
【通用大语言模型】GLM-130B:一个开放的双语预训练模型
最伟大的艺术家不是画出最美的图画、写出最好的诗或演奏最好的交响乐的人。伟大的艺术家不是完美的。三亚最热的月份是6月,平均气温为28.5°C,极端最高气温为35.7°C ,三亚没有明显的冬季,而且冬季更是到海滨旅游的最好时候,所以三亚是全年全天候避寒、消暑、度假、旅游的好地方。在 NLU、条件生成和无条件生成的广泛任务中,GLM 在相同模型大小和数据的情况下优于 BERT、T5 和 GPT,并且在具
GLM-130B:一个开放的双语预训练模型

论文:https://aclanthology.org/2022.acl-long.26.pdf
There have been various types of pretraining architectures including autoencoding models (e.g., BERT), autoregressive models (e.g., GPT), and encoder-decoder models (e.g., T5). However, none of the pretraining frameworks performs the best for all tasks of three main categories including natural language understanding (NLU), unconditional generation, and conditional generation. We propose a General Language Model (GLM) based on autoregressive blank infilling to address this challenge. GLM improves blank filling pretraining by adding 2D positional encodings and allowing an arbitrary order to predict spans, which results in performance gains over BERT and T5 on NLU tasks. Meanwhile, GLM can be pretrained for different types of tasks by varying the number and lengths of blanks. On a wide range of tasks across NLU, conditional and unconditional generation, GLM outperforms BERT, T5, and GPT given the same model sizes and data, and achieves the best performance from a single pretrained model with 1.25× parameters of BERT Large , demonstrating its generalizability to different downstream tasks.
有多种类型的预训练架构,包括自动编码模型(例如 BERT)、自回归模型(例如 GPT)和编码器-解码器模型(例如 T5)。然而,没有一个预训练框架对自然语言理解 (NLU)、无条件生成和条件生成这三个主要类别的所有任务表现最好。我们提出了一种基于自回归空白填充的通用语言模型 (GLM) 来应对这一挑战。 GLM 通过添加 2D 位置编码并允许以任意顺序预测跨度来改进空白填充预训练,从而在 NLU 任务上获得优于 BERT 和 T5 的性能。同时,可以通过改变空白的数量和长度来针对不同类型的任务对 GLM 进行预训练。在 NLU、条件生成和无条件生成的广泛任务中,GLM 在相同模型大小和数据的情况下优于 BERT、T5 和 GPT,并且在具有 1.25× BERT Large 参数的单个预训练模型中实现了最佳性能,展示了其对不同下游任务的泛化能力。
来自:GLM: General Language Model Pretraining with Autoregressive Blank Infilling - ACL Anthology
代码:
GitHub - THUDM/GLM-130B: GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)
目录
Left-To-Right Generation / Blank Filling从左到右生成/空白填充
2.5X faster Inference using FasterTransformer使用 FasterTransformer 的推理速度提高 2.5 倍

GLM-130B is an open bilingual (English & Chinese) bidirectional dense model with 130 billion parameters, pre-trained using the algorithm of General Language Model (GLM). It is designed to support inference tasks with the 130B parameters on a single A100 (40G * 8) or V100 (32G * 8) server. With INT4 quantization, the hardware requirements can further be reduced to a single server with 4 * RTX 3090 (24G) with almost no performance degradation. As of July 3rd, 2022, GLM-130B has been trained on over 400 billion text tokens (200B each for Chinese and English) and it has the following unique features:
GLM-130B 是一个开放的双语(英汉)双向密集模型,具有 1300 亿个参数,使用通用语言模型(GLM)的算法进行预训练。它旨在支持单台A100(40G * 8)或V100(32G * 8)服务器上具有130B参数的推理任务。通过 INT4 量化,硬件要求可以进一步降低到具有 4 * RTX 3090(24G)的单个服务器,而性能几乎没有下降。截至 2022 年 7 月 3 日,GLM-130B 已经接受了超过 4000 亿个文本标记(中文和英文各 200B)的训练,它具有以下独特的特点:
- Bilingual: supports both English and Chinese.
