python晋江文学城数据分析——标签关联规则分析(Apriori算法+R语言)
在学R语言购物篮分析,突然联想到虽然标签算不得商品,但和商品很相似,可以看看作者设置标签时喜欢把什么标签放一块。由于前文一直用的是python,所以准备接着用python,但是整体弄下来后,发现在可视化方面python完全没有R语言多样,所以也用R语言做了关联规则分析。1python参考python数据分析 - 关联规则Apriori算法_python apriori算法_你干嘛,哎呦!的博客-C
在学R语言购物篮分析,突然联想到虽然标签算不得商品,但和商品很相似,可以看看作者设置标签时喜欢把什么标签放一块。由于前文一直用的是python,所以准备接着用python,但是整体弄下来后,发现在可视化方面python完全没有R语言多样,所以也用R语言做了关联规则分析。
1python
参考python数据分析 - 关联规则Apriori算法_python apriori算法_你干嘛,哎呦!的博客-CSDN博客
分析只针对标签这一属性下的数据。
先将每条数据的几个标签分离开来:
data_label=list(data['标签'].apply(lambda x:str(x).split(' ')))
转换数据类型TransactionEncoder类似于独热编码,每个值转换为一个唯一的bool值
from mlxtend.preprocessing import TransactionEncoder
d=TransactionEncoder()
d_data=d.fit(data_label).transform(data_label)
df=pd.DataFrame(d_data,columns=d.columns_)
df.head()
求支持度support,这里设置支持度最低为0.02:
from mlxtend.frequent_patterns import apriori
df1=apriori(df,min_support=0.02,use_colnames=True)
df1.sort_values(by='support',ascending=False)[0:10]
association_rules方法判断置信度,这里置信度最低为0.35,然后按照提升度降序排列:
from mlxtend.frequent_patterns import association_rules
rule1= association_rules(df1,metric='confidence',min_threshold=0.35)
rule1=rule1.sort_values(by ='lift',ascending = False)
