
论文解析:基于激光雷达的车道线检测 LLDN-GFC---K-Lane: Lidar Lane Dataset and Benchmark for Urban Roads and Highways
车道检测功能是检测本车道和相邻车道的准确位置和曲率,为路径规划功能提供必要的输入。解决了基于图像的车道线检测易受光照影响问题网络结构上通过实验对比选用实时性更友好的基于pillar方式的编码器和GFC形式的特征提取主干网络开源了车道线检测的一整套开发工具包,包括数据、可视化工具、标注工具、模型训练及评测。
1、摘要
车道检测功能是检测本车道和相邻车道的准确位置和曲率,为路径规划功能提供必要的输入。
出发点:
随着大量的基于图像的车道线检测数据集出现,基于摄像头的车道线检测网络发展迅速,但这些算法依赖于图像,图像在消失线附近失真并且容易受光照影响。而基于车道线检测数据集和算法还没有。
贡献点:
- 提出首个大型基于lidar的车道线检测数据集K-Lane,该数据集拥有超过15000帧数据,包含各种道路和交通条件下多达6条车道的标注,例如多种城市和高速道路、昼夜道路、合并或分流道路、直线或曲线道路。
- 基于K-Lane提出一个LLDN-GFC的lidar车道线检测算法,该算法在K-Lane上的F1score达到了82.1%,在各种光照条件和严重遮挡的情况下也表现出很好的性能。
- 开源了全套的车道线检测开发工具链,包含数据集、可视化工具、模型训练评估流程、数据标注工具等。
2、当前技术分析
1、 基于图像的传统车道线检测技术
严重依赖于去噪、边缘检测和线拟合等方法,容易出现车道线部分缺失或被遮挡的情况
2、 基于图像的深度学习车道线检测技术
这类方法通常要投影到BEV视角,这样在图像消失线附近的BEV投影,检测到的车道线不准确或者扭曲,且图像易受光照影响,因此限制了路径规划的可控范围。
3、 基于激光雷达的车道线检测技术
通过反射率阈值或者通过聚类的方法进行车道线检测,这些方法泰国依赖于固定的参数,只适合固定场景。
且受限于数据集较少,技术发展缓慢。
4、 基于lidar和camera的车道线检测技术
利用CNN从点云中预测密集的BEV高度估计,然后与BEV图像融合,进行车道检测
但这种方法无法区分不同的车道类型。
3、激光雷达车道线检测数据集
3.1、 其他数据集
1、基于图像的
TuSimple:第一个基于摄像头的车道线数据集(6408帧)
CULane:更多样化、难度更大的基于摄像头的车道线数据集(133235帧)
2、基于激光雷达的
DeepLane:城市和高速道路(55168帧)
RoadNet:高速公路(5200帧)
K-Lane:城市和高速公路、白天夜间、直线曲线、多车道(15382帧)
3.2、K-Lane
包含不同场景如城市和高速道路、不同光照如白天和夜间、不同车道去直线和曲线、不同遮挡程度
其中车道数量最多包含6条,种类有:直线、平缓曲线、合并(汇合与分叉)和急转弯
遮挡程度分级:遮挡分为6个等级,分别用0、1、2、3、4、5
4、车道线检测网络
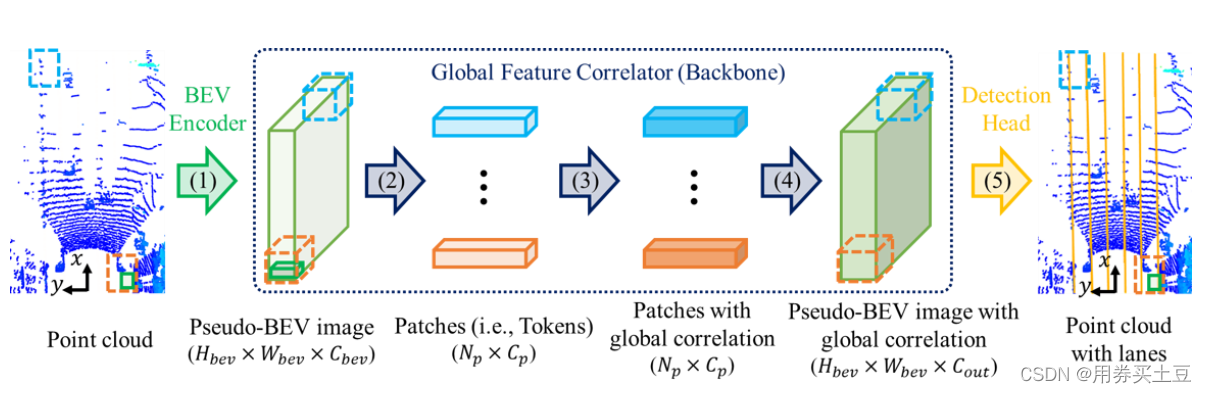
网络框架预览
图解
(1)表示:BEV编码器
(2)表示:reshape与per-patch线性转换
(3)表示:特征提取主干网络(Transformer或者Mixer Block)
(4)表示:reshape与共享MLP
