测。
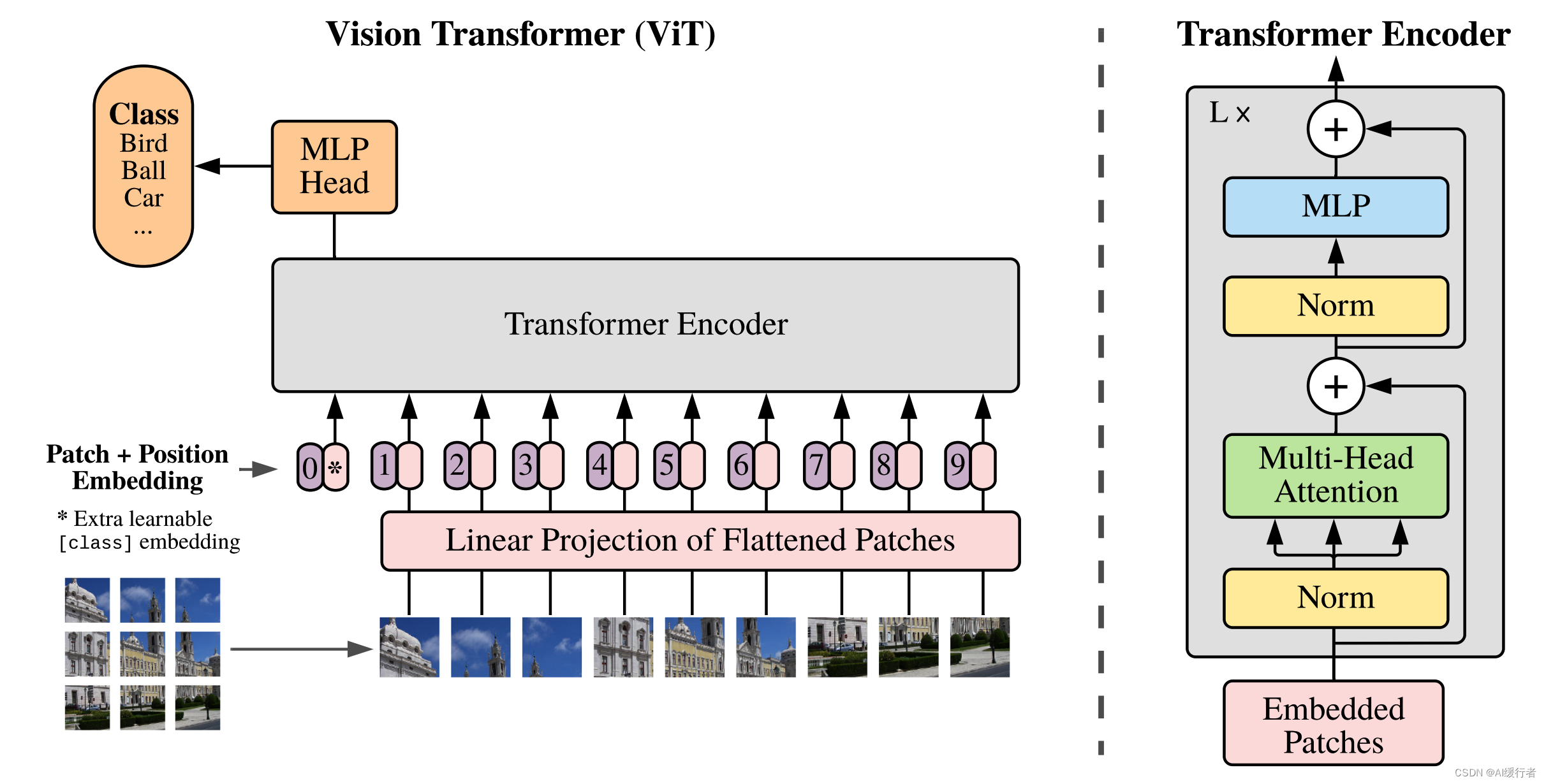
- 模型架构图-动图:

- 按照上面的流程图,一个ViT block可以分为以下几个步骤
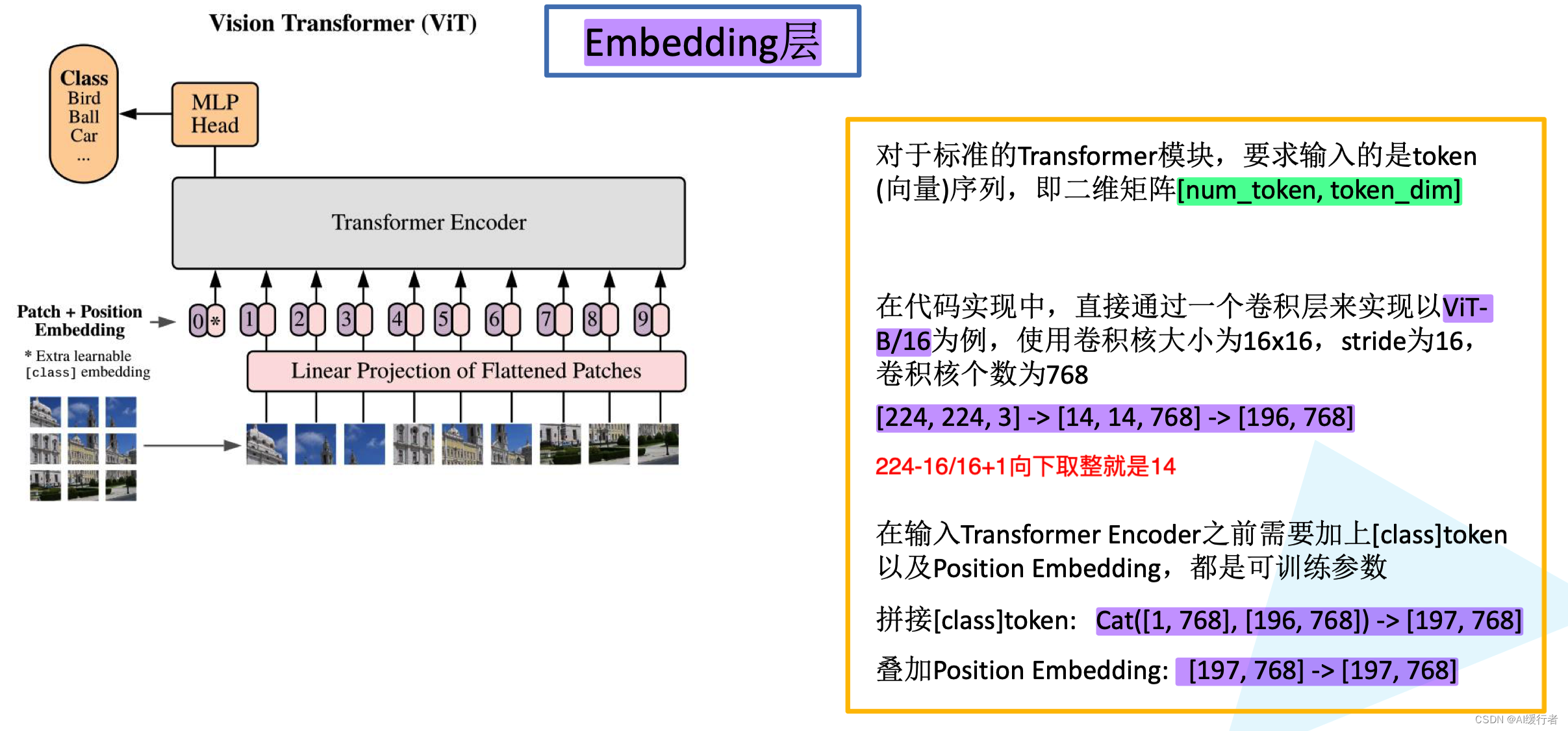
- 1. Patch embedding:例如输入图片大小为 224 × 224 224\times224 224×224,将图片分为固定大小的patch,patch大小为 16 × 16 16\times16 16×16,则每张图像会生成 224 × 224 / 16 × 16 = 196 224\times224/16\times16=196 224×224/16×16=196个patch,即输入序列长度为 196 196 196,每个patch维度 16 × 16 × 3 = 768 16\times16\times3=768 16×16×3=768,线性投射层的维度为 768 × N ( N = 768 ) 768 \times N (N=768) 768×N(N=768),因此输入通过线性投射层之后的维度依然为 196 × 768 196\times768 196×768,即一共有 196 196 196 个token,每个token的维度是 768 768 768。这里还需要在前面加上一个特殊字符cls,因此最终的维度是 197 × 768 197\times 768 197×768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题。
- 2. Positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有 N N N行, N N N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同( 768 768 768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是 197 × 768 197\times 768 197×768。