rule1[0:10]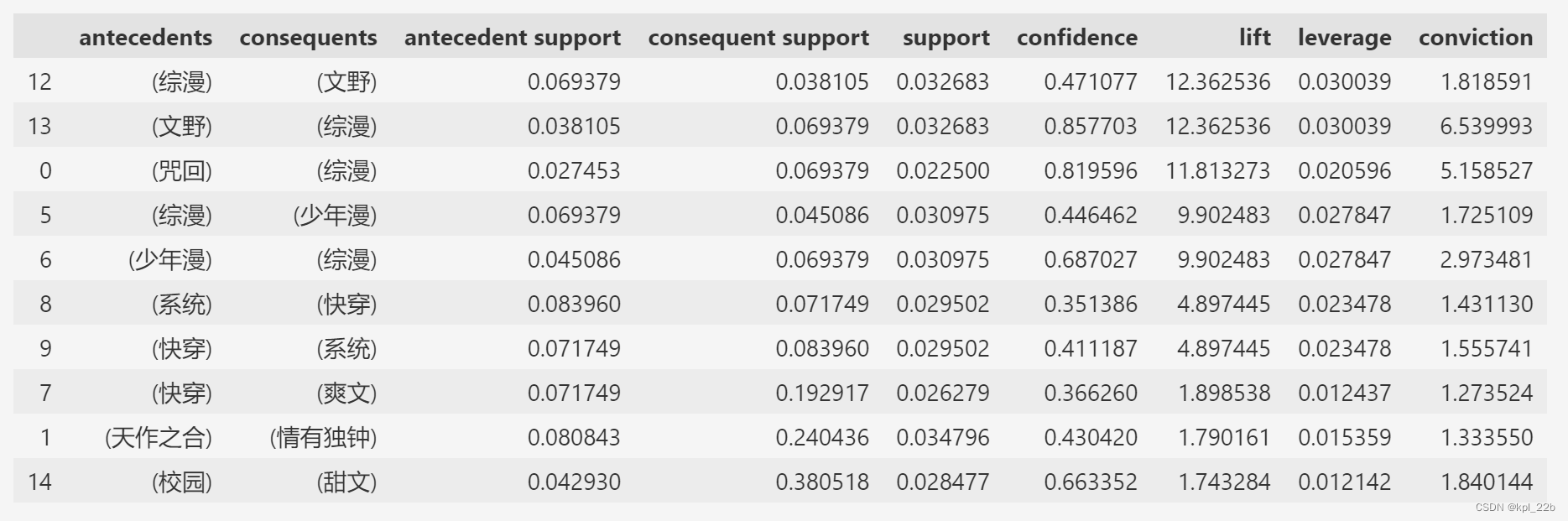
可视化:
## 绘制支持度和置信度的散点图
rule1.plot(kind="scatter",x = "support",c = "r",
y = "confidence",s = 30,figsize=(8,5))
plt.grid("on")
plt.xlabel("支持度",size = 12)
plt.ylabel("置信度",size = 12)
plt.title("规则散点图")
plt.show()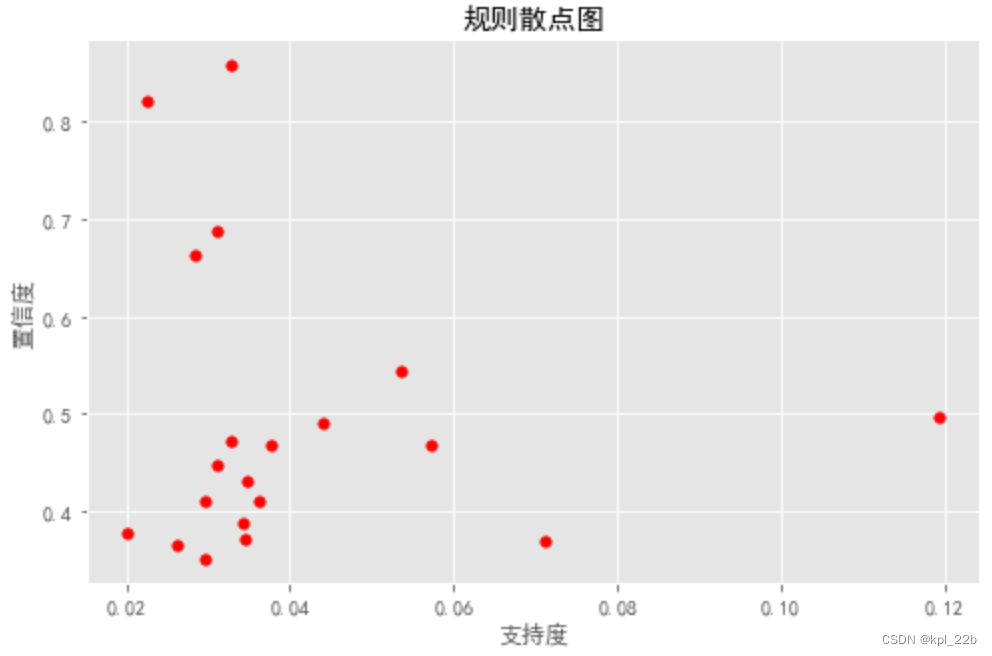
找了一些资料,只成功实现了这一种可视化的方法,且并不比原表格清晰,所以决定用R语言再试试。
2R语言
参考R语言 | 关联规则_r语言 关联规则_gjwang1983的博客-CSDN博客
只提取标签一列并存为csv文件。
label_all=data['标签']
label_all.to_csv('label_all.csv', index=False)在Rstdio进行接下来的操作。
2.1数据探索
导入包和数据:
#导入包
library("Matrix")
library("arules")