(5)表示:检测头
4.1、BEV编码器
两种方式:
1、将点云投影到xy水平平面上,利用CNN(基于resnet)生成BEV特征图,输出特征图是输入伪图像的1/64。
2、以pillar的形式编码点云,网格大小和1相同,性能略差,但推理速度快。
对比之后,本文选用2:以pillar的形式进行点云编码。
4.2、特征提取Backbone
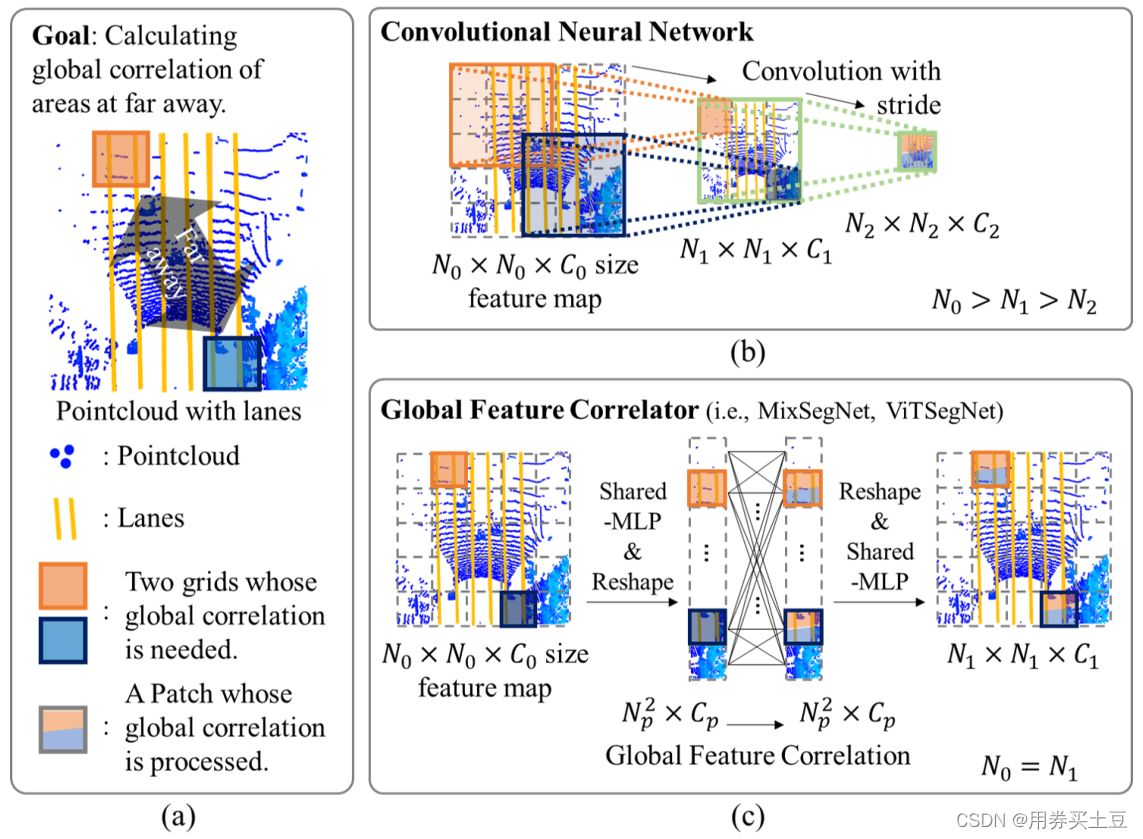
图解
(a)计算两个较远网格相关性示意图
(b)通过CNN计算,特征图中两个网格的变化
©通过GFC(例如MixSegNet、ViTSegNet等)计算,特征图中两个网格的变化
N0, N1, N2按深度顺序分别表示三层特征图的大小
C0, C1, C2按深度顺序分别表示三层特征图的通道数
最终选用GFC
理由:
- 如上图所示,道路上的车道线较细,沿整个点云延伸,仅占用少量像素(即稀疏)。由于这种薄性和稀疏性,需要在高分辨率下进行特征提取。
- 基于CNN的特征提取主干网络在经过几层卷积和下采样后,可能会发现远处网格之间的相关性,但降低了特征图的分辨率。
- 在定量和定性上,如下图、表所示,可以观察到,与基于CNN的网络相比,patch-wise自注意网络具有更高的性能。
![[图片]](https://img-blog.csdnimg.cn/6e65bd734845492cba09dbb126b15ad5.png)
RNF 表示带有 FPN 的ResNet
S13表示用13层的跨步卷积实现的残差块
D23表示用23层的空洞卷积实现的残差块
C13分别表示用13的CBAM实现的残差块(CBAM:Convolutional Block Attention Model)
![[图片]](https://img-blog.csdnimg.cn/fb69276b1dab4e84ac325ec592a86bc3.png)
中间结果的可视化图
第一行是推理结果在左上角有标签的前视图图像上的投影,
第二行是在BEV点云上的推理,
从第三行到第五行,分别表示沿着骨干的第1、2和3块输出特征图的通道采样的热力图(例如,GFC的第1、2和3个Transformer块或RNF的剩余块)。
![[图片]](https://img-blog.csdnimg.cn/cca9b892dd29443da841a8d10029c49f.png)
注意力分数的可视化图
a 上 表示推理结果在前视摄像头图像上的投影
a 下 表示点云上的推理结果和query patch
b c d 分别表示GFC第1、2、3块的注意评分(紫色)。其中:BEV中的点云(蓝色)、车道推断结果(黄、红、绿色)、query patch(黄色方框)、标签(青色)
4.3、检测头
为了检测车道线的类别和形状,本文将车道线检测问题转化为多类别分割问题,每个像素进行分类和置信度打分
具体为:
检测头由两个分割头组成
每个分割头由两层共享mlp序列组成
中间为非线性激活。
4.4、损失函数
1、 soft dice loss
由于每帧数据中,车道线的样本量远小于背景样本数量,所以采用soft dice loss解决不平衡的置信度损失
Dice loss是针对前景比例太小的问题提出的,dice系数源于二分类,本质上是衡量两个样本的重叠部分。
