语音识别之Kaldi:神经网络实战
今天学习基于神经网络的语音识别。
ASR神经网络实战
kaldi语音识别理论与实践课程学习。
之前学习了基于GMM-HMM的传统语音识别:GMM-HMM
其中也包含Kaldi架构的简介,语音数据的预处理,特征提取等过程。
今天学习基于神经网络的语音识别。
神经网络训练脚本
以TDNN为例。
Kaldi中大部分的例子egs里,都提供了训练thnn的recipe。
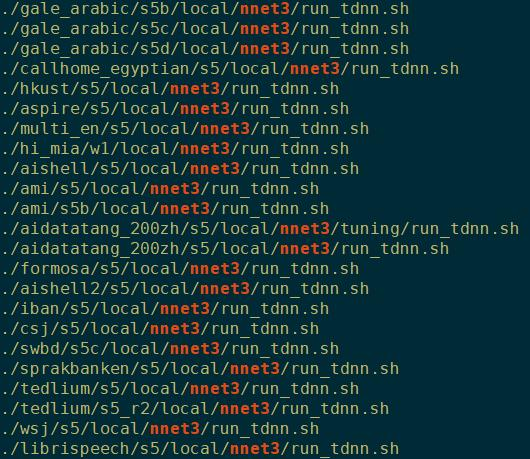
不同recipes的内容可能有所差异,但大体都能分为3个部分。

神经网络config可以简单理解为一张图,Kaldi网络就是从这张图初始化得到的。
参数设置
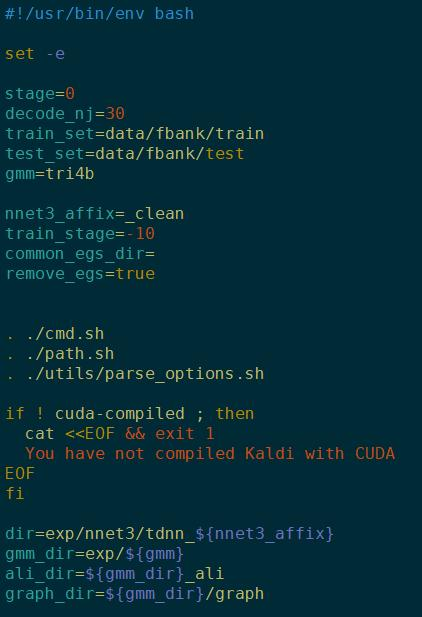
stage:控制脚本运行起始位置的参数。
nnet3_affix:训练好的神经网络存放名字后缀
train_stage:如果训到第50轮断了,就把该值设置成50,就可以从第50轮开始,而不需要从头开始
common_egs_dir和remove_egs后续会再说。
再下来 . ./的是配置环境变量。其中:
utils/parse_options.sh 实现了基于shell脚本的“ --key value”的传参方式, 例如:
./run_tdnn.sh --stage 0 --gmm tri4b \
--nnet3_affix data_aug
