Neural Voice Puppetry阅读笔记
Neural Voice Puppetry: Audio-driven Facial Reenactment
·
Neural Voice Puppetry:Audio-driven Facial Reenactment
概述
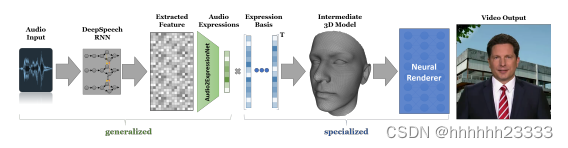
NVP(神经语音木偶)包括泛化和特化两个主要部分。对泛化部分输入一个音频序列,使用预训练的语音文本转换网络DeepSpeech RNN提取音频特征,输入到音频转表情网络预测音频对应的表情,得到驱动特化部分中3D人脸建模的混合形状系数。特化部分为每个人学习一组表情基,使得3D人脸建模具有目标人物的特质,包括面部动作和外观。使用一种新型的轻量级神经渲染网络对目标人脸模型进行新表情的渲染。
approach
- 数据预处理:
- 3D人脸跟踪:使用统计人脸模型和三角形状来表示三维潜在空间,用于建模面部动画。3D人脸模型空间将人脸空间压缩到只有几百个参数(形状为100,反照率为100,表情为76),并保持不变。利用密集人脸跟踪方法,估计序列的每一帧的模型参数。在跟踪过程中提取每帧的表情参数,用于训练音频转表情网络。存储重构的人脸网格的栅格化纹理坐标以训练神经渲染器。
- 音频特征提取:使用预训练的语音到文本模型DeepSpeech 的循环特征提取器,每一视频帧提取一个字符日志窗口。每个窗口包含16个20ms的时间间隔,产生16 × 29的音频特征。DeepSpeech模型在数千种不同的声音中进行了一般化,并在Mozilla的CommonVoice数据集上进行了训练。
- Audio2ExpressionNet:生成面部运动的时间平滑预测。采用具有两个阶段的深度神经网络::(a)获取DeepSpeech特征作为输入的每帧音频表达式估计网络,预测的每帧面部表情。(b)为了获得流畅的音频表达式,沿时间维度采用内容感知的过滤,给定每帧的噪声预测作为输入,使用神经网络预测滤波器来计算单帧平滑的音频表达式。每帧网络和滤波网络可以联合训练,输出音频表达系数。这个音频表达空间由多人共享,并被解释为混合形状系数。对于每个人,计算一个混合形状基,它在通用脸模型的子空间中。该网络训练的损失基于面部模型的顶点。
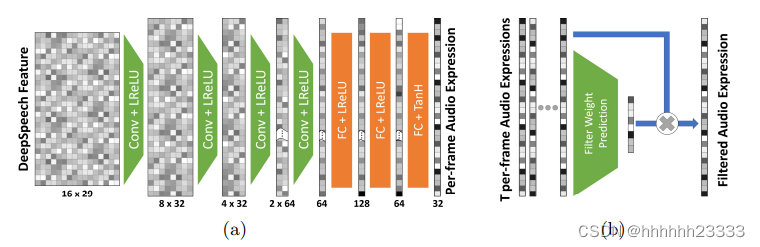
- (a)每帧音频表情估计网络:使用DeepSpeech的RNN部分提取广义音频特征,这些特征代表了20毫秒音频信号的DeepSpeech字母表日志,对于每个视频帧,在帧周围提取16个特征的时间窗口,由29个日志组成(DeepSpeech字母表的长度为29)。将得到的16×29的张量输入到每帧估计网络中,应用4个卷积层和3个全连接层映射到每帧音频表达空间。具体来说,先使用4个核维为3、步幅为2的一维卷积,并在时间维中进行过滤。卷积层有偏倚,每个Conv后面跟着一个LReLU(斜率0.02),使得特征维数依次由(16 × 29)、(8 × 32)、(4 × 32)、(2 × 64)降至(1 × 64)。这个简化的特征被输入到具有偏倚的3个全连接层,前两个FC后面也跟着一个LReLU(斜率为0.02),最后一个FC一个TanH激活。全连接层将卷积网络中的64个特征映射到128,然后映射到64,最后映射到32维的音频表达空间。
- (b)时间滤波机制:为了产生时间稳定的音频表情预测,学习一个泛化的过滤网络,它获得每帧T个估计作为输入。具体来说,使用每帧预测时间步t−T/2到t+T/2的线性组合来估计帧t的音频表达式。线性组合的权重是使用神经网络计算的,该神经网络将音频表达式作为输入(这导致了表情感知的过滤)。滤波器权重预测网络由5个核大小为3的一维卷积滤波器和一个用softmax函数激活的全连接层组成。应用一维卷积滤波器依次将特征空间从8×32、8×16、8×8、8×4、8×2缩小到8×1,每个卷积层都有偏倚,并跟着一个LReLU(负斜率0.02)激活。将卷积网络的输出输入到一个带有偏置的全连接层,该层将1×8输入映射到使用softmax函数规范化的8个滤波器权值。
