
matlab中奇妙的rand随机数,解决你的疑惑
matlab中奇妙的rand随机数,解决你的疑惑
随机数是大家在学习算法的过程中经常遇到的一个名词,在寻优算法和机器学习算法中出现的频率很高,随机数正因为其随机的特性每次运行结果生成的值都不一样,因此含有大量随机数的寻优算法以及机器学习算法每次运行的结果都会有一定的差异性。(所以很多同学问我每次运行遗传算法或者bp神经网络结果为什么不一样呢,随机数就是原因;如果算法中不存在随机数,那么每次运行的结果就应该是一样的。)
在matlab中随机数的生成主要依靠两个函数,一个是rand(满足均匀分布)一个是randn(满足正态分布),其他大部分与随机数相关的函数都是由这两个函数衍生出来的。
那么我们这里就以rand函数为例子,首先我们生成一个随机数,并且多次运行,如下图


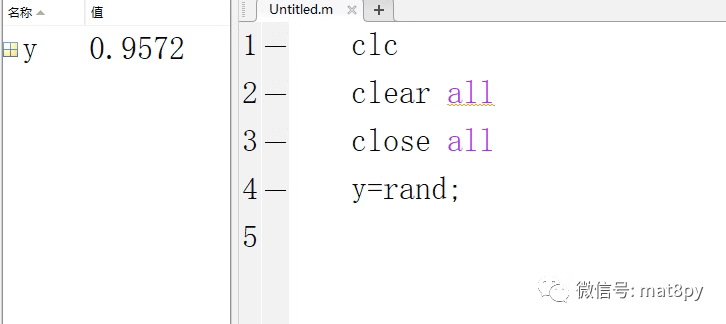
可以看到,3次运行每次生成的结果都是不一样的;然后我们试着在一个文件中生成3个随机数,如下图
从工作区可以看到3次生成的值是不一样的,本质上和运行三次每次只生成一个随机数原理一致。因为每一次的生成都是随机的,并且三次生成彼此没有关系,所以能生成出完全一样的值的可能性几乎没有。衍生到生成n个随机数,道理是一样的.........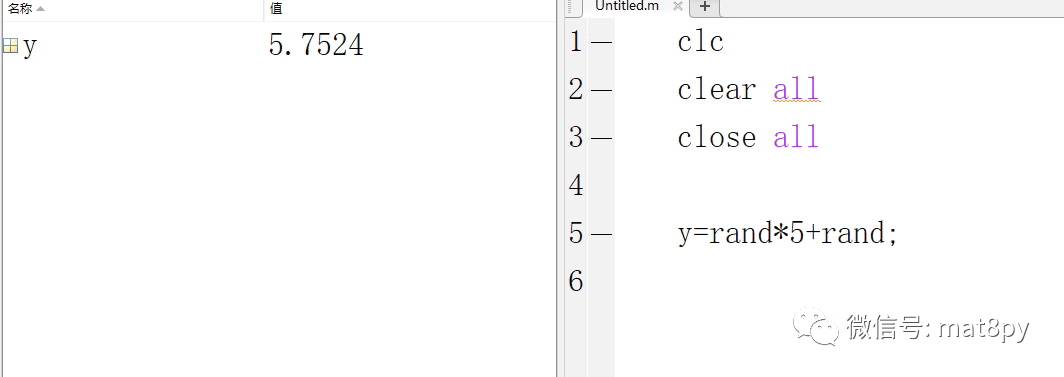
如上图,一行代码中有两个rand,相当于按照从左到右的顺序依次生成了两个随机数,与上图中的c1,c2同理。
如果程序中存在循环结构(如for、while),那么情况如何呢?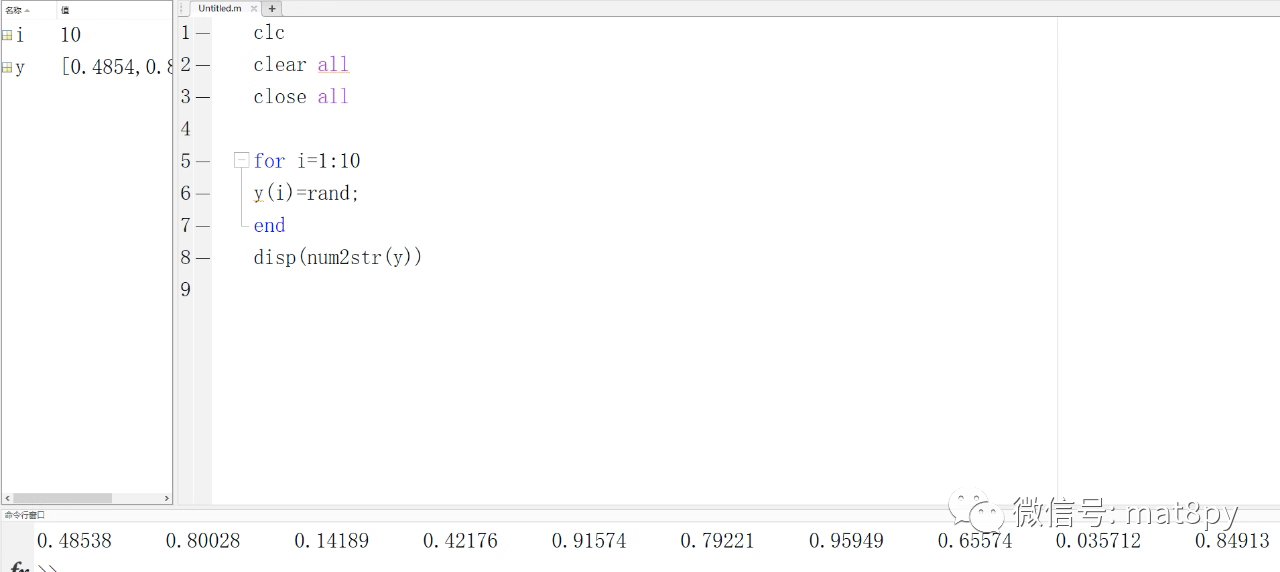