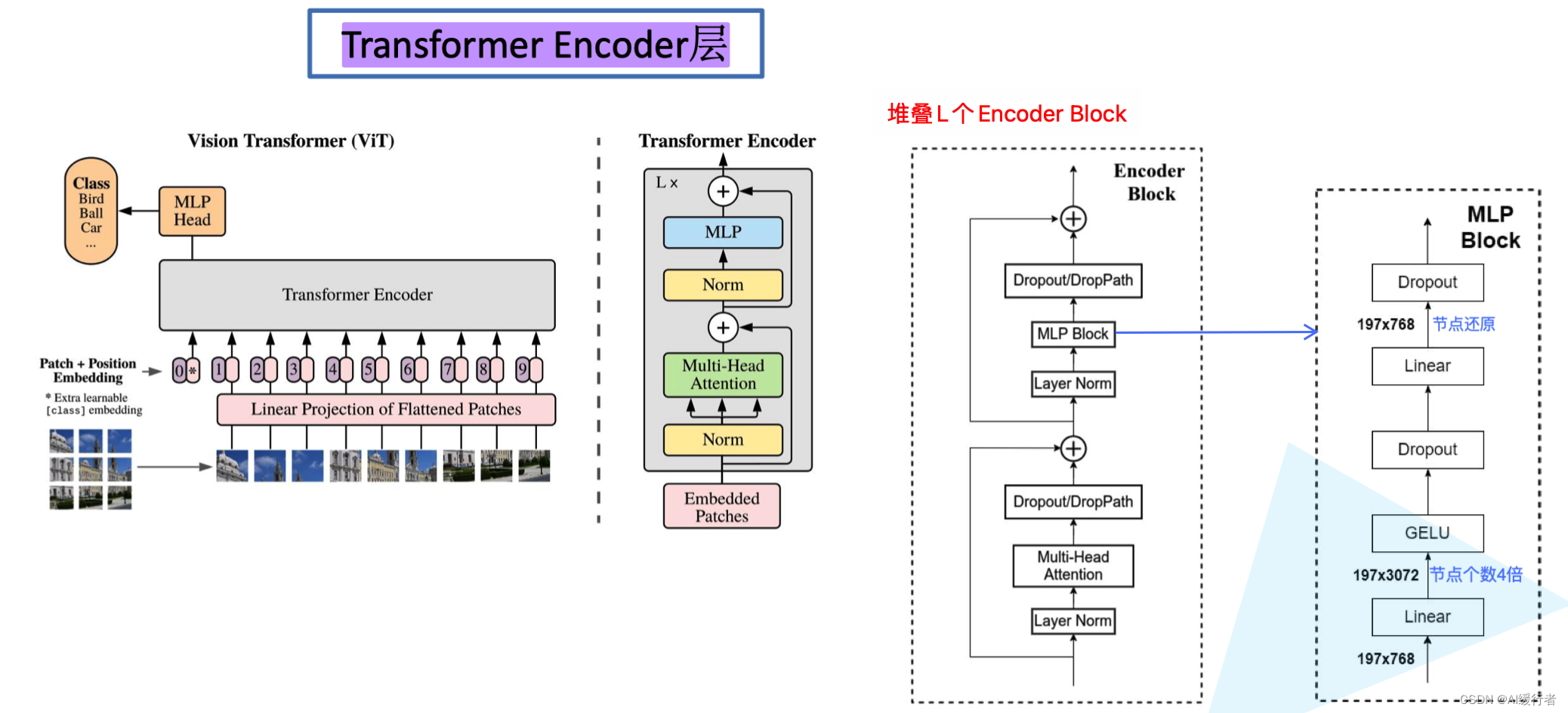
- 3. LN/multi-head attention/LN:LN输出维度依然是 197 × 768 197\times 768 197×768。多头自注意力时,先将输入映射到 q , k , v \boldsymbol {q,k,v} q,k,v,如果只有一个头, q , k , v \boldsymbol {q,k,v} q,k,v的维度都是 197 × 768 197\times 768 197×768,如果有12个头 ( 768 / 12 = 64 ) (768/12=64) (768/12=64),则 q , k , v \boldsymbol {q,k,v} q,k,v的维度是 197 × 64 197\times64 197×64,一共有12组 q , k , v \boldsymbol {q,k,v} q,k,v,最后再将12组 q , k , v \boldsymbol {q,k,v} q,k,v的输出拼接起来,输出维度是 197 × 768 197\times 768 197×768,然后在过一层LN,维度依然是 197 × 768 197\times 768 197×768。
- 4. MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768
