
【深度学习】李宏毅2021/2022春深度学习课程笔记 - Self-supervised Learning(自监督式学习)
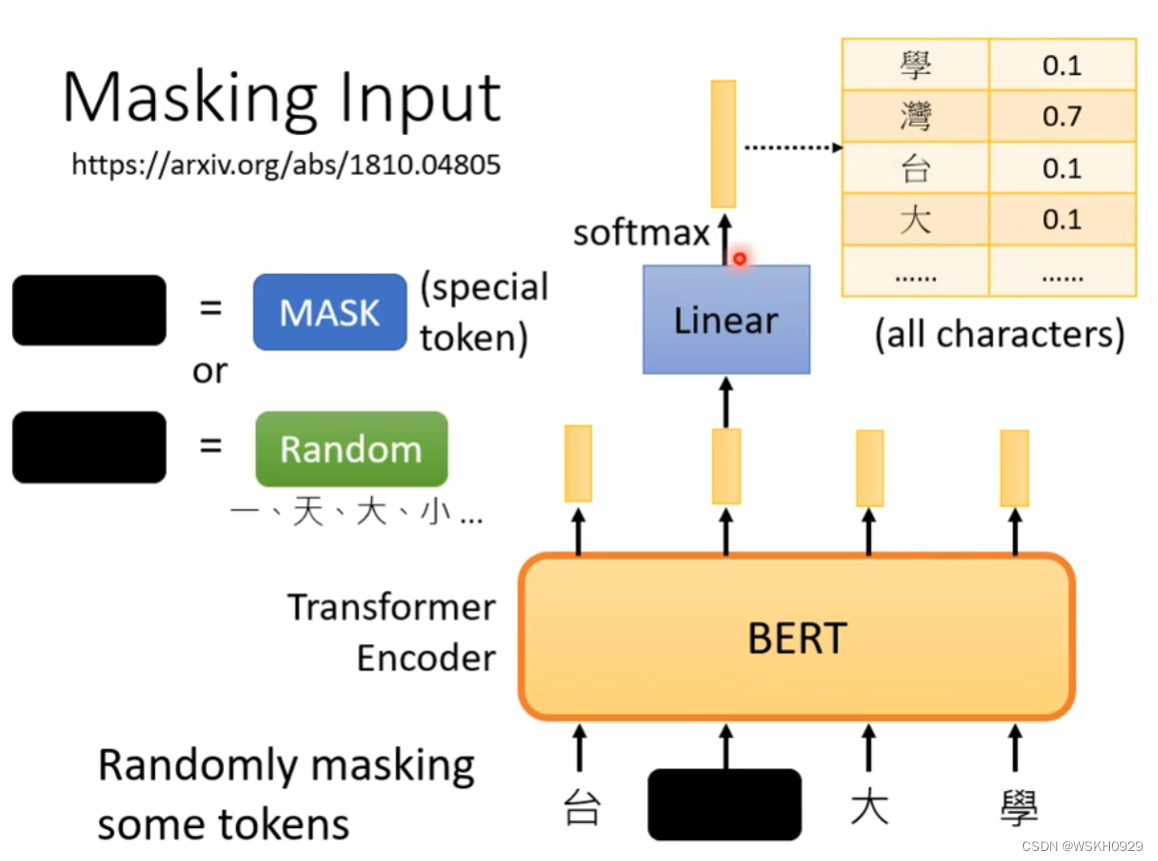
在训练的时候,BERT的输入是Mask的,如下图所示,输入“台湾大学”中的“湾”字被Mask了,通常Mask有两种方式,一种是替换为特殊的Mask符,还有一种是随机替换为另一个中文字符。Predict Next Token 是生成式的,它可以根据输入的Token预测下一个Token,然后再用预测的Token作为输入继续往下预测Token,直到预测出现终止符停止。有很多方法,如下图所示,实验表明,把
一、芝麻街与进击的巨人
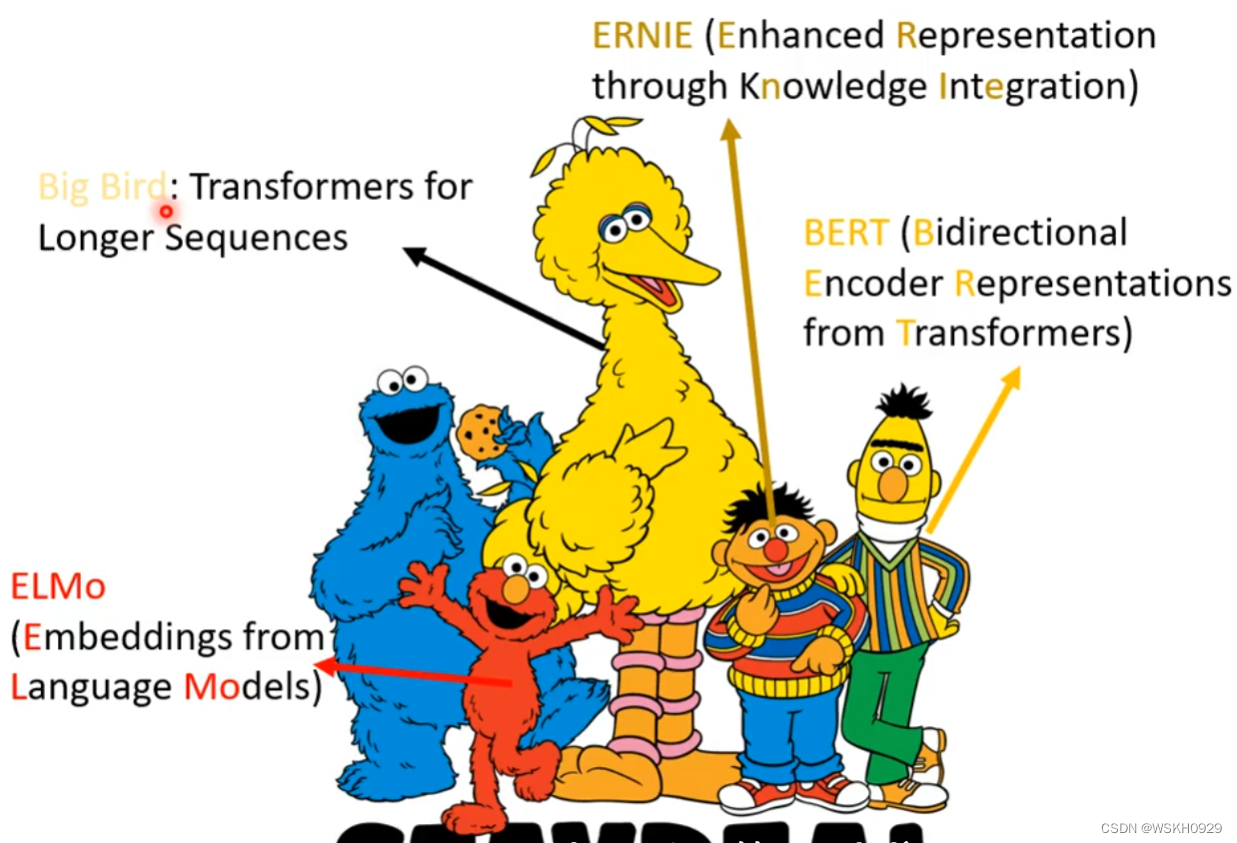
实际上,BERT是很巨大的模型,他的参数可以达到340M

但即使如此,还是有很多比BERT更大的模型



二、Self-supervised Learning
