k8s补充+helm+minikube
目录
master高可用
架构

master节点——整个集群的控制中枢
- Kube-APIServer:集群的控制中枢,各个模块之间信息交互都需要经过Kube-APIServer,同时它也是集群管理、资源配置、整个集群安全机制的入口。
- Controller-Manager:集群的状态管理器,保证Pod或其他资源达到期望值,也是需要和APIServer进行通信,在需要的时候创建、更新或删除它所管理的资源。
- Scheduler:集群的调度中心,它会根据指定的一系列条件,选择一个或一批最佳的节点,然后部署我们的Pod。
- Etcd:键值数据库,报错一些集群的信息,一般生产环境中建议部署三个以上节点(奇数个)。
node节点——工作节点
Worker、node节点、minion节点
- Kubelet:负责监听节点上Pod的状态,同时负责上报节点和节点上面Pod的状态,负责与Master节点通信,并管理节点上面的Pod。
- Kube-proxy:负责Pod之间的通信和负载均衡,将指定的流量分发到后端正确的机器上。
- 查看Kube-proxy工作模式:curl 127.0.0.1:10249/proxyMode
- Ipvs:监听Master节点增加和删除service以及endpoint的消息,调用Netlink接口创建相应的IPVS规则。通过IPVS规则,将流量转发至相应的Pod上。
- Iptables:监听Master节点增加和删除service以及endpoint的消息,对于每一个Service,他都会场景一个iptables规则,将service的clusterIP代理到后端对应的Pod。
其他组件
- Calico:符合CNI标准的网络插件,给每个Pod生成一个唯一的IP地址,并且把每个节点当做一个路由器。
- CoreDNS:用于Kubernetes集群内部Service的解析,可以让Pod把Service名称解析成IP地址,然后通过Service的IP地址进行连接到对应的应用上。
- Docker:容器引擎,负责对容器的管理。
搭建
…
kubeadm搭建
…
二进制搭建
…
探针
- StartupProbe:k8s 1.16版本后新加的探测方式,用于判断容器内应用程序是否已经启动。如果配置了startupProbe,就会先禁止其他的探测,直到它成功为止,成功后将不在进行探测。
- LivenessProbe:用于探测容器是否运行,如果探测失败,kubelet会根据配置的重启策略进行相应的处理。若没有配置该探针,默认就是success。
- ReadinessProbe:一般用于探测容器内的程序是否健康,它的返回值如果为success,那么久代表这个容器已经完成启动,并且程序已经是可以接受流量的状态。
检测方式
- ExecAction:在容器内执行一个命令,如果返回值为0,则认为容器健康。
- TCPSocketAction:通过TCP连接检查容器内的端口是否是通的,如果是通的就认为容器健康。
- HTTPGetAction:通过应用程序暴露的API地址来检查程序是否是正常的,如果状态码为200~400之间,则认为容器健康。
探针检查参数配置
initialDelaySeconds: 60 # 初始化时间
timeoutSeconds: 2 # 超时时间
periodSeconds: 5 # 检测间隔
successThreshold: 1 # 检查成功为1次表示就绪
failureThreshold: 2 # 检测失败2次表示未就绪
执行顺序
在 Kubernetes 中,三种探针(Liveness Probe、Readiness Probe 和 Startup Probe)的执行顺序如下:
-
Startup Probe(启动探针):当容器启动时,首先执行 Startup Probe。它会在容器启动后立即开始运行,并在其成功之前不会影响容器的状态。如果 Startup Probe 失败,Kubernetes 将认为容器启动失败,并可能触发容器的重启。
-
Liveness Probe(存活探针):一旦容器成功启动,并且 Startup Probe 成功,Kubernetes 开始执行 Liveness Probe。Liveness Probe 用于检测容器是否存活。如果 Liveness Probe 失败,Kubernetes 将重启容器,以尝试恢复容器的健康状态。
-
Readiness Probe(就绪探针):一旦容器成功启动,并且 Liveness Probe 成功,Kubernetes 开始执行 Readiness Probe。Readiness Probe 用于检测容器是否准备好接收流量。如果 Readiness Probe 失败,Kubernetes 将停止将流量转发到容器,直到探针恢复为成功。
通过同时配置这三种探针,可以实现更全面的容器管理和健康检查策略。Startup Probe 可以用于确保容器在启动过程中成功启动,Liveness Probe 可以用于检测容器是否存活,而 Readiness Probe 可以用于检测容器是否准备好接收流量。
每个探针可以根据容器的需要进行配置,并具有不同的检测频率、超时时间和探测逻辑。这样,Kubernetes 可以根据这些探针的结果来判断容器的健康状况,并采取相应的行动,如重启容器、停止转发流量等。
需要注意的是,配置探针时应根据应用程序的需求进行权衡和调整,以确保适当的容器管理和健康检查策略。
为什么有了livenessProbe和readnessProbe还要有StartupProbe(1.16)
Startup Probe(启动探针)在容器启动过程中起着独特的作用,与 Liveness Probe(存活探针)和 Readiness Probe(可读探针)有所不同。虽然 Liveness Probe 和 Readiness Probe 可以用于检测容器的状态和可用性,但 Startup Probe 具有以下特点:
-
启动过程中的延迟:在容器启动后,Liveness Probe 和 Readiness Probe 可能需要一定的时间才能开始执行和检测容器状态。这意味着在容器刚启动时,它们可能会返回失败的结果。Startup Probe 旨在在容器启动的早期阶段执行,以便更快地检测容器的启动状态。
-
避免误判:Liveness Probe 和 Readiness Probe 可能会因为容器启动时的瞬时问题而导致误报。例如,容器可能在启动时进行初始化或加载依赖项,这可能会导致短暂的不可用状态。通过使用 Startup Probe,可以将容器的启动过程与正常的运行状态分开,以避免误判和过早地重启容器。
-
针对特定的容器启动问题:有些应用程序在启动时可能需要进行一些特定的操作,如数据库初始化、数据加载或网络连接等。Startup Probe 可以用于检测这些特定的启动问题,并在启动失败时防止容器接收流量。一旦 Startup Probe 成功,Liveness Probe 和 Readiness Probe 将接管以持续监测容器的状态。
综上所述,Startup Probe 提供了一个独立的探针来检测容器的启动过程,并确保容器在正常运行之前成功完成启动。它与 Liveness Probe 和 Readiness Probe 相互补充,提供了更全面的容器管理和健康检查策略。
零宕机发布
pod退出流程