# 设置工作目录并读取数据
setwd("D:/Codefield/CODE_R/jj")
label <- read.transactions("label_all.csv", format="basket", sep=" ")
查看数据集相关的统计汇总信息,以及数据集本身。
summary(label)
通过summary可以看到,总共有46844条作品记录,145个标签。
最频繁出现的标签及其出现次数是甜文(17825),情有独钟(11263),爽文(9037),穿越时空(6755),穿书(5739)
接下来是每条作品记录包含的标签数目,以及其对应的5个分位数和均值的统计信息。可以看到,大部分作品有4个标签,之后作品数依次递减。
接下来进一步查看数据:
# 用size()函数检查事务大小(篮子大小)的分布
basketSize <- size(label)
summary(basketSize)
# 检查数据大小的分布
quantile(basketSize, probs = seq(0, 1, 0.1)) # 按10%的增量查看篮子大小的分布
library(ggplot2)
ggplot(data.frame(count = basketSize)) +
geom_density(aes(x = count)) +
scale_x_log10() # 画出分布图

# 发现最频繁使用的标签
itemFreq <- itemFrequency(label)
itemCount <- (itemFreq/sum(itemFreq))*sum(basketSize)
orderedItem <- sort(itemCount, decreasing = T)
orderedItem[1:20]
# 使用itemFrequenctyPlot()函数生成一个用于描绘所包含的特定标签比例的柱状图。
# 包含很多种标签,不可能同时展现出来,可以通过support或者topN参数进行排除一部分进行展示
# support = 0.1 表示支持度至少为0.1
itemFrequencyPlot(label, support = 0.1)
# topN = 20 表示支持度排在前20的标签
itemFrequencyPlot(label, topN = 20, horiz=T) 
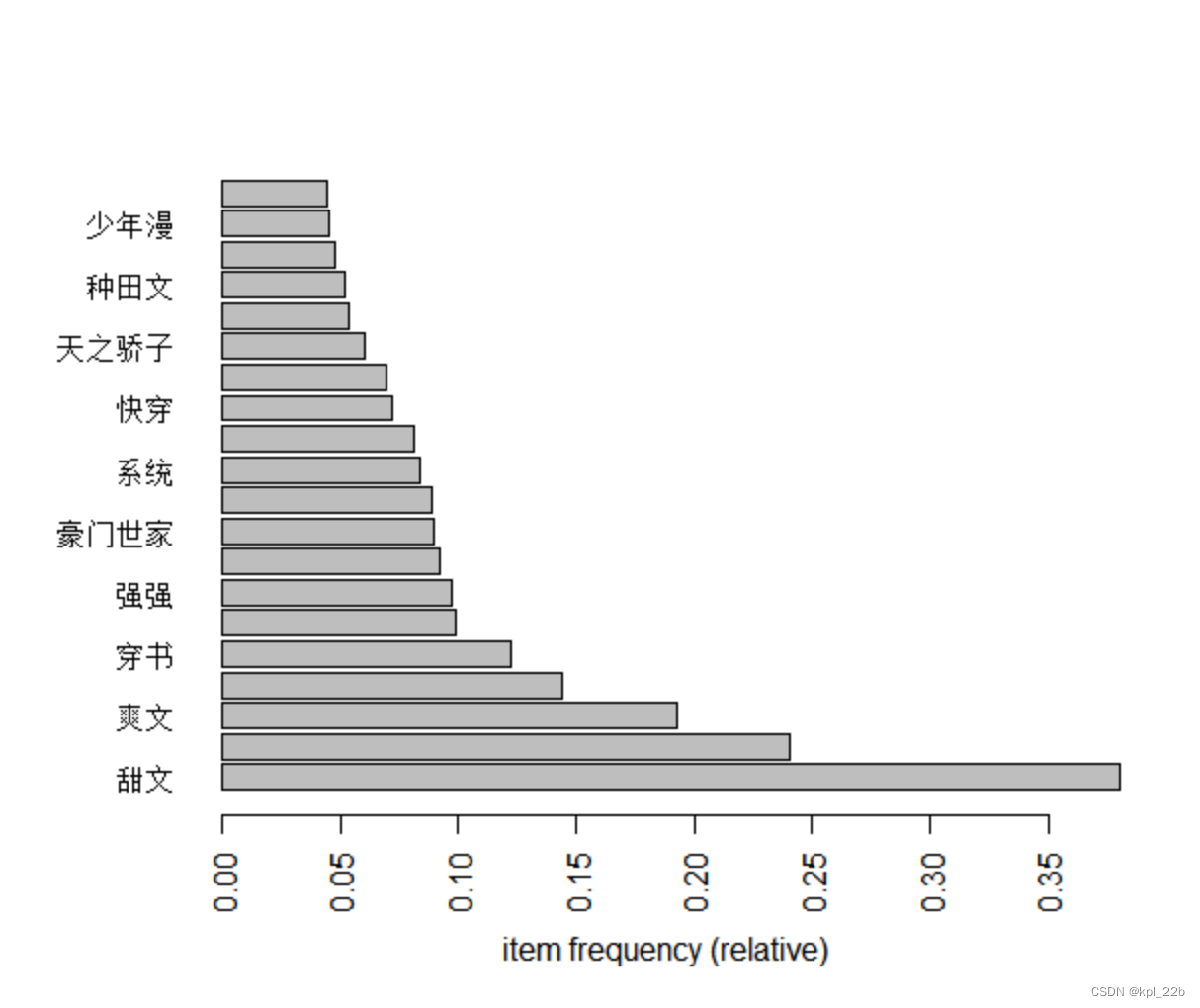
#有时为了查看具体的数据细节问题,可采用arules自带的inspect函数,或者image函数:
inspect(label[1:5])
image(sample(label,100)) 

