
深度学习之图像分割—— deeplabv2基本思想和网络结构以及论文补充
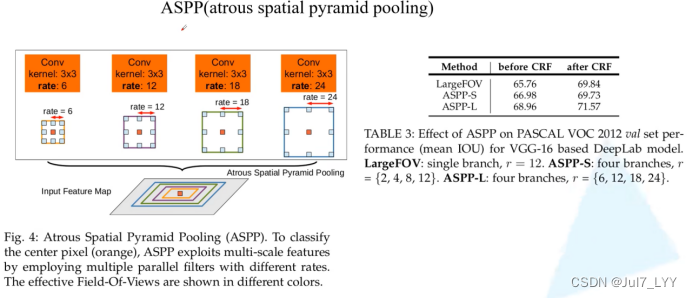
下图是原论文中介绍ASPP的示意图,就是在backbone输出的Feature Map上并联四个分支,每个分支的第一层都是使用的膨胀卷积,但不同的分支使用的膨胀系数不同(即每个分支的感受野不同,从而具有解决目标多尺度的问题)。下图有画出更加详细的ASPP结构(这里是针对VGG网络为例的),将Pool5输出的特征层(这里以VGG为例)并联4个分支,每个分支分别通过一个3x3的膨胀卷积层,1x1的卷积
文章目录
deeplabv2的引入
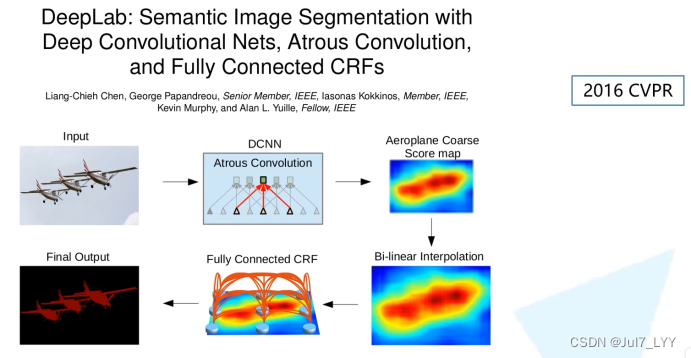
这是一篇2016年发布在CVPR上的文章。接着上一篇DeepLab V1网络,本文对DeepLab V2网络进行简单介绍。相对DeepLab V1,DeepLab V2就是换了个backbone(VGG -> ResNet,简单换个backbone就能涨大概3个点)然后引入了一个新的模块ASPP(Atros Spatial Pyramid Pooling),其他的没太大区别。
1.DCNNs应用在语义分割任务中问题
和上篇文章一样,在文章的引言部分作者提出了DCNNs应用在语义分割任务中遇到的问题。
1.分辨率被降低(主要由于下采样stride>1的层导致)
2.目标的多尺度问题
3.DCNNs的不变性(invariance)会降低定位精度
2.解决办法
1.针对分辨率被降低的问题,一般就是将最后的几个Maxpooling层的stride给设置成1(如果是通过卷积下采样的,比如resnet,同样将stride设置成1即可),然后在配合使用膨胀卷积。
2.针对目标多尺度的问题,最容易想到的就是将图像缩放到多个尺度分别通过网络进行推理,最后将多个结果进行融合即可。这样做虽然有用但是计算量太大了。为了解决这个问题,DeepLab V2 中提出了ASPP模块(atrous spatial pyramid pooling),具体结构后面会讲。