preStop
可以执行,
# 杀掉进程
kill `pgrep app`
然后新的容器启动后就可以直接服务了。
如果写sleep xxs,会导致不生效:
只会执行30多秒
无状态服务Deploy
用于部署无状态的服务,这个最常用的控制器。一般用于管理维护企业内部无状态的微服务,比如configserver、zuul、springboot。可以管理多个副本的Pod实现无缝迁移、自动扩容缩容、自动灾难恢复、一键回滚等功能。
部署deploy
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2020-09-19T02:41:11Z"
generation: 1
labels:
app: nginx
name: nginx
namespace: default
spec:
progressDeadlineSeconds: 600
replicas: 2 #副本数
revisionHistoryLimit: 10 # 历史记录保留的个数
selector:
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.15.2
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Deployment的更新
更改deployment的镜像并记录:
kubectl set image deploy nginx nginx=nginx:1.15.3 –record
查看更新过程:
kubectl rollout status deploy nginx
或者使用describe查看:
kubectl describe deploy nginx
更新过程中会创建新的rs,先设置新rs的副本数为1,然后将旧的rs的副本数设置为1,再将新的rs副本数设置为2,将老的rs设置为0,并保留旧的rs,方便回滚。
Deployment回滚
查看历史版本
kubectl rollout history deploy nginx
回滚到上一个版本
kubectl rollout undo deploy nginx
查看指定版本的详细信息
kubectl rollout history deploy nginx --revision=5
回滚到执行的版本
kubectl rollout undo deploy nginx --to-revision=5
Deployment扩容
kubectl scale命令:
# 扩容副本数为3
kubectl scale --replicate=3 deploy nginx
扩容和缩容没有改变spec.templates下的配置,所以不会产生新的rs。
Deployment的暂停和恢复
命令行set针对于多个地方更新会频繁触发滚动更新(edit命令修改yaml可以更直接的修改全部配置):
Deployment 暂停功能
kubectl rollout pause deployment nginx
连续set两次配置:
kubectl set image deploy nginx nginx=nginx:1.15.3 --record
kubectl set resources deploy nginx -c nginx --limits=cpu=200m,memory=128Mi --requests=cpu=10m,memory=16Mi
恢复deploy:
kubectl rollout resume deploy nginx
Deployment注意事项
- .spec.revisionHistoryLimit:设置保留RS旧的revision的个数,设置为0的话,不保留历史数据
- .spec.minReadySeconds:可选参数,指定新创建的Pod在没有任何容器崩溃的情况下视为Ready最小的秒数,默认为0,即一旦被创建就视为可用。
- 滚动更新的策略:
- .spec.strategy.type:更新deployment的方式,默认是RollingUpdate
- RollingUpdate:滚动更新,可以指定maxSurge和maxUnavailable
- maxUnavailable:指定在回滚或更新时最大不可用的Pod的数量,可选字段,默认25%,可以设置成数字或百分比,如果该值为0,那么maxSurge就不能0
- maxSurge:可以超过期望值的最大Pod数,可选字段,默认为25%,可以设置成数字或百分比,如果该值为0,那么maxUnavailable不能为0
- Recreate:重建,先删除旧的Pod,在创建新的Pod
- RollingUpdate:滚动更新,可以指定maxSurge和maxUnavailable
- .spec.strategy.type:更新deployment的方式,默认是RollingUpdate
有状态的StatefulSet
StatefulSet主要用于管理有状态应用程序的工作负载API对象。比如在生产环境中,可以部署ElasticSearch集群、MongoDB集群或者需要持久化的RabbitMQ集群、Redis集群、Kafka集群和ZooKeeper集群等。
和Deployment类似,一个StatefulSet也同样管理着基于相同容器规范的Pod。不同的是,StatefulSet为每个Pod维护了一个粘性标识。这些Pod是根据相同的规范创建的,但是不可互换,每个Pod都有一个持久的标识符,在重新调度时也会保留,一般格式为StatefulSetName-Number。
比如定义一个名字是Redis-Sentinel的StatefulSet,指定创建三个Pod,那么创建出来的Pod名字就为Redis-Sentinel-0、Redis-Sentinel-1、Redis-Sentinel-2。而StatefulSet创建的Pod一般使用Headless Service(无头服务)进行通信,和普通的Service的区别在于Headless Service没有ClusterIP,它使用的是Endpoint进行互相通信,Headless一般的格式为:
statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.local。
说明:
- statefulSetName为StatefulSet的名字;
- 0…N-1为Pod所在的序号,从0开始到N-1;
- serviceName为Headless Service的名字,创建StatefulSet时,必须指定Headless Service名称;
- namespace为服务所在的命名空间;
- .cluster.local为Cluster Domain(集群域)。
举例
-
比如在进行SpringCloud项目容器化时,Eureka的部署是比较适合用StatefulSet部署方式的,可以给每个Eureka实例创建一个唯一且固定的标识符,并且每个Eureka实例无需配置多余的Service,其余Spring Boot应用可以直接通过Eureka的Headless Service即可进行注册。
-
Eureka的statefulset的资源名称是eureka,eureka-0 eureka-1 eureka-2
-
Service:headless service,没有ClusterIP eureka-svc
-
可以直接通过pod名+svc名就可以访问到部署的实例:Eureka-0.eureka-svc.NAMESPACE_NAME eureka-1.eureka-svc …
-
-
比如用一个名为redis-ms的StatefulSet部署主从架构的Redis,第一个容器启动时,它的标识符为redis-ms-0,并且Pod内主机名也为redis-ms-0,此时就可以根据主机名来判断,当主机名为redis-ms-0的容器作为Redis的主节点,其余从节点,那么Slave连接Master主机配置就可以使用不会更改的Master的Headless Service,此时Redis从节点(Slave)配置文件如下:
port 6379 slaveof redis-ms-0.redis-ms.public-service.svc.cluster.local 6379 tcp-backlog 511 timeout 0 tcp-keepalive 0 ……其中redis-ms-0.redis-ms.public-service.svc.cluster.local是Redis Master的Headless Service,在同一命名空间下只需要写redis-ms-0.redis-ms即可,后面的public-service.svc.cluster.local可以省略。
StatefulSet注意事项
一般StatefulSet用于有以下一个或者多个需求的应用程序:
- 需要稳定的独一无二的网络标识符。
- 需要持久化数据。
- 需要有序的、优雅的部署和扩展。
- 需要有序的自动滚动更新。
StatefulSet是Kubernetes 1.9版本之前的beta资源,在1.5版本之前的任何Kubernetes版本都没有。
Pod所用的存储必须由PersistentVolume Provisioner(持久化卷配置器)根据请求配置StorageClass,或者由管理员预先配置,当然也可以不配置存储。
为了确保数据安全,删除和缩放StatefulSet不会删除与StatefulSet关联的卷,可以手动选择性地删除PVC和PV
StatefulSet目前使用Headless Service(无头服务)负责Pod的网络身份和通信,需要提前创建此服务。
删除一个StatefulSet时,不保证对Pod的终止,要在StatefulSet中实现Pod的有序和正常终止,可以在删除之前将StatefulSet的副本缩减为0。
定义一个StatefulSet资源文件
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
# 设置必须为None成为无头svc
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
# 必须要指向一个存在的svc
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15.2
ports:
- containerPort: 80
name: web