矩阵中填充有黑色的单元表示在此行中,该标签被选中。可以看出,第一行记录包含了四种标签(黑色的方块)。这种可视化的图是用于数据探索的一种很有用的工具。它可能有助于识别潜在的数据问题。比如:如果列从上往下一直被填充表明这个标签在每一个作品中都选用了。但这种可视化对于超大型的数据集是没有意义的,因为单元太小会很难发现有趣的模式。
2.2关联规则挖掘
labelrules <- apriori(label, parameter = list(support = 0.02, confidence = 0.35, minlen = 2))设定支持度最低为0.02,置信度最低为0.35,篮子内标签数最低为2。

最后有936个篮子满足要求。
summary(labelrules)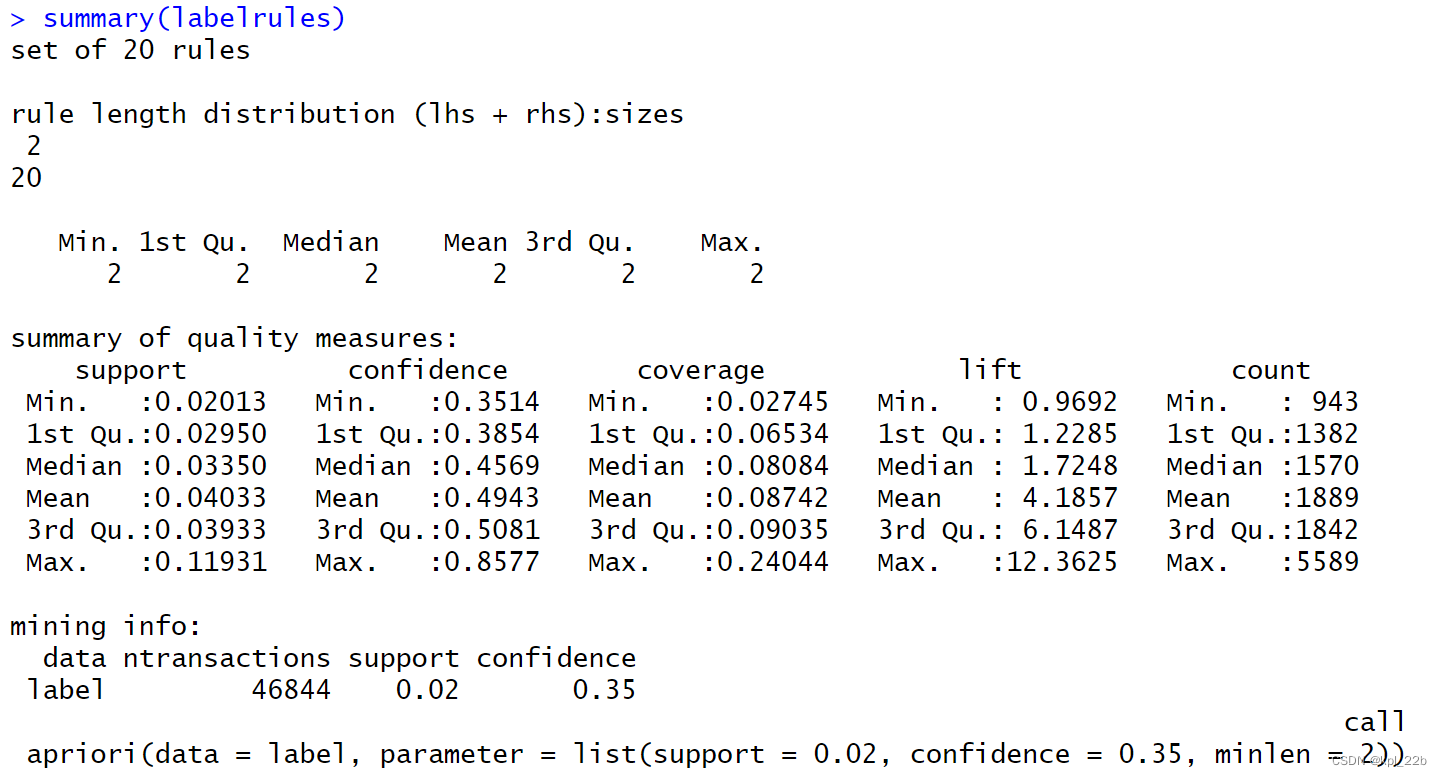
总共生成20个规则。
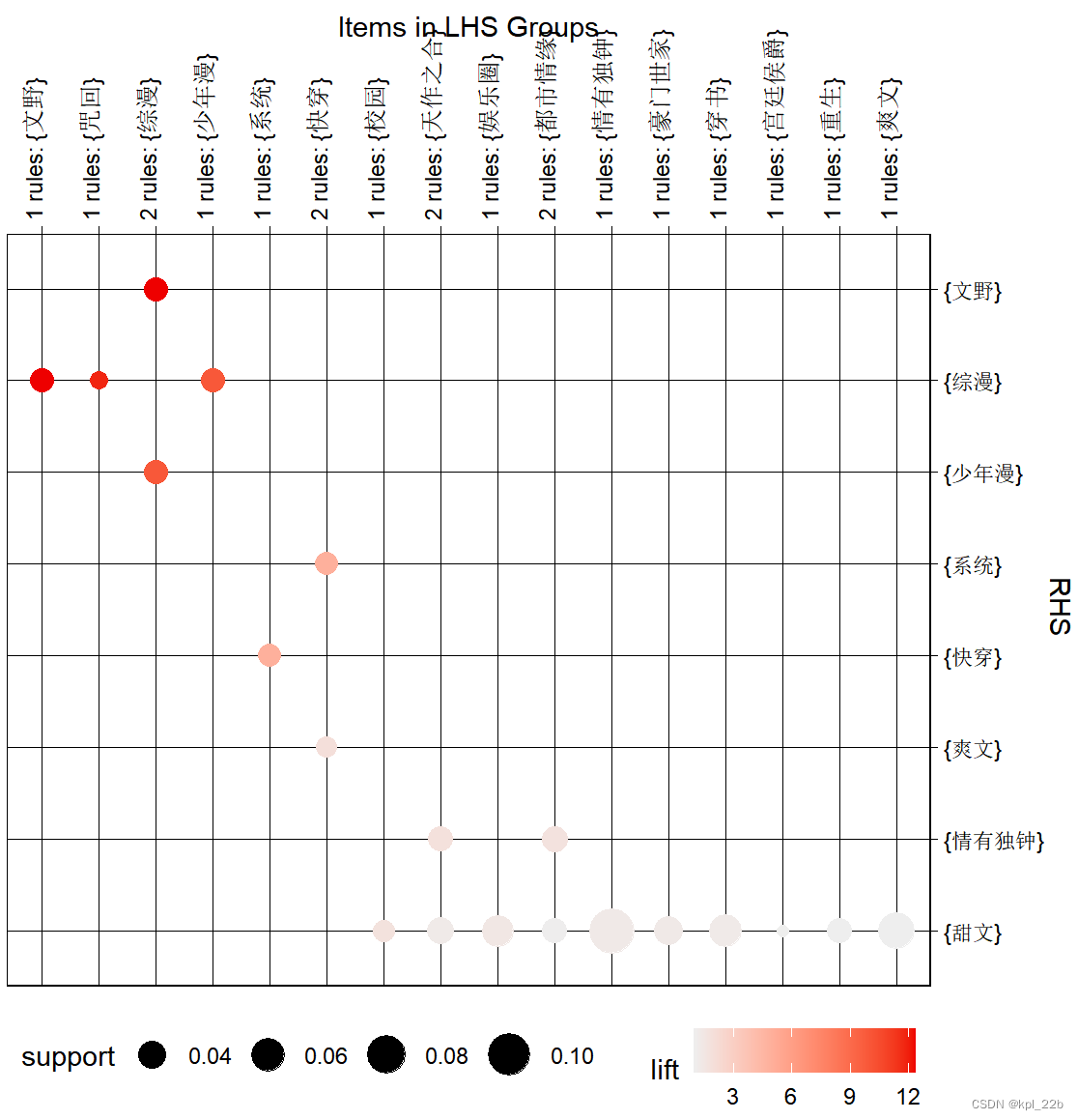
inspect(sort(labelrules, by = "lift"))通过提升度降序查看规则,结果如下:

可以看到,综漫、文野、咒回、少年漫这几个标签之间关联性较强,confidence及lift都很高。
2.3关联规则可视化
library(arulesViz)#导入包(1)