- 一个block之后维度依然和输入相同,都是 197 × 768 197\times 768 197×768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出 z L 0 \mathbf z_L^{0} zL0 作为encoder的最终输出,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类。
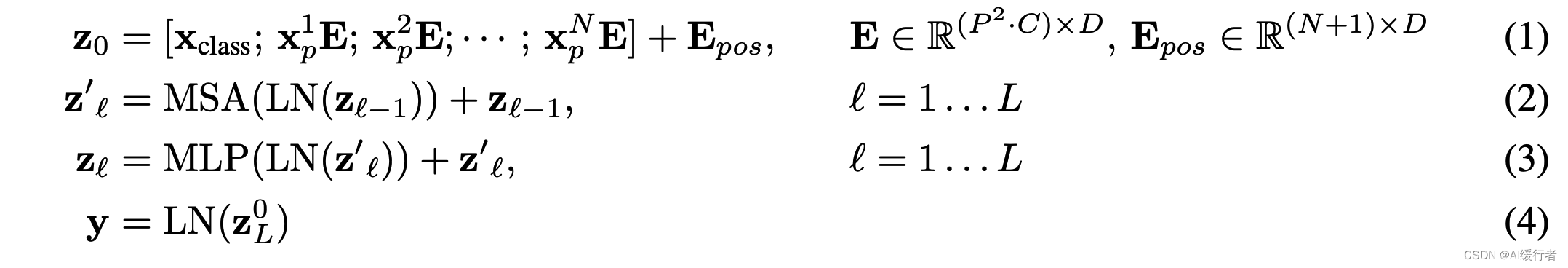
- 其中image x ∈ R H × W × C \mathbf x \in \mathbf{R}^{H\times W \times C} x∈RH×W×C,2D pathes x p ∈ R N × ( P 2 C ) \mathbf x_p \in \mathbf{R}^{N\times (P^2 C)} xp∈RN×(P2C), C C C 是通道数,P是patch大小,一共有 N N N 个patches,
- Embedding层细节问题
- Encoder层细节问题
- Layer Normalization是针对自然语言处理领域提出的,例如像RNN循环神经网络。为什么不使用直接BN呢,因为在RNN这类时序网络中,时序的长度并不是一个定值(网络深度不一定相同),比如每句话的长短都不一定相同,所有很难去使用BN,所以作者提出了Layer Normalization,注意,在图像处理领域中BN比LN是更有效的,但现在很多人将自然语言领域的模型用来处理图像,比如Vision Transformer,此时还是会涉及到LN。参考链接:Layer Normalization解析
- MLP Head层
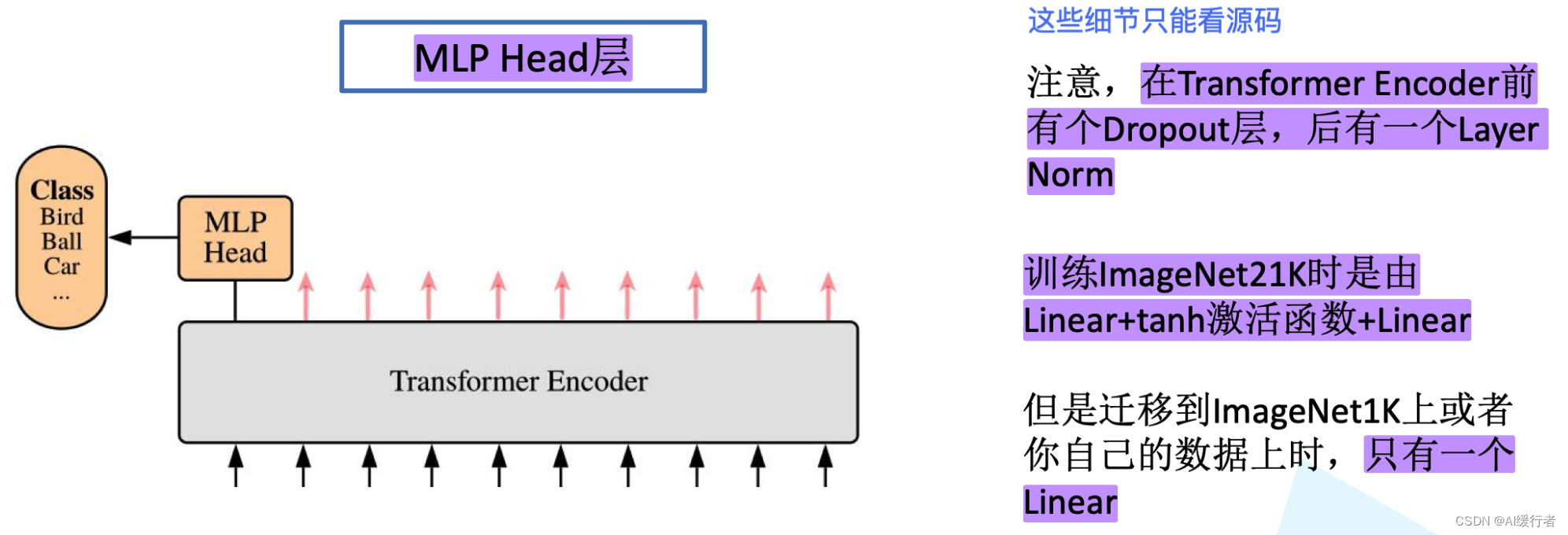
- Vision Transformer网络结构(以ViT-B/16为例)