在StatefulSet中必须设置Pod选择器(.spec.selector)用来匹配其标签(.spec.template.metadata.labels)。在1.8版本之前,如果未配置该字段(.spec.selector),将被设置为默认值,在1.8版本之后,如果未指定匹配Pod Selector,则会导致StatefulSet创建错误。
当StatefulSet控制器创建Pod时,它会添加一个标签statefulset.kubernetes.io/pod-name,该标签的值为Pod的名称,用于匹配Service。
再启动一个busy-box:
cat<<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
EOF
进入busy-box解析标识符:
kubectl exec -ti busybox sh

直接将svc解析成了pod的IP,直接ping web-0.nginx也是可以ping通的。
Nslookup是一个命令行工具,用于监控网络中的DNS服务器是否能够正确实现域名解析。功能是查询DNS记录,看域名解析是否正常,网络故障时诊断网络问题,如 nslookup www.baidu.com


StatefulSet(sts)扩容缩容
- 在创建下一个pod之前,如果有任何一个pod有故障,则不会创建成功;
- 在删除时,从最后一个序号开始往前删除。
StatefulSet更新策略

updateStrategy:
rollingUpdate:
# 只更新partition大于0的,如web-0,web-1.web-2
partition: 0
type: RollingUpdate
SteatefulSet灰度发布
在一般情况下,升级服务器端应用,需要将应用源码或程序包上传到服务器,然后停止掉老版本服务,再启动新版本。但是这种简单的发布方式存在两个问题,一方面,在新版本升级过程中,服务是暂时中断的,另一方面,如果新版本有BUG,升级失败,回滚起来也非常麻烦,容易造成更长时间的服务不可用。
为了解决这些问题,人们研究出了多种发布策略:
蓝绿部署

蓝绿部署,是指同时运行两个版本的应用。
蓝绿部署的时候,并不停止掉老版本,而是直接部署一套新版本,等新版本运行起来后,再将流量切换到新版本上。
但是蓝绿部署要求在升级过程中,同时运行两套程序,对硬件的要求就是日常所需的二倍,比如日常运行时,需要10台服务器支撑业务,那么使用蓝绿部署,就需要二十台服务器。
滚动发布
滚动发布能够解决掉蓝绿部署时对硬件要求增倍的问题。
滚动升级,就是在升级过程中,并不一下子启动所有新版本,是先启动一台新版本,再停止一台老版本,然后再启动一台新版本,再停止一台老版本,直到升级完成。
滚动升级有一个问题,在开始滚动升级后,流量会直接流向已经启动起来的新版本,但是这个时候,新版本是不一定可用的,比如需要进一步的测试才能确认。那么在滚动升级期间,整个系统就处于非常不稳定的状态,如果发现了问题,也比较难以确定是新版本还是老版本造成的问题。
灰度发布(金丝雀发布)
灰度发布也叫金丝雀发布,起源是,矿井工人发现,金丝雀对瓦斯气体很敏感,矿工会在下井之前,先放一只金丝雀到井中,如果金丝雀不叫了,就代表瓦斯浓度高。

灰度发布开始后,先启动一个新版本应用,但是并不直接将流量切过来,而是测试人员对新版本进行线上测试,启动的这个新版本应用,就是金丝雀。如果没有问题,那么可以将少量的用户流量导入到新版本上,然后再对新版本做运行状态观察,收集各种运行时数据,如果此时对新旧版本做各种数据对比,就是所谓的A/B测试。
当确认新版本运行良好后,再逐步将更多的流量导入到新版本上,在此期间,还可以不断地调整新旧两个版本的运行的服务器副本数量,以使得新版本能够承受越来越大的流量压力。直到将100%的流量都切换到新版本上,最后关闭剩下的老版本服务,完成灰度发布。
如果在灰度发布过程中(灰度期)发现了新版本有问题,就应该立即将流量切回老版本上,这样,就会将负面影响控制在最小范围内。
sts灰度发布
设置partition = 2时,就只会对web-2,web-3,web-4进行更新,可以先切一部分流量到web-2,web-3,web-4看看效果,如果没有问题就可以逐步让partition变小。
先修改配置文件启动4个副本,并且设置partition=2
然后修改镜像版本为1.15.4,进行升级:
只升级了web-2,web-3 。
sts级联删除和非级联删除
- 级联删除:删除sts时同时删除pod。(默认级联删除)

- 非级联删除:删除sts时不删除pod,
--cascade=false,得到孤儿pod,此时删除pod不会被重建。
守护进程服务DaemonSet
DaemonSet:守护进程集,缩写为ds,在所有节点或者是匹配的节点上都部署一个Pod。
使用DaemonSet的场景
- 运行集群存储的daemon,比如ceph或者glusterd
- 节点的CNI网络插件,calico
- 节点日志的收集:fluentd或者是filebeat
- 节点的监控:node exporter
- 服务暴露:部署一个ingress nginx
创建一个DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: nginx
name: nginx
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.15.2
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
启动ds:
kubectl apply -f nginx_ds.yaml

修改ds部署的节点:
# 给node打标签
kubectl label node k8s-node01 k8s-node02 ds=true
# 修改yaml
spec:
nodeSelector:
ds: "true"
# 更新
kubectl apply -f nginx_ds.yaml

不符合标签的节点的pod被删除掉了。

新加入的节点只需要打上一个标签,ds就会自动创建。
DaemonSet的更新和回滚
如果使用rollingUpdate应该将maxUnavailable设置为1为好。
ds的更新策略建议使用:Ondelete
HPA自动扩缩容
Horizontal Pod Autoscaler:Pod的水平自动伸缩器。
-
观察Pod的CPU、内存使用率自动扩展或缩容Pod的数量。
-
不适用于无法缩放的对象,比如DaemonSet。
-
CPU、内存、自定义指标的扩缩容。
-
必须定义 requests参数,必须安装metrics-server,才可以进行pod占用资源的检测。
-
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability.yaml
将requests改小:
使用命令生成hpa:
查看hpa:
写一个脚本:while true;do wget -q -o http://svc >/dev/null; done查看资源占用:

Label和 Selector
Label:对k8s中各种资源进行分类、分组,添加一个具有特别属性的一个标签。
Selector:通过一个过滤的语法进行查找到对应标签的资源
定义Label
公司与xx银行有一条专属的高速光纤通道,此通道只能与192.168.7.0网段进行通信,因此只能将与xx银行通信的应用部署到192.168.7.0网段所在的节点上,此时可以对节点进行Label(即加标签):
kubectl label node k8s-node02 region=subnet7
node/k8s-node02 labeled
然后,可以通过Selector对其筛选:
kubectl get no -l region=subnet7
NAME STATUS ROLES AGE VERSION
k8s-node02 Ready <none> 3d17h v1.17.3
最后,在Deployment或其他控制器中指定将Pod部署到该节点:
containers:
......
dnsPolicy: ClusterFirst
nodeSelector:
region: subnet7
restartPolicy: Always
......
也可以用同样的方式对Service进行Label:
kubectl label svc canary-v1 -n canary-production env=canary version=v1
service/canary-v1 labeled
查看Labels:
kubectl get svc -n canary-production --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
canary-v1 ClusterIP 10.110.253.62 <none> 8080/TCP 24h env=canary,version=v1
还可以查看所有Version为v1的svc:
kubectl get svc --all-namespaces -l version=v1
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
canary-production canary-v1 ClusterIP 10.110.253.62 <none> 8080/TCP 25h
Selector条件匹配
Selector主要用于资源的匹配,只有符合条件的资源才会被调用或使用,可以使用该方式对集群中的各类资源进行分配。
假如对Selector进行条件匹配,目前已有的Label如下:
kubectl get svc --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
details ClusterIP 10.99.9.178 <none> 9080/TCP 45h app=details
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d19h component=apiserver,provider=kubernetes
nginx ClusterIP 10.106.194.137 <none> 80/TCP 2d21h app=productpage,version=v1
nginx-v2 ClusterIP 10.108.176.132 <none> 80/TCP 2d20h <none>
productpage ClusterIP 10.105.229.52 <none> 9080/TCP 45h app=productpage,tier=frontend
ratings ClusterIP 10.96.104.95 <none> 9080/TCP 45h app=ratings
reviews ClusterIP 10.102.188.143 <none> 9080/TCP 45h app=reviews
选择app为reviews或者productpage的svc:
kubectl get svc -l 'app in (details, productpage)' --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
details ClusterIP 10.99.9.178 <none> 9080/TCP 45h app=details
nginx ClusterIP 10.106.194.137 <none> 80/TCP 2d21h app=productpage,version=v1
productpage ClusterIP 10.105.229.52 <none> 9080/TCP 45h app=productpage,tier=frontend
选择app为productpage或reviews但不包括version=v1的svc:
kubectl get svc -l version!=v1,'app in (details, productpage)' --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
details ClusterIP 10.99.9.178 <none> 9080/TCP 45h app=details
productpage ClusterIP 10.105.229.52 <none> 9080/TCP 45h app=productpage,tier=frontend
选择labelkey名为app的svc:
kubectl get svc -l app --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
details ClusterIP 10.99.9.178 <none> 9080/TCP 45h app=details
nginx ClusterIP 10.106.194.137 <none> 80/TCP 2d21h app=productpage,version=v1
productpage ClusterIP 10.105.229.52 <none> 9080/TCP 45h app=productpage,tier=frontend
ratings ClusterIP 10.96.104.95 <none> 9080/TCP 45h app=ratings
reviews ClusterIP 10.102.188.143 <none> 9080/TCP 45h app=reviews
修改标签(Label),在实际使用中,Label的更改是经常发生的事情,可以使用overwrite参数修改标签。修改标签,比如将version=v1改为version=v2:
kubectl get svc -n canary-production --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
canary-v1 ClusterIP 10.110.253.62 <none> 8080/TCP 26h env=canary,version=v1
[root@k8s-master01 canary]# kubectl label svc canary-v1 -n canary-production version=v2 --overwrite
service/canary-v1 labeled
[root@k8s-master01 canary]# kubectl get svc -n canary-production --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
canary-v1 ClusterIP 10.110.253.62 <none> 8080/TCP 26h env=canary,version=v2
删除标签(Label),删除标签,比如删除version:
kubectl label svc canary-v1 -n canary-production version-
service/canary-v1 labeled
[root@k8s-master01 canary]# kubectl get svc -n canary-production --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
canary-v1 ClusterIP 10.110.253.62 <none> 8080/TCP 26h env=canary
service
- 在k8s中,每次修改pod都会重新生成一个ip,所以无法靠ip+port来直接访问pod。
- 主要用于Pod之间的通信,相对于Pod的IP它创建完成以后就是不变的资源,其他pod可以通过这个svc访问到这个svc代理的pod。
创建一个svc
deploy的nginx pod,标签为:app = nginx
创建svc代理pod:
通过svc的clusterIP可以直接访问nginx:
在其他容器中通过svc的name(http://svc_name)也可以访问,如果不在同一个名称空间下需要用:http://svc_name.ns,如http://nginx_svc.default来访问:
应用之间相互调用不建议使用跨ns的调用,如果访问公共redis或kafka可以使用跨ns调用。
svc创建后会产生一个同名的endpoints,可以get ep查看:
删除pod,新启动的pod的ip会自动被添加到ep,所以服务之间调用要使用svc的名称调用。
使用svc代理k8s外部服务

创建一个代理外部的svc:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-external
labels:
app: nginx-svc-external
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
name: http
type: ClusterIP
创建代理外部的svc是不会创建同名endpoints的
手动创建一个代理百度的ep:
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: nginx-svc-external
# 名称必须和svc相同,否则不会自动建立关联
name: nginx-svc-external
namespace: default
subsets:
- addresses:
- ip: 110.242.68.66
ports:
- name: http
port: 80
protocol: TCP

curl访问百度curl baidu.com -I:
curl一下svc,结果是相同的:
如果百度的地址变更了,只需要编辑ep.yaml即可,而且常用ExternalName,而不是ClusterIP
svc代理外部域名
代理百度:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-externalname
labels:
app: nginx-svc-externalname
spec:
type: ExternalName
externalName: www.baidu.com
进入busybox访问svc:

svc常用类型
-
ClusterIP:在集群内部使用的,默认类型。
-
NodePort:在每个宿主机上暴露一个随机端口,30000-32767,–service-node-port-range,集群外部可通过节点ip地址和NodePort的端口号访问到集群pod的服务。