注意: 只有定义在utils/parse_options.sh之前的参数允许以该方式传参, 图中的[dir, gmm_dir, ali_dir, graph_dir]等不能以此方式传参。
神经网络config
num_target:神经网络维度,tree的叶子节点数。
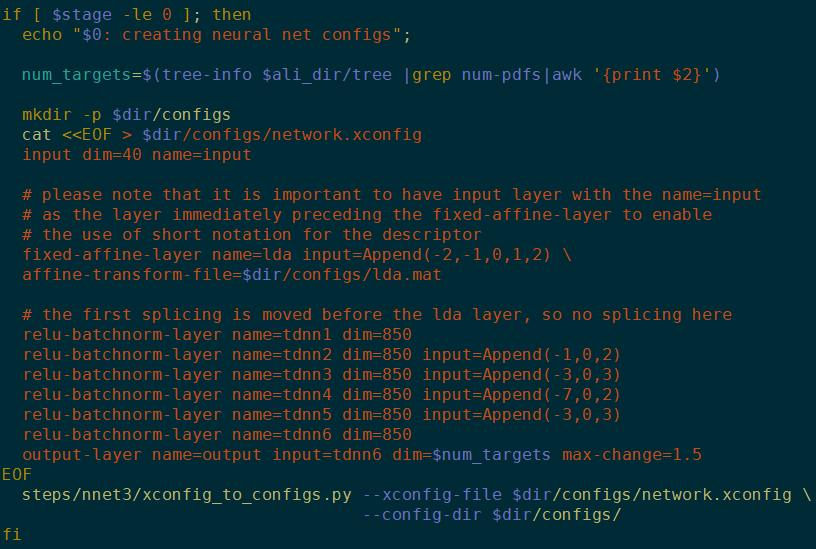
下面是个TDNN的网络结构。tdnn1,2,3只是名字,不代表是第一层、第二层等,你也可以写成a,b,c。(-1,0,2)代表context的左一右二。
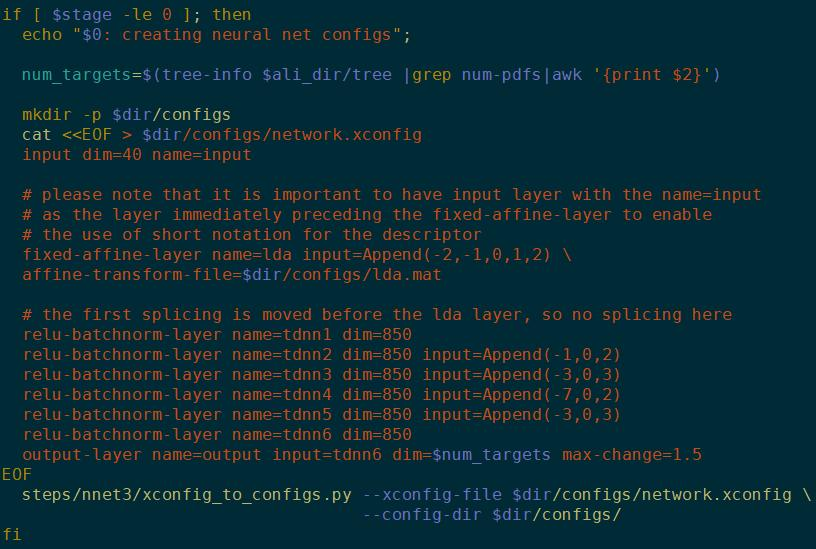
configs是一组配置。可以理解为就是神经网络的画像,整体结构和内部节点之间的关系。网络初始化的时候就要按config里的定义初始化。
为了便于理解config,Kaldi提供了一个config解析器,即xconfig_to_configs。
生成以下文件:
{ final.config; init.config; init.raw; network.config; ref.config;
ref.raw; vars; xconfig; xconfig.expanded.1; xconfig.expanded.2 }
可分为四类:
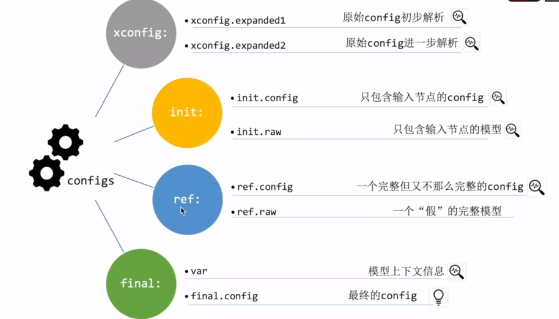
xconfig:
比原始的config增加了一些定义。expend2是对1的进一步解析。