- 首先卷积层的卷积核大小为 16 × 16 16\times16 16×16,stride为16,卷积核的个数为 768 768 768,通过卷积层之后,数据层由 224 × 224 × 3 224\times 224 \times 3 224×224×3变成 14 × 14 × 768 14\times 14 \times 768 14×14×768,接着我们在高度和宽度方向上进行一个Flatten打平处理 196 × 768 196\times 768 196×768,接着我们Concat一个
Class Token( 1 × 768 1\times 768 1×768),然后在加上Position Embedding( 196 × 768 196\times 768 196×768),再经过一个Dorpout层,在经过Transformer Encoder层(重复L次),
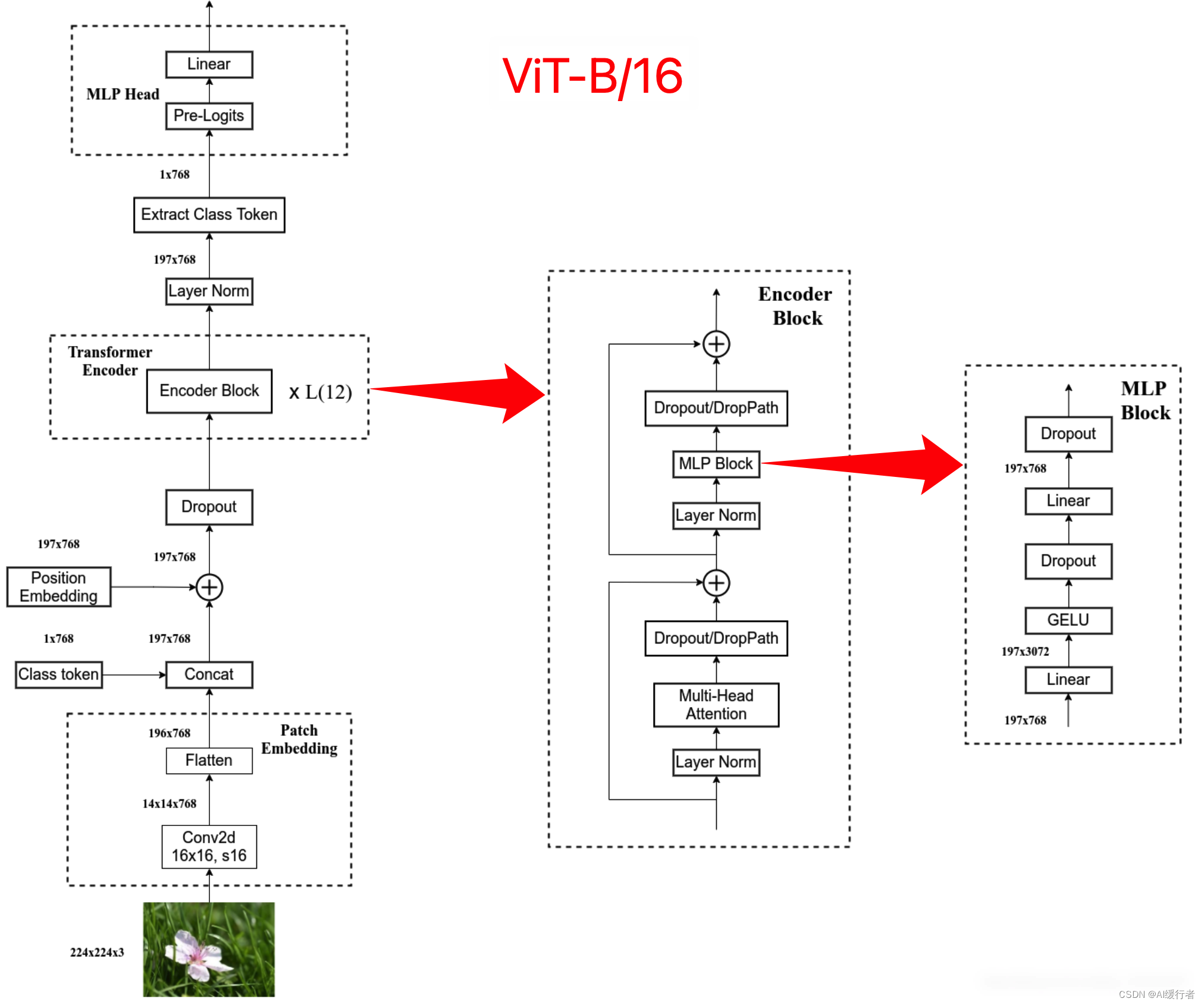
2.1. 关于image presentation
- 是否可以直接使用average pooling得到最终的image presentation,而不加特殊字符cls,通过实验表明,同样可以使用average pooling,原文ViT是为了尽可能是模型结构接近原始的Transformer,所以采用了类似于BERT的做法,加入特殊字符。
- class-token 和 global average pooling 分类器的比较。 两者都工作得很好,但需要不同的学习率。
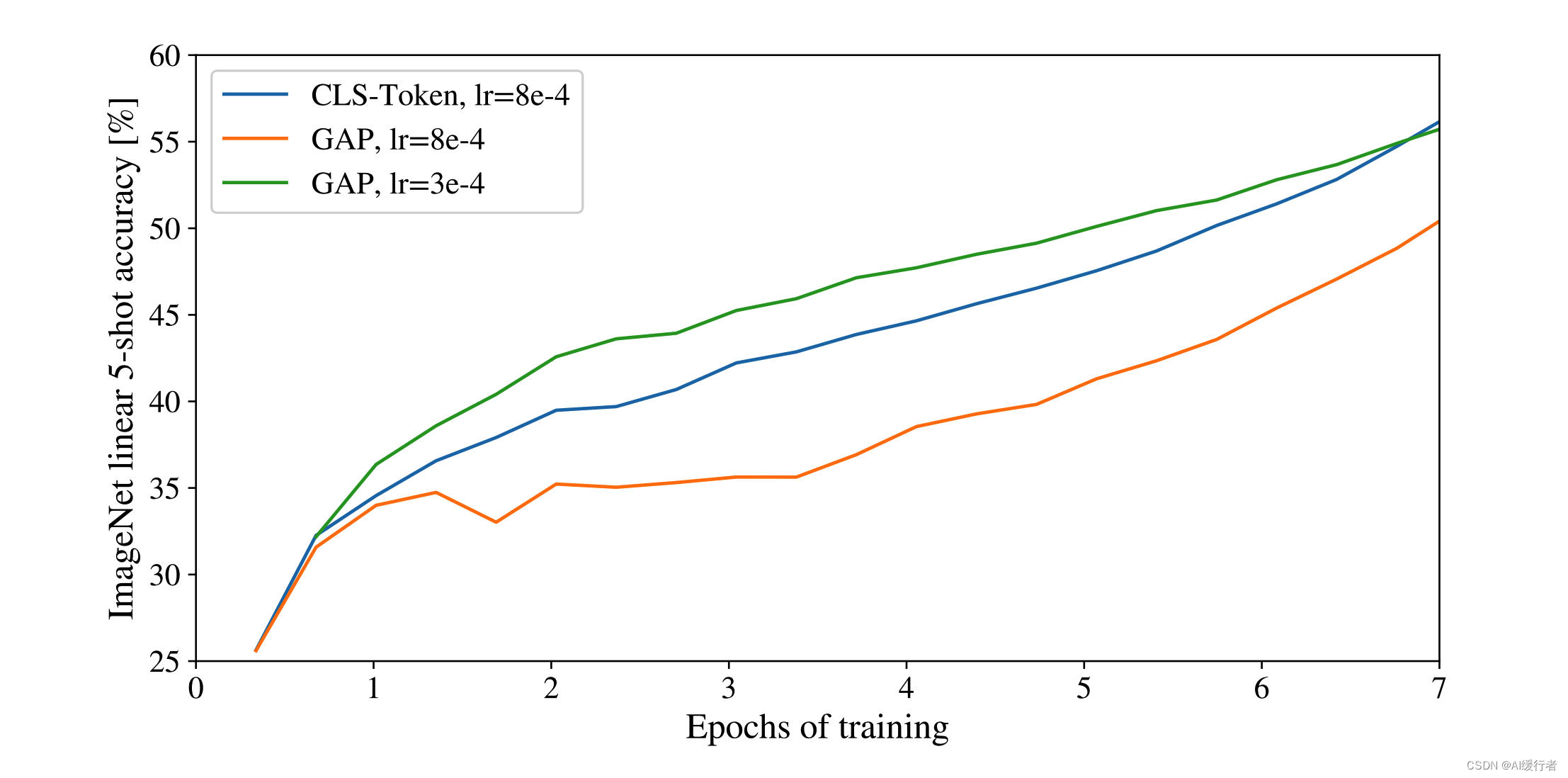
2.2. 关于positional encoding
- 1-D 位置编码:例如 3 × 3 3\times3 3×3共 9 9 9个patch,patch编码为1到9
- 2-D 位置编码:patch编码为 11 , 12 , 13 , 21 , 22 , 23 , 31 , 32 , 33 11,12,13,21,22,23,31,32,33 11,12,13,21,22,23,31,32,33,即同时考虑 X X X和 Y Y Y轴的信息,每个轴的编码维度是 D / 2 D/2 D/2