-
ExternalName:反代到指定的域名上。
-
LoadBalancer:使用云服务商提供的IP地址。成本太高。
注意事项:
- 没有Selector的service,不会自动创建EndPoints。
- NodePort的默认端口可以修改


创建一个NodePort:
外部就可以通过31000访问到pod的80端口。
原理是:kube-proxy在node节点机器上开放了对应的port,使用netstat -lntp来查看:

k8s部署的mysql,redis集群一般不会对外开放,但可以通过临时性创建一个NodePort访问(不建议),项目对外一般不会直接开放端口,而是使用ingress+域名来访问。
ingress(待续)
当使用nodePort暴露pod,然后在前面再加一个nginx反向代理,也可以实现域名访问。
- nodePod性能问题。
- 成百上千个nodePort端口不好维护。
- 基于已有的k8s平台,不推荐结合传统的部署方式。
Ingress也是k8s的一种资源类型,是Kubernetes集群中服务的入口,可以提供负载均衡、SSL终止和基于域名的虚拟主机,用于实现域名的方式访问k8s内部应用,实现方式有:Treafik、Nginx、HAProxy、Istio。
ingress使用
配置文档:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/
创建一个nginx
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: example
annotations:
kubernates.io/ingress.class: "nginx"
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /
backend:
serviceName: nginx-svc
servicePort: 80
查看ing:
kubectl get ing

在外部(C:\Windows\System32\drivers\etc\hosts)配置dns
访问域名:
ConfigMap
-
一般用ConfigMap去管理一些配置文件、或者一些大量的环境变量信息。
-
ConfigMap将配置和Pod分开,有一个nginx,nginx.conf -> configmap,使nginx 更易于配置文件的更改和管理。
-
Secret:Secret更倾向于存储和共享敏感、加密的配置信息。
从目录创建ConfigMap
执行官网的例子:
# 将示例文件下载到 `configure-pod-container/configmap/` 目录
wget https://kubernetes.io/examples/configmap/game.properties -O ./game.properties
wget https://kubernetes.io/examples/configmap/ui.properties -O ./ui.properties
# 创建 ConfigMap
kubectl create configmap game-config --from-file=./
查看:kubectl describe configmaps game-config
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
或者查看yaml:kubectl get configmaps game-config -o yaml
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2022-02-18T18:52:05Z
name: game-config
namespace: default
resourceVersion: "516"
uid: b4952dc3-d670-11e5-8cd0-68f728db1985
data:
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
基于文件创建 ConfigMap
使用多个--from-file:
kubectl create configmap game-config-2 --from-file=configure-pod-container/configmap/game.properties --from-file=configure-pod-container/configmap/ui.properties
基于nginx.conf创建cm:

将 ConfigMap 中的所有键值对配置为容器环境变量
-
创建一个包含多个键值对的 ConfigMap:
apiVersion: v1 kind: ConfigMap metadata: name: special-config namespace: default data: SPECIAL_LEVEL: very SPECIAL_TYPE: charm -
运行一个busybox:
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: test-container image: registry.k8s.io/busybox command: [ "/bin/sh", "-c", "env" ] # 常用的形式 envFrom: - configMapRef: name: special-config restartPolicy: Never -
由于command是输出环境变量,所以需要logs查看:

将 ConfigMap 数据添加到一个卷中
基于两个文件创建 ConfigMap:
kubectl create configmap nginx-conf-env --from-file=./nginx.conf --from-file=./dj_env.conf
将nginx.conf挂载到busybox中作为配置文件,dj_env.conf挂载到环境变量:
apiVersion: v1
kind: Pod
metadata:
name: mybusybox
spec:
containers:
- name: mybusybox
image: busybox
command: [ "/bin/sh", "-c", "sleep 36000"]
envFrom:
volumeMounts:
- name: nginx
mountPath: /etc/config
env:
- name: myenv
valueFrom:
configMapKeyRef:
name: nginx-conf-env
# env的key
key: dj_env.conf
volumes:
# 此处是config文件
- name: nginx
configMap:
# 提供包含要添加到容器中的文件的 ConfigMap 的名称
name: nginx-conf-env
items:
# nginx的key
- key: nginx.conf
path: nginx.conf
restartPolicy: Always
进入容器查看conf挂载情况:

cm的name被作为文件名,data被当作文件内容:
subPath解决目录覆盖的问题
如果直接将nginx.conf生成的configMap挂载到deploy中,会导致目录被覆盖:

因此,nginxpod不会启动会导致一直重启,所以需要删除探针和覆盖命令:
查看/etc/nginx目录:
修改配置添加subPath,以文件形式挂载nginx.conf,key就是cm的data中的key:
Secret
- 用来保存敏感信息的,比如密码、令牌或者Key,Redis、MySQL密码。
- 特殊字符(例如 $、\、*、= 和 !)会被 Shell 解释,因此需要转义。
- 在大多数 Shell 中,对密码进行转义的最简单方式是用单引号(')将其括起来。 例如,如果实际密码是 S!B*d$zDsb,则应通过以下方式执行命令:
kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password='S!B\*d$zDsb='
使用文件或key-val创建secret
文件:
kubectl create secret generic db-user-pass \
--from-file=./username.txt \
--from-file=./password.txt
key-val
kubectl create secret generic db-user-pass \
--from-literal=username=admin \
--from-literal=password='S!B\*d$zDsb='
创建出来的secret格式是相同的:
secret使用
ImagePullSecret:Pod拉取私有镜像仓库时使用的账户密码,里面的账户信息,会传递给kubelet,然后kubelet就可以拉取有密码的仓库里面的镜像。
kubectl create secret docker-registry myregistrykey --docker-server=DUMMY_SERVER \
--docker-username=DUMMY_USERNAME --docker-password=DUMMY_DOCKER_PASSWORD \
--docker-email=DUMMY_DOCKER_EMAIL
比如阿里云:sudo docker login --username=爱吃饺子的西瓜 registry.cn-hangzhou.aliyuncs.com
kubectl create secret docker-registry myregistrykey --docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=爱吃饺子的西瓜 --docker-password=*********************** \
--docker-email=********************
设置拉取镜像的仓库:
kubectl edit serviceaccount/default
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2021-07-07T22:02:39Z
name: default
namespace: default
uid: 052fb0f4-3d50-11e5-b066-42010af0d7b6
imagePullSecrets:
- name: myregistrykey
现在,在当前名字空间中创建新 Pod 并使用默认 ServiceAccount 时, 新 Pod 的 spec.imagePullSecrets 会被自动设置。
kubectl run nginx --image=nginx --restart=Never
kubectl get pod nginx -o=jsonpath='{.spec.imagePullSecrets[0].name}{"\n"}'
输出为:
myregistrykey
volumes