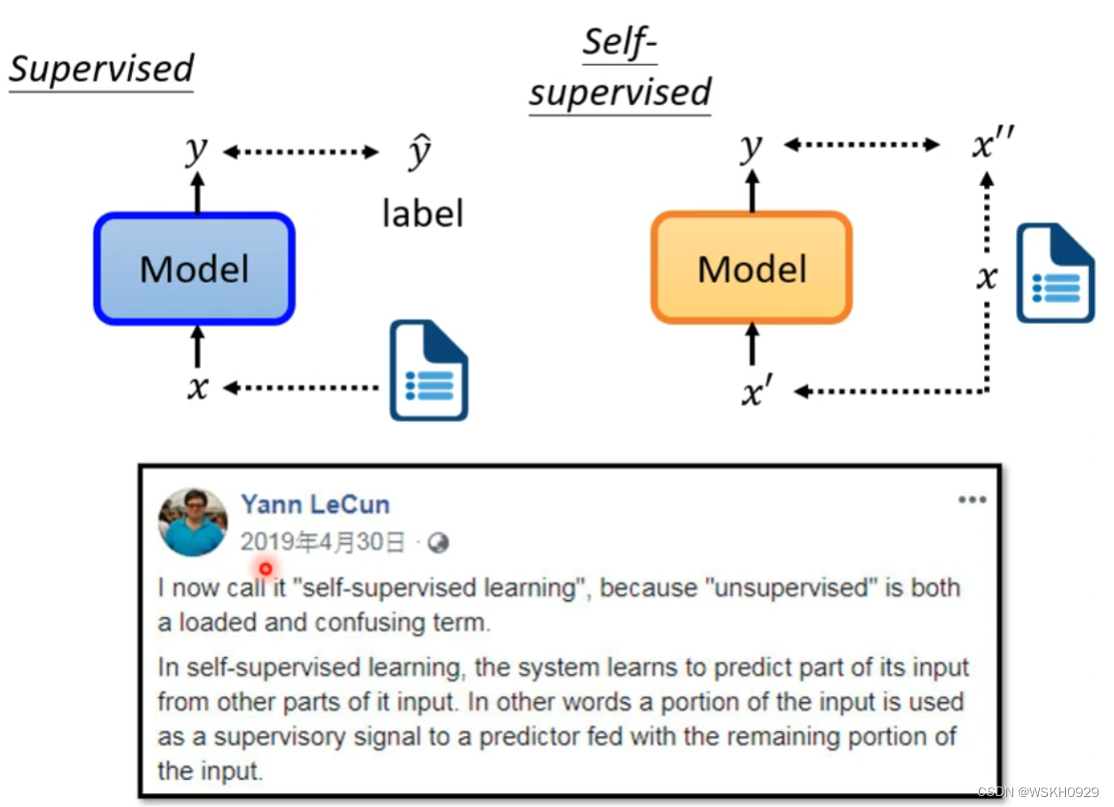
在Self-supervised中,没有标签y,Self-supervised的做法是将数据x分为两个部分,只拿其中一部分作为输入。
由于不需要标签y,所以之前Self-supervised都叫做 unsupervised learning ,Yann LeCun 在2019年4月30日正式将其正名为 Self-supervised Learning
三、BERT
接下来,就拿BERT这个模型解释一下什么是 Self-supervised
3.1 Masking Input
在训练的时候,BERT的输入是Mask的,如下图所示,输入“台湾大学”中的“湾”字被Mask了,通常Mask有两种方式,一种是替换为特殊的Mask符,还有一种是随机替换为另一个中文字符。BERT的输出会连接线性层,最后经过SoftMax函数归一化,输出属于每个中文字符的概率。损失的计算就是用交叉熵损失。
