

DataX简介、部署、原理和使用介绍
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效
DataX简介、部署、原理和使用介绍
1.DataX简介
1-1.项目地址
项目地址:https://github.com/alibaba/DataX
官方文档:https://github.com/alibaba/DataX/blob/master/introduction.md
1-2.DataX概述
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通
1-3.DataX支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 阿里云图数据库 | GDB | √ | √ | 读 、写 |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | 写 | ||
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
1-4.DataX特点
- 可靠的数据质量监控
- 丰富的数据转换功能
- 精准的速度控制
- 强劲的同步性能
- 健壮的容错机制
- 极简的使用体验
2.DataX原理
2-1.DataX设计理念
- 异构数据源同步问题,就是不同框架之间同步数据时,相同的数据在不同框架中具有不同的数据结构。
- DataX的设计理念:
DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接数据各种数据源。
当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
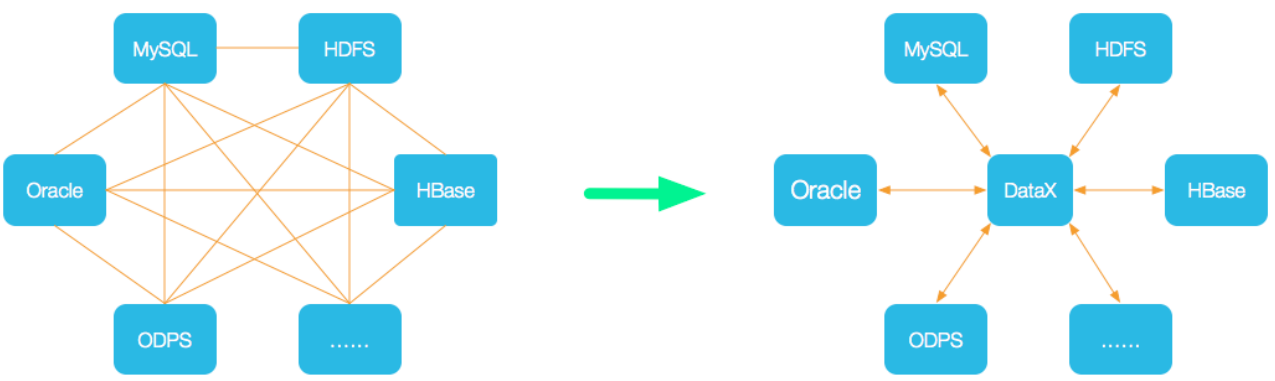
2-2.DataX框架设计
DataX本身作为离线数据同步框架,采用Framework+plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中

-
Reader
- 数据采集模块,负责采集数据源的数据,将数据发送给Framework
-
Writer
- 数据写入模块,负责不断从Framework取数据,并将数据写出到目的端。
-
Framework
- 主题框架,用于连接Reader和Writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题
Framework的几大功能
- 缓冲
Reader 和 Writer 可能会有读写速度不一致的情况,所以中间需要一个组件作为缓冲
- 流控
控制数据传输的速度,DataX 可以随意根据需求调整数据传输速度
- 并发
并发的同步或写入数据
- 数据转换
既然是异构,那么说明读 Reader 的数据源与 写 Writer 的数据源 数据结构可能不同,数据结构不同的话,需要做数据转换操作,转换也在 Framework 中完成
2-3.DataX运行流程
DataX支持单机多线程模式完成同步作业,下面用一个DataX作业生命周期的时序图,用以说明DataX的运行流程、核心概念以及每个概念的关系
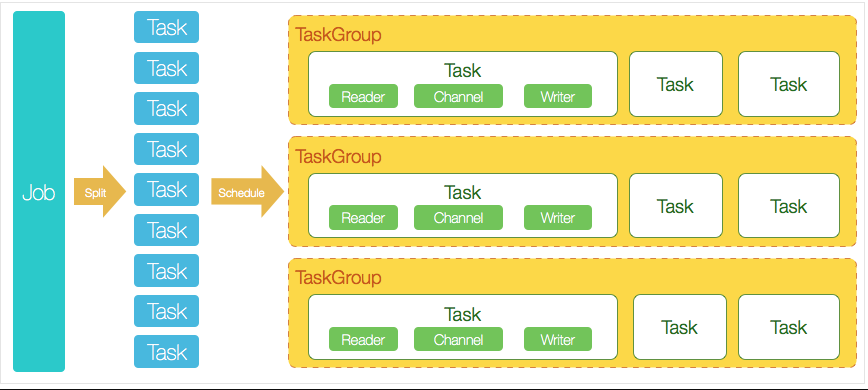
- 核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
2-4.DataX调度策略
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
3.DataX安装部署
# 下载安装包
[wangting@hdt-dmcp-ops05 ~]$ cd /opt/software/
[wangting@hdt-dmcp-ops05 software]$ wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz
# 解压安装包
[wangting@hdt-dmcp-ops05 software]$ tar -xf datax.tar.gz -C /opt/module
[wangting@hdt-dmcp-ops05 software]$ cd /opt/module/datax/
# DataX自检任务
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py job/job.json
2023-02-15 19:01:48.489 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-15 19:01:38
任务结束时刻 : 2023-02-15 19:01:48
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
# 成功执行自检任务
4.DataX使用介绍
4-1.同步MySQl全量数据到HDFS案例
将MySQL的全量数据,利用DataX工具同步至HDFS
1.查看MySQL被迁移的数据情况
2.根据需求确定reader为mysqlreader,writer为hdfswriter
查看reader和writer模板的方式(-r 读模板; -w 写模板):
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py -r mysqlreader -w hdfswriter
3.编写同步json脚本
4.确定HDFS上目标路径是否存在
5.通过datax.py指定json任务运行同步数据
6.数据验证,查看HDFS上是否已经有MySQL对应表中的所有数据
这里先跑通一个实验案例,再根据操作来总结
- MySQL数据:
[wangting@hdt-dmcp-ops05 ~]$ mysql -uroot -p123456 -Dwangtingdb
mysql> select * from test;
+------+---------+
| id | name |
+------+---------+
| 1 | wang111 |
| 2 | wang222 |
| 3 | wang333 |
+------+---------+
3 rows in set (0.00 sec)
- 同步任务定义:
[wangting@hdt-dmcp-ops05 datax]$ vim job/mysql2hdfs.json
mysql2hdfs.json内容:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hdt-dmcp-ops05:3306/wangtingdb"],
"table": ["test"]
}
],
"password": "123456",
"username": "root",
"splitPk": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name": "id","type": "bigint"},
{"name": "name","type": "string"}
],
"compress": "gzip",
"defaultFS": "hdfs://hdt-dmcp-ops01:8020",
"fieldDelimiter": "\t",
"fileName": "test",
"fileType": "text",
"path": "/test",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 任务执行:
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -mkdir /test