- 实际实验结果表明,不管使用哪种位置编码方式,模型的精度都很接近,甚至不适用位置编码,模型的性能损失也没有特别大。原因可能是ViT是作用在image patch上的,而不是image pixel,对网络来说这些patch之间的相对位置信息很容易理解,所以使用什么方式的位置编码影像都不大。
2.3. 关于CNN+Transformer
- 既然CNN具有归纳偏置的特性,Transformer又具有很强全局归纳建模能力,使用CNN+Transformer的混合模型是不是可以得到更好的效果呢?将 224 × 224 224\times224 224×224图片送入CNN得到 16 × 16 16\times16 16×16的特征图,拉成一个向量,长度为196,后续操作和ViT相同
2.4. 关于输入图片大小
- 通常在一个很大的数据集上预训练ViT,然后在下游任务相对小的数据集上微调,已有研究表明在分辨率更高的图片上微调比在在分辨率更低的图片上预训练效果更好(It is often beneficial to fine-tune at higher resolution than pre-training)(参考2019-NIPS-Fixing the train test resolution discrepancy)
- 当输入图片分辨率发生变化,输入序列的长度也发生变化,虽然ViT可以处理任意长度的序列,但是预训练好的位置编码无法再使用(例如原来是 3 × 3 3\times3 3×3,一种9个patch,每个patch的位置编码都是有明确意义的,如果patch数量变多,位置信息就会发生变化),一种做法是使用插值算法,扩大位置编码表。但是如果序列长度变化过大,插值操作会损失模型性能,这是ViT在微调时的一种局限性