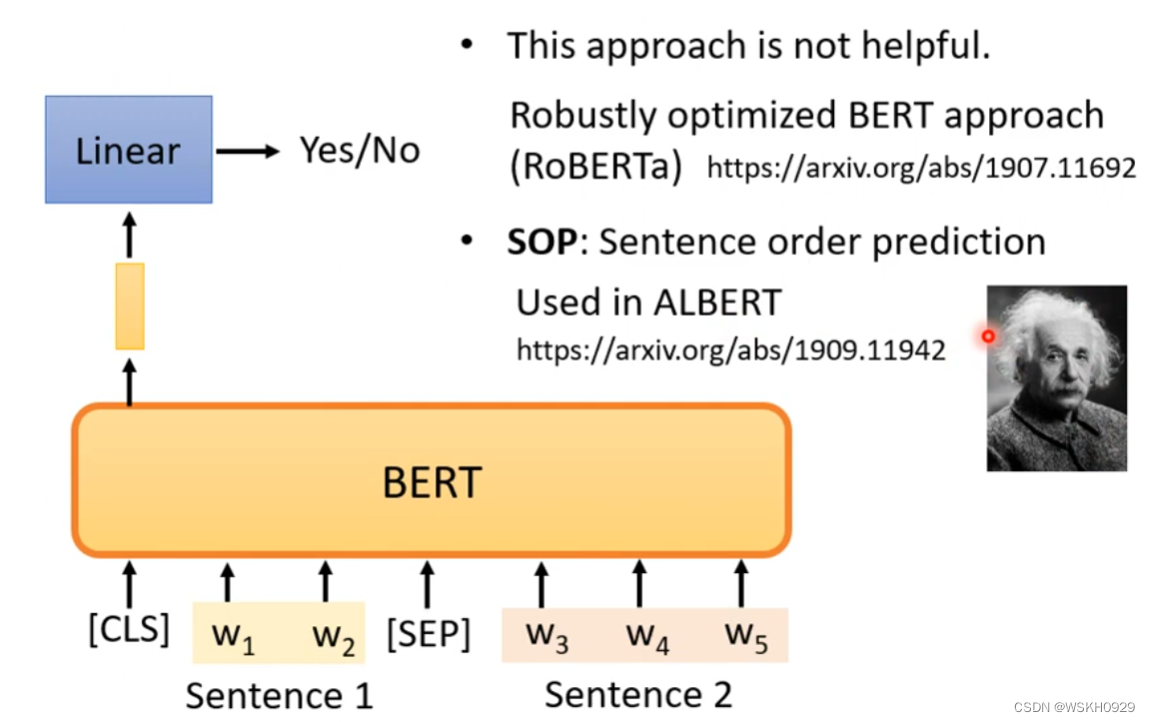
3.2 Next Sentence Prediction
预测两个句子是不是应该被接在一起
给BERT一些有标注的资料,BERT就可以做各式各样的下游任务
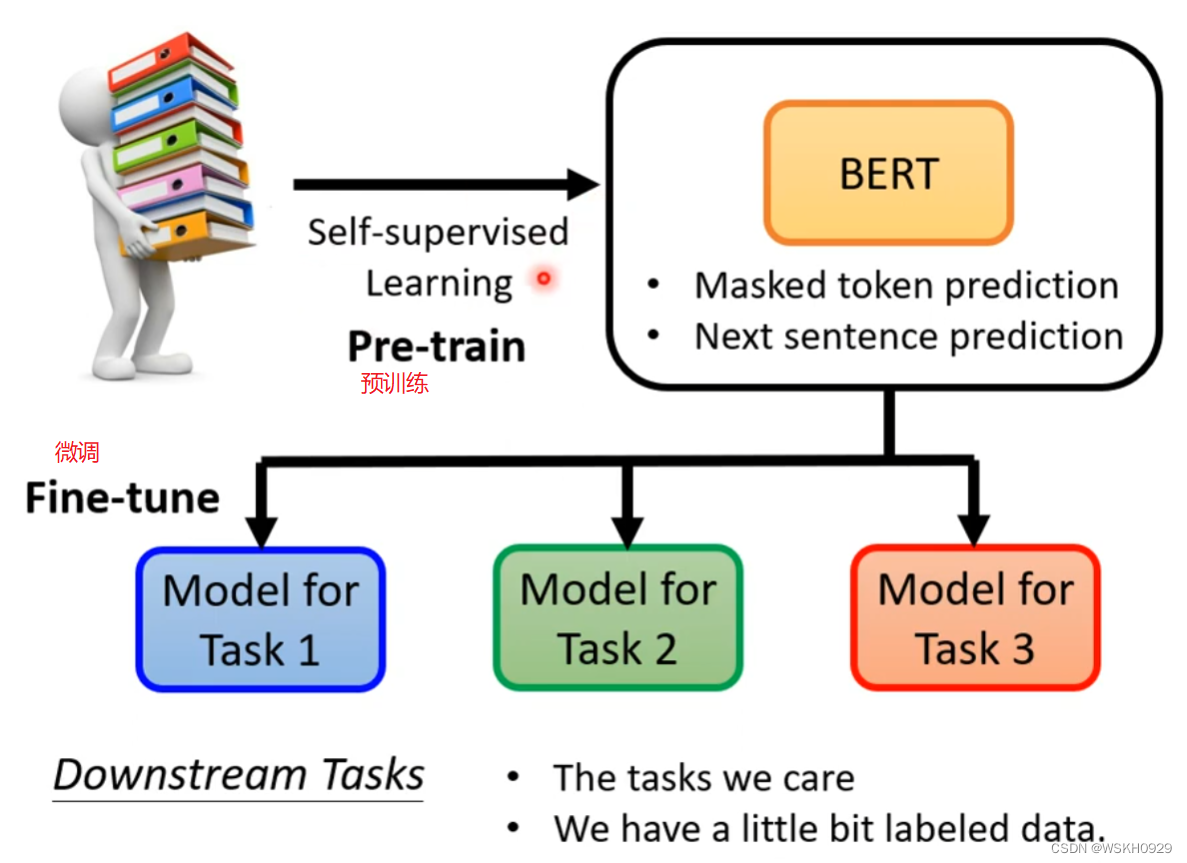
3.3 GLUE 任务集
最有名的测试BERT模型好坏的任务集是GLUE,它里面总共有9个任务,我们一般看BERT模型在这9个任务集上的平均表现

下图可以看出,模型在GLUE任务集上的平均表现(蓝色虚线)越来越好,并逐渐超过人类的表现(黑线)
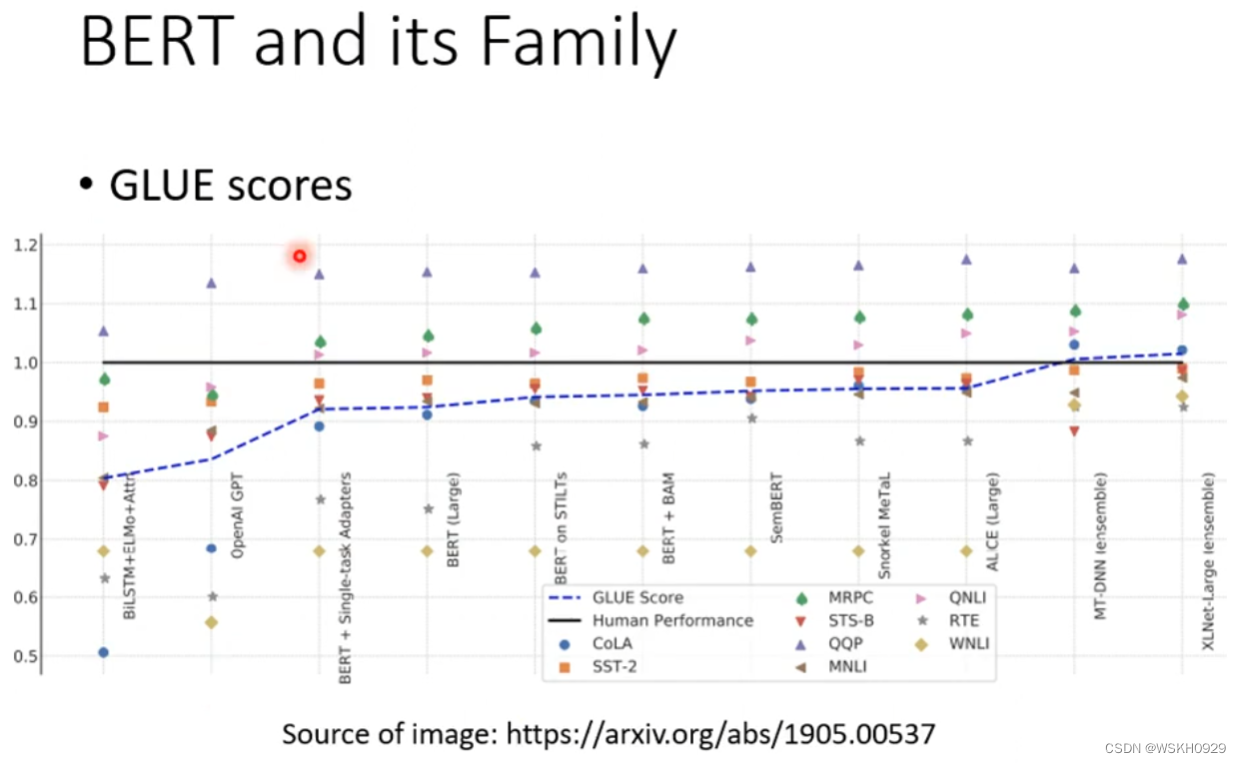
3.4 How to use BERT
3.4.1 Case1
输入:序列
输出:类别
举例:输入“Happy”,输出“positive”;输入“Sad”,输出“negative”