2023-02-15 19:25:04,683 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py job/mysql2hdfs.json
...
...
2023-02-15 19:25:43.656 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.022s | 0.022s | 0.022s
PS Scavenge | 1 | 1 | 1 | 0.010s | 0.010s | 0.010s
2023-02-15 19:25:43.656 [job-0] INFO JobContainer - PerfTrace not enable!
2023-02-15 19:25:43.656 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 24 bytes | Speed 2B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s| All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-02-15 19:25:43.657 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-15 19:25:32
任务结束时刻 : 2023-02-15 19:25:43
任务总计耗时 : 11s
任务平均流量 : 2B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
- 验证
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -ls /test
2023-02-15 19:28:48,080 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
-rw-r--r-- 3 wangting supergroup 43 2023-02-15 19:25 /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -get /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz ~/
2023-02-15 19:29:41,378 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2023-02-15 19:29:41,786 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[wangting@hdt-dmcp-ops05 datax]$ cd ~
[wangting@hdt-dmcp-ops05 ~]$ ll
total 8
drwxrwxr-x 2 wangting wangting 4096 Feb 15 15:13 bin
-rw-r--r-- 1 wangting wangting 43 Feb 15 19:29 test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
[wangting@hdt-dmcp-ops05 ~]$ gunzip test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
[wangting@hdt-dmcp-ops05 ~]$ ll
total 8
drwxrwxr-x 2 wangting wangting 4096 Feb 15 15:13 bin
-rw-r--r-- 1 wangting wangting 30 Feb 15 19:29 test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4
[wangting@hdt-dmcp-ops05 ~]$ cat test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4
1 wang111
2 wang222
3 wang333
截至到这里,可以看到最终数据文件的内容和原MySQL数据匹配的上
总结:
**MysqlReader插件介绍:**实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的SQL语句将数据从mysql库中select出来。
**MysqlReader插件原理:**MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
**HdfsWriter插件介绍:**提供项HDFS文件系统指定路径中写入TextTile和OrcFile类型的文件,文件内容可与Hive表相关联。
**HdfsWriter:**插件实现过程:首先根据用户指定的path,创建一个hdfs文件系统上的不存在的临时目录,创建规则是:path_随机;然后将读取的文件写入到这个临时目录中;待到全部写入后,再将这个临时目录下的文件移动到用户所指定的目录下,(在创建文件时保证文件名不重复);最后删除临时目录。如果在中间过程中发生网络中断等情况,造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录
4-2.同步MySQl需求数据到HDFS案例(where)
相对上个案例的变化:
1.增加了
where关键词,过滤同步的数据范围2.去除了压缩格式:
"compress": "gzip"3.更换了分隔符,由原
\t变成不可见分隔字符\u0001
[wangting@hdt-dmcp-ops05 datax]$ vim job/mysql2hdfs_2.json
mysql2hdfs_2.json脚本内容:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hdt-dmcp-ops05:3306/wangtingdb"],
"table": ["test"]
}
],
"password": "123456",
"username": "root",
"where": "id>=2",
"splitPk": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name": "id","type": "bigint"},
{"name": "name","type": "string"}
],
"defaultFS": "hdfs://hdt-dmcp-ops01:8020",
"fieldDelimiter": "\u0001",
"fileName": "test",
"fileType": "text",
"path": "/test",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行任务:
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py job/mysql2hdfs_2.json
...
...
2023-02-16 10:37:05.503 [job-0] INFO JobContainer - PerfTrace not enable!
2023-02-16 10:37:05.504 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 16 bytes | Speed 1B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s| All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-02-16 10:37:05.505 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-16 10:36:54
