Flink-1.17.0(Standalone)集群安装-大数据学习系列(四)
链接: https://pan.baidu.com/s/1-GAeyyDOPjhsWhIp_VV7yg?链接: https://pan.baidu.com/s/1X_P-Q8O_eLADmEOJ438u5Q?切换到k8s-node1、k8s-node2 验证是否安装成功。切换到k8s-node1机器上操作(分发环境)2.1 在集群(各机器上都执行!2.1 切换到k8s-master执行。2.2 切
前置:集群规划
| 机器信息 | Hostname | k8s-master | k8s-node1 | k8s-node2 |
| 外网IP | 106.15.186.55 | 139.196.15.28 | 47.101.63.122 | |
| 内网IP | 172.25.73.65 | 172.25.73.64 | 172.25.73.66 | |
| master | ||||
| slave1 | slave2 | slave3 |
step1 安装前准备
- 安装Scala
从官网(The Scala Programming Language)下载 Scala版本
链接: https://pan.baidu.com/s/1-GAeyyDOPjhsWhIp_VV7yg?pwd=3fws 提取码: 3fws
2.1 在集群(各机器上都执行!!!)
#创建安装目录
mkdir -p /home/install/scala
mkdir -p /home/module/scala
#最终安装目录为/home/module/scala/scala-2.12.17/
#向 /etc/profile 文件追加如下内容
echo "export SCALA_HOME=/home/module/scala/scala-2.12.17" >> /etc/profile
echo "export PATH=:\$PATH:\${SCALA_HOME}/bin:\${SCALA_HOME}/sbin" >> /etc/profile
#使得配置文件生效
source /etc/profile
2.2 切换到k8s-node1机器上操作(分发环境)
cd /home/install/scala
#上传 scala-2.12.17.tgz
#解压压缩包到 安装目录
tar -xvf /home/install/scala/scala-2.12.17.tgz -C /home/module/scala/
#测试是否安装成功
scala -version
#最终安装目录为/home/module/scala/scala-2.12.17/ 分发到各机器目录
#复制到k8s-node1
scp -r /home/module/scala/ root@k8s-node1:/home/module/scala/
#复制到k8s-node2
scp -r /home/module/scala/ root@k8s-node2:/home/module/scala/
2.3 切换到k8s-node1、k8s-node2 验证是否安装成功
#测试是否安装成功
scala -version
step2 安装Flink环境
1.下载Flink安装包
可以去官网下载 Apache Flink® — Stateful Computations over Data Streams | Apache Flink
flink-1.17.0-bin-scala_2.12.tgz 、 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
链接: https://pan.baidu.com/s/1X_P-Q8O_eLADmEOJ438u5Q?pwd=ugwu 提取码: ugwu
- 创建Flink安装目录并解压
2.1 切换到k8s-master执行
#创建安装目录
mkdir -p /home/install/flink
mkdir -p /home/module/flink
#上传 flink-1.17.0-bin-scala_2.12.tgz
#上传 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
#进入安装目录
cd /home/install/flink
#解压压缩包 最终的安装目录为 /home/module/flink/flink-1.17.0
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /home/module/flink
#copy flink-shaded-hadoop-2-uber-2.8.3-10.0.jar 到安装目录lib中 如果不做这步 与hadoop有关的操作将会错误