3.针对DCNNs不变性导致定位精度降低的问题,和DeepLab V1差不多还是通过CRFs解决,不过这里用的是fully connected pairwise CRF,相比V1里的fully connected CRF要更高效点。在DeepLab V2中CRF涨点就没有DeepLab V1猛了,在DeepLab V1中大概能提升4个点,在DeepLab V2中大概只能提升1个多点了。
3.DeepLab V2的优势
和DeepLab V1中写的一样:
1.速度更快
2.准确率更高(当时的state-of-art)
3.模型结构简单,还是DCNNs和CRFs联级
4.ASPP(atrous spatial pyramid pooling空洞空间金字塔池化)
下图是原论文中介绍ASPP的示意图,就是在backbone输出的Feature Map上并联四个分支,每个分支的第一层都是使用的膨胀卷积,但不同的分支使用的膨胀系数不同(即每个分支的感受野不同,从而具有解决目标多尺度的问题)。对 Input Feature Map 以不同采样率的空洞卷积并行采样;然后将得到的结果 concat 到一起,扩大通道数;最后通过 1 × 1的卷积将通道数降低到预期的数值。相当于以多个比例捕捉图像的上下文。
注意:连续使用膨胀卷积时,公约数不能大于1,但是在这里是特征融合,属于并联情况所以不牵扯最大公约数的问题。
原因:请参考空洞卷积
在论文中有给出两个ASPP的配置,ASPP-S(四个分支膨胀系数分别为2,4,8,12)和ASPP-L(四个分支膨胀系数分别为6,12,18,24),下表是对比LargeFOV、ASPP-S以及ASPP-L的效果。这里只看CRF之前的(before CRF)对比,ASPP-L优于ASPP-S优于LargeFOV。
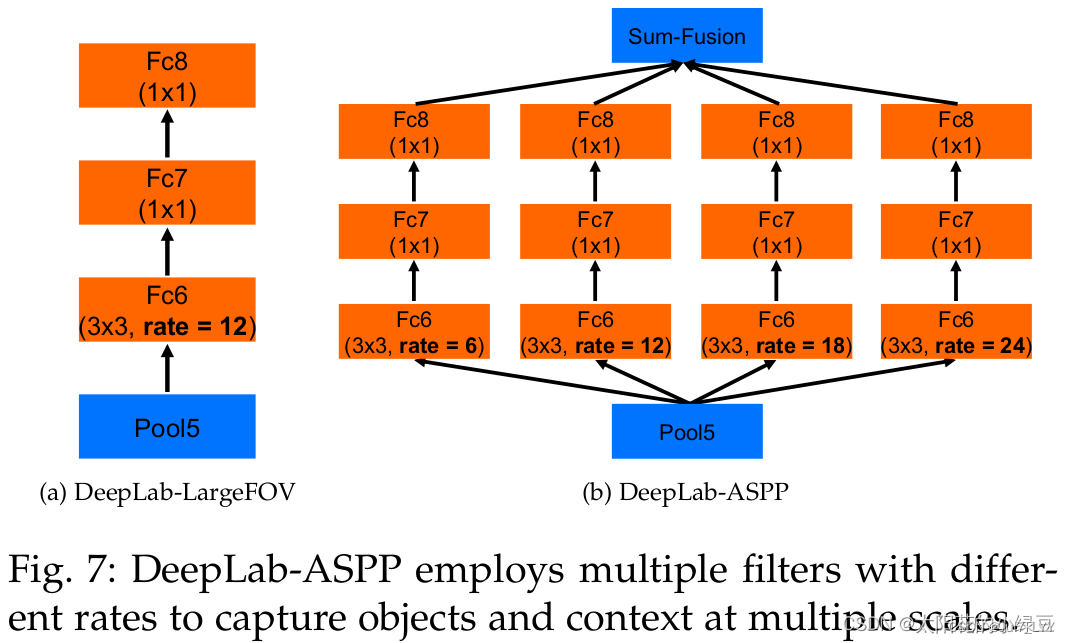
下图有画出更加详细的ASPP结构(这里是针对VGG网络为例的),将Pool5输出的特征层(这里以VGG为例)并联4个分支,每个分支分别通过一个3x3的膨胀卷积层,1x1的卷积层,1x1的卷积层(卷积核的个数等于num_classes)。最后将四个分支的结果进行Add融合即可。 如果是以ResNet101做为Backbone的话,每个分支只有一个3x3的膨胀卷积层,卷积核的个数等于num_classes(看源码分析得到的)。