双语:支持英文和中文。 - Performance (EN): better than GPT-3 175B (+4.0%), OPT-175B (+5.5%), and BLOOM-176B (+13.0%) on LAMBADA and slightly better than GPT-3 175B (+0.9%) on MMLU.
性能(EN):在 LAMBADA 上优于 GPT-3 175B(+4.0%)、OPT-175B(+5.5%)和 BLOOM-176B(+13.0%),略优于 GPT-3 175B(+0.9%)在 MMLU 上。 - Performance (CN): significantly better than ERNIE TITAN 3.0 260B on 7 zero-shot CLUE datasets (+24.26%) and 5 zero-shot FewCLUE datasets (+12.75%).
性能(CN):在 7 个零样本 CLUE 数据集(+24.26%)和 5 个零样本 FewCLUE 数据集(+12.75%)上明显优于 ERNIE TITAN 3.0 260B。 - Fast Inference: supports fast inference on both SAT and FasterTransformer (up to 2.5X faster) with a single A100 server.
快速推理:支持使用单个 A100 服务器对 SAT 和 FasterTransformer(快达 2.5 倍)进行快速推理。 - Reproducibility: all results (30+ tasks) can be easily reproduced with open-sourced code and model checkpoints.
可重现性:所有结果(30 多个任务)都可以使用开源代码和模型检查点轻松重现。 - Cross-Platform: supports training and inference on NVIDIA, Hygon DCU, Ascend 910, and Sunway (Will be released soon).
跨平台:支持在NVIDIA、Hygon DCU、Ascend 910、Sunway(即将发布)上的训练和推理。
This repository mainly focus on the evaluation of GLM-130B, the training part is open for research purposes, please send an email to glm-130b@googlegroups.com to apply for access. If you find our work and our open-sourced efforts useful, ⭐️ to encourage our following development! :)
本资源库主要针对GLM-130B的评估,训练部分开放供研究使用,请发邮件至glm-130b@googlegroups.com申请访问。如果您发现我们的工作和我们的开源努力有用, ⭐️ 鼓励我们的后续发展! :)
News 消息
- [2023.01.21] GLM-130B has been accepted to ICLR 2023!
[2023.01.21] GLM-130B已被ICLR 2023接收! - [2022.10.06] Our paper for GLM-130B is out!
[2022.10.06] 我们的GLM-130B论文出来了! - [2022.08.24] We are proud to publish the quantized version for GLM-130B. While preserving the activation precision as FP16, the model weights can be quantized to as low as INT4 with almost no degradation of performance, further reducing the hardware requirements of the GLM-130B to a single server with 4 * RTX 3090 (24G)! See Quantization of GLM-130B for details.
[2022.08.24] 我们很自豪地发布了 GLM-130B 的量化版本。在保留 FP16 激活精度的同时,模型权重可以量化到低至 INT4 而性能几乎没有下降,进一步将 GLM-130B 的硬件要求降低到具有 4 * RTX 3090(24G)的单服务器!有关详细信息,请参阅 GLM-130B 的量化。
For smaller models, please find monolingual GLMs (English: 10B/2B/515M/410M/335M/110M, Chinese: 10B/335M) and an 1B multilingual GLM (104 languages).