cp /home/install/flink/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar /home/module/flink/flink-1.17.0/lib
2.2 切换到k8s-node1执行
#创建安装目录
mkdir -p /home/install/flink
mkdir -p /home/module/flink
2.3 切换到k8s-node2执行
#创建安装目录
mkdir -p /home/install/flink
mkdir -p /home/module/flink
- 修改配置文件
切换到k8s-master执行
3.1 flink-conf.yaml
#进入flink配置文件目录
cd /home/module/flink/flink-1.17.0
#给模版文件做个备份
mv flink-conf.yaml flink-conf.yaml.bak
cat > flink-conf.yaml << EOF
#指定集群主节点 可用机器名或者IP地址
jobmanager.rpc.address: k8s-master
#JobManager的RPC访问端口,默认为6123
jobmanager.rpc.port: 6123
#JobManager JVM的堆内存大小,默认1024MB
jobmanager.heap.size: 2048m
#TaskManager JVM的堆内存大小,默认1024MB
taskmanager.heap.size: 4096m
#每个TaskManager提供的Task Slot数量(默认为1),Task Slot数量代表TaskManager的最大并行度,建议设置成cpu的核心数
taskmanager.numberOfTaskSlots: 2
#默认是false。指定Flink当启动时,是否一次性分配所有管理的内存
taskmanager.memory.preallocate: false
#系统级别的默认并行度(默认为1)
parallelism.default: 1
#jobmanager端口 此处要注意端口冲突 netstat -anp |grep 端口号检查
jobmanager.web.port: 8081
#配置每个taskmanager 生成的临时文件夹
taskmanager.tmp.dirs: /home/module/flink/tmp
#页面提交
web.submit.enable: true
EOF
3.2 masters
#进入flink的配置文件
cd /home/module/flink/flink-1.17.0/conf
#创建 master 文件
cat > masters << EOF
k8s-master:8081
EOF
3.3 workers
workers文件必须包含所有需要启动的TaskManager节点的主机名,且每个主机名占一行
#进入flink的配置文件
cd /home/module/flink/flink-1.17.0/conf
#创建 workers 文件
cat > workers << EOF
k8s-master
k8s-node1
k8s-node2
EOF
- 分发文件
切换到k8s-master执行
#复制到k8s-node1
scp -r /home/module/flink/flink-1.17.0 root@k8s-node1:/home/module/flink/flink-1.17.0
#复制到k8s-node2
scp -r /home/module/flink/flink-1.17.0 root@k8s-node2:/home/module/flink/flink-1.17.0
- 启动flink集群验证
#启动集群
/home/module/flink/flink-1.17.0/bin/start-cluster.sh
#关闭集群
#/home/module/flink/flink-1.17.0/bin/stop-cluster.sh
#查看进程
Jps -m
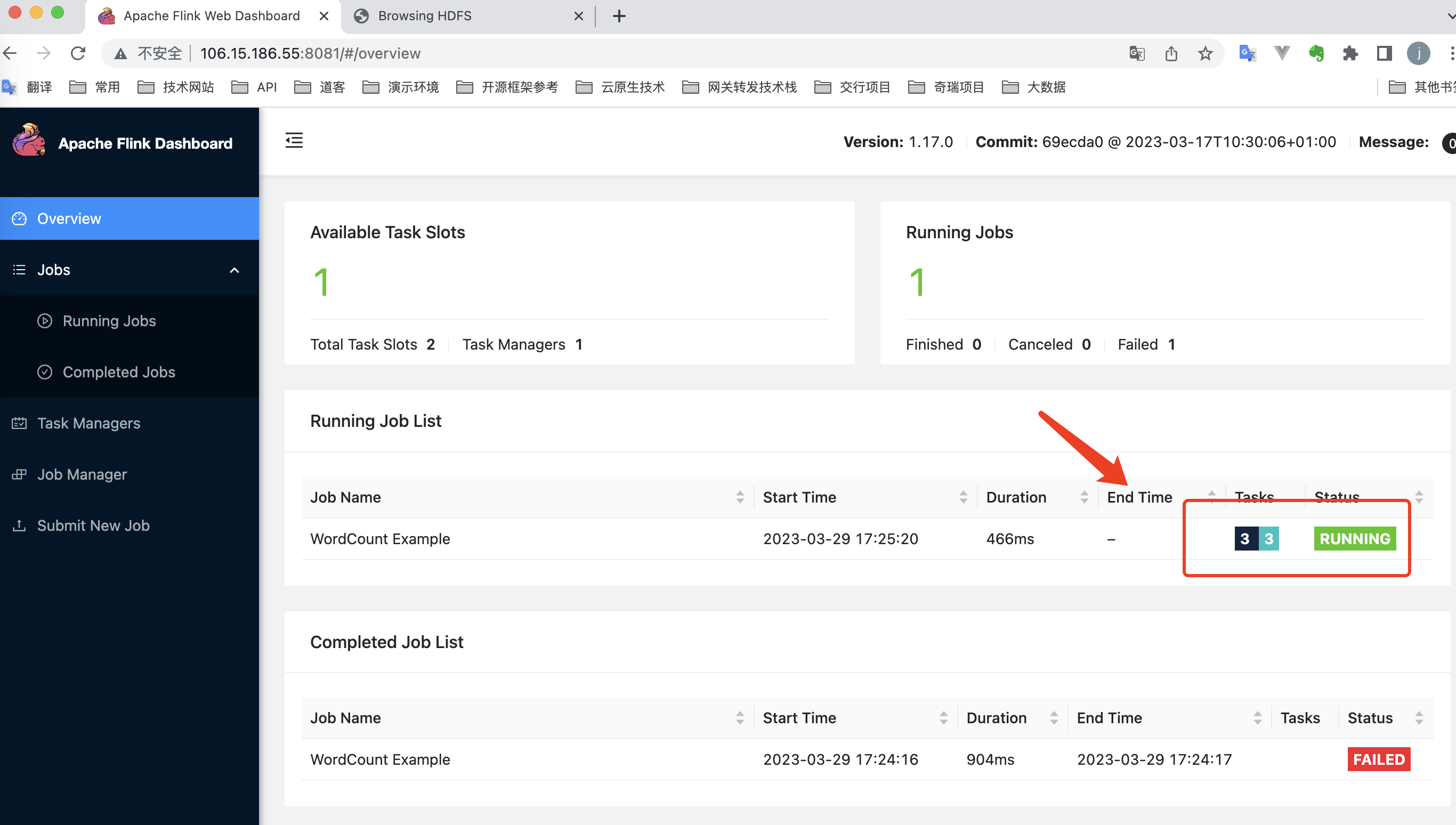
step3 Flink UI 环境验证
|
|

step4 Flink 任务执行验证
4.1 向hdfs上传文件
#创建用于test的文件夹 并进入
mkdir -p /home/test/flink
cd /home/test/flink
#创建计数用的文本
cat > wordcount.txt << EOF
Any kind of data is produced as a stream of events. Credit card transactions, sensor measurements, machine logs, or user interactions on a website or mobile application, all of these data are generated as a stream.