如下图所示,线性层的参数是随机初始化的,而BERT的参数是预训练后得到的
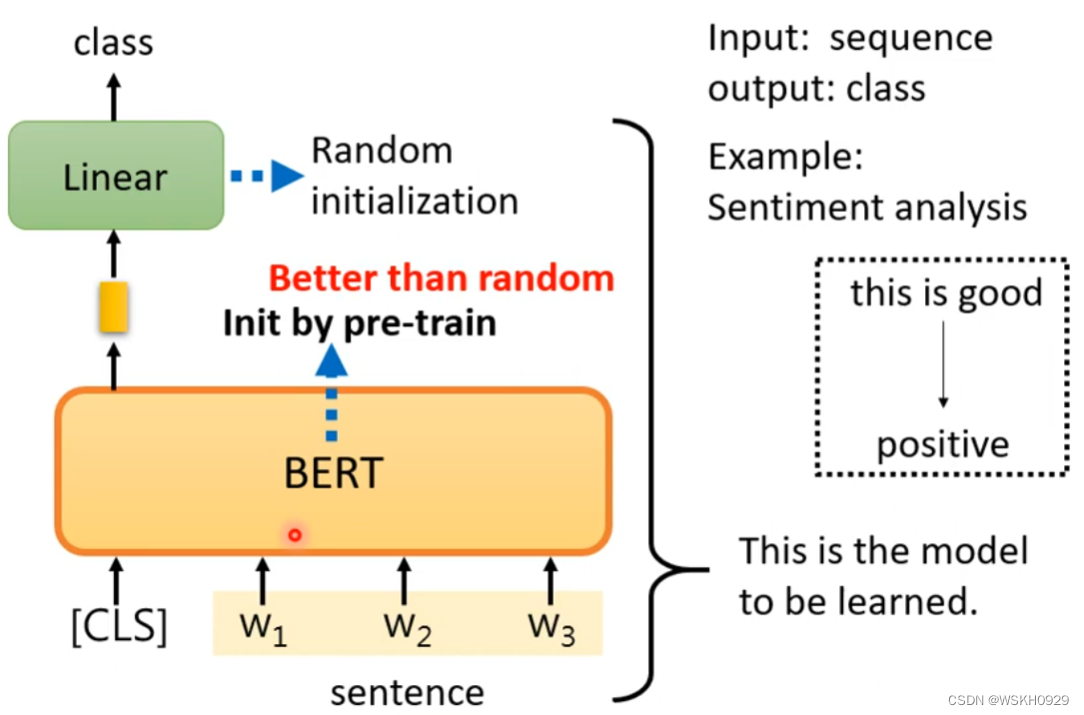
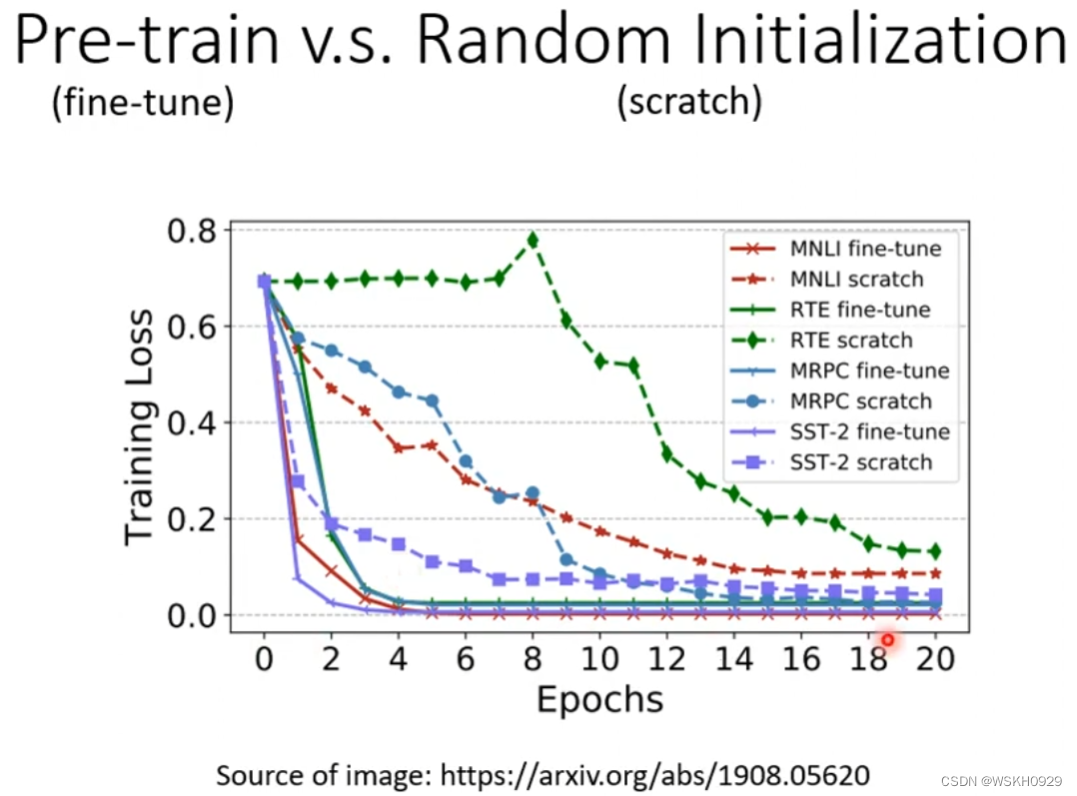
事实证明,预训练的BERT模型,比随机初始化的BERT模型表现更好
3.4.2 Case2
输入:序列
输出:序列(长度和输入一样)
例子:词性标注
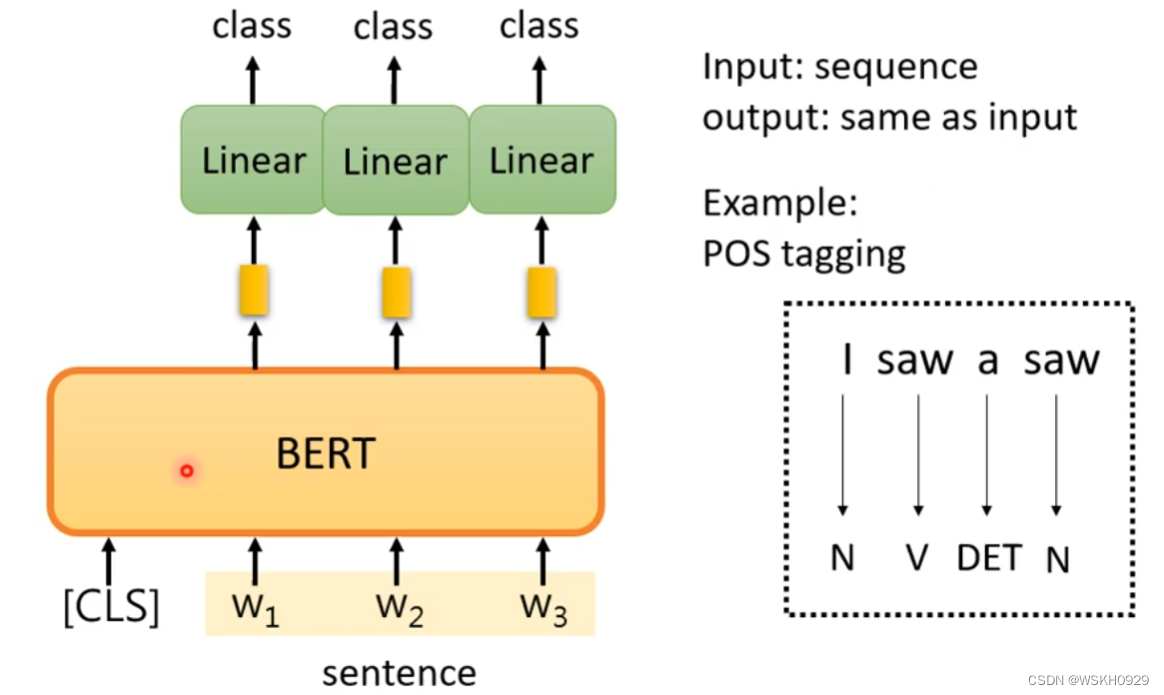
3.4.3 Case3
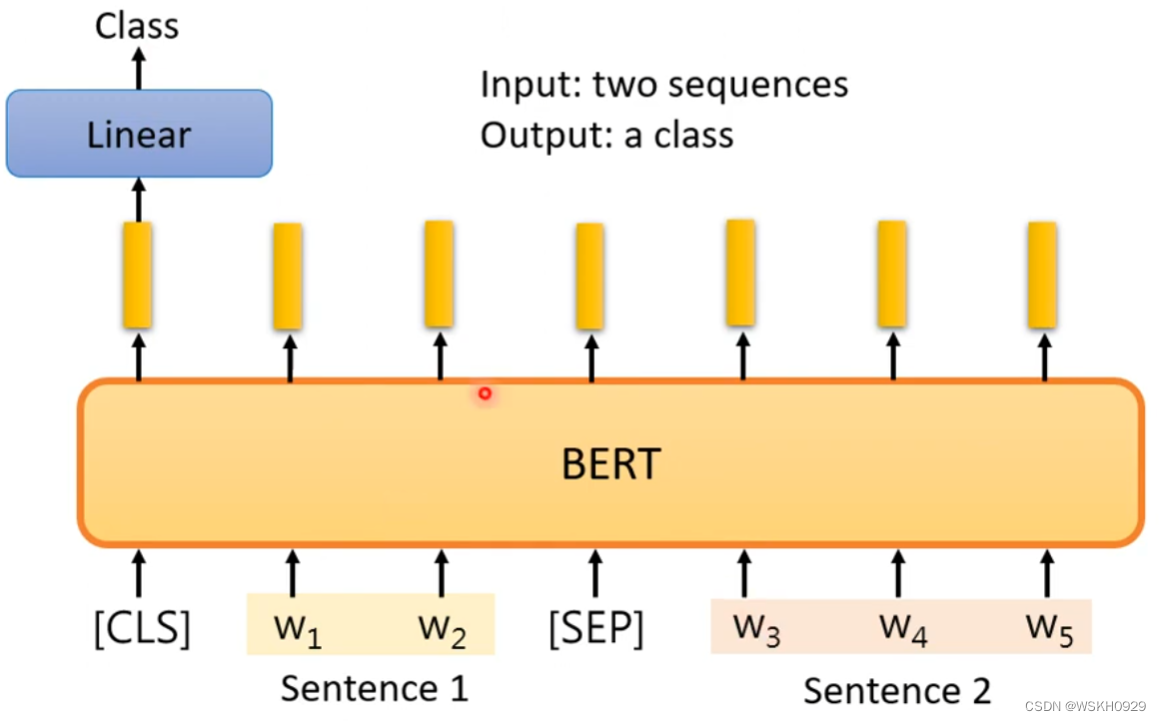
输入:两个序列
输出:类别
例子:输入两个句子,输出它们之间的关系:矛盾、相似
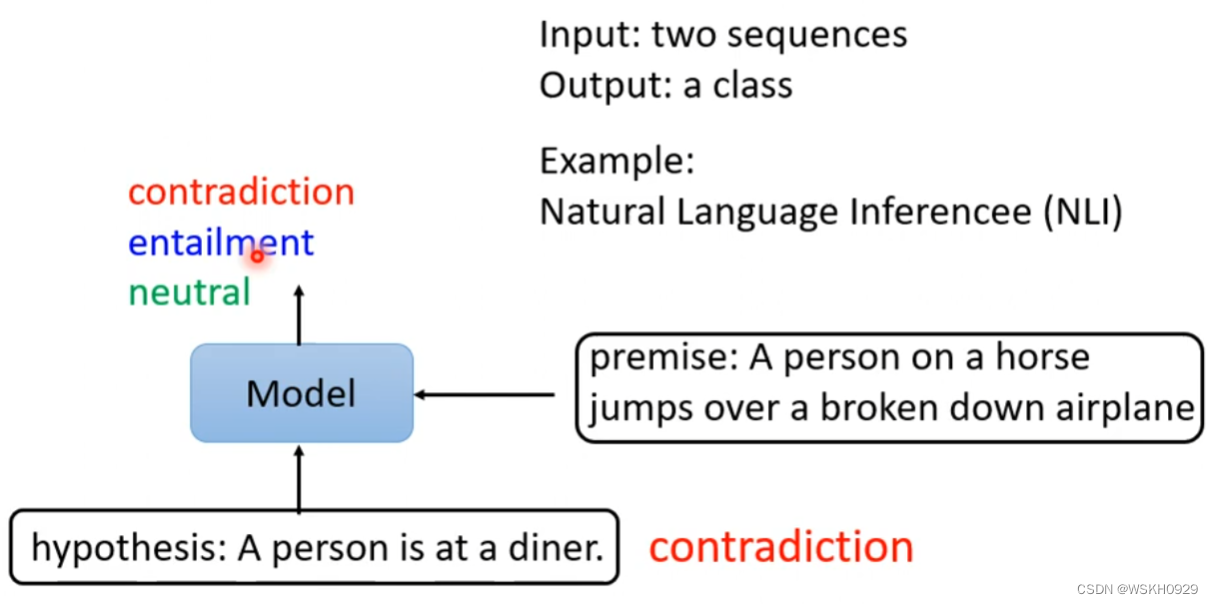
3.4.4 Case4
问答系统:输入一篇文章和一个问题,输出问题的答案。(答案一定是出现在文章里的某个片段)