对于较小的模型,请查找单语 GLM(英文:10B/2B/515M/410M/335M/110M,中文:10B/335M)和 1B 多语言 GLM(104 种语言)。
Getting Started 入门
Environment Setup 环境设置
Hardware 硬件
| Hardware 硬件 | GPU Memory 显存 | Quantization 量化 | Weight Offload 重量卸载 |
|---|---|---|---|
| 8 * A100 | 40 GB 40GB | No 不 | No 不 |
| 8 * V100 8*V100 | 32 GB 32GB | No 不 | Yes (BMInf) 是(BMInf) |
| 8 * V100 8*V100 | 32 GB 32GB | INT8 整数8 | No 不 |
| 8 * RTX 3090 8*RTX 3090 | 24 GB 24GB | INT8 整数8 | No 不 |
| 4 * RTX 3090 4*RTX 3090 | 24 GB 24GB | INT4 整数4 | No 不 |
| 8 * RTX 2080 Ti 8 * RTX 2080 钛 | 11 GB 11GB | INT4 整数4 | No 不 |
It is recommended to use the an A100 (40G * 8) server, as all GLM-130B evaluation results (~30 tasks) reported can be easily reproduced with a single A100 server in about half a day. With INT8/INT4 quantization, efficient inference on a single server with 4 * RTX 3090 (24G) is possible, see Quantization of GLM-130B for details. Combining quantization and weight offloading techniques, GLM-130B can also be inferenced on servers with even smaller GPU memory, see Low-Resource Inference for details.
建议使用 A100 (40G * 8) 服务器,因为报告的所有 GLM-130B 评估结果(~30 个任务)可以在大约半天内使用单个 A100 服务器轻松重现。通过 INT8/INT4 量化,可以在具有 4 * RTX 3090(24G)的单个服务器上进行高效推理,详情请参阅 GLM-130B 的量化。结合量化和权重卸载技术,GLM-130B 还可以在具有更小 GPU 内存的服务器上进行推理,有关详细信息,请参阅低资源推理。
Software 软件
The GLM-130B code is built on the top of SAT. We recommend using Miniconda to manage your environment and installing additional dependencies via pip install -r requirements.txt. Here are the recommended environment configurations:
GLM-130B 代码建立在 SAT 之上。我们建议使用 Miniconda 来管理您的环境并通过 pip install -r requirements.txt 安装额外的依赖项。以下是推荐的环境配置:
- Python 3.9+ / CUDA 11+ / PyTorch 1.10+ / DeepSpeed 0.6+ / Apex (installation with CUDA and C++ extensions is required, see here)
Python 3.9+ / CUDA 11+ / PyTorch 1.10+ / DeepSpeed 0.6+ / Apex(需要安装 CUDA 和 C++ 扩展,见此处) - SwissArmyTransformer>=0.2.11 is required for quantization
SwissArmyTransformer >=0.2.11 需要量化
Model weights 模型权重
Download the GLM-130B’s model checkpoint from here, make sure all 60 chunks are downloaded completely, then use the following command to merge them into a single archive file and extract it:
从这里下载 GLM-130B 的模型检查点,确保所有 60 个块都已完全下载,然后使用以下命令将它们合并为一个存档文件并解压缩:
cat glm-130b-sat.tar.part_* > glm-130b-sat.tar
tar xvf glm-130b-sat.tar
Set CHECKPOINT_PATH in configs/model_glm_130b.sh to the path of the extracted folder. Since the checkpoint file is up to 260G, it is recommended to use the SSD or RAM disk to reduce the checkpoint loading time. Since the checkpoint we distribute is in 8-way tensor parallel, a conversion scripts is also provided if you need to change the tensor parallel dimension.