helm
安装helm
- https://github.com/helm/helm/releases选择合适的版本
- 解压,如
tar -zxvf helm-v3.0.0-linux-amd64.tar.gz - 移动到需要的目录中,
mv linux-amd64/helm /usr/local/bin/helm
什么是helm



helm目录结构
通过helm create chart_name创建一个chart:
templates/ 目录包括了模板文件。当Helm评估chart时,会通过模板渲染引擎将所有文件发送到templates/目录中。 然后收集模板的结果并发送给Kubernetes。
values.yaml 文件也导入到了模板。这个文件包含了chart的 默认值 。这些值会在用户执行helm install 或 helm upgrade时被覆盖。
Chart.yaml 文件包含了该chart的描述。你可以从模板中访问它。charts/目录 可以 包含其他的chart(称之为 子chart)。 指南稍后我们会看到当涉及模板渲染时这些是如何工作的。
快速查看 mychart/templates/
如果你看看 mychart/templates/ 目录,会注意到一些文件已经存在了:
- NOTES.txt: chart的"帮助文本"。这会在你的用户执行helm install时展示给他们。
- deployment.yaml: 创建Kubernetes 工作负载的基本清单
- service.yaml: 为你的工作负载创建一个 service终端基本清单。
- _helpers.tpl: 放置可以通过chart复用的模板辅助对象
然后要做的是… 把它们全部删掉! 这样就可以从头开始学习我们的教程。在开始时会创造自己的NOTES.txt和_helpers.tpl。
$ rm -rf mychart/templates/*
编制生产环境级别的chart时,有这些chart的基础版本会很有用。
创建一个configmap
-
创建一个chart:
helm create fuck -
删除所有templates下的模板并且新建一个configmap.yaml:
apiVersion: v1 kind: ConfigMap metadata: name: mychart-configmap data: myvalue: "hello world" -
创建configmap,执行
helm install myconfigmaprelease ./fuck -
执行
helm list查看:
-
查看创建后的详细信息:
helm manifest myconfigmaprelease,helm get manifest 命令后跟一个发布名称(full-coral)然后打印出了所有已经上传到server的Kubernetes资源。 每个文件以—开头表示YAML文件的开头,然后是自动生成的注释行,表示哪个模板文件生成了这个YAML文档。
-
删除实例,
helm uninstall myconfigmaprelease
添加一个模板调用
将name:硬编码到一个资源中不是很好的方式。名称应该是唯一的。因此我们可能希望通过插入发布名称来生成名称字段。
提示: 由于DNS系统的限制,name:字段长度限制为63个字符。因此发布名称限制为53个字符。 Kubernetes 1.3及更早版本限制为24个字符 (名称长度是14个字符)。
在Kubernetes中,每个资源(如Pod、Service、Deployment等)都有一个名称(name)字段,用于唯一标识该资源。根据DNS(Domain Name System)系统的限制,域名的总长度不能超过255个字符,其中包括域名标签(label)和域名分隔符(".")。
在Kubernetes中,资源的名称会作为域名的一部分,以便在集群中进行服务发现和访问。由于DNS系统的限制,Kubernetes对资源名称的长度进行了限制。根据官方文档中的描述,Kubernetes 1.3及更早版本限制资源名称的长度为24个字符,其中名称的长度限制为14个字符。这是为了确保资源名称与域名的总长度不超过255个字符。
随着Kubernetes的发展和版本升级,对资源名称长度的限制也发生了变化。从Kubernetes 1.4版本开始,资源名称的长度限制增加到63个字符,这是由于DNS系统的域名长度限制。然而,出于兼容性考虑,发布名称(Release Name)的长度限制仍保持为53个字符,以确保与之前版本的兼容性。
因此,根据Kubernetes版本和发布名称的不同,资源名称的长度限制也会有所不同。这些限制是为了确保在集群中进行资源访问和服务发现时,域名的长度不超过DNS系统的限制。
对应改变一下configmap.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
当你想测试模板渲染的内容但又不想安装任何实际应用时,可以使用helm install --debug --dry-run goodly-guppy ./mychart。这样不会安装应用(chart)到你的kubenetes集群中,只会渲染模板内容到控制台(用于测试)。渲染后的模板如下:
$ helm install --debug --dry-run goodly-guppy ./mychart
install.go:149: [debug] Original chart version: ""
install.go:166: [debug] CHART PATH: /Users/ninja/mychart
NAME: goodly-guppy
LAST DEPLOYED: Thu Dec 26 17:24:13 2019
NAMESPACE: default
STATUS: pending-install
REVISION: 1
TEST SUITE: None
USER-SUPPLIED VALUES:
{}
COMPUTED VALUES:
affinity: {}
fullnameOverride: ""
image:
pullPolicy: IfNotPresent
repository: nginx
imagePullSecrets: []
ingress:
annotations: {}
enabled: false
hosts:
- host: chart-example.local
paths: []
tls: []
nameOverride: ""
nodeSelector: {}
podSecurityContext: {}
replicaCount: 1
resources: {}
securityContext: {}
service:
port: 80
type: ClusterIP
serviceAccount:
create: true
name: null
tolerations: []
HOOKS:
MANIFEST:
---
# Source: mychart/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: goodly-guppy-configmap
data:
myvalue: "Hello World"
内置对象
Release对象描述了版本发布本身
- Release.Name: release名称
- Release.Namespace: 版本中包含的命名空间(如果manifest没有覆盖的话)
- Release.IsUpgrade: 如果当前操作是升级或回滚的话,该值将被设置为true
- Release.IsInstall: 如果当前操作是安装的话,该值将被设置为true
- Release.Revision: 此次修订的版本号,安装时是1,每次升级或回滚都会自增
- Release.Service: service返回当前模板的服务名称。这个值总是
Helm
定义config.yaml文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
namespace: {{ .Release.Namespace}}
data:
isupgrade: "{{ .Release.IsUpgrade }}"
isinstall: "{{ .Release.IsInstall }}"
revision: "{{ .Release.Revision }}"
service: "{{ .Release.Service}}" # helm
执行:helm install myconfigmap ./myconfigmap --debug --dry-run命令