任务结束时刻 : 2023-02-16 10:37:05
任务总计耗时 : 11s
任务平均流量 : 1B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
验证:
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -ls /test
2023-02-16 10:37:45,122 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 2 items
-rw-r--r-- 3 wangting supergroup 20 2023-02-16 10:36 /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
-rw-r--r-- 3 wangting supergroup 43 2023-02-15 19:25 /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -cat /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
2023-02-16 10:38:07,714 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2023-02-16 10:38:08,111 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2wang222
3wang333
可以看到只有满足id>=2的2条数据被写入到了HDFS,直接看似乎没有分隔符,字符相连了,把文件下载到本地再次验证
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -get /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224 ~/
2023-02-16 10:38:39,679 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2023-02-16 10:38:40,079 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[wangting@hdt-dmcp-ops05 datax]$ vim ~/test__00adf34b_234b_49d8_8ba6_bd3b94881224
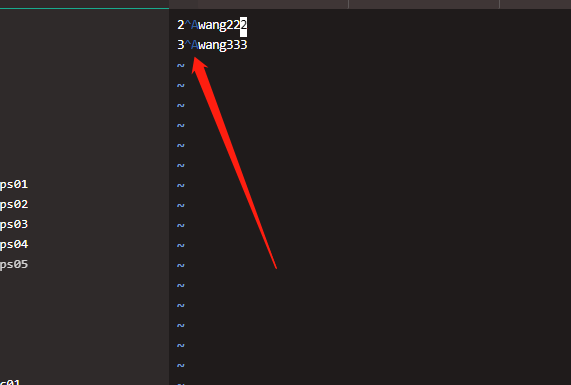
注意,
cat文件是看不到特殊分隔符的
4-3.同步MySQl需求数据到HDFS案例(传条件参数)
在生产环境中,离线数据同步任务需要在任务调度平台每日定时重复执行去拉取某个时间窗口的数据,例如每日同步T-1的数据到HDFS,但脚本中如果写了固定日期,每日任务都需要修改日期条件,显然不合理。因此为实现这个业务需求,需要使用DataX的传参功能。
创建测试表:
[wangting@hdt-dmcp-ops05 datax]$ mysql -uroot -p123456
mysql> use wangtingdb;
mysql> create table test_2(id int(11),name varchar(20),updated datetime);
insert into test_2 value(1,"wangting111","2023-02-13 15:13:42");
insert into test_2 value(2,"wangting222","2023-02-13 21:22:12");
insert into test_2 value(3,"wangting333","2023-02-14 09:15:04");
insert into test_2 value(4,"wangting444","2023-02-14 18:00:32");
insert into test_2 value(5,"wangting555","2023-02-15 13:44:30");
insert into test_2 value(6,"wangting666","2023-02-15 22:13:41");
insert into test_2 value(7,"wangting777","2023-02-16 12:22:30");
insert into test_2 value(8,"wangting888","2023-02-16 23:14:52");
mysql> select * from test_2;
+------+-------------+---------------------+
| id | name | updated |
+------+-------------+---------------------+
| 1 | wangting111 | 2023-02-13 15:13:42 |
| 2 | wangting222 | 2023-02-13 21:22:12 |
| 3 | wangting333 | 2023-02-14 09:15:04 |
| 4 | wangting444 | 2023-02-14 18:00:32 |
| 5 | wangting555 | 2023-02-15 13:44:30 |
| 6 | wangting666 | 2023-02-15 22:13:41 |
| 7 | wangting777 | 2023-02-16 12:22:30 |
| 8 | wangting888 | 2023-02-16 23:14:52 |
+------+-------------+---------------------+
8 rows in set (0.01 sec)
当前时间为20230216,
拟定2个变量:
START_FLAG=date -d"1 day ago" +%Y%m%d
END_FLAG=date +%Y%m%d
[wangting@hdt-dmcp-ops05 datax]$ date -d"1 day ago" +%Y%m%d
20230215
[wangting@hdt-dmcp-ops05 datax]$ date +%Y%m%d
20230216
编写同步脚本任务
[wangting@hdt-dmcp-ops05 datax]$ vim job/mysql2hdfs_3.json
mysql2hdfs_3.json脚本任务内容:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name","updated"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hdt-dmcp-ops05:3306/wangtingdb"],
"table": ["test_2"]
}
],
"password": "123456",
"username": "root",
"where": "updated>=${START_FLAG} AND updated<${END_FLAG}",
"splitPk": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name": "id","type": "bigint"},