输出是两个整数,代表了答案在文章中的起始位置和结束位置
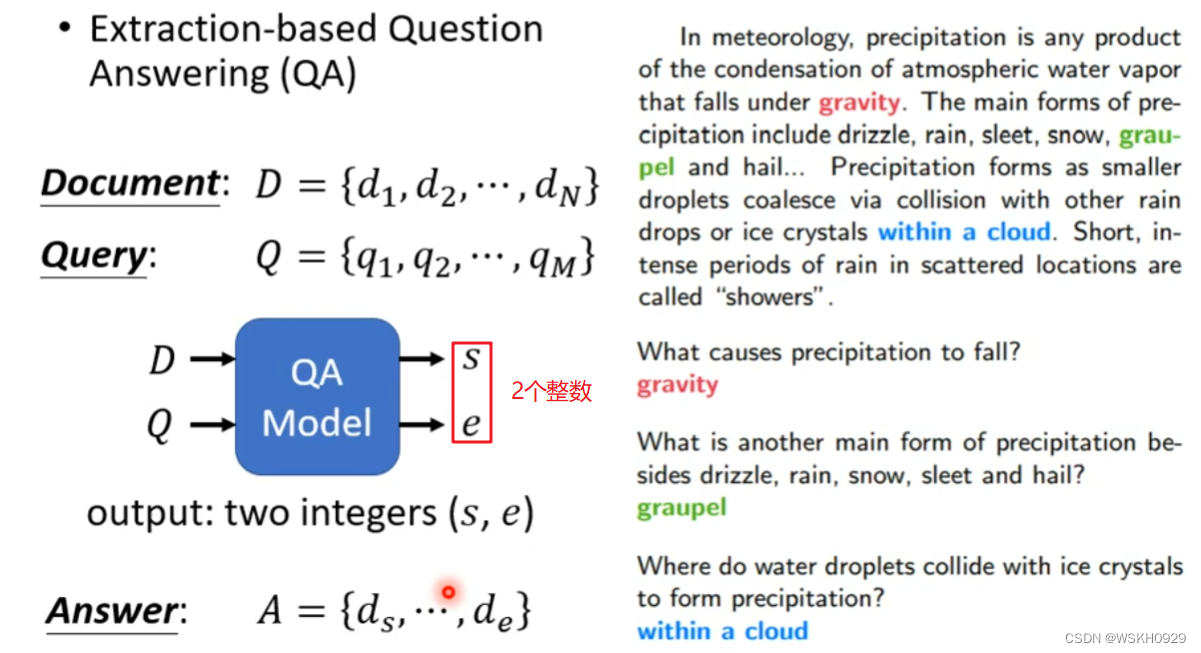
找开始位置
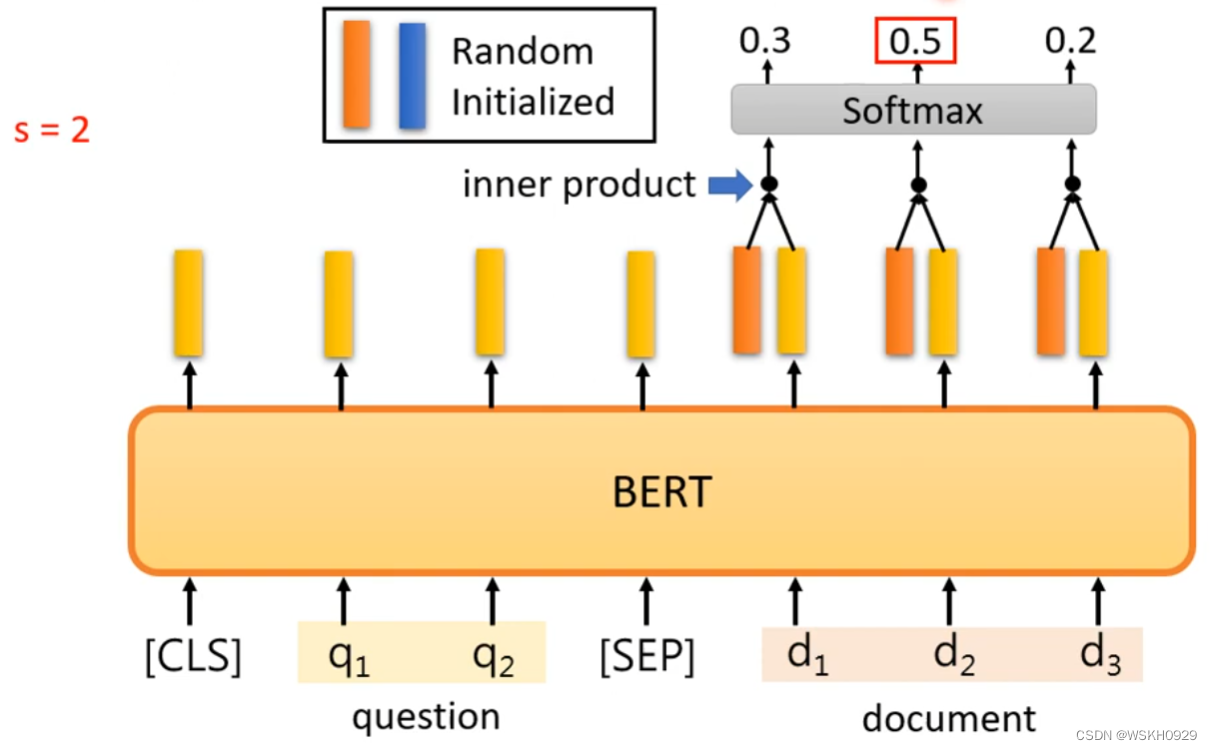
找结束位置
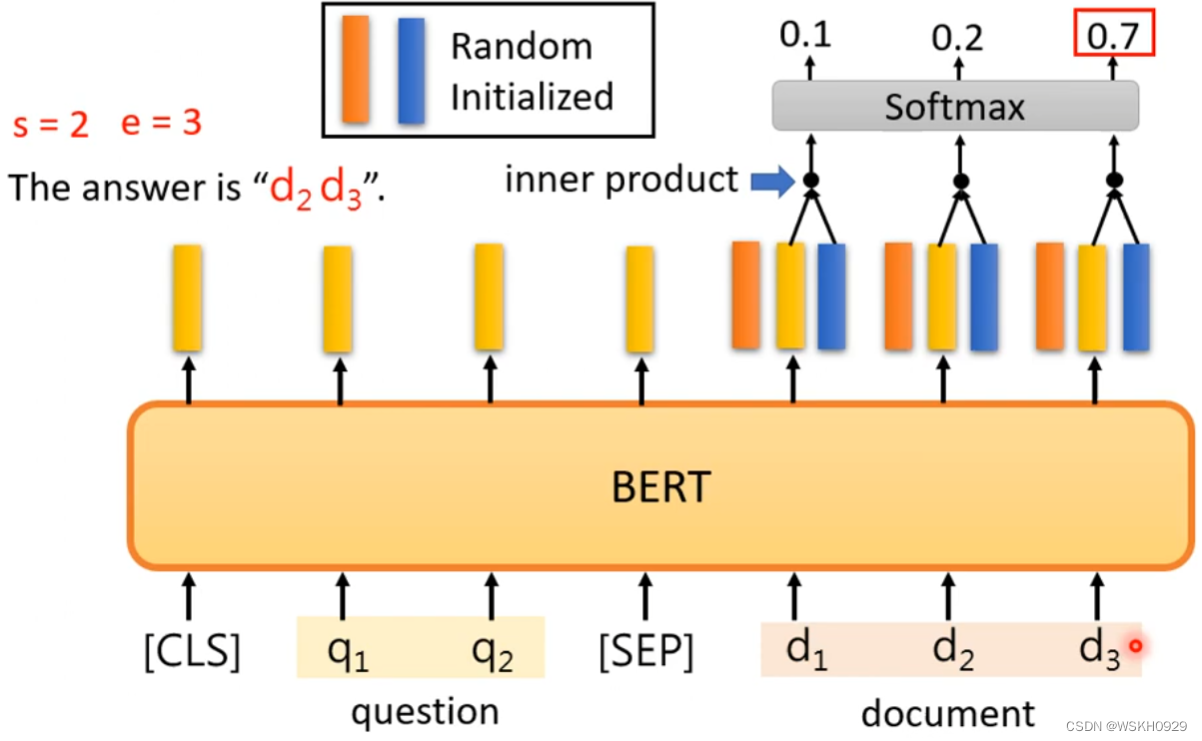
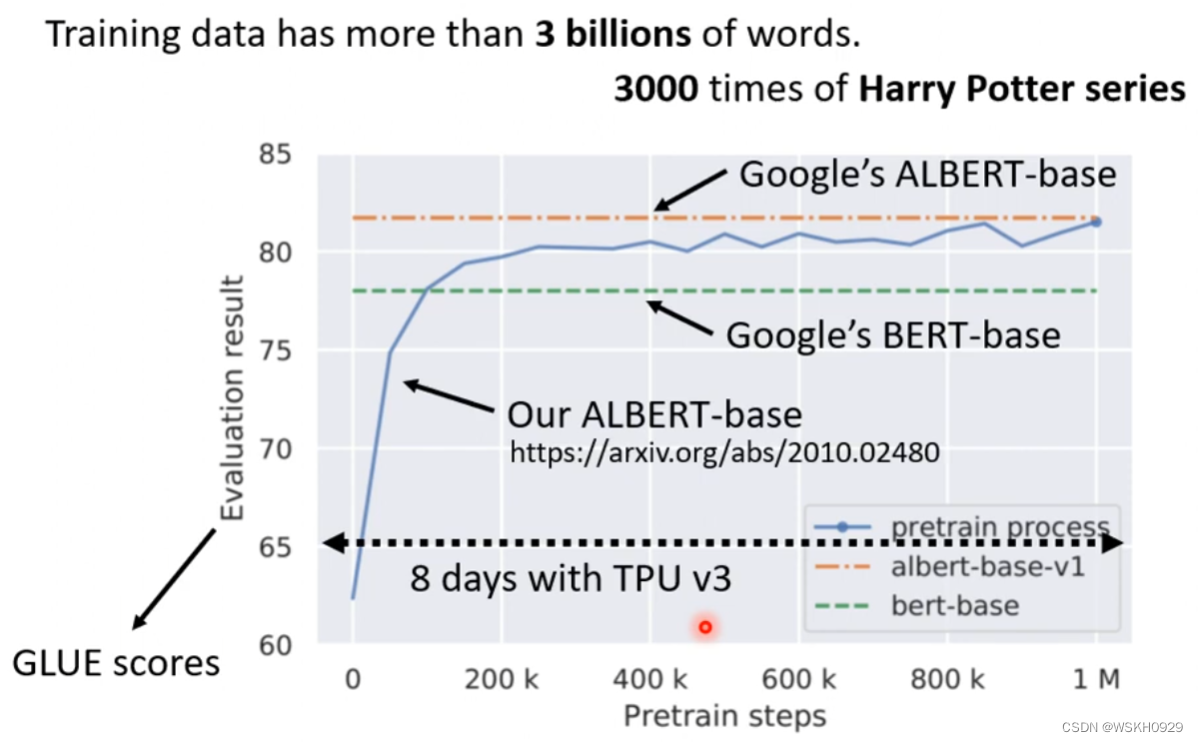
3.5 Training BERT is challenging!
3.6 Pre-Training a Seq2Seq Model
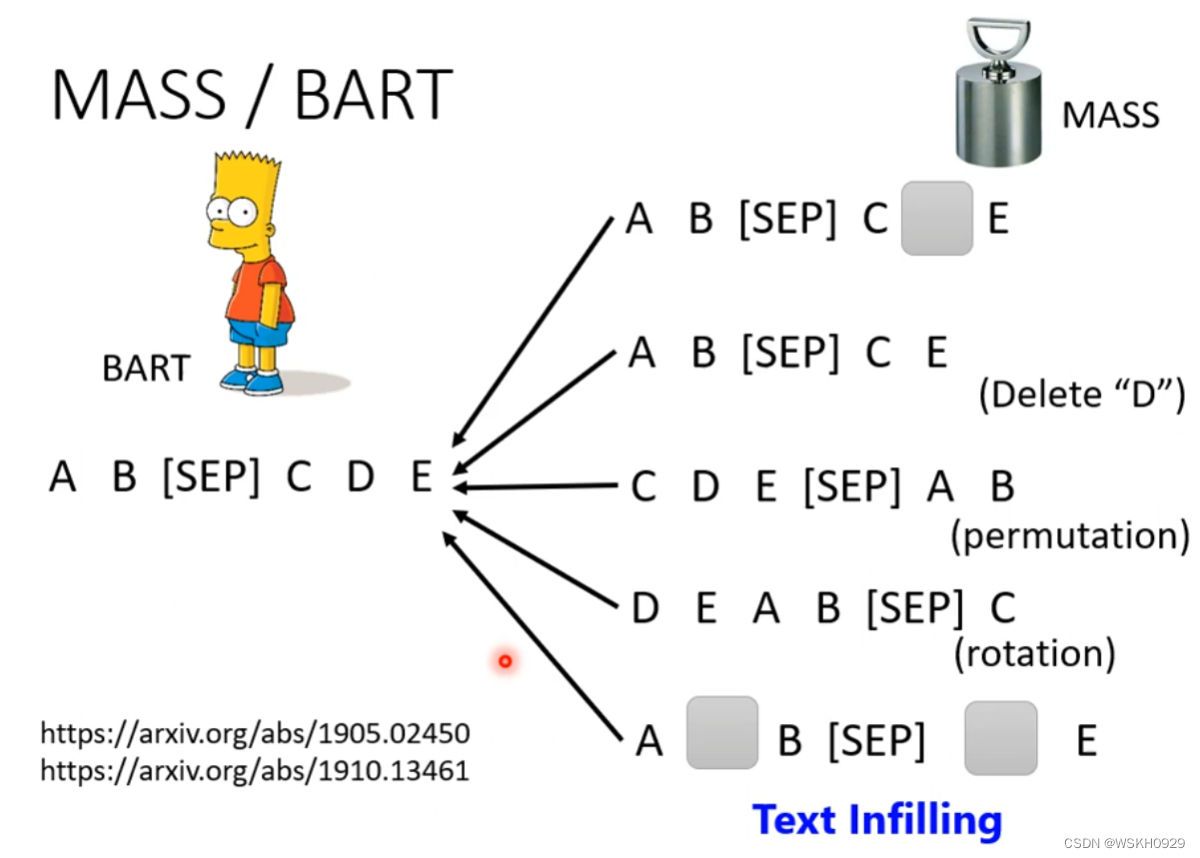
将序列做一些扰动,再输入Encoder,Decoder的任务是输出和扰动前的序列越接近越好