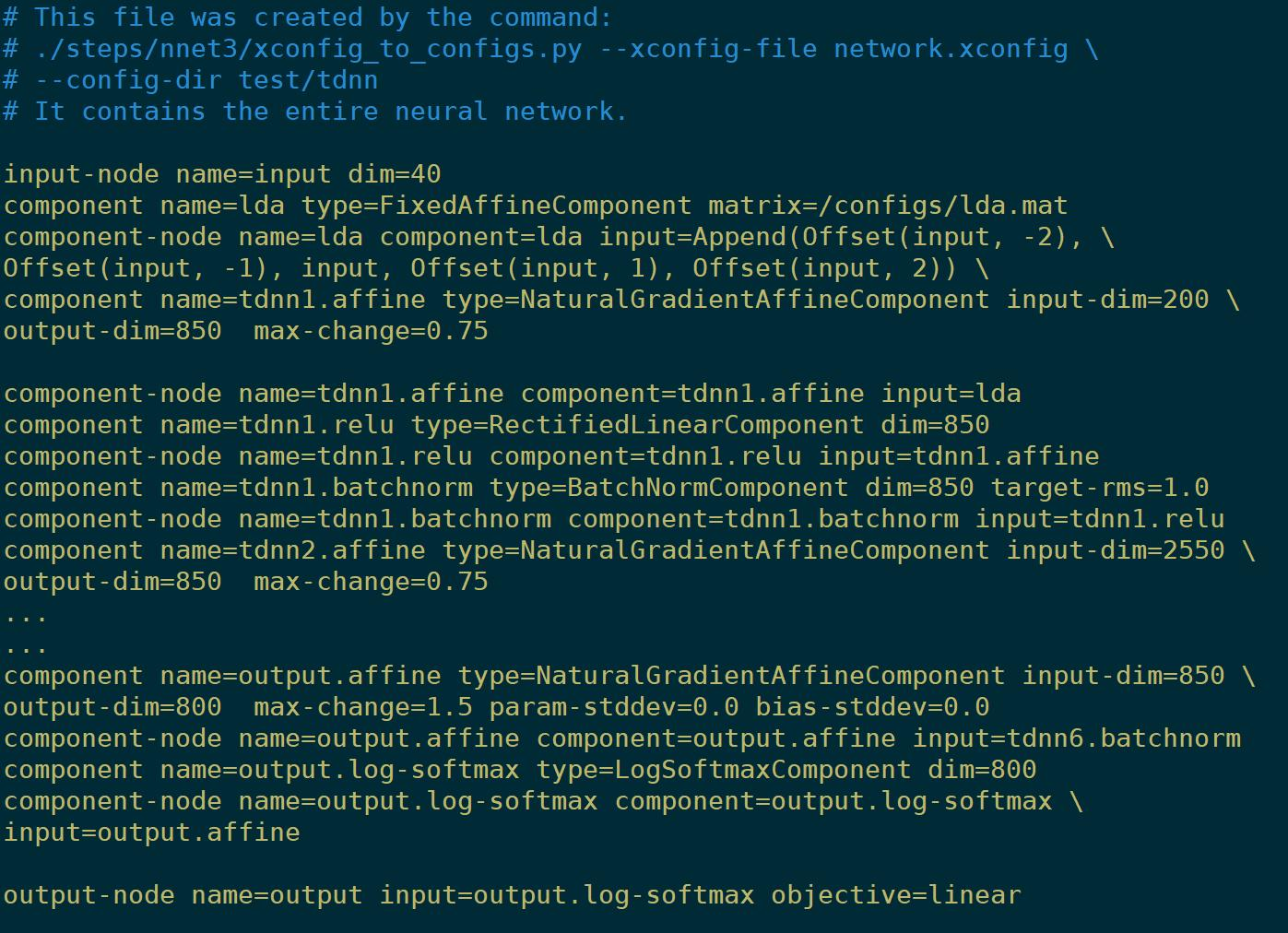
init:
注意:是只和输入相关的节点,不是初始化后的整个网络。
init.config
只包含两个节点,input node和output node

init.raw
从init.config初始化得到的,

需要init.config的目的是得到输入数据的维度相关的信息,以便于训练后面的LDA,这是一个训练的小技巧。
ref
是reference的简称。顾名思义是个参考的config。
lda矩阵是”假“的(随机初始化的):还没有对输入数据进行遍历,还没有统计
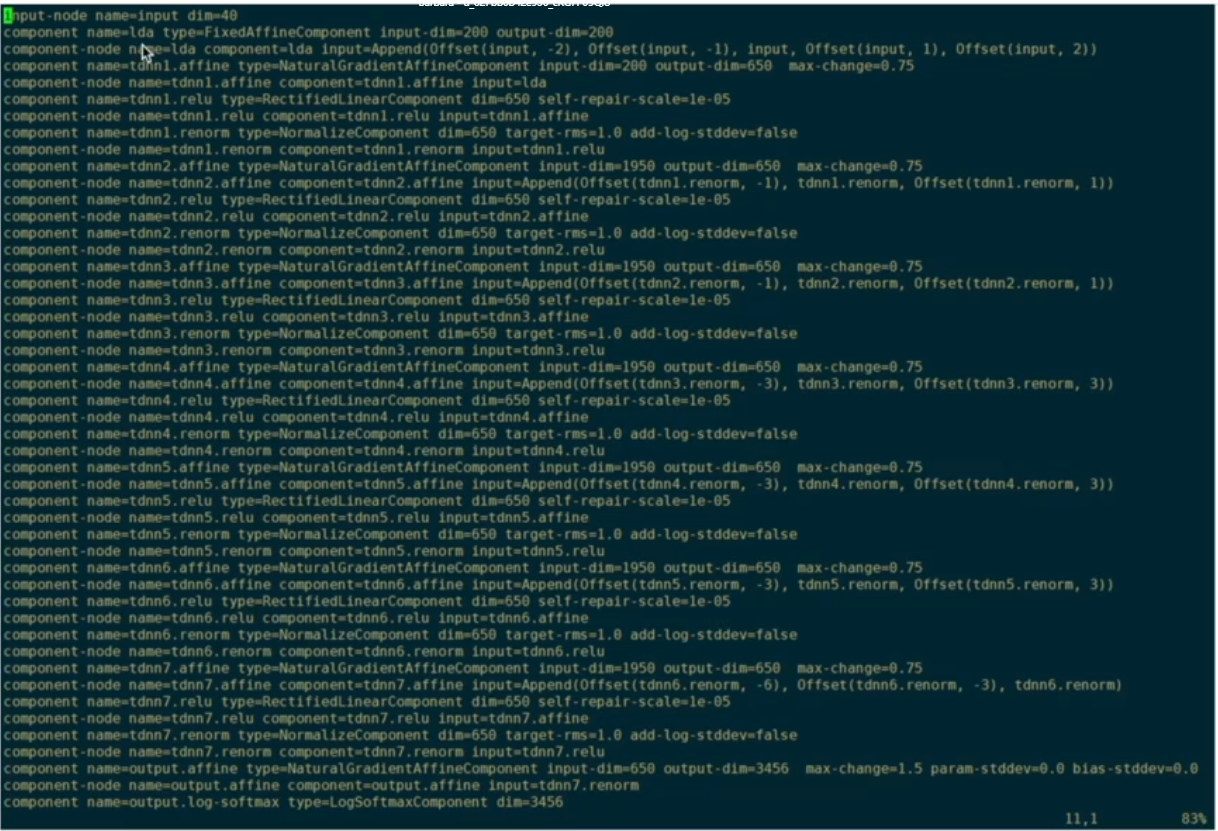
ref.raw就是从ref.config得到的完整模型,为了给kaldi提供一个参考,供kaldi遍历,能够计算出整个模型的context。
final
var,全程variable,存储模型上下文信息
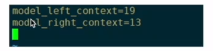
这个左右context是根据左右context是根据ref.raw计算出来的。
final.config
训练的神经网咯就是由它初始化得到的。
被解析成更小的单元 component node
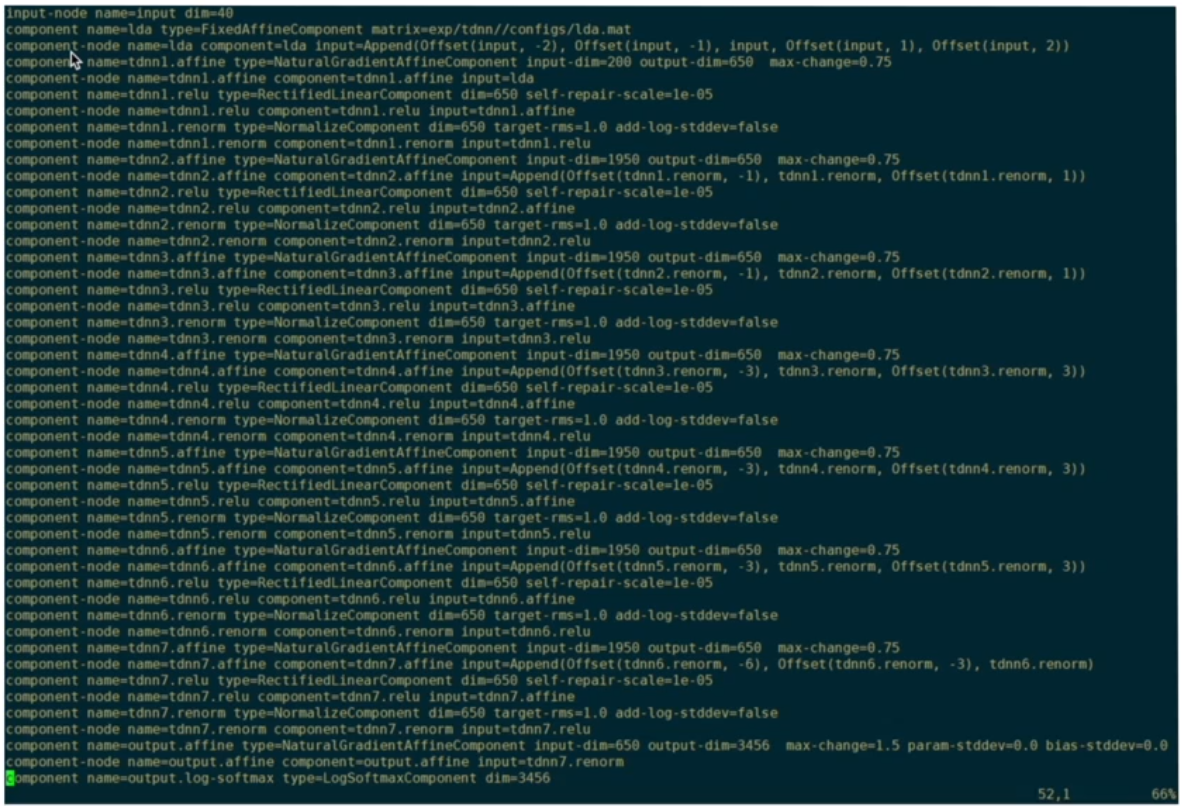
那component和component node之间是什么关系?
