
巨细!Python爬虫详解(建议收藏)
爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。
爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,他们沿着蜘蛛网抓取自己想要的猎物/数据。(全套Python教程文末领取哈)
爬虫的基本流程

网页的请求与响应
网页的请求和响应方式是 Request 和 Response
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,收到请求信息后返回数据(返回的数据中可能包含其他链接,如:image、js、css等)
浏览器在接收 Response 后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收 Response 后,是要提取其中的有用数据。
1、发起请求:Request
请求的发起是使用 http 库向目标站点发起请求,即发送一个Request
Request对象的作用是与客户端交互,收集客户端的 Form、Cookies、超链接,或者收集服务器端的环境变量。
Request 对象是从客户端向服务器发出请求,包括用户提交的信息以及客户端的一些信息。客户端可通过 HTML 表单或在网页地址后面提供参数的方法提交数据。
然后服务器通过 request 对象的相关方法来获取这些数据。request 的各种方法主要用来处理客户端浏览器提交的请求中的各项参数和选项。
Request 包含:请求 URL、请求头、请求体等
**Request 请求方式:**GET/POST
**请求url:**url全称统一资源定位符,一个网页文档、一张图片、 一个视频等都可以用url唯一来确定
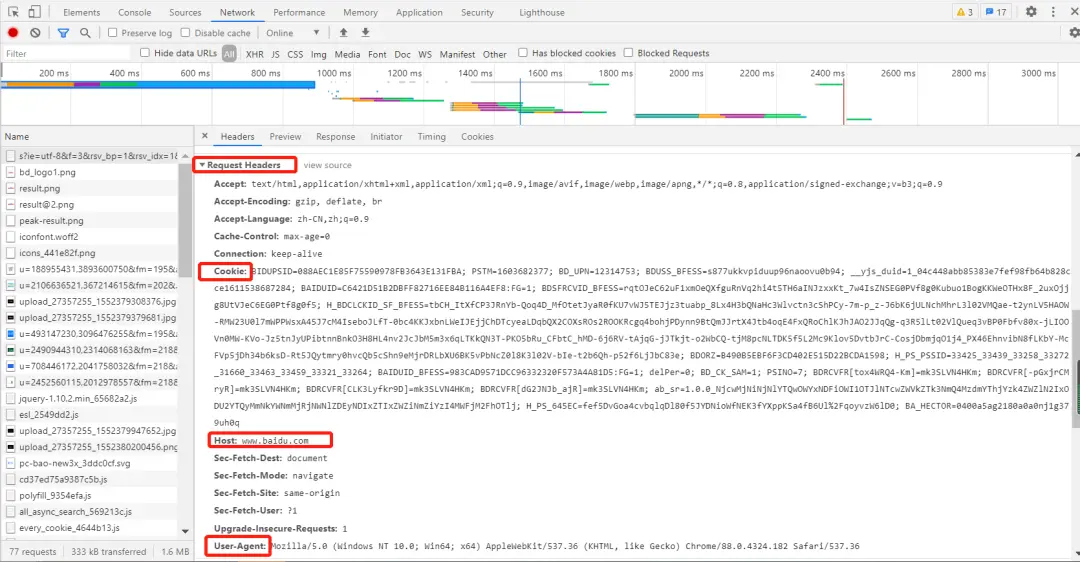
**请求头:**User-agent:请求头中如果没有 user-agent 客户端配置,服务端可能将你当做一个非法用户;
**cookies:**cookie 用来保存登录信息
一般做爬虫都会加上请求头
例如:抓取百度网址的数据请求信息如下:
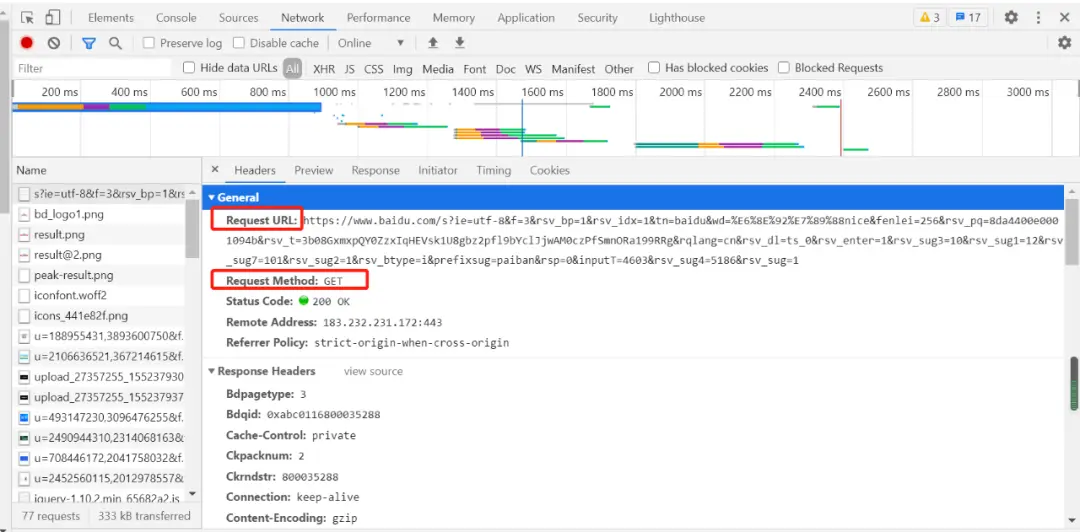
2、获取响应内容
爬虫程序在发送请求后,如果服务器能正常响应,则会得到一个Response,即响应;
Response 信息包含:html、json、图片、视频等,如果没报错则能看到网页的基本信息。例如:一个的获取网页响应内容程序如下:
import requests
request_headers={
‘Accept’:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9’,
‘Cookie’:‘BIDUPSID=088AEC1E85F75590978FB3643E131FBA; PSTM=1603682377; BD_UPN=12314753; BDUSS_BFESS=s877ukkvpiduup96naoovu0b94; __yjs_duid=1_04c448abb85383e7fef98fb64b828cce1611538687284; BAIDUID=C6421D51B2DBFF82716EE84B116A4EF8:FG=1; BDSFRCVID_BFESS=rqtOJeC62uF1xmOeQXfguRnVq2hi4t5TH6aINJzxxKt_7w4IsZNSEG0PVf8g0Kubuo1BogKKWeOTHx8F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbCH_ItXfCP3JRnYb-Qoq4D_MfOtetJyaR0fKU7vWJ5TEJjz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VMQae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjjChDTcyeaLDqbQX2COXsROs2ROOKRcgq4bohjPDynn9BtQmJJrtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW-KVo-Jz5tnJyUPibtnnBnkO3H8HL4nv2JcJbM5m3x6qLTKkQN3T-PKO5bRu_CFbtC_hMD-6j6RV-tAjqG-jJTkjt-o2WbCQ-tjM8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN8fLKbY-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2b6Qh-p52f6LjJbC83e; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33439_33258_33272_31660_33463_33459_33321_33264; BAIDUID_BFESS=983CAD9571DCC96332320F573A4A81D5:FG=1; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BD_HOME=1; H_PS_645EC=0c49V2LWy0d6V4FbFplBYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM; BA_HECTOR=0l05812h21248584dc1g38qhn0r; COOKIE_SESSION=1_0_8_3_3_9_0_0_7_3_0_1_5365_0_3_0_1614047800_0_1614047797%7C9%23418111_17_1611988660%7C5; BDSVRTM=1’,
‘Host’:‘www.baidu.com’,
‘User-Agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36’}
response = requests.get(‘https://www.baidu.com/s’,params={‘wd’:‘帅哥’},headers=request_headers)#params内部就是调用urlencode
print(response.text)
以上内容输出的就是网页的基本信息,它包含 html、json、图片、视频等,如下图所示:
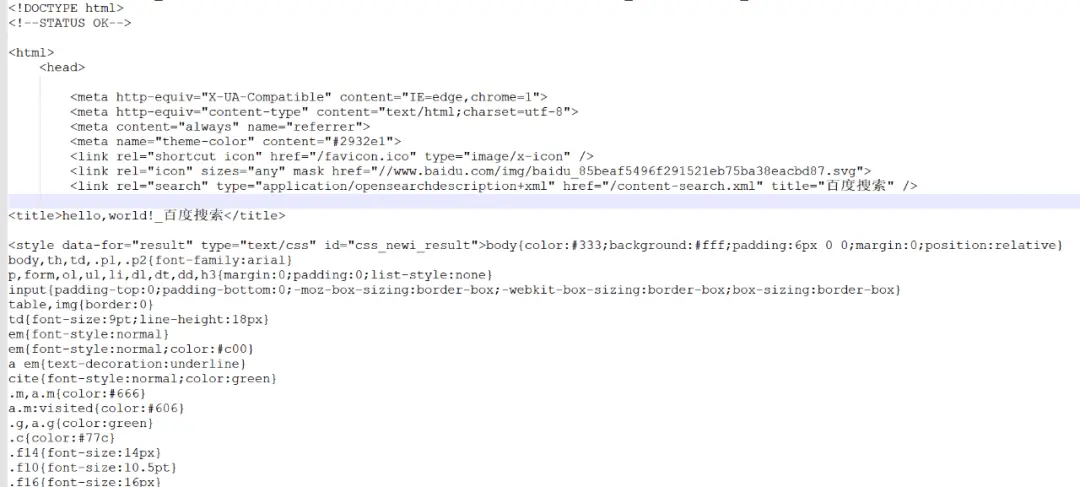
Response 响应后会返回一些响应信息,例下:
1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误
2、Respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
3、preview 是网页源代码
最主要的部分,包含了请求资源的内容,如网页html、图片、二进制数据等
3、解析内容
解析 html 数据:解析 html 数据方法有使用正则表达式、第三方解析库如 Beautifulsoup,pyquery 等
解析 json 数据:解析 json数据可使用 json 模块
解析二进制数据:以 b 的方式写入文件
4、保存数据
爬取的数据以文件的形式保存在本地或者直接将抓取的内容保存在数据库中,数据库可以是 MySQL、Mongdb、Redis、Oracle 等……
写在最后
爬虫的总流程可以理解为:蜘蛛要抓某个猎物–>沿着蛛丝找到猎物–>吃到猎物;即爬取–>解析–>存储;
在爬取数据过程中所需参考工具如下:
爬虫框架:Scrapy
请求库:requests、selenium
解析库:正则、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis……
总结
今天的文章是对爬虫的原理做一个详解,希望对大家有帮助,同时也在后面的工作中奠定基础!