{"name": "name","type": "string"}
{"name": "updated","type": "string"}
],
"defaultFS": "hdfs://hdt-dmcp-ops01:8020",
"fieldDelimiter": "\t",
"fileName": "test",
"fileType": "text",
"path": "/test",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
"where": "updated>=${START_FLAG} AND updated<${END_FLAG}"相当于updated大于等于2023-02-15 00:00:00,小于2023-02-16 00:00:00的数据
当前日期为2月16日,则意为着数据是前一天日内的全量数据
执行任务:
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py -p "-DSTART_FLAG=`date -d"1 day ago" +%Y%m%d` -DEND_FLAG=`date +%Y%m%d`" job/mysql2hdfs_3.json
2023-02-16 16:58:22.742 [job-0] INFO JobContainer - PerfTrace not enable!
2023-02-16 16:58:22.742 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 40 bytes | Speed 4B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s| All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-02-16 16:58:22.743 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-16 16:58:11
任务结束时刻 : 2023-02-16 16:58:22
任务总计耗时 : 11s
任务平均流量 : 4B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
验证数据:
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -ls /test
2023-02-16 16:58:37,819 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 3 items
-rw-r--r-- 3 wangting supergroup 20 2023-02-16 10:36 /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
-rw-r--r-- 3 wangting supergroup 43 2023-02-15 19:25 /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
-rw-r--r-- 3 wangting supergroup 68 2023-02-16 16:58 /test/test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -cat /test/test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4
2023-02-16 16:58:49,450 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2023-02-16 16:58:49,845 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
5 wangting555 2023-02-15 13:44:30
6 wangting666 2023-02-15 22:13:41
可以看到数据只收取到了T-1日的2条数据
4-4.同步HDFS数据到MySQL案例
准备HDFS文件目录
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -ls /test
2023-02-16 17:17:50,778 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 3 items
-rw-r--r-- 3 wangting supergroup 20 2023-02-16 10:36 /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
-rw-r--r-- 3 wangting supergroup 43 2023-02-15 19:25 /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
-rw-r--r-- 3 wangting supergroup 68 2023-02-16 16:58 /test/test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -rm /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
2023-02-16 17:18:15,296 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Deleted /test/test__00adf34b_234b_49d8_8ba6_bd3b94881224
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -rm /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
2023-02-16 17:18:31,868 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Deleted /test/test__34c4b765_ecd9_426f_b64e_96ef6f9dbba4.gz
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -ls /test
2023-02-16 17:18:45,837 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
-rw-r--r-- 3 wangting supergroup 68 2023-02-16 16:58 /test/test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4
[wangting@hdt-dmcp-ops05 datax]$ hdfs dfs -cat /test/test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4
2023-02-16 17:18:56,387 INFO Configuration.deprecation: No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2023-02-16 17:18:56,791 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
5 wangting555 2023-02-15 13:44:30