就是面向对象里的 类 component和 对象 component node的关系。
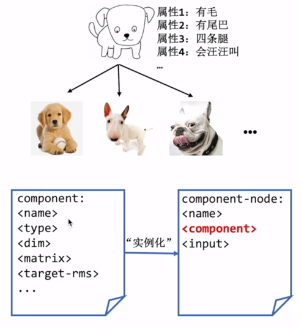
比如下面,
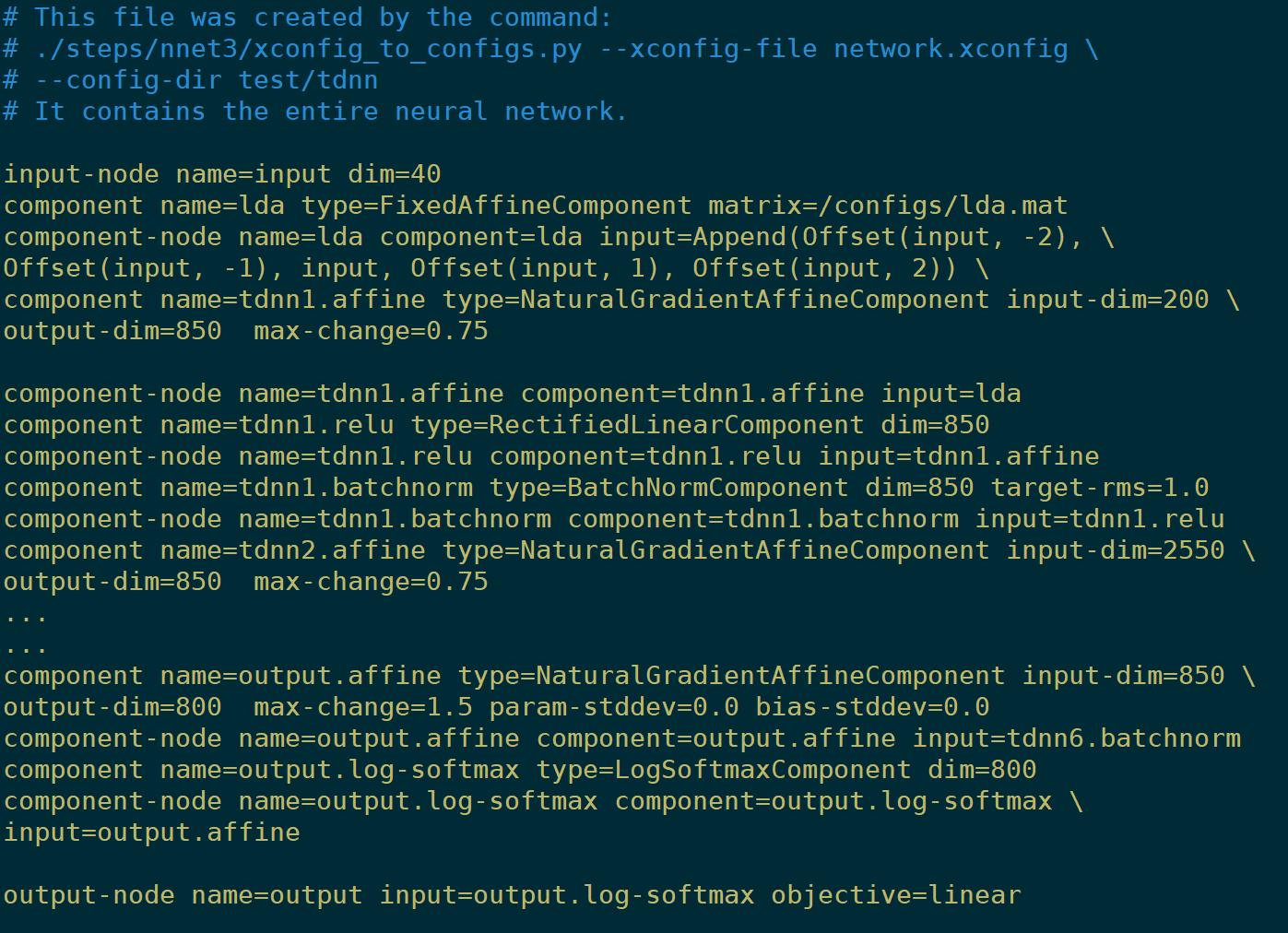
处了刚才例子中的TDNN模型中的relu-batchnorm组件,kaldi还有哪些组件呢?