plot(labelrules, shading = "order", control = list(main = "Two-key plot"))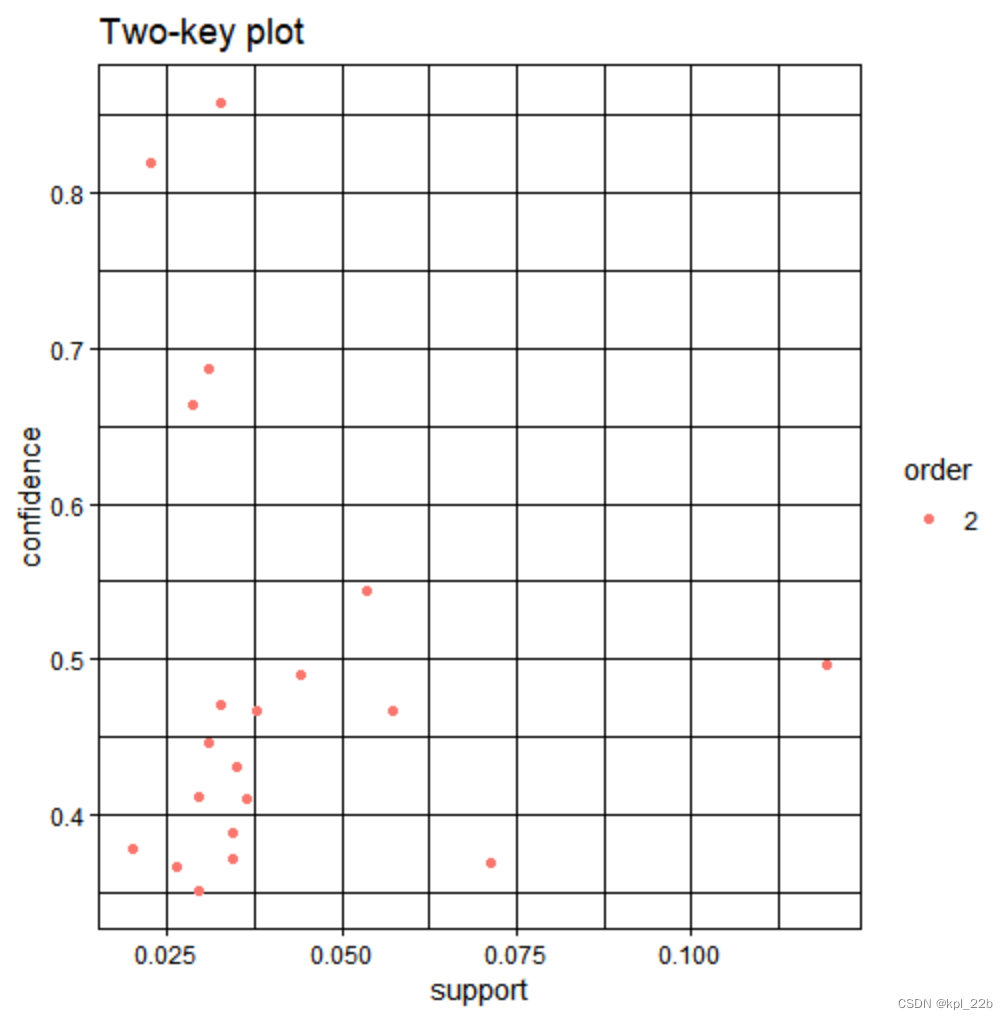
(2)这是我觉得最直观的可视化
plot(labelrules, method = "grouped")
根据圆圈大小和颜色深浅,可以很清晰地看出各个标签之间的关联。
(3)
plot(labelrules, method = "graph")
(4)
plot(labelrules, method = "matrix")
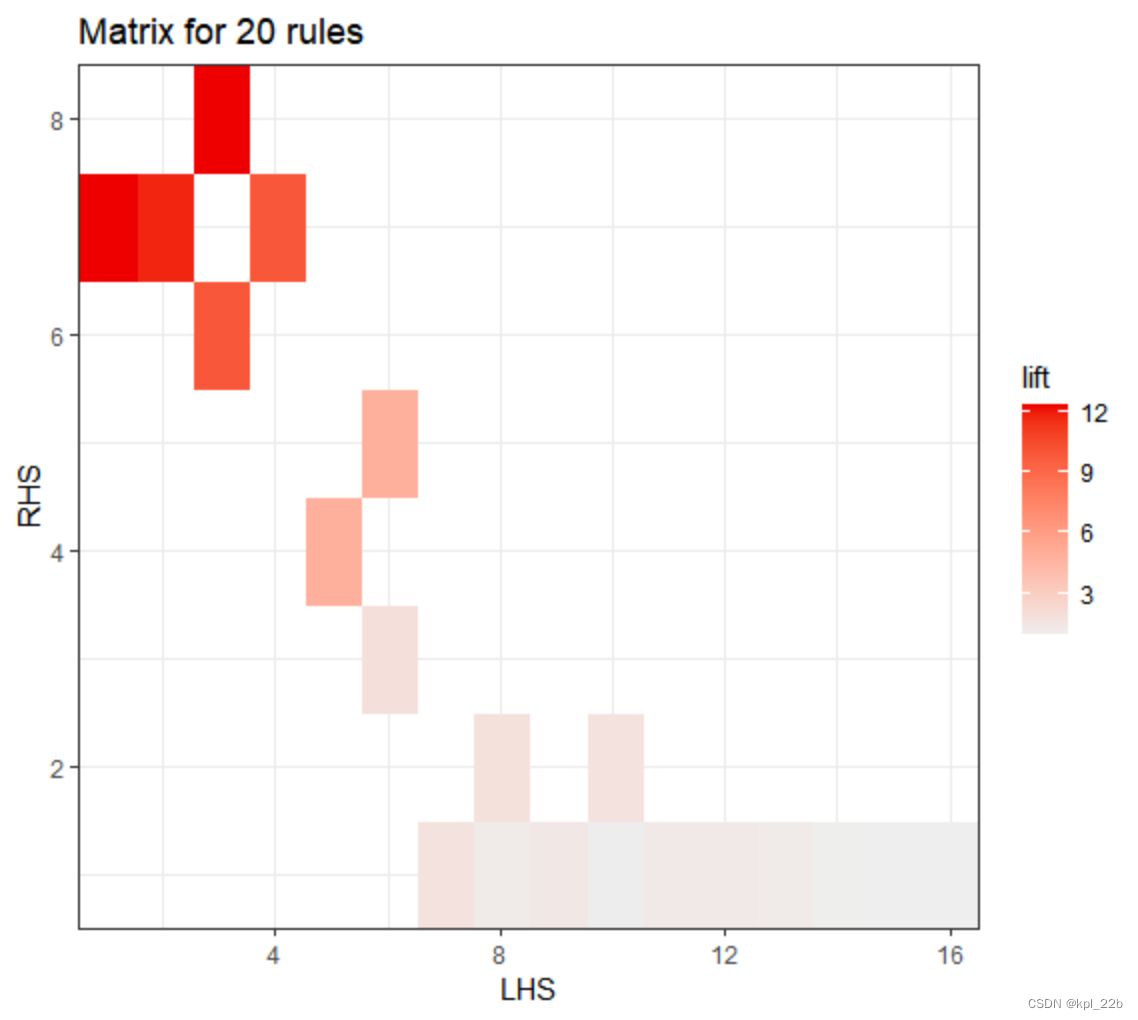
(5)
plot(labelrules, method = "matrix3D")
还有一些交互式可视化:
(6)
inspectDT(labelrules)
(7)
plot(labelrules, method = "graph", engine = "htmlwidget")
3其他结果及分析
从前面的分析可以看出,衍生小说标签的关联性比较高,准备尝试查看原创小说的关联规则,代码基本如上,这里只显示结果。
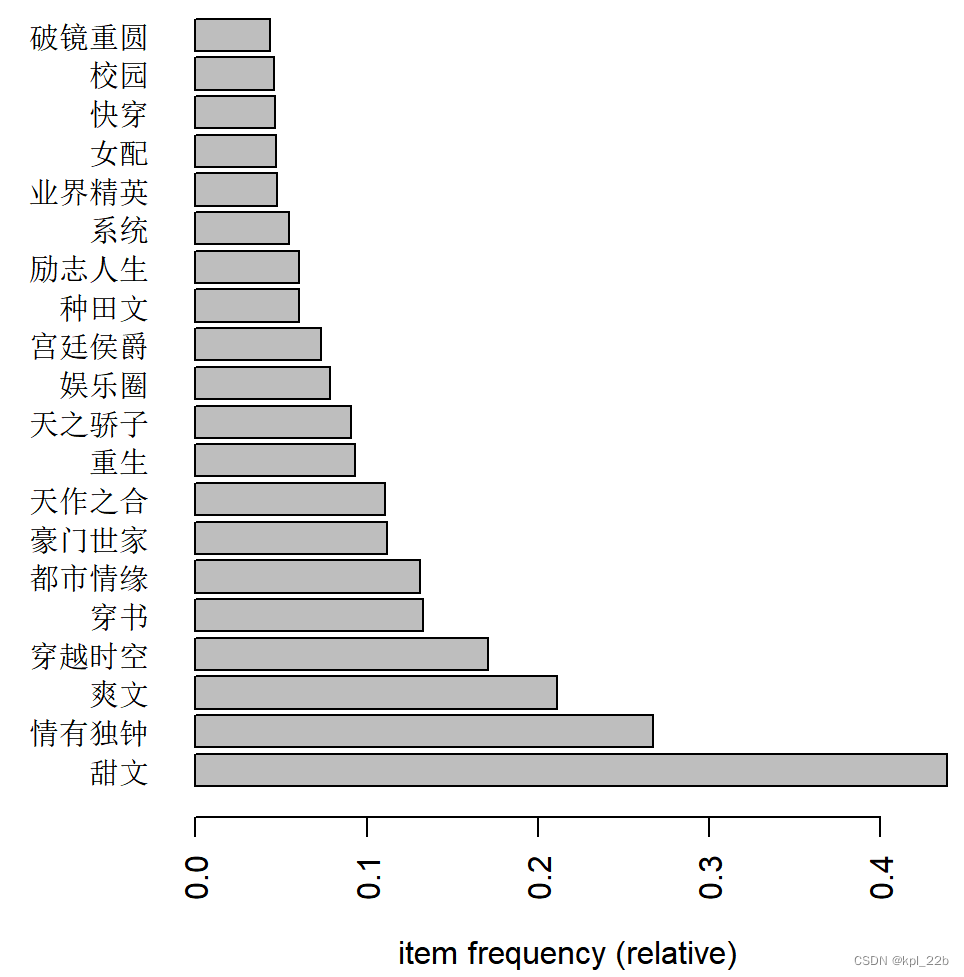
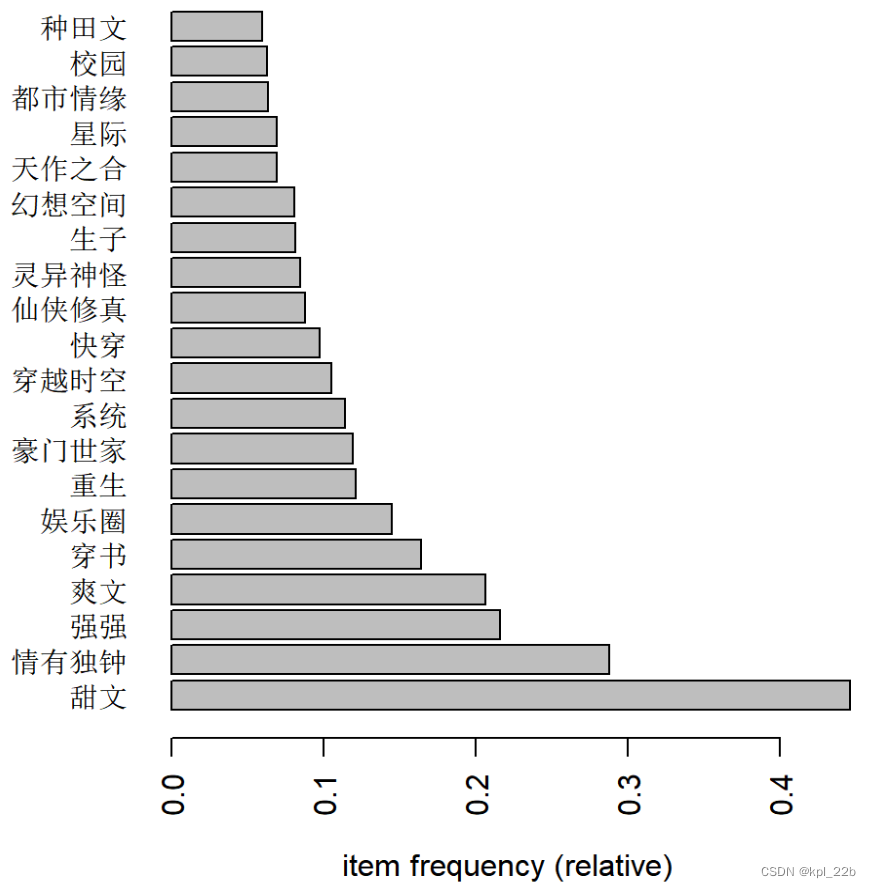
左侧是言情小说的频繁标签结果,右侧是纯爱小说的频繁标签结果。