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
- ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
- ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
- ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
- ⑦ 超300本Python电子好书,从入门到高阶应有尽有
- ⑧ 华为出品独家Python漫画教程,手机也能学习
- ⑨ 历年互联网企业Python面试真题,复习时非常方便
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈
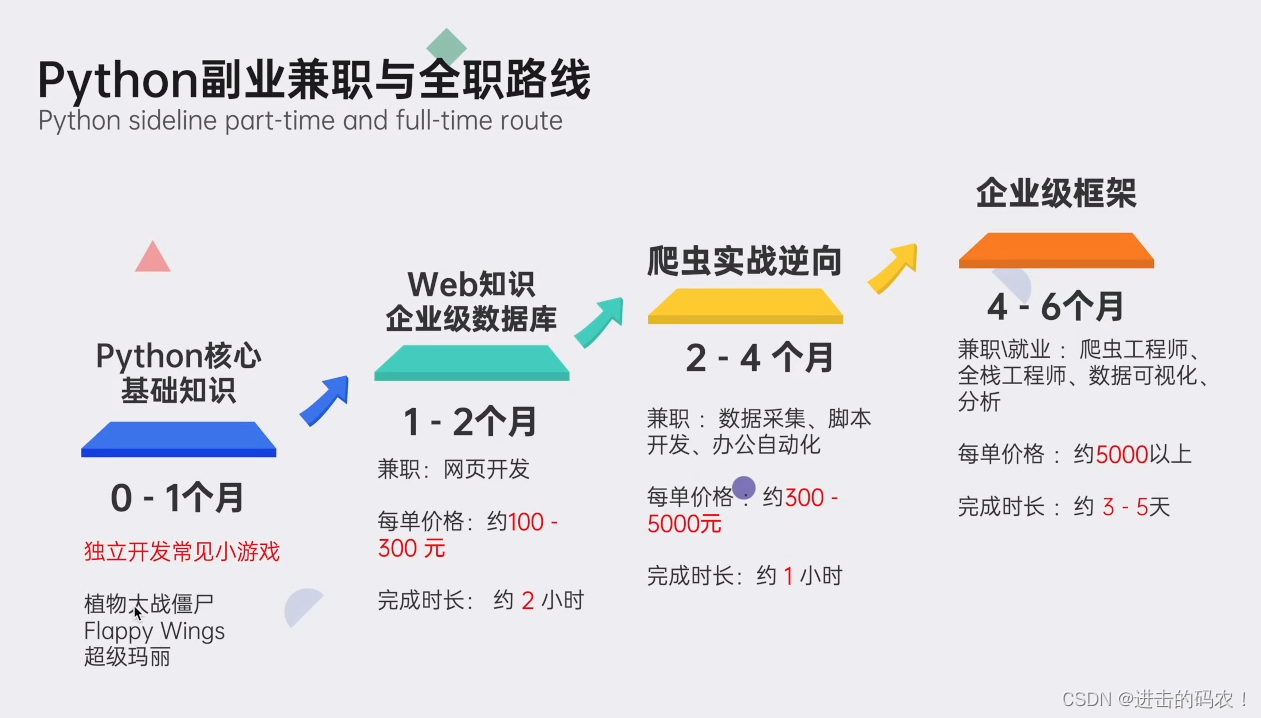
👉python副业兼职与全职路线👈
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)