xconfig_parser支持的组件都在这个文件里: kaldi/egs/steps/libs/nnet3/xconfig/parser.py
这些组件可以分为以下几类:
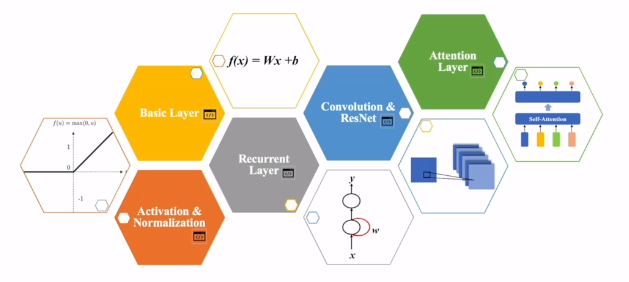
- Basic layer

- Activation & Normalization

- Recurrent layer

- Convolution layer

- Attention layer

这些组件按情况组在一起,可以DIY自己的网络。
下面介绍常见的网络模型。
Kaldi中的常见的神经网络
TDNN
一个简单的TDNN
看一下它的final.config

Append:拼接
offset:相对于当前位置的偏移,-3向历史时刻偏移3时刻,+3向未来。
一个稍微复杂的TDNN
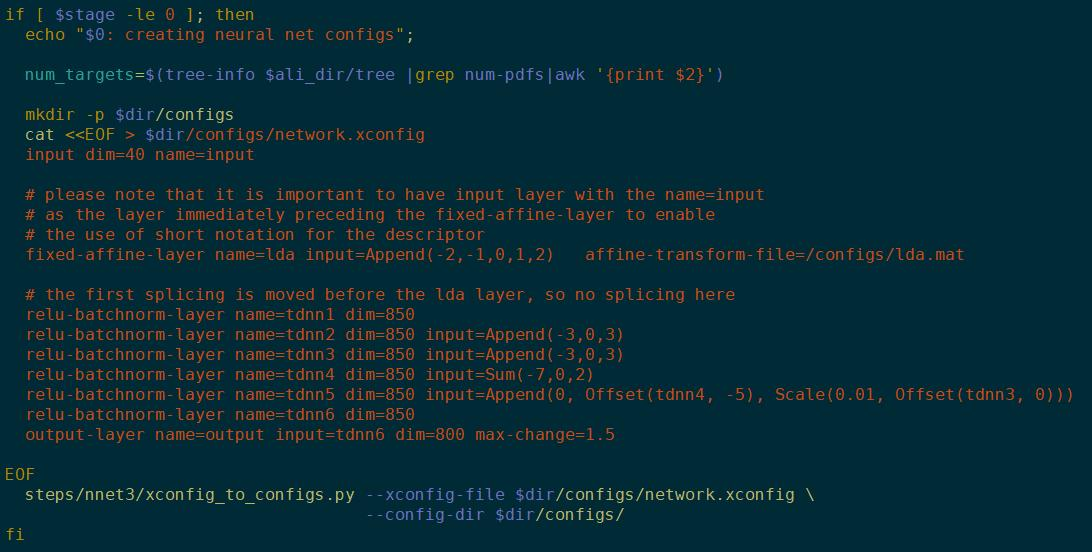

除了拼接,实现加的操作sum
直接把tdnn3的0时刻接到tdnn5
scale对某个层的输出放大、缩小
CNN
一个简单的CNN
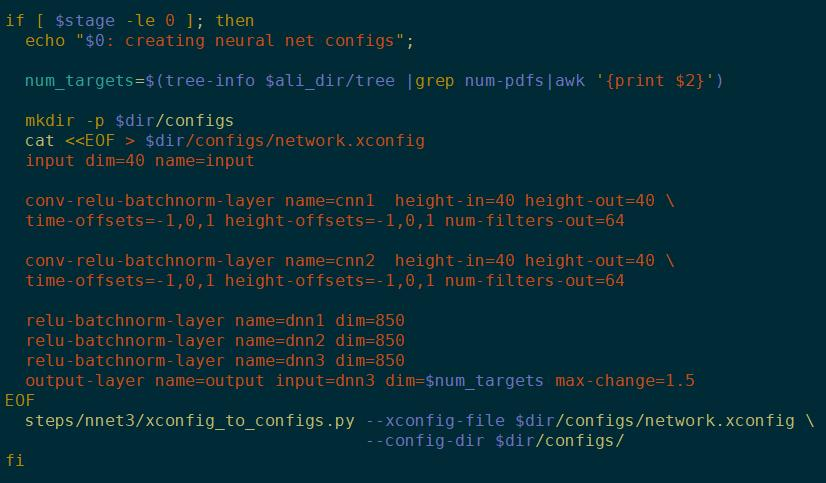
用了conv-relu-batchnorm的组件
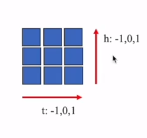