将 configs/model_glm_130b.sh 中的 CHECKPOINT_PATH 设置为解压文件夹的路径。由于checkpoint文件高达260G,建议使用SSD或者RAM盘来减少checkpoint加载时间。由于我们分发的checkpoint是8路tensor parallel,如果需要改变tensor parallel维度,也提供了转换脚本。
python tools/convert_tp.py \
--input-folder <SRC_CKPT_PATH> \
--output-folder <DST_CKPT_PATH> \
--target-tp <TARGET_TP>
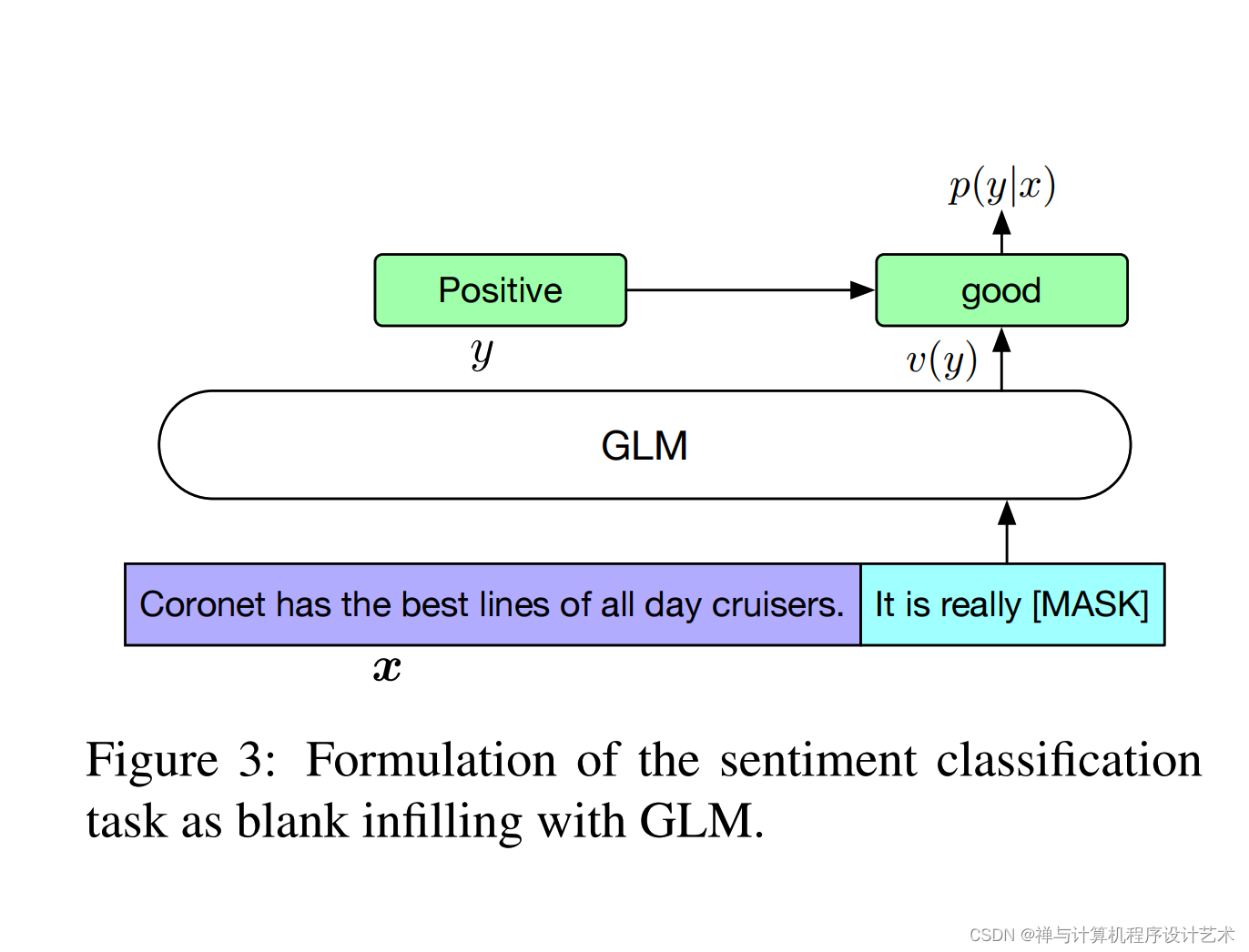
Left-To-Right Generation / Blank Filling
从左到右生成/空白填充
bash scripts/generate.sh --input-source interactive
You can also specify an input file by --input-source input.txt.
您还可以通过 --input-source input.txt 指定输入文件。
GLM-130B uses two different mask tokens: [MASK] for short blank filling and [gMASK] for left-to-right long text generation. When the input does not contain any MASK token, [gMASK] will be automatically appended to the end of the text.