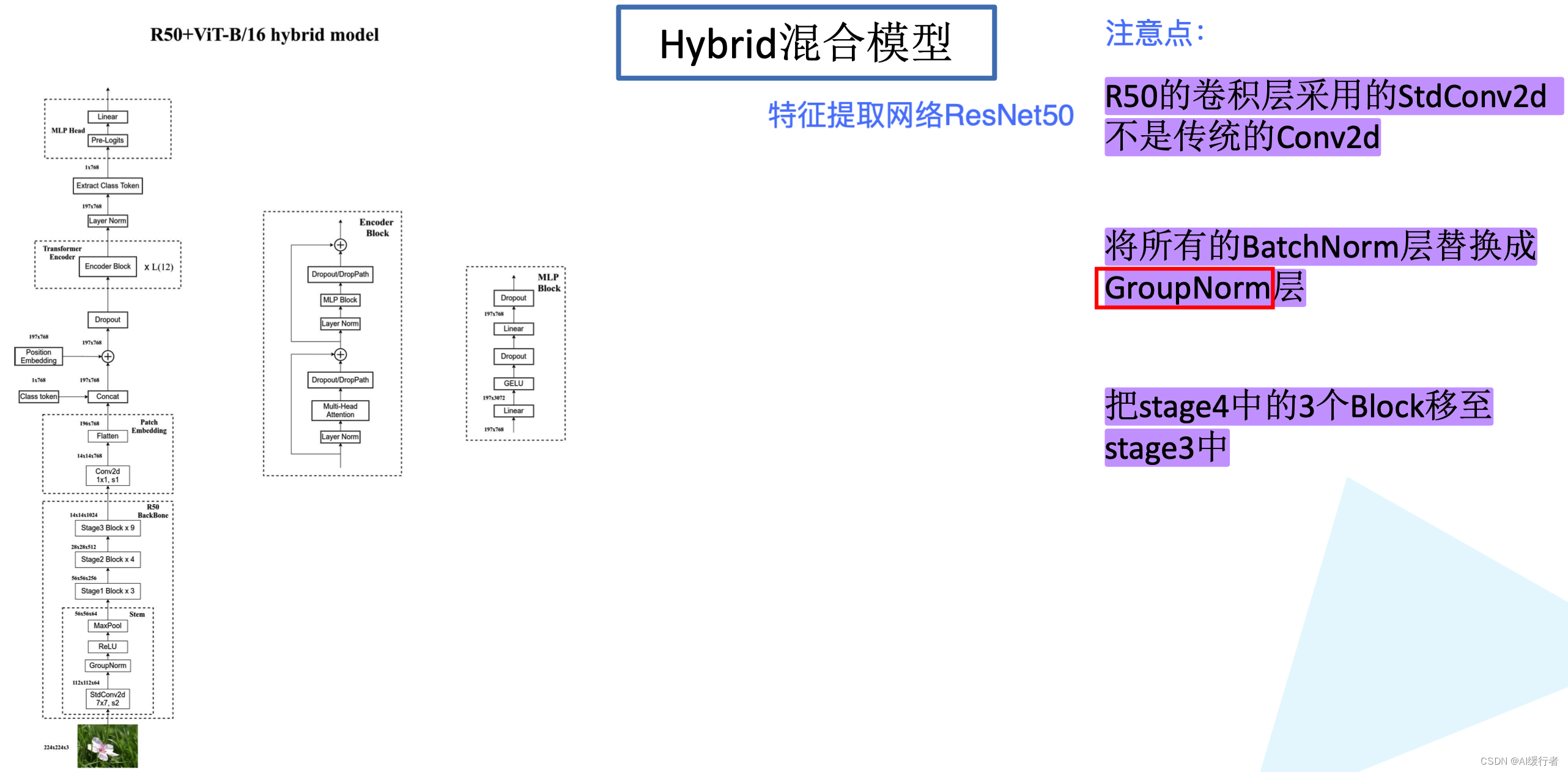
2.5. Hybrid混合模型
三. 实验部分
3.1. 数据集
- 为了探究模型的可扩展性(to explore model scalability),预训练阶段使用了
ImageNet-1K(130万)、ImageNet-21K(1400万),JFT-18K(30300万)三个数据集。同时参考BiT,删除预训练数据集中和下游任务测试集中重复的数据(de-duplicate the pre-training datasets w.r.t. the test sets of the downstream)- 下游数据集包括:
ImageNet(on the original validation labels),ImageNet (on the cleaned-up ReaL labels ),CIFAR-10/100,Oxford-IIIT Pets,Oxford Flowers-102,VTAB (19 tasks)
- imagenet-1k是 ISLVRC2012的数据集,训练集大约是1281167张+标签,验证集是50000张图片加标签,最终打分的测试集是100000张图片,一共1000个类别。
- imagenet-21k是WordNet架构组织收集的所有图片,大约1400万张,2.1万个类。多用于自监督预训练,比如VIT。
3.2. 模型及变体
- ViT:参考BERT,共设置了三种模型变体(增加了Huge变体)如下图所示。例如
ViT-L/16,代表Large变体,输入patch size为16x16。- CNN:baseline CNNs选择ResNet,同时用Group Normalization替代Batch Normalization,使用standardized convolutions,以提升模型迁移性能。