height就是FBank的维数,time-offset就是卷积核kernel的大小
代码里描述的就是一个3 *3 的卷积核
这样的组件解析出的final.config:
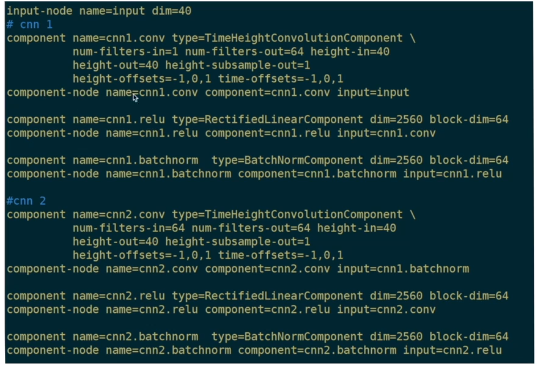
大多数参数和之前的一样,多了个height-subsample-out,指高度上的降采样率,因为输入高度height-in和输出高度height-out都是40,所以没有降采样,所以这里等于1。
另一个要注意的,num_filters_out=64,所以后面跟的component要有 block-dim=64,不然初始化模型时候会报错。
注:这里为了方面给大家看,里面有 /的换行符号,实际中kaldi是不允许有的。
LSTM
一个简单的LSTM
就多了个lstm-layer 和 cell,delay=3就是三次循环
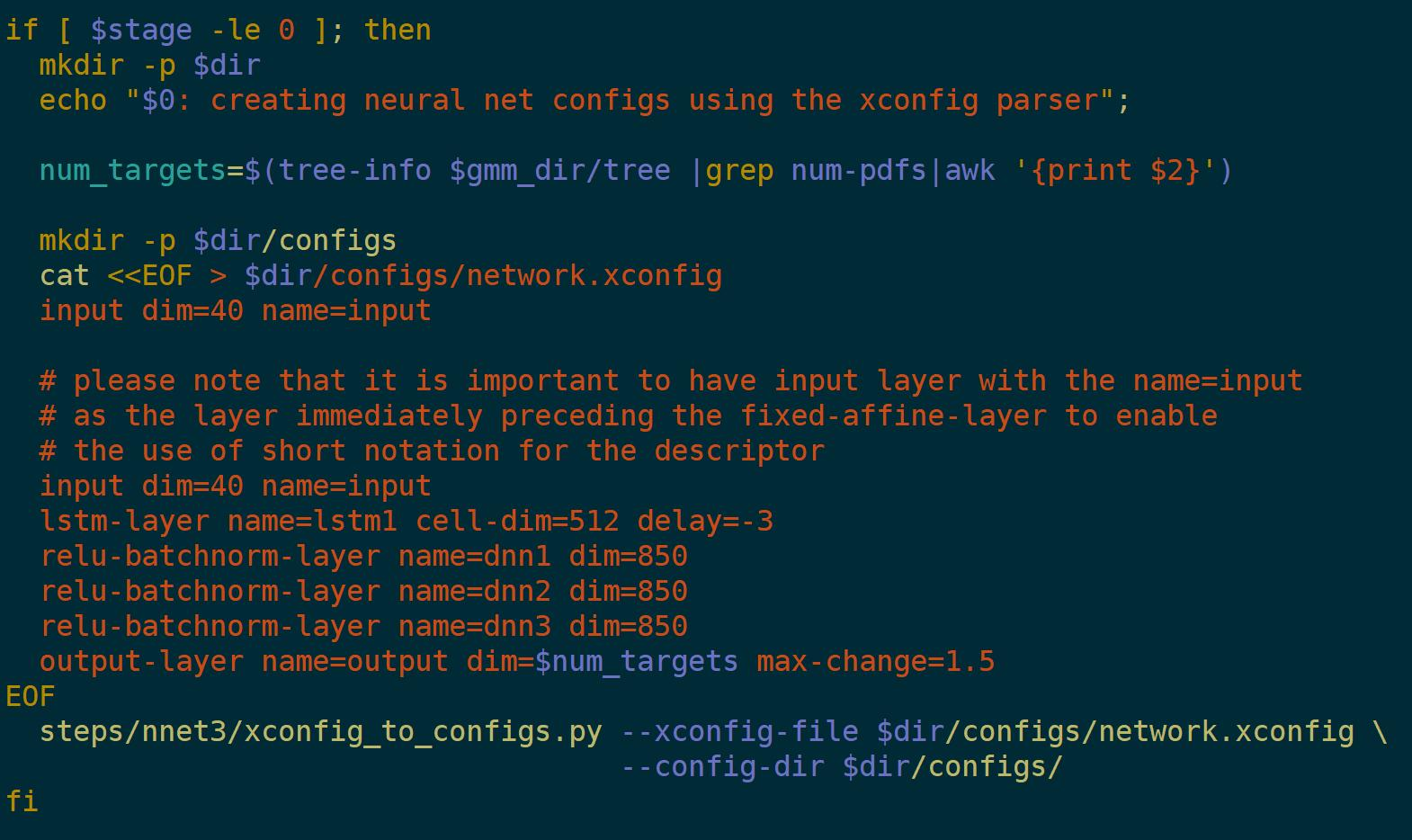
先回归一下LSTM的网络结构:
输入xt,,历史信息rt ,输出yt。细胞核Ct
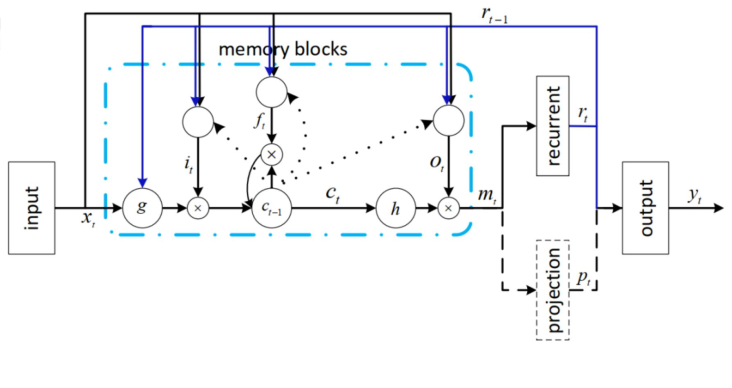
看下final-config:
因为比较复杂,下图删除了DNN的部分
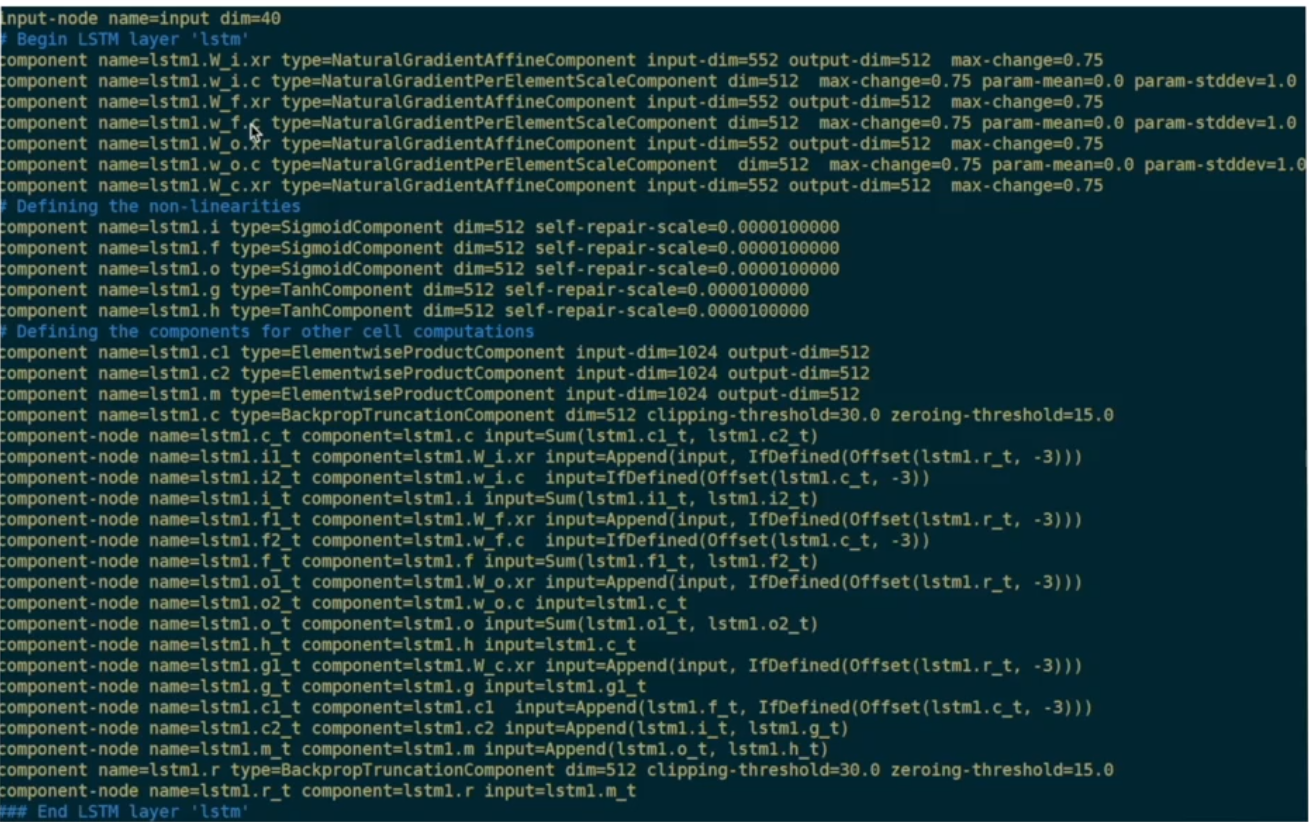