GLM-130B 使用两种不同的掩码标记: [MASK] 用于短空白填充, [gMASK] 用于从左到右的长文本生成。当输入不包含任何 MASK 标记时, [gMASK] 将自动附加到文本末尾。
Left-To-Right Generation Examples
从左到右生成示例
Example 1 示例 1
Input: Who is the greatest artist? The greatest artist is [gMASK]
输入:谁是最伟大的艺术家?最伟大的艺术家是[gMASK]
Output: Who is the greatest artist? The greatest artist is not the one who paints the most beautiful picture, or writes the best poem, or plays the best symphony. The greatest artist is the one whose work has the greatest impact on the lives of others. The Greatest Artist is the artist who inspires us to be our best selves. The Great Artist is not the artist whose work is flawless. The great artist is not one who is perfect. The true great artist has the ability to make us feel something. The artist who makes us feel is the great artist. The art of the great artists is to make you feel something that you have never felt before. The greatness of an artist is in the ability of their work to touch the lives and hearts of others, and to make them feel something they have never experienced before. This is the true greatness of the artist. 2. The Significance of the Great Artist The significance of the greatest artist cannot be overstated. The significance and impact of the art of a great artist cannot even be measured. The impact of a single work of art can change the course of history. A single work can change a person’s life. A work of great art can make you laugh, make you cry, make your heart race, or make you think. A great work of artistic expression has the power to change the way you look at the world. The work of a truly great artist can change your life forever. 3. The Impact of the Greatest Artist The greatest artists have the ability and the power of their art to change people’s lives. They have the power and the ability, through their art, to make people feel something new. The power of the work of the truly great artists cannot be measured, but it can be felt. The greater the impact of an artists work, the greater the power it has to change lives. 4. The Influence of the Art of the Artist The art and the work created by the greatest artists has the potential to change a life. The influence of the artists work cannot be quantified, but is felt by those who experience it. The truly great work has an ability to touch people’ lives in a way that no other work can.
输出:谁是最伟大的艺术家?最伟大的艺术家不是画出最美的图画、写出最好的诗或演奏最好的交响乐的人。最伟大的艺术家是其作品对他人生活产生最大影响的人。最伟大的艺术家是激励我们成为最好的自己的艺术家。伟大的艺术家不是作品完美无缺的艺术家。伟大的艺术家不是完美的。真正伟大的艺术家有能力让我们有所感受。让我们感同身受的艺术家才是伟大的艺术家。伟大艺术家的艺术就是让你感受到你以前从未感受过的东西。艺术家的伟大在于他们的作品能够触及他人的生活和心灵,并让他们感受到他们以前从未体验过的东西。这才是艺术家真正的伟大之处。 2. 伟大艺术家的意义 伟大艺术家的意义怎么强调都不为过。伟大艺术家的艺术的意义和影响甚至无法衡量。一件艺术品的影响可以改变历史进程。一件作品可以改变一个人的一生。一件伟大的艺术作品可以让你发笑,让你哭泣,让你心跳加速,或者让你思考。一件伟大的艺术表现作品具有改变你看待世界的方式的力量。真正伟大的艺术家的作品可以永远改变你的生活。 3. 最伟大艺术家的影响最伟大的艺术家拥有改变人们生活的能力和力量。他们有力量和能力,通过他们的艺术,让人们感受到新的东西。真正伟大的艺术家作品的力量无法衡量,但可以感受到。艺术家作品的影响越大,它改变生活的力量就越大。 4. 艺术家艺术的影响 最伟大的艺术家创作的艺术和作品具有改变生活的潜力。艺术家作品的影响无法量化,但亲身体验的人会感受到。真正伟大的作品能够以其他作品无法触及的方式触动人们的生活。