6 wangting666 2023-02-15 22:13:41
# /test目录下有一个test__4ffd9840_bc1f_4370_88ab_75d9ee97f1f4文件
# 文件中有2条数据
创建MySQL被导入的测试表
[wangting@hdt-dmcp-ops05 datax]$ mysql -uroot -p123456 -Dwangtingdb;
mysql> create table test_666 like test_2;
Query OK, 0 rows affected (0.01 sec)
mysql> desc test_666;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| updated | datetime | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> select * from test_666;
Empty set (0.00 sec)
# 当前test_666表为空,没有数据
[wangting@hdt-dmcp-ops05 datax]$ vim job/hdfs2mysql.json
hdfs2mysql.json任务内容:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/test",
"defaultFS": "hdfs://hdt-dmcp-ops01:8020",
"column": [
{"index":0,"type":"string"},
{"index":1,"type":"string"},
{"index":2,"type":"string"}
],
"fileType": "text",
"encoding": "UTF-8",
"nullFormat": "\\N",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"updated"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hdt-dmcp-ops05:3306/wangtingdb?useUnicode=true&characterEncoding=utf-8",
"table": [
"test_666"
]
}
]
}
}
}
]
}
}
执行任务:
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py job/hdfs2mysql.json
2023-02-16 17:19:56.672 [job-0] INFO JobContainer - PerfTrace not enable!
2023-02-16 17:19:56.673 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 62 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s| All Task WaitReaderTime 0.004s | Percentage 100.00%
2023-02-16 17:19:56.674 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-16 17:19:45
任务结束时刻 : 2023-02-16 17:19:56
任务总计耗时 : 11s
任务平均流量 : 6B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
验证查看MySQL
[wangting@hdt-dmcp-ops05 datax]$ mysql -uroot -p123456 -Dwangtingdb -e "select * from test_666;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+------+-------------+---------------------+
| id | name | updated |
+------+-------------+---------------------+
| 5 | wangting555 | 2023-02-15 13:44:30 |
| 6 | wangting666 | 2023-02-15 22:13:41 |
+------+-------------+---------------------+
4-5.同步CSV文件数据倒MySQL案例
- 准备一个csv文件用于同步数据
[wangting@hdt-dmcp-ops05 ~]$ cd /opt/module/datax/job/huatong_data/
[wangting@hdt-dmcp-ops05 huatong_data]$ vim prefecture_level_city_quarter.csv
"dbcode","code","cname","ayearmon","regcode","regname","cunit",data,"updatetime"
"djsjd","A0302","社会消费品零售总额_累计增长","2021D","511000","内江市","%",18.2,"2022-02-20 09:29:00"
"djsjd","A0302","社会消费品零售总额_累计增长","2021C","511000","内江市","%",21.1,"2021-11-08 08:14:05"
"djsjd","A0302","社会消费品零售总额_累计增长","2021B","511000","内江市","%",25.1,"2021-07-29 07:23:33"
"djsjd","A0302","社会消费品零售总额_累计增长","2021A","511000","内江市","%",29.9,"2021-07-29 07:23:30"
"djsjd","A0302","社会消费品零售总额_累计增长","2020D","511000","内江市","%",-3.2,"2021-08-02 11:42:00"
"djsjd","A0302","社会消费品零售总额_累计增长","2020B","511000","内江市","%",-7.9,"2021-08-02 11:41:56"
"djsjd","A0302","社会消费品零售总额_累计增长","2020A","511000","内江市","%",-11.9,"2021-08-02 11:41:55"
"djsjd","A0301","社会消费品零售总额_累计值","2021C","511000","内江市","亿元",446.38,"2021-11-08 08:14:05"
"djsjd","A0301","社会消费品零售总额_累计值","2020B","511000","内江市","亿元",232.43,"2021-08-02 11:41:56"
"djsjd","A0301","社会消费品零售总额_累计值","2020A","511000","内江市","亿元",106.81,"2021-08-02 11:41:55"
"djsjd","A0202","城镇常住居民人均可支配收入_累计增长","2016D","511000","内江市","%",8.53,"2018-12-13 05:21:45"
"djsjd","A0202","城镇常住居民人均可支配收入_累计增长","2022A","511000","内江市","%",6.4,"2022-05-11 02:11:47"
"djsjd","A0202","城镇常住居民人均可支配收入_累计增长","2021D","511000","内江市","%",8.9,"2022-05-27 02:14:21"