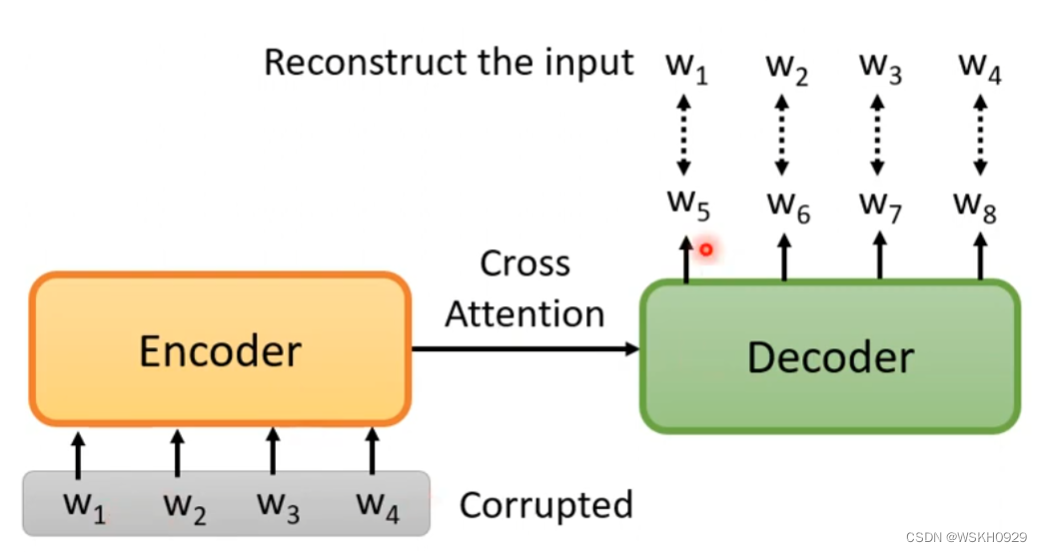
那么怎么扰动呢?有很多方法,如下图所示,实验表明,把这些扰动的方法都用上效果是比较好的
3.7 Why does BERT work?
为什么BERT有用呢?
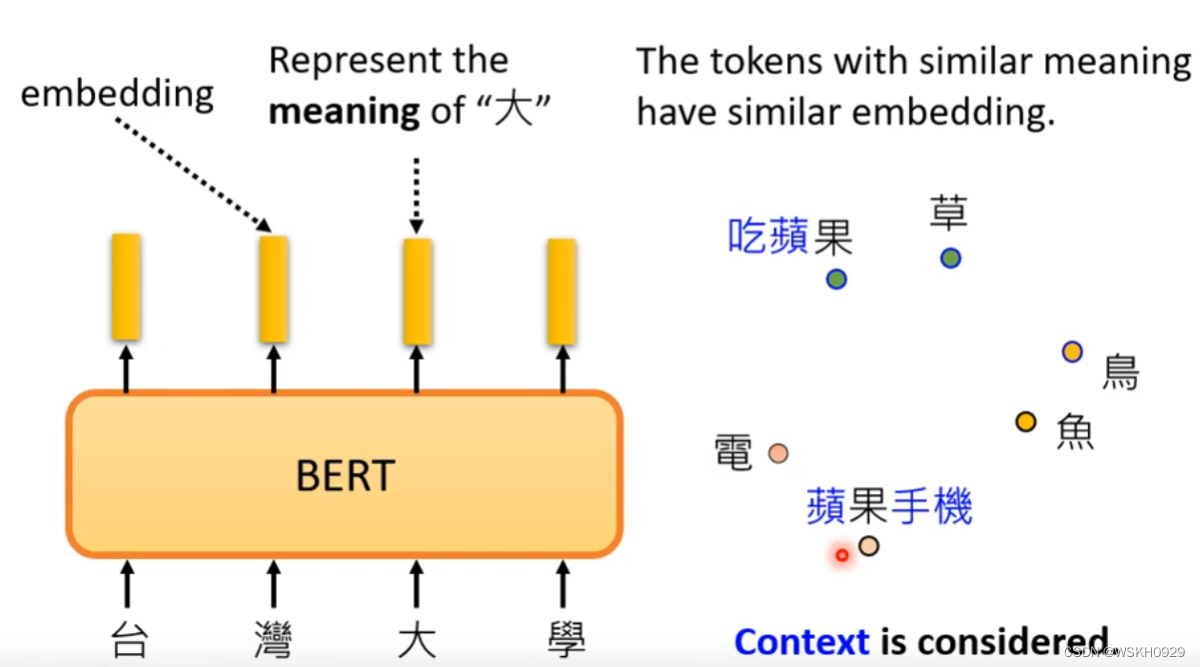
BERT可以实现一词多义。如下图所示,同样的”果“字,由于上下文的不同,它的Embedding也不同
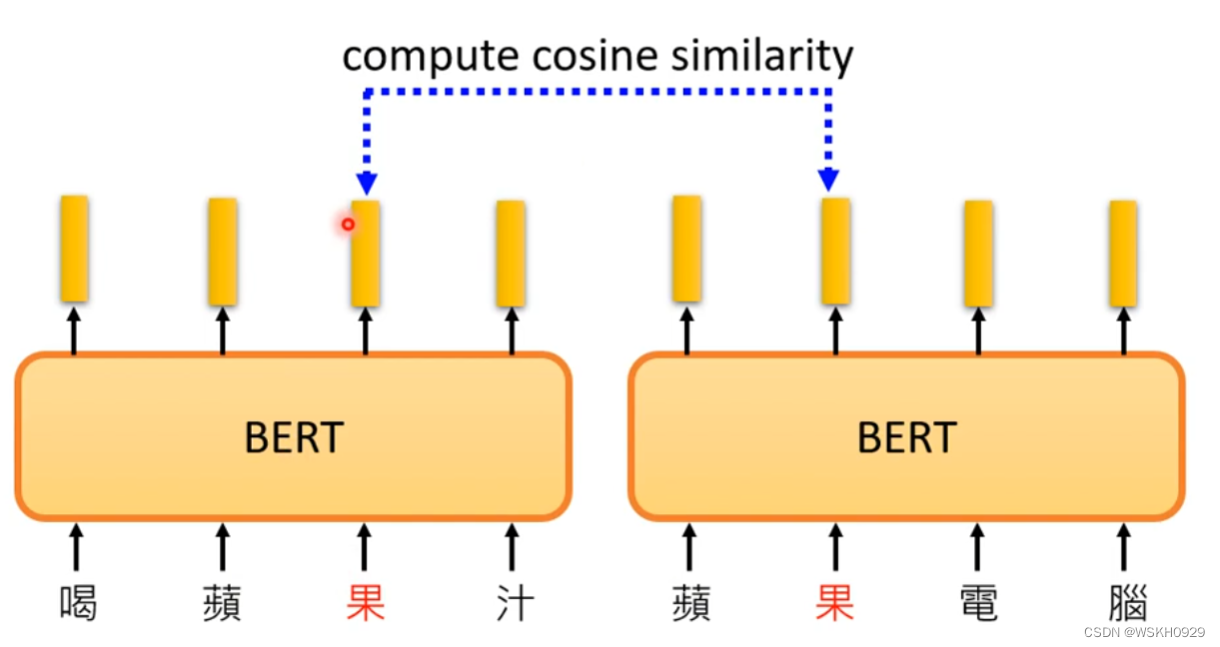
接下来做个实验看看是不是真的可以做到识别同一个字在不同句子里的多义现象。可以输入不同句子,计算同一个字的相似度
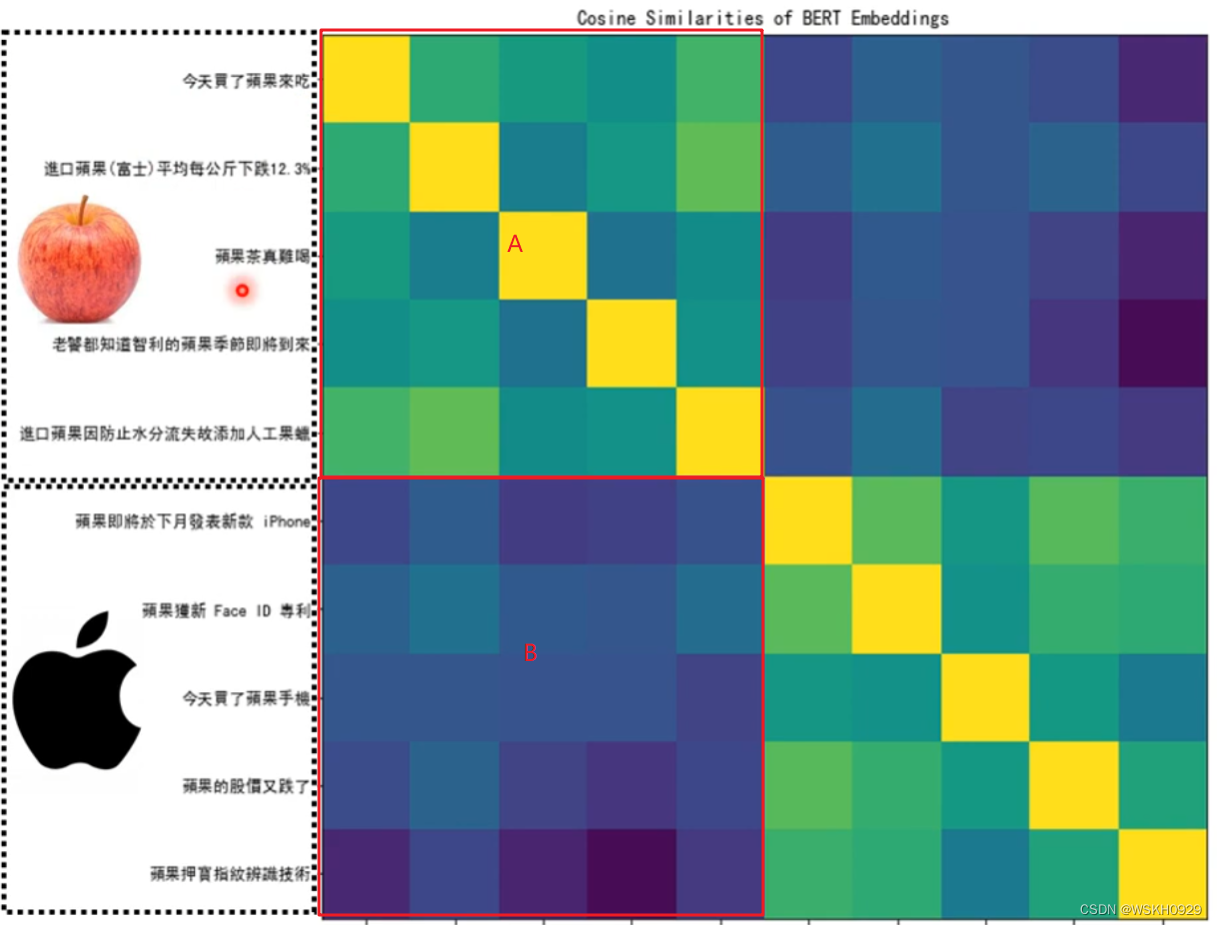
然后根据相似度绘制热力图。如下图所示,可以看到A和B区有较为明显的区别。说明BERT可以识别出一词多义的情况。