Data can be processed as unbounded or bounded streams.
Unbounded streams have a start but no defined end. They do not terminate and provide data as it is generated. Unbounded streams must be continuously processed, i.e., events must be promptly handled after they have been ingested. It is not possible to wait for all input data to arrive because the input is unbounded and will not be complete at any point in time. Processing unbounded data often requires that events are ingested in a specific order, such as the order in which events occurred, to be able to reason about result completeness.
Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations. Ordered ingestion is not required to process bounded streams because a bounded data set can always be sorted. Processing of bounded streams is also known as batch processing.
EOF
#在hdfs上创建测试目录
hadoop fs -mkdir -p /mytest/input
hadoop fs -put /home/test/flink/wordcount.txt /mytest/input
|
|
| 可以看到wordcount.txt 已经在HDFS上了 |

#进入flink的执行目录
cd /home/module/flink/flink-1.17.0/bin
#执行测试任务
./flink run /home/module/flink/flink-1.17.0/examples/batch/WordCount.jar --input hdfs://k8s-master:8020/mytest/input/wordcount.txt --output hdfs://k8s-master:8020/mytest/output
#获取结果
cd /home/test/flink
hadoop fs -get hdfs://k8s-master:8020/mytest/output
cat output
|
|
|
|


至此测试成功
错误解决:
1.内存分配过小导致的错误
jobmanager.heap.size 建议大于2G
taskmanager.heap.size 建议大于4G
否则内存过小导致启动报错:
INFO [] - 'taskmanager.memory.flink.size' is not specified, use the configured deprecated task manager heap value (1024 bytes) for it.
INFO [] - The derived from fraction network memory (102 bytes) is less than its min value 64.000mb (67108864 bytes), min value will be used instead
Exception in thread "main" org.apache.flink.configuration.IllegalConfigurationException: TaskManager memory configuration failed: Sum of configured Framework Heap Memory (128.000mb (134217728 bytes)), Framework Off-Heap Memory (128.000mb (134217728 bytes)), Task Off-Heap Memory (0 bytes), Managed Memory (409 bytes) and Network Memory (64.000mb (67108864 bytes)) exceed configured Total Flink Memory (1024 bytes).