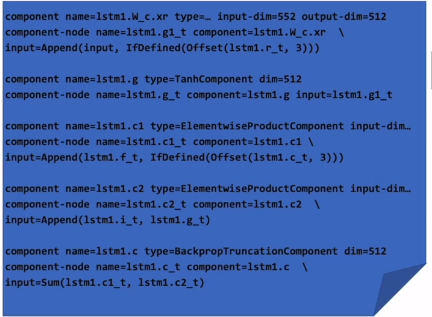
下面看看component和LSTM的公式是怎么联系起来的?

比如,以输入门为例
it 可以从图中看到有三个输入箭头,
Wix和Wir对应上面代码的第一部分(前三行)
Wic对应第二部分(中间三行),向后偏移3个时刻
第三部分就是激活函数
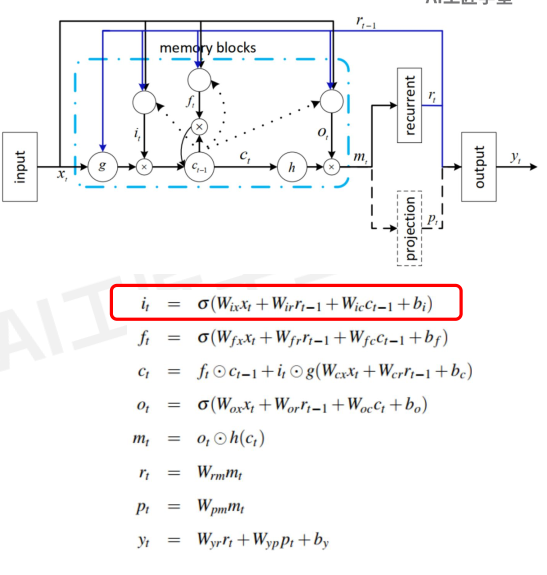
再看个细胞核Ct的计算过程:
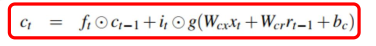
ElementwiseProduct就是点乘。
总结以下:
上面学习了如何使用Xconfig提供的组件搭建TDNN等这些网络,从component中看和公式的对应关系。等熟练了这些,就可以自己DIY网络结构。

神经网络训练流程
如何使用定义好的神经网络进行训练?
先看一个标准DNN训练的脚本:
feat-cmvn-opts:是否对参数归一化
训练前后期的jobs数,和学习率lrate,还可以用以前的egs,需不需要删掉,每多少步保存,是否用GPU,需要的文件地址,训练结束后模型存储位置
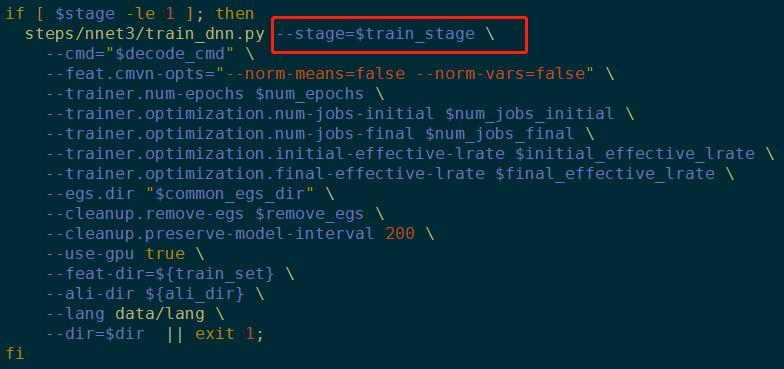
stage:描述控制训练流程
那标准的训练流程包含哪些步骤呢?