3.8 To Learning More BERT

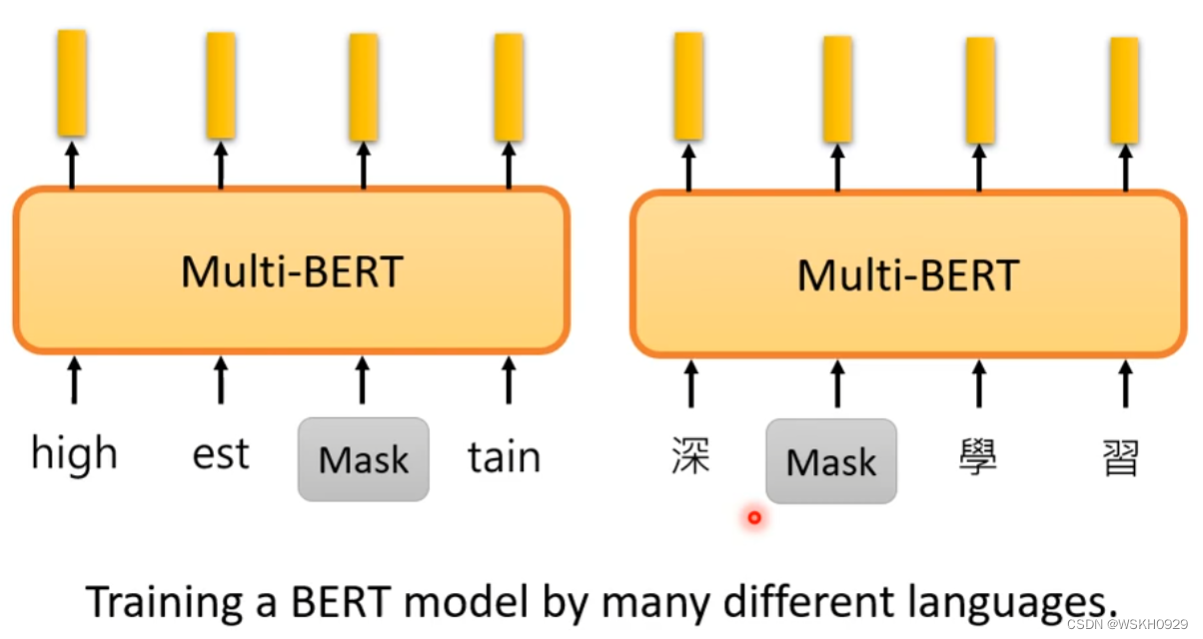
3.9 Multi-lingual BERT
Multi-lingual BERT 指的是不同语言训练而成的BERT模型,如下图所示
四、GPT
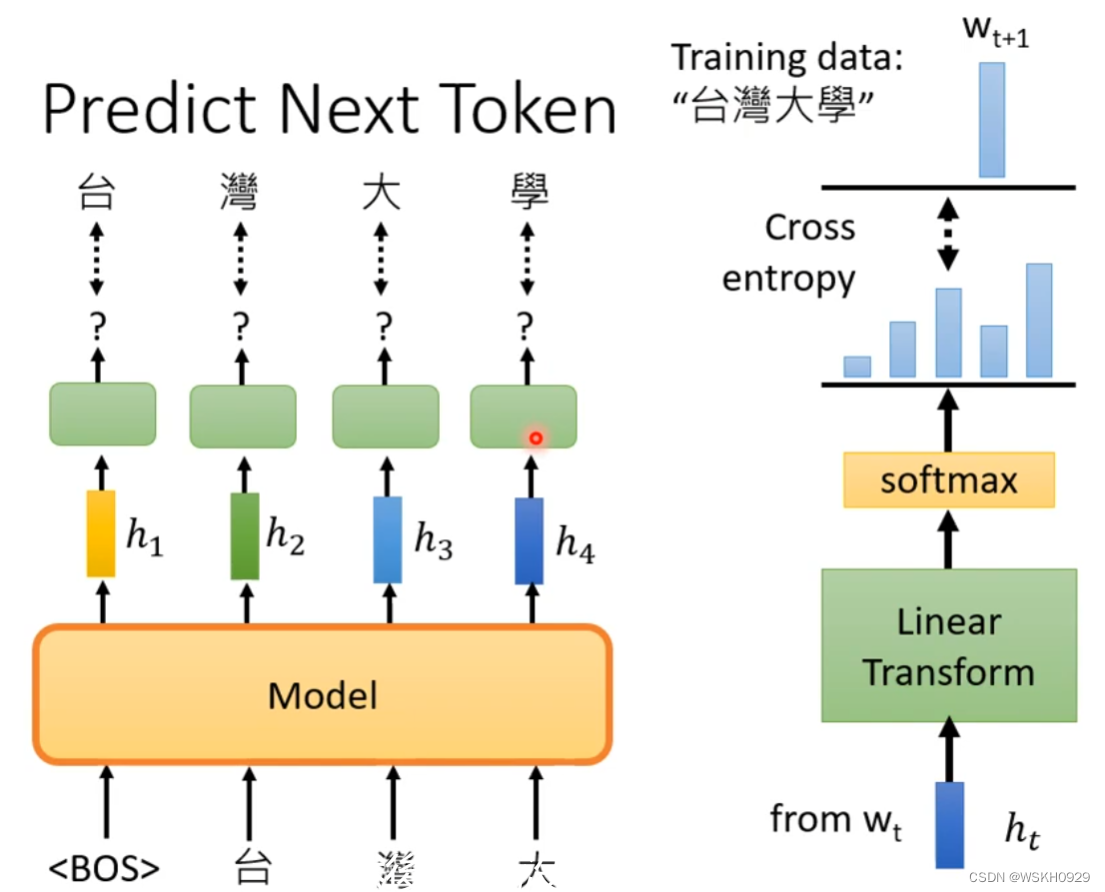
4.1 Predict Next Token
Predict Next Token 是生成式的,它可以根据输入的Token预测下一个Token,然后再用预测的Token作为输入继续往下预测Token,直到预测出现终止符停止
为什么通常GPT和独角兽放在一起呢?是因为GPT最有名的例子就是生成了一篇和独角兽有关的假新闻。