at org.apache.flink.runtime.clusterframework.TaskExecutorProcessUtils.processSpecFromConfig(TaskExecutorProcessUtils.java:166)
at org.apache.flink.runtime.util.bash.BashJavaUtils.getTmResourceParams(BashJavaUtils.java:85)
at org.apache.flink.runtime.util.bash.BashJavaUtils.runCommand(BashJavaUtils.java:67)
at org.apache.flink.runtime.util.bash.BashJavaUtils.main(BashJavaUtils.java:56)
Caused by: org.apache.flink.configuration.IllegalConfigurationException: Sum of configured Framework Heap Memory (128.000mb (134217728 bytes)), Framework Off-Heap Memory (128.000mb (134217728 bytes)), Task Off-Heap Memory (0 bytes), Managed Memory (409 bytes) and Network Memory (64.000mb (67108864 bytes)) exceed configured Total Flink Memory (1024 bytes).
at org.apache.flink.runtime.util.config.memory.taskmanager.TaskExecutorFlinkMemoryUtils.deriveFromTotalFlinkMemory(TaskExecutorFlinkMemoryUtils.java:178)
at org.apache.flink.runtime.util.config.memory.taskmanager.TaskExecutorFlinkMemoryUtils.deriveFromTotalFlinkMemory(TaskExecutorFlinkMemoryUtils.java:42)
at org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils.deriveProcessSpecWithTotalFlinkMemory(ProcessMemoryUtils.java:103)
at org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils.memoryProcessSpecFromConfig(ProcessMemoryUtils.java:80)
at org.apache.flink.runtime.clusterframework.TaskExecutorProcessUtils.processSpecFromConfig(TaskExecutorProcessUtils.java:163)
... 3 more
2.未放入对应hadoop插件导致的错误
[root@k8s-master bin]# ./flink run /home/module/flink/flink-1.17.0/examples/batch/WordCount.jar --input hdfs://k8s-master:8020/mytest/input/wordCount.txt --output hdfs://k8s-master:8020/mytest/output
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:105)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:851)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:245)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1095)
at org.apache.flink.client.cli.CliFrontend.lambda$mainInternal$9(CliFrontend.java:1189)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.mainInternal(CliFrontend.java:1189)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1157)
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:321)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1061)
at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:144)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:73)
at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:93)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)
... 9 more
Caused by: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1056)
... 17 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:321)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:75)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
at java.util.concurrent.CompletableFuture$Completion.exec(CompletableFuture.java:457)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
Caused by: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.runtime.jobmaster.DefaultJobMasterServiceProcess.lambda$new$0(DefaultJobMasterServiceProcess.java:97)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1609)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.util.concurrent.CompletionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfs://k8s-master:8020/mytest/output, delimiter: ))': Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1606)
... 3 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfs://k8s-master:8020/mytest/output, delimiter: ))': Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:321)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedSupplier$4(FunctionUtils.java:114)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
... 3 more
Caused by: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfs://k8s-master:8020/mytest/output, delimiter: ))': Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.runtime.executiongraph.DefaultExecutionGraphBuilder.buildGraph(DefaultExecutionGraphBuilder.java:189)
at org.apache.flink.runtime.scheduler.DefaultExecutionGraphFactory.createAndRestoreExecutionGraph(DefaultExecutionGraphFactory.java:163)
at org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:365)
at org.apache.flink.runtime.scheduler.SchedulerBase.(SchedulerBase.java:210)
at org.apache.flink.runtime.scheduler.DefaultScheduler.(DefaultScheduler.java:136)
at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:152)
at org.apache.flink.runtime.jobmaster.DefaultSlotPoolServiceSchedulerFactory.createScheduler(DefaultSlotPoolServiceSchedulerFactory.java:119)
at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:371)
at org.apache.flink.runtime.jobmaster.JobMaster.(JobMaster.java:348)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.internalCreateJobMasterService(DefaultJobMasterServiceFactory.java:123)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.lambda$createJobMasterService$0(DefaultJobMasterServiceFactory.java:95)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedSupplier$4(FunctionUtils.java:112)
... 4 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:543)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:409)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:274)
at org.apache.flink.api.common.io.FileOutputFormat.initializeGlobal(FileOutputFormat.java:288)
at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initializeOnMaster(InputOutputFormatVertex.java:113)
at org.apache.flink.runtime.executiongraph.DefaultExecutionGraphBuilder.buildGraph(DefaultExecutionGraphBuilder.java:180)
... 15 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:55)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:526)
... 20 more

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)