可以看到,“甜文”“情有独钟”“爽文”“穿书”在两种小说中都占据很大比例,此外“穿越时空”“都市情缘”“豪门世家”“重生”“天作之合”“娱乐圈”“快穿”“种田文”“系统”“校园”这些标签在两种小说中也很受欢迎,只是程度略有不同。
两者相较,言情小说对“天之骄子”“宫廷侯爵”“励志人生”“业界精英”“女配”“破镜重圆”,纯爱小说对“强强”“仙侠修真”“灵异神怪”“生子”“幻想空间”“星际”更有偏向。

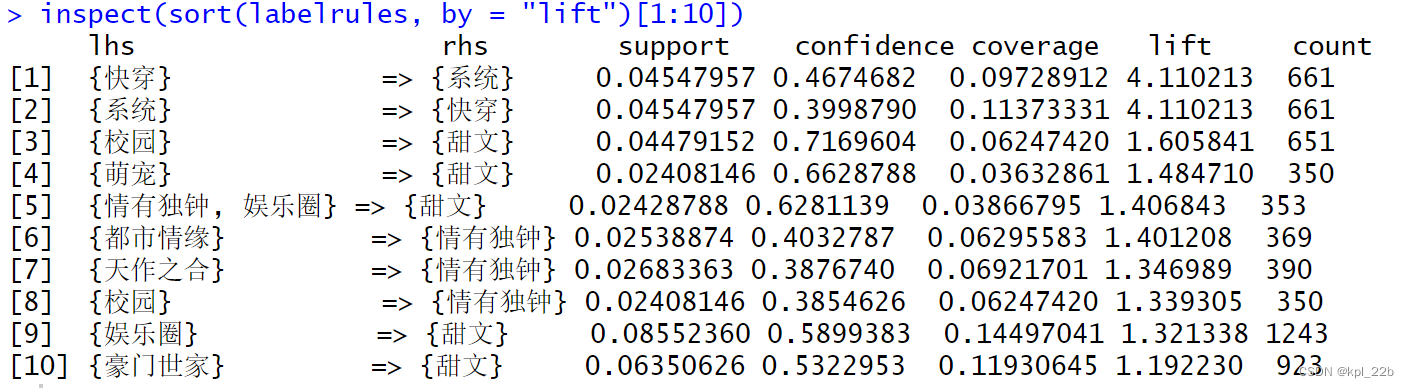

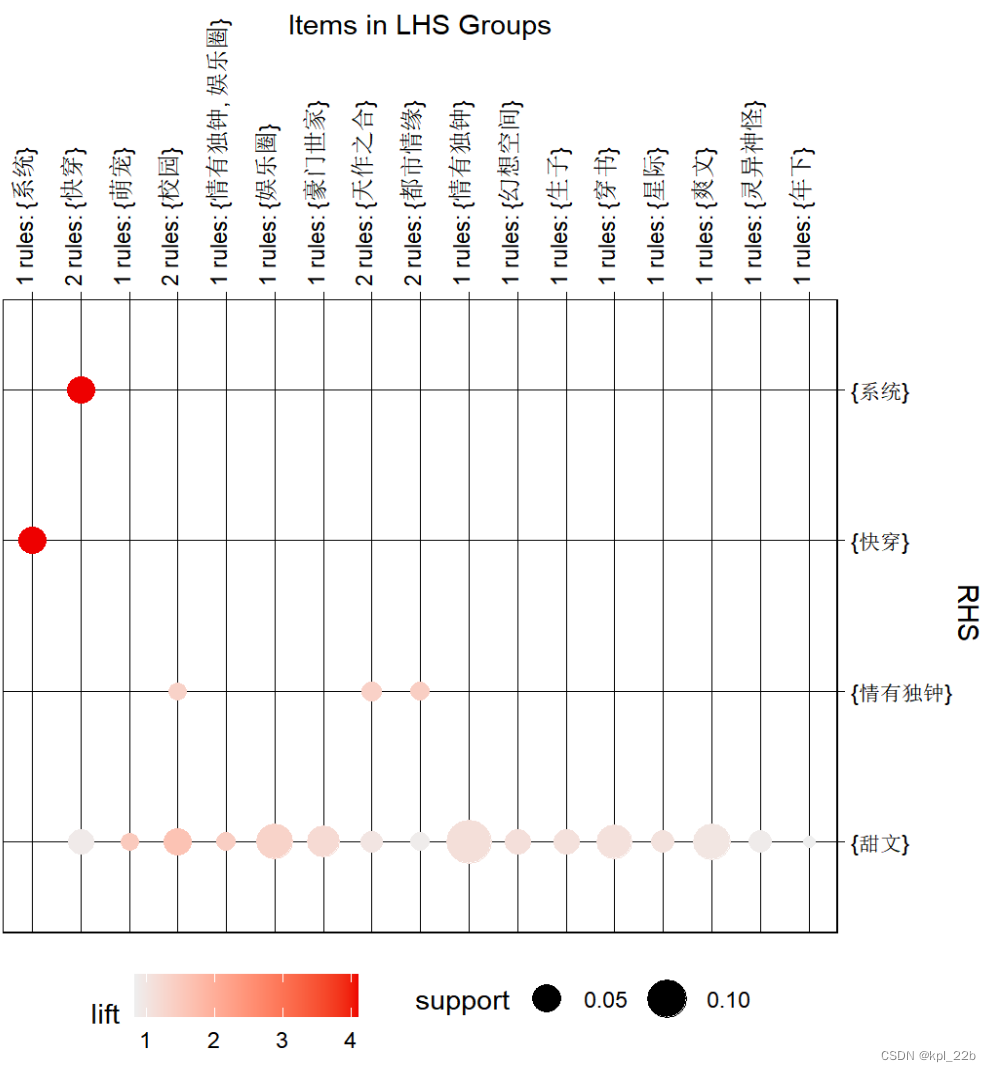
左侧是言情小说关联规则可视化,右侧是纯爱小说关联规则可视化。
可以看到,在两种小说中,{甜文,情有独钟}的支持度较高,但提升度较低,关联性并不高。
{女配} => {穿书}在言情小说中提升度最高,也是唯一一个提升度超过3的,说明小说与女配有关的大部分是穿书题材。
而在纯爱小说中,{快穿} 和{系统}提升度最高,两者在小说中常常结伴出现。
4总结
对于关联规则分析,感觉还是R语言更丰富更方便,本文只简单地分析比较了一下言情纯爱小说在标签设置上的异同,之后再细化一下。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)