4.2 How to use GPT?


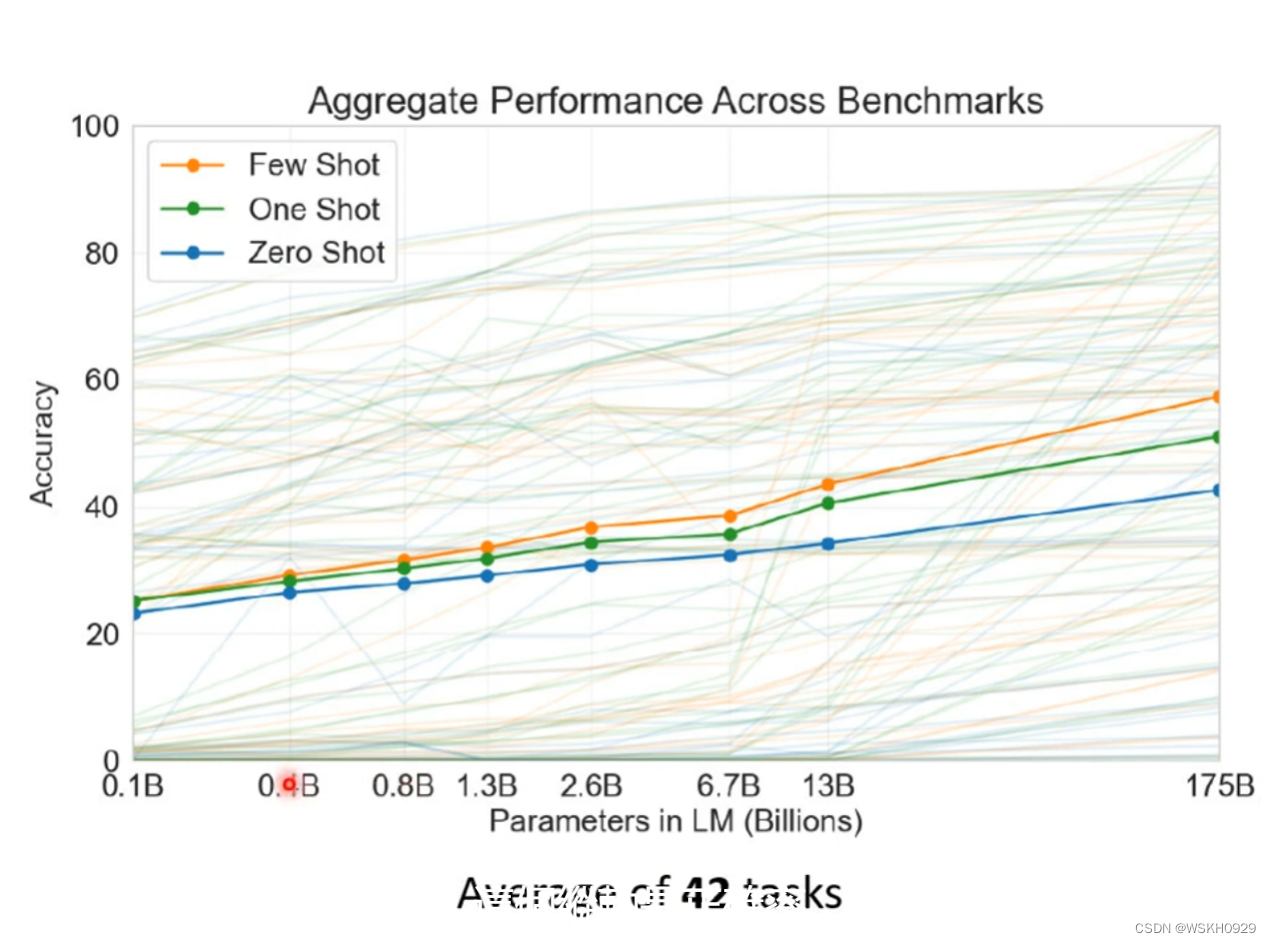
事实证明,GPT的正确率比较低
4.3 To Learn More GPT

五、 Beyond Text
实际上,自监督式学习能做的还可以更多,不只是文字方面,还可以是语音识别和图像识别方面
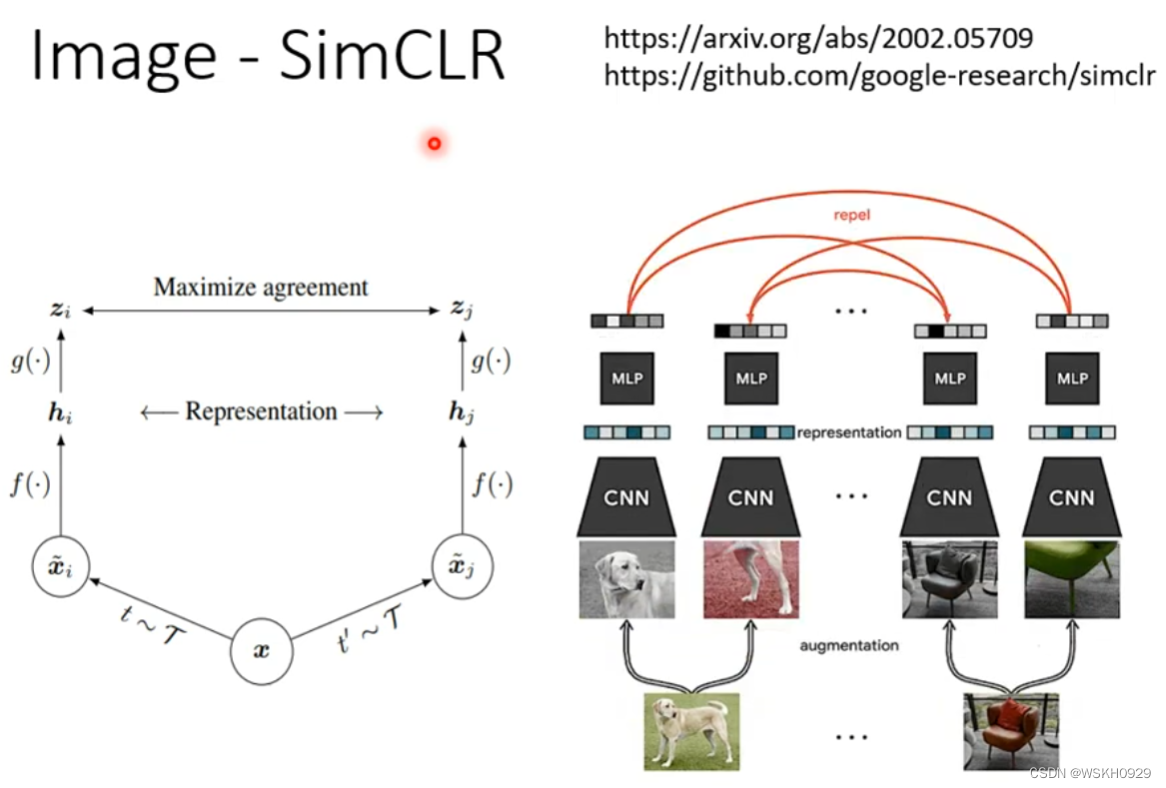
5.1 Image - SimCLR
5.2 Image - BYOL

5.3 Speech
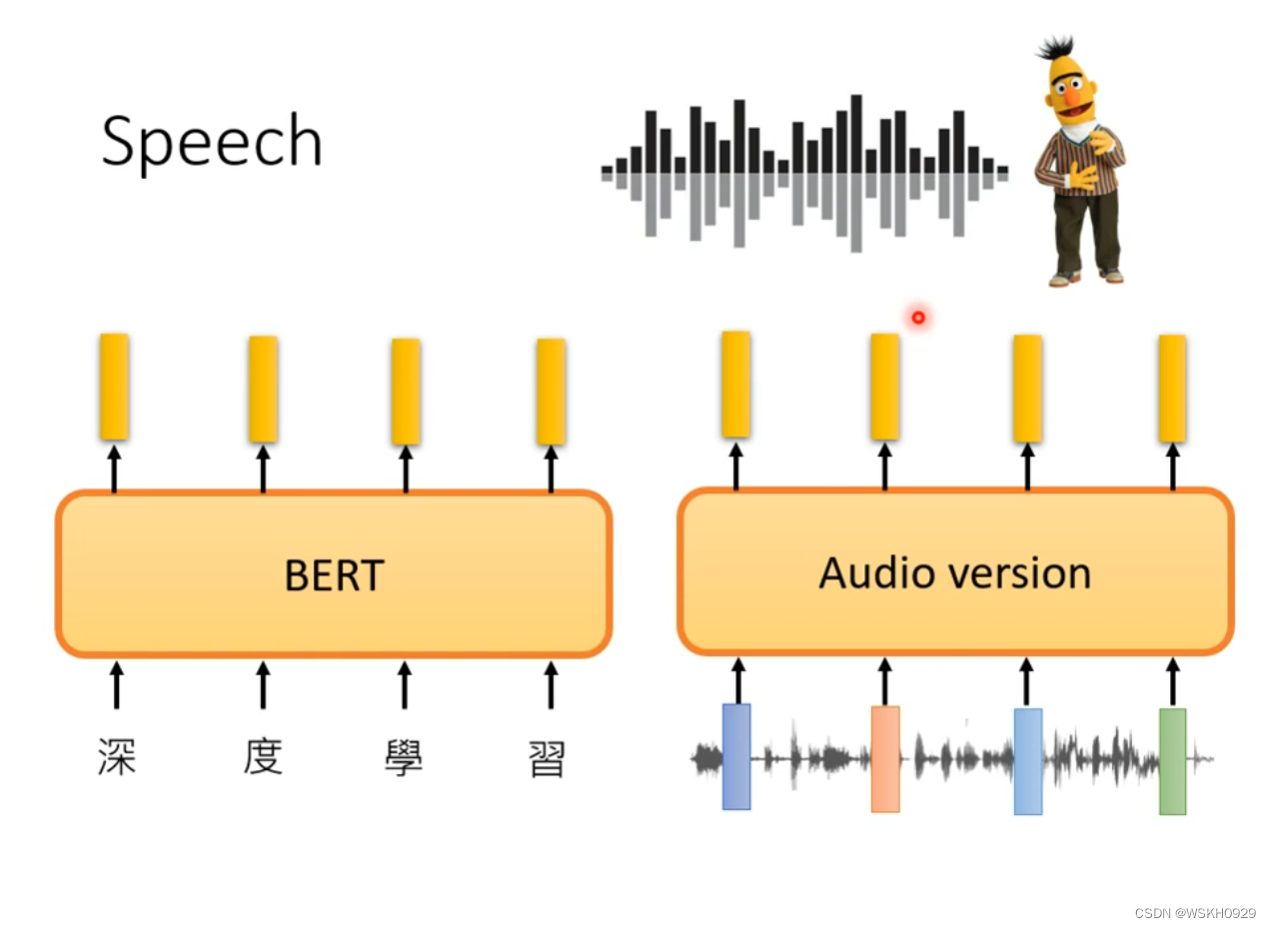
Speech 领域的 GLUE:SUPERB


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)