init初始化stage不控制
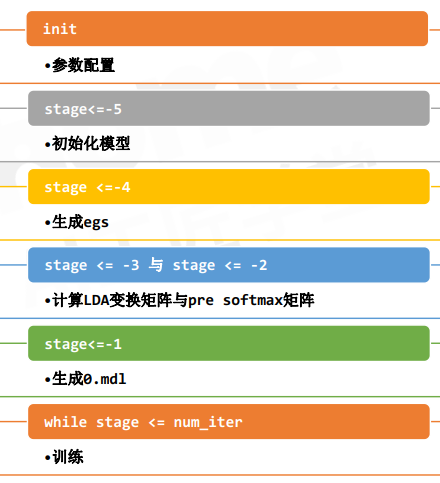
- egs:表示examples,训练使用的样例。把输入数据和标签换了一种方便读取的格式,整合在一起生成的文件。
- LDA:一般放在神经网络第一层
计算LDA变换矩阵与pre softmax矩阵就是训练的小技巧,一般数据集小的时候用到,数据量大的时候不用(此时对数据规整起不到太大作用,甚至有反作用) - stage=50,从50轮开始继续训练
一个重要的步骤egs:
stage=-4
这个目录下会生成四组文件
exp/$dir/egs
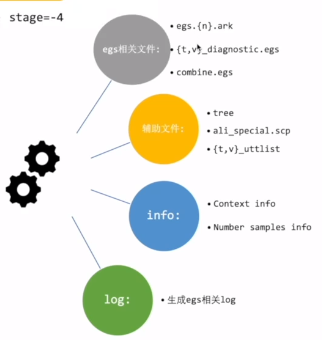
- egs相关文件
egs.{n}.ark:训练数据易于读写的,有利于训练的形式
{t,v}_diagnostic.egs:计算模型在训练集t上的loss和验证集v上的loss
combine.egs:训练结束后,用来合并多个模型的egs - 辅助文件
tree:输出节点的个数,从而确定egs的标签的上限
ali_special.scp和{t,v}_uttlist用来辅助生成{t,v}_diagnostic.egs - info
总共有多少egs,多少帧等信息
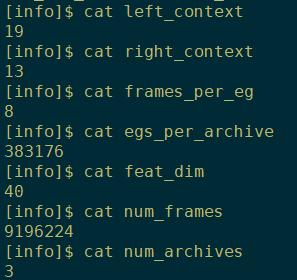
egs内部的具体信息:
参数信息:
左右context,每个egs中有8帧语音,每个大的egs里有383176个egs,特征维度feat_num,num_frames用来训练的羽音帧数,num_archives最后生成的egs个数
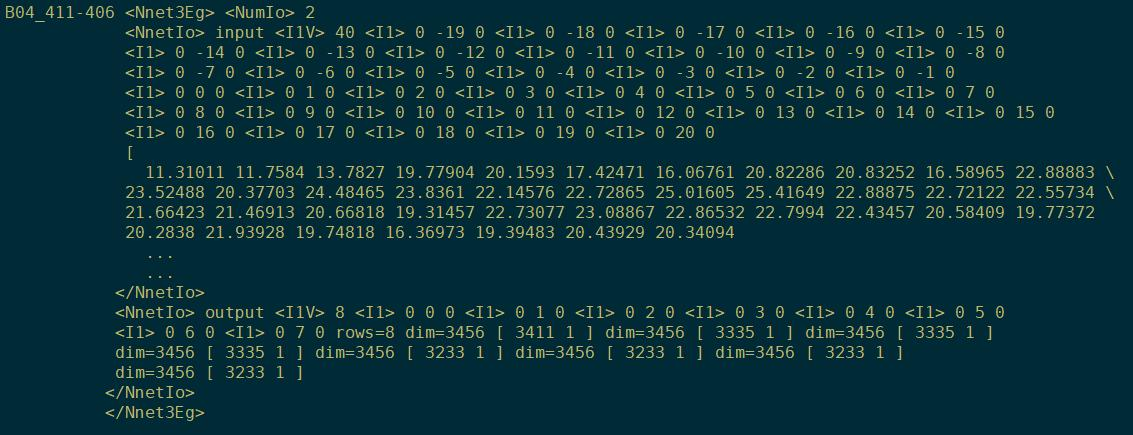
egs内部:
每个大的egs里有383176个小的egs,下面看小的egs,是kaldi读取输入输出数据的最小单元。从上面的参数知,这个小的egs里有8帧有效帧,但下图中的input是40,是包含了context的(19+13+8)
整个训练的结果
final.raw只有神经网络的参数
final.mdl是在.raw的基础上增加了些信息
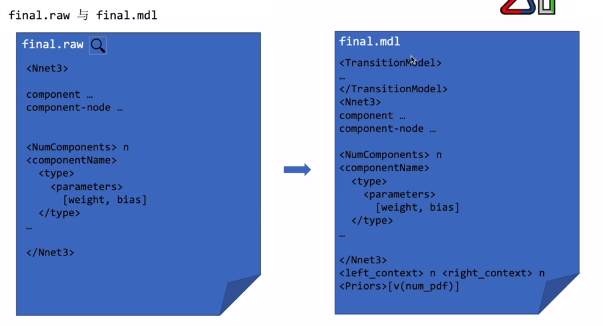
Priors:先验向量
单纯的神经网络只是计算出来后验概率,再结合TransitionModel和priors计算似然分数,才能得到声学模型
final.mdl是声学模型,final.raw只是神经网络模型

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)