- Hybrid:混合模型就是使用ResNet50输出的特征图,不同stage会得到不同大小的特征图,即生成不同长度序列
- Layers是Transformer Encoder中重复堆叠Encoder Block的次数;
- Hidden Size是通过Embedding层后每个token的dim(向量的长度,也就是卷积核使用的个数)
- MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍)
- Heads代表Transformer中Multi-Head Attention的heads数
| Model | Patch Size | Layers | Hidden Size D | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| ViT-Base | 16 × 16 16\times16 16×16 | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 16 × 16 16\times16 16×16 | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 14 × 14 14\times14 14×14 | 32 | 1280 | 5120 | 16 | 632M |
- 下面的实验显示,当在很大的数据集上预训练时,ViT性能超越CNN,后面探究不同大小预训练数据集对模型性能的影响(不能只看超大数据集)
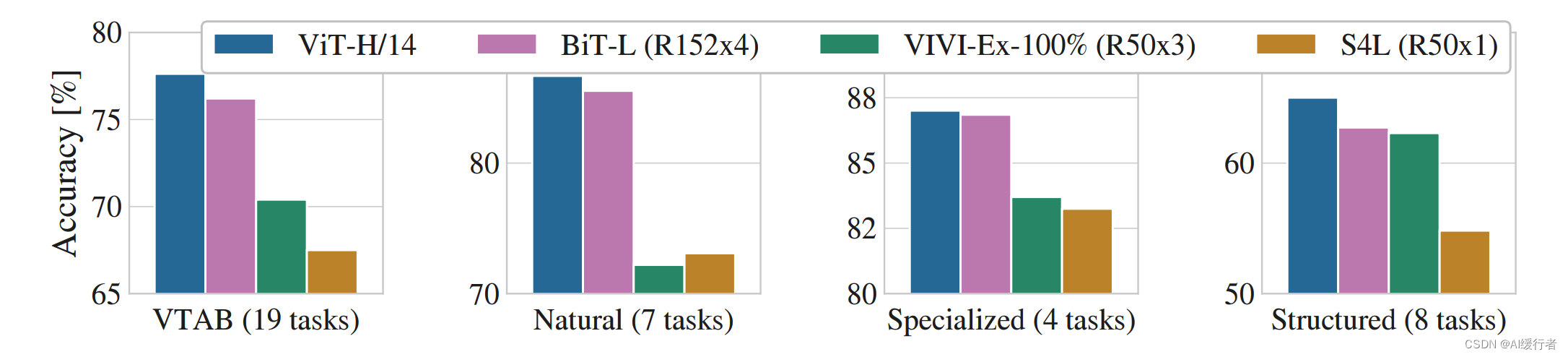
3.3. 实验结果
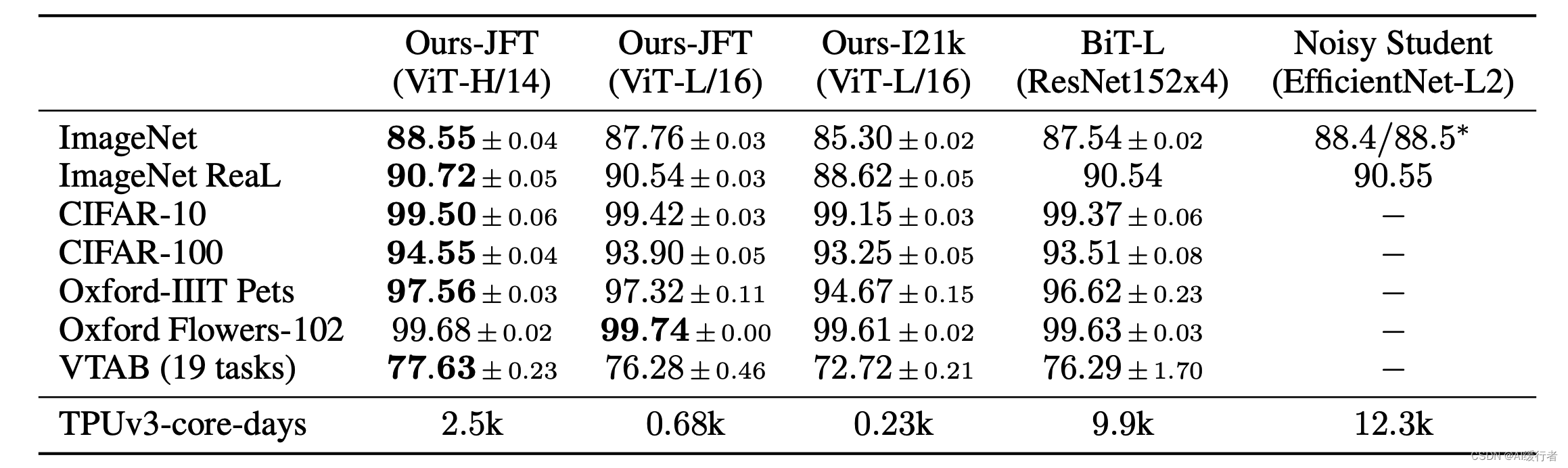