4.deeplabv2网络结构
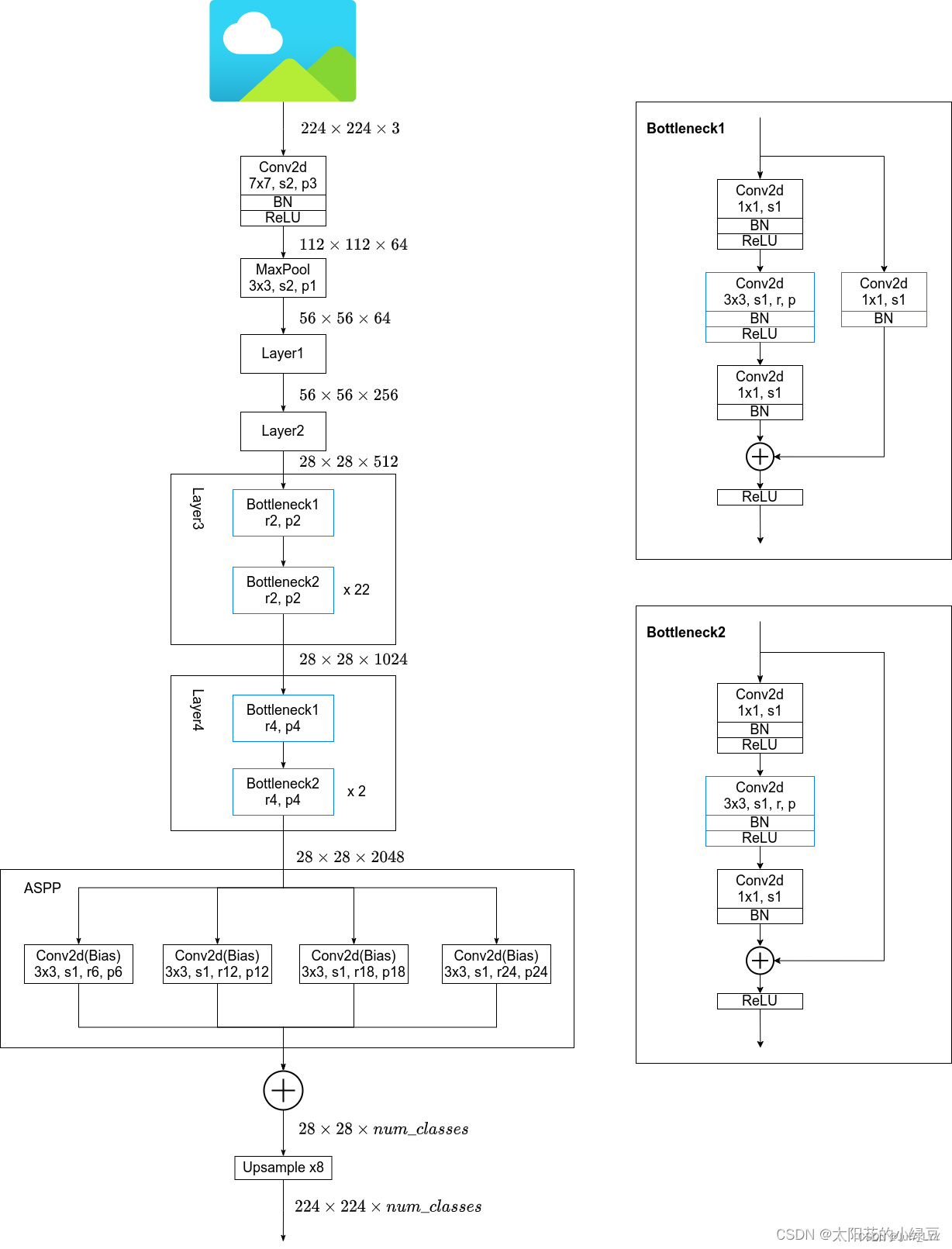
这里以ResNet101作为backbone为例,下图是deeplabv2网络结构(这里不考虑MSC即多尺度)。在ResNet的Layer3中的Bottleneck1中原本是需要下采样的(3x3的卷积层stride=2),但在DeepLab V2中将stride设置为1,即不在进行下采样。而且3x3卷积层全部采用膨胀卷积膨胀系数为2。在Layer4中也是一样,取消了下采样,所有的3x3卷积层全部采用膨胀卷积膨胀系数为4。最后需要注意的是ASPP模块,在以ResNet101做为Backbone时,每个分支只有一个3x3的膨胀卷积层,且卷积核的个数都等于num_classes。
5.学习率调整策略(Learning rate policy)poly
在DeepLab V2中训练时采用的学习率策略叫poly,相比普通的step策略(即每间隔一定步数就降低一次学习率)效果要更好。文中说最高提升了3.63个点。poly学习率变化策略公式如下:
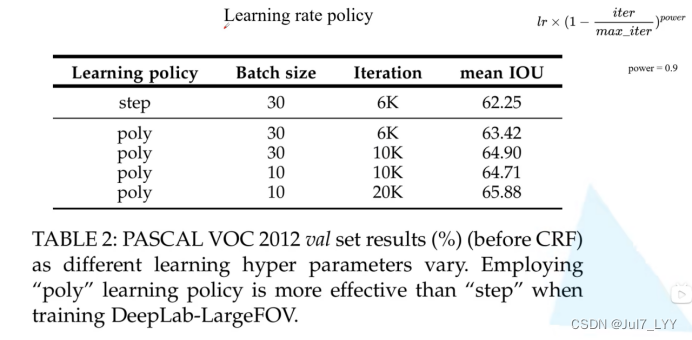 其中lr为初始学习率,iter为当前迭代的step数,max_iter为训练过程中总的迭代步数。
其中lr为初始学习率,iter为当前迭代的step数,max_iter为训练过程中总的迭代步数。
6.消融实验

其中:
1.MSC表示多尺度输入,即先将图像缩放到0.5、0.7和1.0三个尺度,然后分别送入网络预测得到score maps,最后融合这三个score maps(对每个位置取三个score maps的最大值)。
2.COCO就代表在COCO数据集上进行预训练
3.Aug代表数据增强,这里就是对输入的图片在0.5到1.5之间随机缩放。
4.LargeFOV是在DeepLab V1中讲到过的结构。
5.ASPP前面讲过了
6.CRF前面也提到过了

更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)