- 特化表情:因人而异的特化声音表情混合形状基是通用混合形状基的线性组合,通过训练可学习到N个76×32的权重矩阵(N是训练序列的数量,76是通用混合形状的数量)。
- 损失函数:使用视觉跟踪训练语料库和基于顶点的损失函数对网络和映射矩阵进行端到端学习,在面部模型的嘴巴区域具有更高的权重(10倍)。具体来说,根据均方根(RMS)距离,从基于音频的预测人脸模型和视觉跟踪的人脸模型中计算一个顶点到顶点的距离:
L e x p r = R M S ( v t − v t ∗ ) + λ ⋅ L t e m p L_{expr}=RMS(v_t-v_t^*)+\lambda \cdot L_{temp} Lexpr=RMS(vt−vt∗)+λ⋅Ltemp
v t v_t vt表示基于帧 t t t的过滤后表情估计的顶点, v t ∗ v^*_t vt∗表示视觉跟踪的顶点。除了预测和视觉跟踪面部几何之间的绝对损失外,还使用了考虑连续帧的顶点位移的时间损失:
L t e m p = R M S ( ( v t − v t − 1 ) − ( v t ∗ − v t − 1 ∗ ) ) + R M S ( ( v t + 1 − v t ) − ( v t + 1 ∗ − v t ∗ ) ) + R M S ( ( v t + 1 − v t − 1 ) − ( v t + 1 ∗ − v t − 1 ∗ ) ) L_{temp}=RMS((v_t-v_{t-1})-(v^*_t-v^*_{t-1}))+RMS((v_{t+1}-v_t)-(v^*_{t+1}-v^*_t))+RMS((v_{t+1}-v_{t-1})-(v^*_{t+1}-v^*_{t-1})) Ltemp=RMS((vt−vt−1)−(vt∗−vt−1∗))+RMS((vt+1−vt)−(vt+1∗−vt∗))+RMS((vt+1−vt−1)−(vt+1∗−vt−1∗))
这些向前、向后和中心的差异用λ加权(在实验中λ = 20)。损失以毫米为单位。
- 神经面部渲染:采用了一种新的基于神经纹理的轻量级神经渲染技术来存储人脸的外观,渲染管道基于音频驱动的表情估计来合成目标视频中的下半张人脸。具体地说,我们使用两个网络:一个网络专注于面部内部,另一个网络将渲染嵌入到原始图像中。

基于表情预测,驱动特定于人的3D人脸模型,渲染神经纹理到目标视频的图像空间。第一网络用于将从神经纹理采样的神经描述符转换为RGB颜色值。第二个网络将该图像嵌入目标视频帧中。对合成图像周围的目标图像进行侵蚀,去除目标参与者的运动,比如下巴的运动。利用这个被侵蚀的目标图像作为背景和第一网络的输出,第二网络输出最终图像。两个网络结构相同,只是输入维度不同。第一个网络得到一个具有16个特征通道作为输入的图像(从维数为256 × 256 × 16的神经纹理中采样的神经描述符的维数),而第二个网络合成了第一个网络的背景和输出,从而得到一个6通道的输入。网络基于Pix2Pix框架实现,但是没有使用带有跨步卷积的经典U-Net,而是建立在扩张卷积的基础上。即在深度为5的U-Net中替换了跨步卷积,不使用转置卷积,而是使用标准卷积,因为模型不向下采样图像,总是保持相同的图像尺寸。此外保留经典U-Net的跳跃式连接。实验中每层特征的数量是32个,导致网络具有~ 2.35mio参数(与具有~ 16mio参数的延迟神经渲染中的网络相比,这是低的)。采用下图所示的结构:
每个卷积层的核大小为3×3,后面是一个负斜率为0.2的LReLU。所有层都有步幅为1,这意味着所有层的中间特征映射具有与输入相同的空间大小(512×512)。第一个卷积层映射到一个32维的特征空间,膨胀率为1。随着层深的增加,特征空间维度和膨胀率每层翻倍。在图层深度为5之后,使用标准卷积。- 损失函数:基于 l 1 l_1 l1损失测量绝对误差和VGG感知损失计算每帧损失:
L r e n d e r i n g = l 1 ( I , I ∗ ) + L 1 ( I ^ , I ∗ ) + V G G ( I , I ∗ ) L_{rendering}=l_1(I,I^*)+L_1(\hat I,I^*)+VGG(I,I^*) Lrendering=l1(I,I∗)+L1(I^,I∗)+VGG(I,I∗)
I I I是最终合成图像, I ∗ I^* I∗是真实图像,而 I ^ \hat I I^是第一个网络的中间结果,它关注脸部内部(损失被遮罩到这个区域)。
- 损失函数:基于 l 1 l_1 l1损失测量绝对误差和VGG感知损失计算每帧损失:
实验
- 训练:模型在PyTorch实现,使用默认设置的Adam优化器( β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 ⋅ e − 8 β_1 = 0.9, β_2 = 0.999,\epsilon = 1·e^{−8} β1=0.9,β2=0.999,ϵ=1⋅e−8),学习率为0.0001,采用Xavier初始化。
- 泛化阶段:以有监督的方式在数据集的所有序列之间训练Audio2ExpressionNet。通过视觉人脸跟踪信息,获得每一帧特定人物的3D人脸模型。在训练过程中,根据音频输入,通过优化网络参数和从音频表达空间到三维空间的个体映射,重新生成这些三维重构。Audio2ExpressionNet被训练了50个阶段(在Nvidia 1080Ti上的训练时间约为28小时),最后30个阶段的学习率衰减为16个批次。
- 特化阶段:训练针对特定目标序列的渲染网络。在给定真实图像和视觉跟踪信息的情况下,对神经渲染器进行端到端训练,包括神经纹理。渲染网络为每个目标人单独训练50个阶段,批处理规模为1(训练时间为~ 30小时,如果是跨步卷积则为~ 5小时)。
- 新目标视频:基于音频的表情估计网络在多人之间是通用的,通过求解线性方程组,可以得到预测的声音表达空间系数与新人的表达空间之间的人特异性映射。具体来说,即为提取所有训练图像的音频表达式,并计算到视觉估计的表达式的线性映射。除了这一步,新目标视频的个人特定渲染网络将从头开始训练。
- 测试:使用基于DNN的IBM Watson的文本到音频模型合成音频流作为输入。
- 结果:使用Self-reenactment来评估模型,645帧测试序列上的重渲染平均色差分别为0.003和0.005,对应的PSNR分别为41.48和36.65。使用Dlib计算了相对于眼睛距离的2D口标记距离,结果是视觉跟踪为0.022,基于音频的预测为0.055。使用SyncNet实现的唇同步的相应定量测量(偏移量/置信度):

置信度越高越好,而低于1的置信度表示不相关的音频视频流。
与其它模型比较: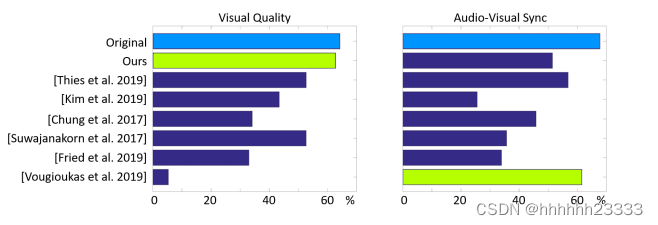
认为视觉和视听质量良好或非常好的参会者的百分比(总共56人)
(a):与基于图像的方法的比较
(b):与带有GANs的逼真语音驱动面部动画模型的比较
与其它音频驱动模型比较,Suwajanakorn等人的方法能够产生逼真的输出,但该方法适用于目标人员的大型视频数据集,因此其适用性有限。NVP适用于短的2 - 3分钟的目标视频剪辑。
总结
- 提出了一种新的基于声音驱动的人脸重现方法,该方法适用于不同的音频源。NVP不仅可以从另一个人的音频序列合成一个会说话的头部的视频,还可以基于合成的声音生成一个逼真的视频,即,可以实现与人工语音同步的文本驱动视频合成。
- 在音频流中有多个声音的情况下,NVP会失败,原始视频的视听同步必须很好。

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)