- ViT和其它SOTA模型性能对比,展示了准确率accuraces的均值和标准差,所有结果都是取三轮微调均值的结果(averaged over three fine-tunning runs)。有关ImageNet的实验,在更高分辨率图片上微调(512 for ViT-L/16 and 518 for ViT-H/14),同时使用了Polyak averaging(0.9999)
- 可以看到在JFT数据集上预训练的ViT模型,迁移到下游任务后,表现要好于基于ResNet的BiT和基于EfficientNet的Noisy Student,且需要更少的预训练时间
3.4. 模型可视化
- 位置编码得相似性分析(cos),位置越接接近,patches之间的相似度越高;相同行/列的patches有相似的embeddings;这里的patches大小是 32 × 32 的 224 / 32 = 7 32\times32 的 224/32=7 32×32的224/32=7,所以大小是大 7 × 7 7\times 7 7×7
- 第1行第1个patches它所对应的位置编码,首先与它自己进行一个余弦相似度的计算,肯定是等于1,这里对应的是黄色。再最后1个,它与最后1行最后1列的余弦相似度是最高的。

参考文献
- ViT(Vision Transformer)解析:https://zhuanlan.zhihu.com/p/445122996
- 霹雳吧啦Wz大神的Vision Transformer详解:https://blog.csdn.net/qq_37541097/article/details/118242600
- Visual Transformer (ViT)模型结构以及原理解析:https://www.jianshu.com/p/d4bc4f540c62

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)