Example 2 (Chinese) 例二(中文)
Input: 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答: [gMASK]
Output: 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答:避寒的话,建议去海南三亚。 三亚位于海南岛的最南端,是中国最南部的热带滨海旅游城市,中国海滨城市,是中国空气质量最好的城市、全国最长寿地区(平均寿命80岁)。三亚市别称鹿城,又被称为"东方夏威夷",位居中国四大一线旅游城市"三威杭厦"之首,拥有全岛最美丽的海滨风光。三亚拥有被无数城市嫉妒的清新空气,柔和海滩。在沙滩悠闲散步、沐浴傍晚温和阳光,在海边玩耍,在雨林里面呼吸健康,欣赏自然奇观,一切都是那么令人享受。 气候 三亚地处热带,属热带季风气候区域,终年气温高,寒暑变化不大,年平均气温25.5度。三亚最热的月份是6月,平均气温为28.5°C,极端最高气温为35.7°C ,三亚没有明显的冬季,而且冬季更是到海滨旅游的最好时候,所以三亚是全年全天候避寒、消暑、度假、旅游的好地方。不过,三亚最旺的旅游时间是从10月份到农历春节,这个时候的人特别多,房间也不好订,建议最好避开高峰。三亚的三个旅游高峰期是"五一"、"十一"、"春节",这三个节日期间的房价都会上浮几倍,如果你选择了这三个假期来三亚的话要提前一个星期定房和咨询。
Blank Filling Examples 填空实例
Example 1 示例 1
Input: Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.
输入:Ng 是 [MASK] 的兼职教授(前副教授兼斯坦福人工智能实验室或 SAIL 主任)。作为在线教育的先驱,吴恩达共同创立了 Coursera 和 deeplearning.ai。
Output: Ng is an adjunct professor at Stanford University (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.
输出:Ng 是斯坦福大学的兼职教授(曾任斯坦福人工智能实验室或 SAIL 副教授兼主任)。作为在线教育的先驱,吴恩达共同创立了 Coursera 和 deeplearning.ai。
Example 2 (Chinese) 例二(中文)
Input: 凯旋门位于意大利米兰市古城堡旁。1807年为纪念[MASK]而建,门高25米,顶上矗立两武士青铜古兵车铸像。
Output: 凯旋门位于意大利米兰市古城堡旁。1807年为纪念拿破仑胜利而建,门高25米,顶上矗立两武士青铜古兵车铸像。
Arguments Useful in Generation 生成中有用的参数
--input-source [path] or "interactive"The input file's path. It can also be "interactive", which will launch a CLI.--input-source [path] or "interactive"输入文件的路径。它也可以是“交互式的”,这将启动一个 CLI。—-output-path [path]The folder containing the results.—-output-path [path]包含结果的文件夹。—-out-seq-length [int]The maximum sequence length for generation (including context).—-out-seq-length [int]生成的最大序列长度(包括上下文)。—-min-gen-length [int]The minimum generation length for each MASK.—-min-gen-length [int]每个 MASK 的最小生成长度。—-sampling-strategy "BaseStrategy" or "BeamSearchStrategy". The sampling strategy used.—-sampling-strategy "BaseStrategy" or "BeamSearchStrategy"。使用的抽样策略。- For BeamSearchStrategy: 对于 BeamSearchStrategy:
—-num-beams [int]The number of beams.—-num-beams [int]光束的数量。—-length-penalty [float]The maximum sequence length for generation (including context).—-length-penalty [float]生成的最大序列长度(包括上下文)。—-no-repeat-ngram-size [int]Prohibit repeated n-gram generation.—-no-repeat-ngram-size [int]禁止重复n-gram生成。—-print-all-beamPrint the generated results for all beams.—-print-all-beam打印所有光束的生成结果。
- For BaseStrategy: 对于基础策略:
—-top-k [int]Top k sampling.—-top-k [int]前 k 个采样。—-top-p [float]Top p sampling.—-top-p [float]Top p 采样。—-temperature [float]The sampling temperature.—-temperature [float]采样温度。
- For BeamSearchStrategy: 对于 BeamSearchStrategy:
Evaluation 评估
We use the YAML file to define tasks. Specifically, you can add multiple tasks or folders at a time for evaluation, and the evaluation script will automatically collect all YAML files under those folders recursively.
