
Shell脚本之文本处理三剑客——grep(含正则表达式详解)
简要介绍grep命令的常用选项,详细介绍了正则表达式内容
·
目录
一.grep命令选项详解
grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
选项介绍:
| -m | 匹配几次后停止 |
| -v | 反选 |
| -i | 忽略字符大小写 |
| -n | 显示匹配行号 |
| -c | 统计匹配行数 |
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式 |
| -A | 后几行 |
| -B | 前几行 |
| -C | 前后各几行 |
| -e | 多个选项之间“或者”关系 |
| -w | 匹配整个单词 |
| -E | 启用扩展正则表达式 =egrep |
| -F | 不支持正则表达式 =fgrep |
| -f | 处理两个文件的相同内容,以第一个文件作为匹配条件 |
| -r | 递归,但不处理软链接 |
| -R | 递归,处理软链接 |
示例1:统计lsblk命令显示中磁盘总个数
lsblk |grep disk |wc -l示例2:在大量文件中快速过滤/etc/文件夹下包含root单词的所有文件
grep -rw 'root' /etc
二.正则表达式
1.正则表达式是什么?
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。在Linux中也就是代表我们定义的模式模板,Linux工具可以用它来过滤文本。
Linux的工具(如sed编辑器或者awk程序)能够在处理数据时使用正则表达式对数据进行模式匹配,如果数据符合匹配的要求,那么就会进入下一步处理;如果数据不符合匹配的要求,就会被过滤掉。
-
正则表达式,又称正规表达式、常规表达式
-
使用字符串来描述、匹配一系列符合某个规则的字符串
-
正则表达式组成
-
普通字符包括大小写字母、数字、标点符号及一些其他符号。
-
元字符是指在正则表达式中具有特殊意义的专用字符
-
2.元字符
2.1 基础正则表达式常见元字符
(支持的工具:grep、egrep、sed、awk)
| 字符 | 作用 |
|---|---|
| \ |
转义,把一些特殊的符号转换成普通的符号字符,还可以把一些普通字符转换成特殊功能,例:\!、\n、\$等 |
|
^ |
表示匹配字符串开始的位置,匹配行首,例: ^a、 ^# |
| $ | 表示匹配字符串末尾的位置,匹配行尾,例: word$、 #$ ;^$表示空行 |
|
. |
匹配任意的单个字符,例: go.d、g..d |
| * | 匹配前面子表达式0次或者多次,贪婪模式所以尽可能长,例: goo*d、go.*d |
| .* | 表示任意长度的任一字符,不包括0次 |
| \? |
匹配其前面字符0或1次,可有可无 |
| \+ | 匹配其前面字符最少1次,有且大于等于1次 |
|
\{n\} |
匹配前面的子表达式n次,例:mo\{2\}y、'[0-9]\{ 2\ }'匹配两位及两位以上数字 |
| \{n,\} | 匹配前面的子表达式不少于n次,例: mo\{2,\}y、'[0-9]\{2,\}'匹配两位及两位以上数字 |
| \{,n\} | 匹配前面的子表达式不多于n次 |
| \{n,m\} | 匹配前面的子表达式n到m次(m>=n),例: mo\{2,3\}y、'[0-9]\{2,3\}'匹配两位到三位数字 |
| 注: egrep(grep-E)、awk使用{n }、{n, }、{n,m}匹配时"{}”前不用加"\" | |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符。等价于"[^A-Za-z0-9_]"。 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \s | 空白符 |
| [:alpha:] | 字母,即A-Z,a-z |
| [:alnum:] | 字母和数字 |
| [:lower:] | 小写字母,即a-z |
| [:upper:] | 大写字母,即A-Z |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 包括空格、制表符、换行符、回车符等各类型空白 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号 |
- ^ 表示匹配字符串开始的位置,匹配行首

- $ 表示匹配字符串末尾的位置,匹配行尾

- * 匹配前面子表达式0次或者多次,贪婪模式所以尽可能长

- . 匹配除\n之外的任意的一个字符

- .* 表示任意长度的任一字符,不包括0次
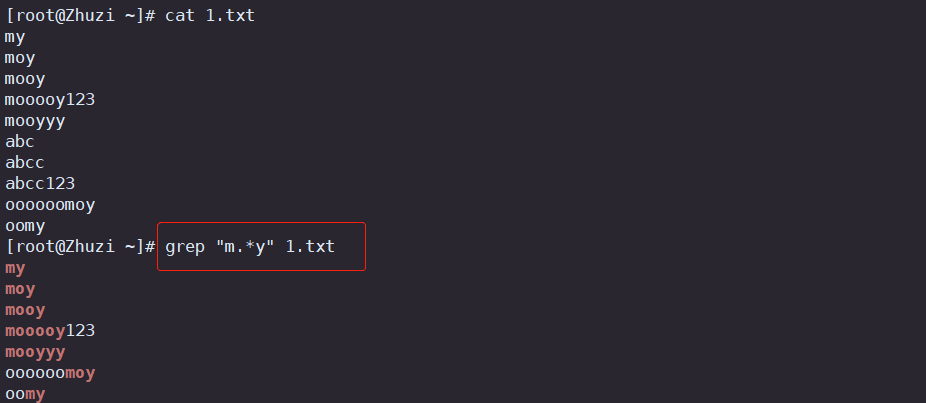
- \{n\} 匹配前面的子表达式n次

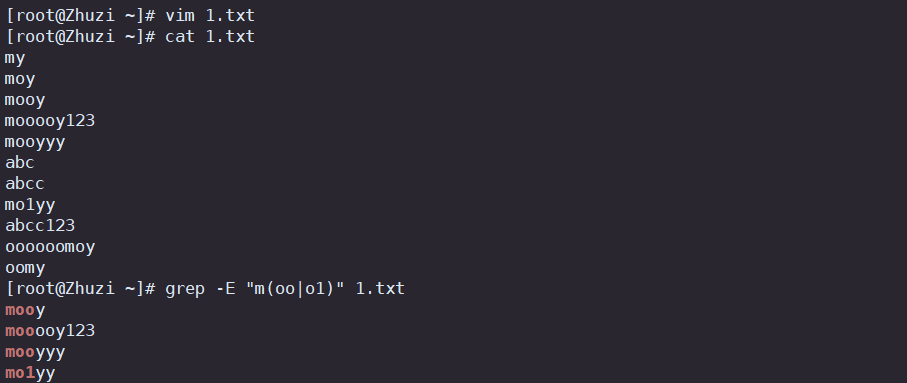
2.2 扩展正则表达式元字符
(支持的工具: egrep、awk、grep -E、sed -r)
| 字符 | 作用 |
|---|---|
| + | 表示匹配前面的子表达式1次以上 |
| ? | 表示匹配前面的子表达式0或者1次 |
|
( ) |
将括号里的内容看成一个整体 |
| | | 以或的方式匹配字符串 |
- + 表示匹配前面的子表达式1次以上

- ? 表示匹配前面的子表达式0或者1次

- ( ) 将括号里的内容看成一个整体

- | 以或的方式匹配字符串

欢迎加入北京社区
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)