"djsjd","A0202","城镇常住居民人均可支配收入_累计增长","2021D","511000","内江市","%",8.9,"2022-02-23 08:23:30"
"djsjd","A0202","城镇常住居民人均可支配收入_累计增长","2021C","511000","内江市","%",9.8,"2022-02-23 09:49:27"
这里只提供部分样例数据用于调试
- 创建MySQL库表用于写入数据
-- 创建db
CREATE DATABASE `huatongdata`;
use huatongdata;
-- 创建地级市季度表
create table prefecture_level_city_quarter(
dbcode varchar(50) comment "维度码",
code varchar(200) comment "指标编码",
cname varchar(200) comment "指标名称",
ayearmon varchar(50) comment "时间期",
regcode varchar(50) comment "地区编码",
regname varchar(200) comment "地区名称",
cunit varchar(80) comment "计量单位",
`data` decimal(38,8) comment "数值",
updatetime datetime comment "更新时间"
) comment "地级市季度表";
-- 刚创建的表目前为空
mysql> select * from prefecture_level_city_quarter;
Empty set (0.00 sec)
- 编写任务脚本
[wangting@hdt-dmcp-ops05 datax]$ vim job/csv2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/opt/module/datax/job/huatong_data/prefecture_level_city_quarter.csv"],
"encoding":"utf-8",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
},
{
"index": 5,
"type": "string"
},
{
"index": 6,
"type": "string"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "string"
}
],
"skipHeader": "true"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"dbcode",
"code",
"cname",
"ayearmon",
"regcode",
"regname",
"cunit",
"data",
"updatetime"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hdt-dmcp-ops05:3306/huatongdata?useUnicode=true&characterEncoding=utf8",
"table": ["prefecture_level_city_quarter"]
}
],
"password": "123456",
"username": "root",
"preSql":[""],
"session":["set session sql_mode='ANSI'"],
"writeMode":"insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- 执行同步任务
[wangting@hdt-dmcp-ops05 datax]$ python bin/datax.py job/csv2mysql.json
...
...
2023-02-17 10:36:17.020 [job-0] INFO JobContainer - PerfTrace not enable!
2023-02-17 10:36:17.021 [job-0] INFO StandAloneJobContainerCommunicator - Total 173559 records, 10806586 bytes | Speed 1.03MB/s, 17355 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 3.118s | All Task WaitReaderTime 0.268s | Percentage 100.00%
2023-02-17 10:36:17.022 [job-0] INFO JobContainer -
任务启动时刻 : 2023-02-17 10:36:06
任务结束时刻 : 2023-02-17 10:36:17
任务总计耗时 : 10s
任务平均流量 : 1.03MB/s
记录写入速度 : 17355rec/s
读出记录总数 : 173559
读写失败总数 : 0
读出记录总数 : 173559
说明本次任务同步到MySQL涉及到173559行
- 验证
# 登录MySQL查询刚创建的prefecture_level_city_quarter地级市季度表查看数据量
mysql> select count(*) from prefecture_level_city_quarter;
+----------+
| count(*) |
+----------+
| 173559 |
+----------+
1 row in set (0.05 sec)
和datax记录总数可以对上,说明CSV文件全部都同步到MySQL
5.DataX常见的参数设置
5-1.加速相关配置
| 参数 | 说明 | 注意事项 |
|---|---|---|
| job.setting.speed.channel | 设置并发数 | |
| job.setting.speed.record | 总record限速 | 配置此参数,则必须配置单个channel的record限速参数 |
| job.setting.speed.byte | 总byte限速 | 配置此参数,则必须配置单个channel的byte限速参数 |
| core.transport.channel.speed.record | 单个channel的record限速,默认10000条/s |
【注意】:如果配置了总record限速和总byte限速,channel并发数就会失效。因为配置了这两个参数后,实际的channel并发数是通过计算得到的
5-2.运行内存调整
当提升DataX Job内的Channel并发数时,内存的占用会明显增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。
例如:channel中会有一个Buffer,作为临时的数据交换缓冲区,而在Reader和Write中,也会有一些buffer,为了防止OOM等错误,需要适当调大JVM堆内存
- 永久修改
修改datax.py
# 找到DEFAULT_JVM相关内容更改:-Xms1g -Xmx1g
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
- 当前任务修改
启动时使用参数:python bin/datax.py --jvm = "-Xms8G -Xmx8G” job.json

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)