Values对象
Value.yaml文件内容,用{{ .Value.xxx}} 来获取Value.yaml中的内容
Chart对象
Chart.yaml文件内容,用{{ .Chart.xxx }} 来获取Chart.yaml中的内容
Files对象
Helm 提供了通过.Files对象访问文件的方法。有些事情需要注意:
- 可以添加额外的文件到chart中。虽然这些文件会被绑定。但是要小心,由于Kubernetes对象的限制,Chart必须小于1M。
- 通常处于安全考虑,一些文件无法通过.Files对象访问:
- 无法访问templates/中的文件
- 无法访问使用.helmignore排除的文件
- helm应用 subchart之外的文件,包括父级中的,不能被访问的
Capabilities对象
提供关于Kubernetes集群支持功能的信息
Capabilities.APIVersions 是一个版本列表
Capabilities.APIVersions.Has $version 说明集群中的版本 (比如,batch/v1) 或是资源 (比如, apps/v1/Deployment) 是否可用
Capabilities.KubeVersion 和Capabilities.KubeVersion.Version 是Kubernetes的版本号
Capabilities.KubeVersion.Major Kubernetes的主版本
Capabilities.KubeVersion.Minor Kubernetes的次版本
Capabilities.HelmVersion 包含Helm版本详细信息的对象,和 helm version 的输出一致
Capabilities.HelmVersion.Version 是当前Helm语义格式的版本
Capabilities.HelmVersion.GitCommit Helm的git sha1值
Capabilities.HelmVersion.GitTreeState 是Helm git树的状态
Capabilities.HelmVersion.GoVersion 是使用的Go编译器版本
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
namespace: {{ .Release.Namespace}}
data:
isupgrade: "{{ .Release.IsUpgrade }}"
isinstall: "{{ .Release.IsInstall }}"
revision: "{{ .Release.Revision }}"
service: "{{ .Release.Service}}" # helm
APIVersions: "{{ .Capabilities.APIVersions }}"
K8SVersion: "{{ .Capabilities.KubeVersion.Version }}"
K8SMajor: "{{ .Capabilities.KubeVersion.Major }}"
K8SMinor: "{{ .Capabilities.KubeVersion.Minor }}"

Template对象
包含当前被执行的当前模板信息
Template.Name: 当前模板的命名空间文件路径 (e.g. mychart/templates/mytemplate.yaml)
Template.BasePath: 当前chart模板目录的路径 (e.g. mychart/templates)
常用命令

Helm 仓库
helm添加chart仓库和查看仓库,类似yum仓库和docker仓库
添加helm仓库:helm repo add
添加chart仓库,语法:
helm repo add [NAME] [URL] [flags]

更新helm仓库:helm repo update
从chart仓库中更新本地可用chart的信息,更新从各自chart仓库中获取的有关chart的最新信息。信息会缓存在本地,被诸如’helm search’等命令使用。
可以指定需要更新的仓库列表。 $ helm repo update <repo_name> … 使用 ‘helm repo update’ 更新所有仓库。
删除helm仓库:helm repo remove
删除一个或多个仓库
helm repo remove [REPO1 [REPO2 ...]] [flags]
chart
创建chart包:helm create
使用给定名称创建新的chart
该命令创建chart目录和chart用到的公共文件目录
比如helm create foo会创建一个目录结构看起来像这样:
foo/
├── .helmignore # Contains patterns to ignore when packaging Helm charts.
├── Chart.yaml # Information about your chart
├── values.yaml # The default values for your templates
├── charts/ # Charts that this chart depends on
└── templates/ # The template files
└── tests/ # The test files
helm create使用一个目录作为参数。如果给定目录路径不存在,Helm会自动创建。如果给定目录存在且非空,冲突文件会被覆盖,其他文件会被保留。
搜索chart仓库:helm search repo
搜索会读取系统上配置的所有仓库,并查找匹配。搜索这些仓库会使用存储在系统中的元数据。
它会展示找到最新稳定版本的chart。如果指定了–devel参数,输出会包括预发布版本。
示例:
# Search for stable release versions matching the keyword "nginx"
$ helm search repo nginx
# Search for release versions matching the keyword "nginx", including pre-release versions
$ helm search repo nginx --devel
# Search for the latest stable release for nginx-ingress with a major version of 1
$ helm search repo nginx-ingress --version ^1.0.0
仓库使用helm repo命令管理。
helm search repo [keyword] [flags]
展示chart:helm show chart
显示chart定义
该命令检查chart(目录、文件或URL)并显示Chart.yaml文件的内容
helm show chart [CHART] [flags]

拉取chart包:helm pull
download a chart from a repository and (optionally) unpack it in local directory
从包仓库中检索包并下载到本地。
对于要获取检查,修改或重新打包的包很有用,还可以用于在不安装chart的情况下对chart进行加密验证。
下载chart之后有解压的选项,会为chart创建一个目录并解压到这个目录中。
如果指定了--verify参数,请求的chart必须有出处文件,且必须通过验证。任意部分的失败都会导致错误,且chart不会在本地保存。
helm pull [chart URL | repo/chartname] [...] [flags]