我们使用 YAML 文件来定义任务。具体来说,你可以一次添加多个任务或文件夹进行评估,评估脚本会自动递归收集这些文件夹下的所有YAML文件。
bash scripts/evaluate.sh task1.yaml task2.yaml dir1 dir2 ...
Download our evaluation dataset here, and set DATA_PATH in scripts/evaluate.sh to your local dataset directory. The task folder contains the YAML files for 30+ tasks we evaluated for GLM-130B. Take the CoLA task for example, run bash scripts/evaluate.sh tasks/bloom/glue_cola.yaml, which outputs an accuracy of ~65% for the best prompt and ~57% for the median.
在此处下载我们的评估数据集,并将 scripts/evaluate.sh 中的 DATA_PATH 设置为您本地的数据集目录。任务文件夹包含我们为 GLM-130B 评估的 30 多个任务的 YAML 文件。以 CoLA 任务为例,运行 bash scripts/evaluate.sh tasks/bloom/glue_cola.yaml 时,最佳提示的准确度约为 65%,中位数的准确度约为 57%。
Expected Output 预期产出
Multi-node evaluation can be configured by setting HOST_FILE_PATH(required by the DeepSpeed lanucher) in scripts/evaluate_multiple_node.sh. Set DATA_PATH in scripts/evaluate_multiple_node.sh and run the following command to evaluate all the tasks in ./task directory.
可以通过在 scripts/evaluate_multiple_node.sh 中设置 HOST_FILE_PATH (DeepSpeed lanucher 需要)来配置多节点评估。在 scripts/evaluate_multiple_node.sh 中设置 DATA_PATH 并运行以下命令来评估 ./task 目录中的所有任务。
bash scripts/evaluate_multiple_node.sh ./tasks
See Evaluate Your Own Tasks for details on how to add new tasks.
有关如何添加新任务的详细信息,请参阅评估您自己的任务。
2.5X faster Inference using FasterTransformer
使用 FasterTransformer 的推理速度提高 2.5 倍
By adapting the GLM-130B model to FasterTransfomer, a highly optimized transformer model library by NVIDIA, we can reach up to 2.5X speedup on generation, see Inference with FasterTransformer for details.
通过使 GLM-130B 模型适应 NVIDIA 高度优化的变压器模型库 FasterTransfomer,我们可以将生成速度提高 2.5 倍,有关详细信息,请参阅使用 FasterTransformer 进行推理。
License 执照
This repository is licensed under the Apache-2.0 license. The use of GLM-130B model weights is subject to the Model License.
此存储库根据 Apache-2.0 许可证获得许可。 GLM-130B 模型重量的使用受模型许可的约束。
Citation 引用
If you find our work useful, please consider citing GLM-130B:
如果您觉得我们的工作有用,请考虑引用 GLM-130B:
@inproceedings{
zeng2023glm-130b,
title={{GLM}-130B: An Open Bilingual Pre-trained Model},
author={Aohan Zeng and Xiao Liu and Zhengxiao Du and Zihan Wang and Hanyu Lai and Ming Ding and Zhuoyi Yang and Yifan Xu and Wendi Zheng and Xiao Xia and Weng Lam Tam and Zixuan Ma and Yufei Xue and Jidong Zhai and Wenguang Chen and Zhiyuan Liu and Peng Zhang and Yuxiao Dong and Jie Tang},
booktitle={The Eleventh International Conference on Learning Representations (ICLR)},
year={2023},
url={https://openreview.net/forum?id=-Aw0rrrPUF}
}You may also consider GLM's original work in your reference:
您还可以在参考资料中考虑 GLM 的原创作品:
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}

长江两岸老火锅,共聚山城开发者!We Want You!
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)