从上图中可以看到,每一次循环都生成了一个随机数,一共生成了10次,生成的顺序为y1,y2....y10,等同于写了10遍的y=rand;
那么当程序中存在子函数,子函数里面又有随机数,那么是怎么个情况呢,如下图: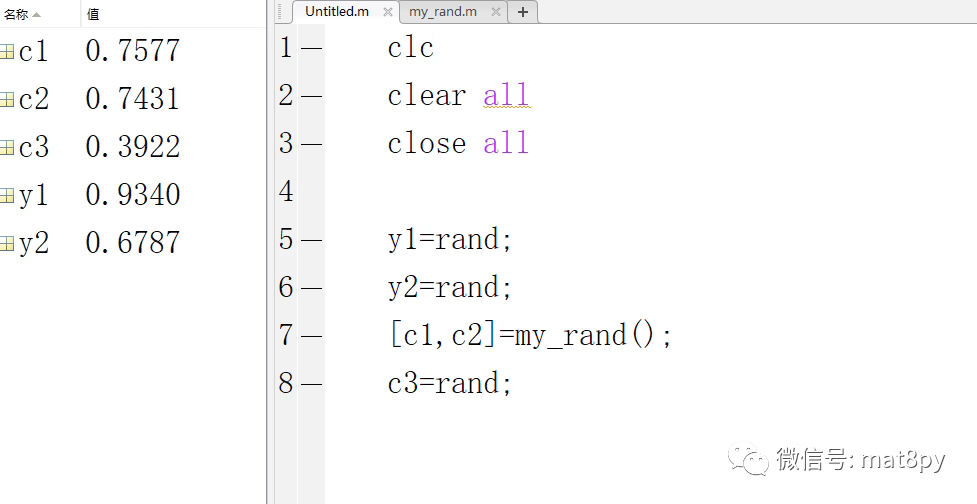

以上述两个图中的程序为例,随机数生成的顺序应该为:y1,y2,c1,c2,c3 也就是说程序执行完第6行之后,就执行第7行的子函数,执行完子函数内的所有代码之后才会执行第8行。所以总结一下就是,随机数的生成的顺序是按照代码的执行顺序来实施的。
当我们要生成多个随机数的时候(如5乘以3的矩阵,矩阵里的每个数都是随机数),可以执行下面的命令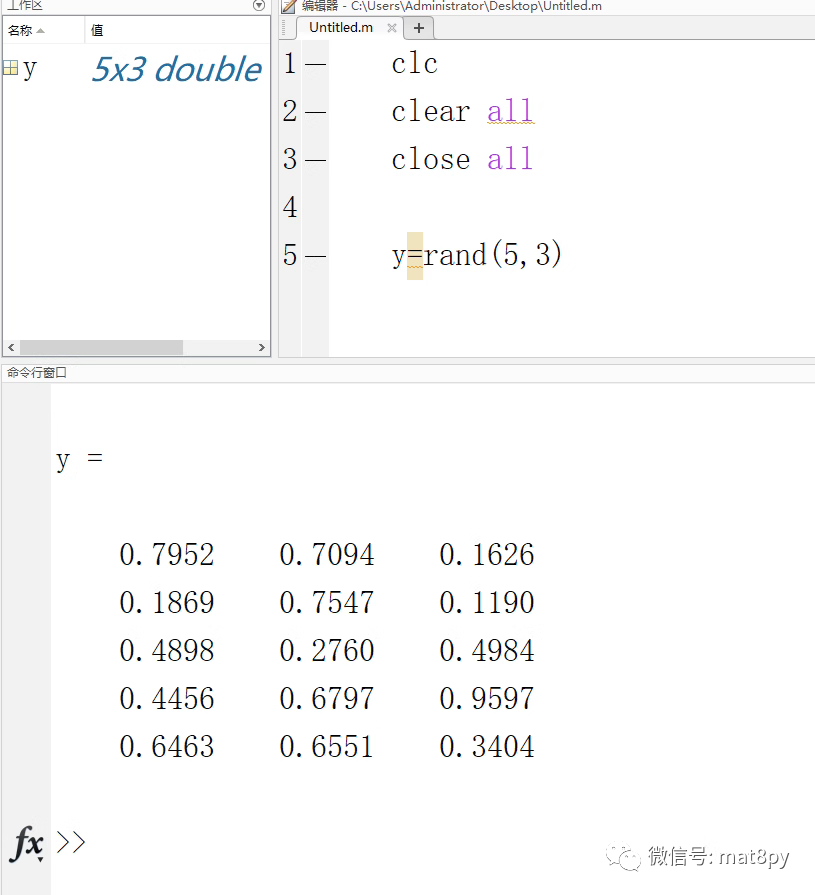

由于rand函数是均匀生成,因此矩阵里的每个数的生成理论上也是独立的,没有任何关联。如果是randn函数生成,那么生成的数据是满足正态分布的,也就是说矩阵里的每个数是有一定关联的,并不完全独立。
由于随机数本身随机的特性,也给编程过程带来了一些麻烦。比如我们运行了一次脚本,生成的结果是我们满意的,但时候如果我们下次再运行就很难再复现出之前的效果,那么我们该怎么办呢?在matlab中是通过‘state’关键字或者rng函数来控制,如下图:
从图中可以看到,代码开头加了两个命令,加了这个命令后我们可以多次运行代码,可以发现在不改变代码内容的前提下每次运行生成的随机数和上一次运行的结果都是一样的,这个时候不要认为是代码错了,而是我们通过认为的手段对随机数进行了复现。rand('state',1)和randn('state',1)分别控制的是rand和randn生成的随机数,也就是说加了rand('state',1)命令,没加randn('state',1),那么通过randn生成的随机数每次运行还是不同的,反过来也是如此。如果我们想要在加了这个命令的前提下让生成的随机数变一变该怎么办呢?这个时候我们可以通过改变'state'后面的序列数(状态数)来使得运行的结果发生变化,如下图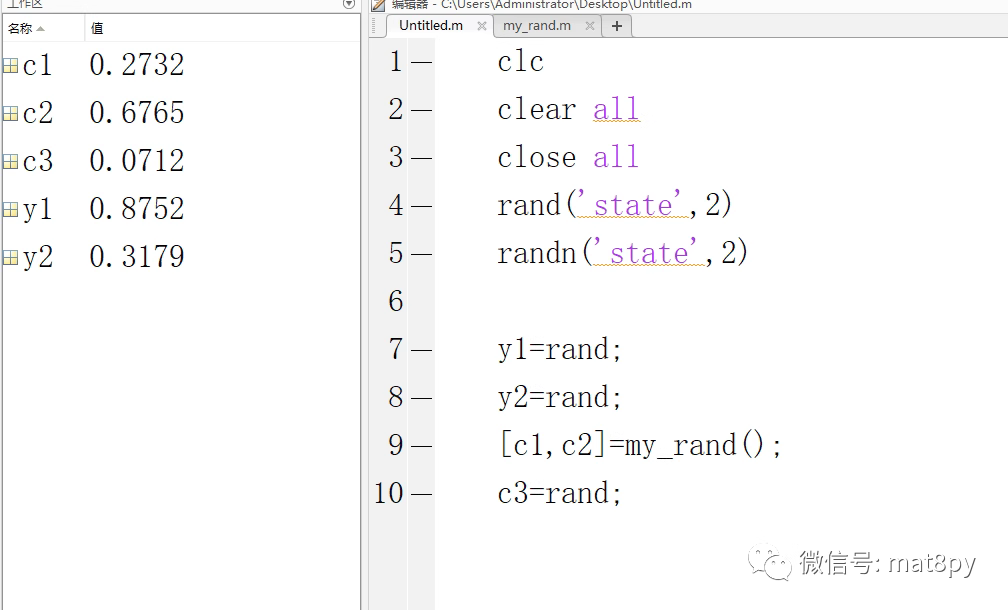
从上图看出,序列数改成2之后,生成的结果和为1时候的结果是不同的。有的同学会问这个1或者2表示什么含义呢,和生成的随机数有什么关联呢?这边呢,小猪老师直接让大家记住,这个1和2本身没有含义的,只是区分状态的不同,这个1和2与生成的随机数也没有联系,只是给大家区分出状态1生成的随机数的值是某一组,而状态2生成的随机数又是另一组值。如果我们序列数改成2之后觉得效果没有1时候的好,我们可以再改回来,那么生成的随机数的值还是会和之前序列数为1时候生成的值一致..............
最后,还有一个很多同学同意踩坑的点,就是当设置了随机数序列数而程序中又有循环结构时,很多同学就会认为每一次循环生成的随机数和之前循环生成的一样,那么事实如何呢?我们看下图
。。。。。。。。。。。。。。。。。
版权原因,完整文章,请参考如下:matlab中奇妙的rand随机数,解决你的疑惑

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)