install/upgrade/rollback



部署自定义的应用

定义nginx模板


安装部署release实例

升级版本


回滚


卸载release

常用helm仓库
- helm官方:https://hub.helm.sh/
- 开源社镜像(开源社是由中国支持开源的企业,社区及个人所组织的一个开源联盟,旨在推广开源。):http://mirror.kaiyuanshe.cn/kubernetes/charts/
- 国内helm仓库:https://hub.grapps.cn/marketplace
- BitNami是一个开源项目,该项目产生的开源软件包括安装 Web应用程序和解决方案堆栈,以及虚拟设备https://bitnami.com/stacks
minikube搭建
Minikube 是一个用于在本地环境快速搭建和管理 Kubernetes 集群的工具。它允许开发者在自己的计算机上运行一个单节点的 Kubernetes 集群,从而无需依赖于远程 Kubernetes 集群或云服务。Minikube 特别适用于学习、开发和测试 Kubernetes 应用程序,因为它提供了一个简单的方式来运行 Kubernetes。
Minikube 的主要特点:
-
轻量级:Minikube 是一个相对轻量级的工具,适合在本地机器上运行单节点 Kubernetes 集群。它通常用于开发、测试和实验,而不是生产环境。
-
支持多种驱动程序:Minikube 支持多种驱动程序来创建 Kubernetes 集群,例如:
- Docker:使用 Docker 容器运行 Kubernetes 集群。
- VirtualBox:使用 VirtualBox 创建虚拟机。
- VMware Fusion / vSphere:在 VMware 环境中运行 Kubernetes 集群。
- None:使用本机操作系统运行 Kubernetes 集群,通常适用于 Linux 系统。
-
简化的配置:Minikube 提供了简单的命令行界面(CLI),通过少量配置便可启动集群。这使得在本地开发和学习 Kubernetes 变得非常容易。
-
快速部署:Minikube 通过预先配置的镜像和自动化脚本,能够快速部署并启动一个完整的 Kubernetes 集群。
-
支持多种 Kubernetes 版本:Minikube 允许你选择和安装不同版本的 Kubernetes,方便开发者进行版本测试。
-
内置的 Kubernetes 工具:Minikube 为 Kubernetes 集群安装了必要的工具,如
kubectl,使得管理集群和应用程序变得更加便捷。
搭建流程
-
拉取镜像:dokcer pull
registry.cn-hangzhou.aliyuncs.com/google_containers/kicbase:v0.0.44 -
先执行一遍:
minikube delete ;minikube start --force --base-image='registry.cn-hangzhou.aliyuncs.com/google_containers/kicbase:v0.0.44' --image-mirror-country='cn' --kubernetes-version=v1.28.0这条命令会报错,但我们要的是程序创建好的缓存!
-
进入上图的缓存中,手动下载k8s需要的组件并且添加权限(选择你需要的版本):
wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/kubeadm wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/kubelet wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/kubectl wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/api-server wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/controller-manager wget https://dl.k8s.io/release/v1.26.15/bin/linux/amd64/scheduler
-
再次执行:
minikube delete ;minikube start --force --base-image='registry.cn-hangzhou.aliyuncs.com/google_containers/kicbase:v0.0.44' --image-mirror-country='cn' --kubernetes-version=v1.28.0 -
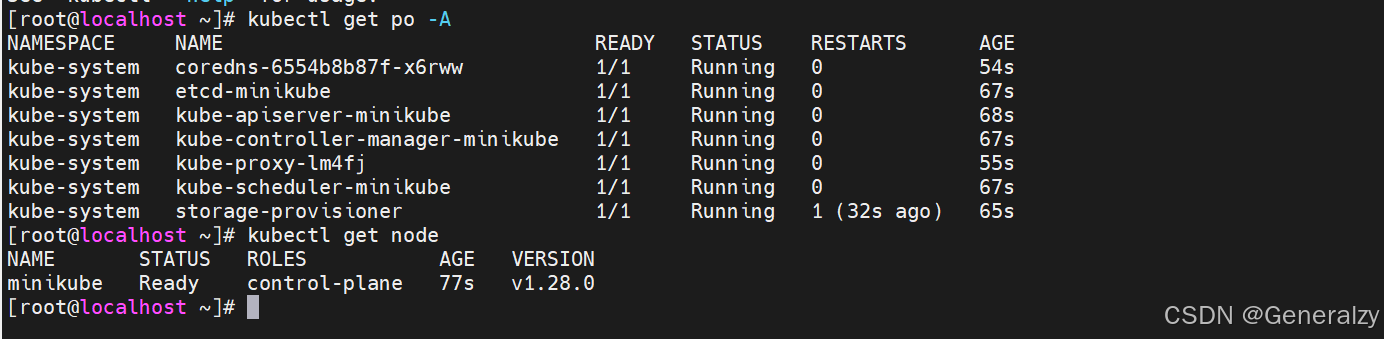
然后就可以使用kubectl去查看node和pod了:
-
吐槽:国内真的是一言难尽,docker镜像——禁了,k8s镜像——禁了,github——禁了,minikube设置了多种防止网络原因导致部署失败的手段,先docker再k8s再github最后httpsl拉取国外网站的,全都禁了!!! 日本和印度要学习IT技术,环境搭建可能只需要1分钟,根本不需要掌握国内这些乱七八糟的东西,唉,what can i say????
Q&A
k8s为什么选用etcd做kv存储,而不是redis?
Kubernetes(简称k8s)选择使用etcd作为其默认的键值存储(KV存储)的原因有以下几点:
-
Consistency guarantees: 在分布式系统中,保证一致性是非常重要的。etcd是一个分布式的一致性存储,能够提供强一致性保证,确保所有节点的视图都是相同的。而Redis虽然支持主从复制和哨兵机制,但它不支持多主同步,并且不保证强一致性,因此不太适合用于Kubernetes这样对一致性要求很高的系统。
-
Performance and scalability: Kubernetes需要一个高性能、高可扩展性的存储系统来存储其状态信息,etcd采用了基于Raft协议的分布式一致性算法,能够提供高可用性和高可扩展性。而Redis虽然也具有高性能和可扩展性,但不如etcd在多节点分布式场景下的表现。
-
Open source and community support: etcd是一个开源项目,与Kubernetes一样,也由CNCF(云原生计算基金会)维护。这意味着etcd拥有一个庞大的社区支持,能够吸引更多的开发者为其贡献代码和提供支持。
综上所述,etcd比Redis更适合用于Kubernetes的KV存储,因为它提供了强一致性保证、高性能和可扩展性,并拥有一个庞大的开源社区支持。
为什么说"redis不保证强一致性"?
Redis是一个内存中的键值存储系统,其在默认情况下提供的是最终一致性(Eventual Consistency),而不是强一致性(Strong Consistency)。最终一致性指的是在一段时间内,系统中的不同节点可能会拥有不同的数据视图,但在一定时间后,所有节点最终会达成一致。而强一致性则保证系统在任何时刻的任何节点的数据视图都是相同的。
Redis提供的主从复制和哨兵机制可以提高系统的可用性和容错能力,但是这些机制并不能保证数据的强一致性。当主节点出现故障时,哨兵会自动将从节点中的某一个节点升级为主节点,但在这个过程中,可能会出现数据丢失或数据不一致的情况,因为新的主节点可能没有完全复制之前主节点的数据,或者有些客户端可能会在主从切换的过程中访问旧的主节点,导致数据不一致。
因此,Redis在设计时并不是一个强一致性的存储系统,而是更注重性能和可扩展性的最终一致性存储系统。在分布式系统中,强一致性是非常重要的,因为它能够保证所有节点的数据视图都是一致的,避免了数据不一致和错误。在一些强一致性要求比较高的场景下,如分布式事务、分布式锁等场景,Redis可能并不是最合适的选择。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)