![[图片]](https://img-blog.csdnimg.cn/425d903e3dc545879ebb0ff902606036.png)
分子代表集合A和B之间的公共元素,并且|A|代表集合A中的元素数量(对于集合B同理)。
对于在预测的分割掩码上评估 Dice 系数,我们可以将 |A∩B| 近似为预测掩码和标签掩码之间的逐元素乘法,然后对结果矩阵求和。
![[图片]](https://img-blog.csdnimg.cn/ffee2b2aaede47ff9b9ec8d14fd0bc74.png)
计算 Dice 系数的分子中有一个2,那是因为分母中对两个集合的元素个数求和,两个集合的共同元素被加了两次。 为了设计一个可以最小化的损失函数,可以简单地使用1−Dice。 这种损失函数被称为 soft Dice loss,这是因为我们直接使用预测出的概率,而不是使用阈值将其转换成一个二进制掩码。
对于每个类别的mask,都计算一个 Dice 损失:
![[图片]](https://img-blog.csdnimg.cn/3179b1fdbc974eec83f353339dba5ab1.png)
将每个类的 Dice 损失求和取平均,得到最后的 Dice soft loss。
dice loss分为前景loss和物体loss,在现实中我们只关心物体loss。
那么loss:
![[图片]](https://img-blog.csdnimg.cn/b5b533065e53420199919fa64a562f7d.png)
def dice_loss(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3])
return 1-K.mean( (2. * intersection + smooth) / (union + smooth), axis=0)
2、cross-entropy loss
对于分类,选用cross-entropy loss
![[图片]](https://img-blog.csdnimg.cn/0116cf2b62a4498e9d10668f01abff1a.png)
其中 a=σ(z), where z=wx+b
利用SGD等算法优化损失函数,通过梯度下降法改变参数从而最小化损失函数:
对两个参数权重和偏置进行求偏导:
![[图片]](https://img-blog.csdnimg.cn/48c95dcc16e649f0a99662884174e480.png)
![[图片]](https://img-blog.csdnimg.cn/9a2f46bf38ee4b16bca28460c5b14f69.png)
3、总的损失函数
total loss = soft dice loss + cross-entropy loss
5、总结
5.1、优点
- 解决了基于图像的车道线检测易受光照影响问题
- 网络结构上通过实验对比选用实时性更友好的基于pillar方式的编码器和GFC形式的特征提取主干网络
- 开源了车道线检测的一整套开发工具包,包括数据、可视化工具、标注工具、模型训练及评测
5.2、缺点
- 将点云编码为伪图像后,划分网格,在最后的检测头通过Share-MLP处理每一个网格,计算成本比较高

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)