

双向长短期记忆网络(BiLSTM)详解
双向长短期记忆网络BiLSTM
双向长短期记忆网络(BiLSTM)详解
一、前言
在学习BiLSTM之前,首先需要对RNN和LSTM有一定的了解,可以参考本人的博客:详细讲解RNN+LSTM+Tree_LSTM(Tree-Long Short Term Memory)基于树状长短期记忆网络,里面讲解了从RNN发展到LSTM的全过程。😃😃😃
二、BiLSTM简介
BiLSTM全称:Bi-directional Long Short-Term Memory,由前向LSTM与后向LSTM组合而成。
为什么要有LSTM和BiLSTM:
将词的表示组合成句子的表示,可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法,但是这些方法没有考虑到词语在句子中前后顺序。如句子“我不觉得他好”。“不”字是对后面“好”的否定,即该句子的情感极性是贬义。使用LSTM模型可以更好的捕捉到较长距离的依赖关系。因为LSTM通过训练过程可以学到应该记忆哪些信息和遗忘哪些信息。
但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
三、BiLSTM是如何运转的
如图所示:单层的BiLSTM是由两个LSTM组合而成,一个是正向去处理输入序列;另一个反向处理序列,处理完成后将两个LSTM的输出拼接起来。在上图中,只有所有的时间步计算完成后,才能得到最终的BiLSTM的输出结果。正向的LSTM经过6个时间步得到一个结果向量;反向的LSTM同样经过6个时间步后得到另一个结果,将这两个结果向量拼接起来,得到最终的BiLSTM输出结果。
四、详细分析BiLSTM运转流程
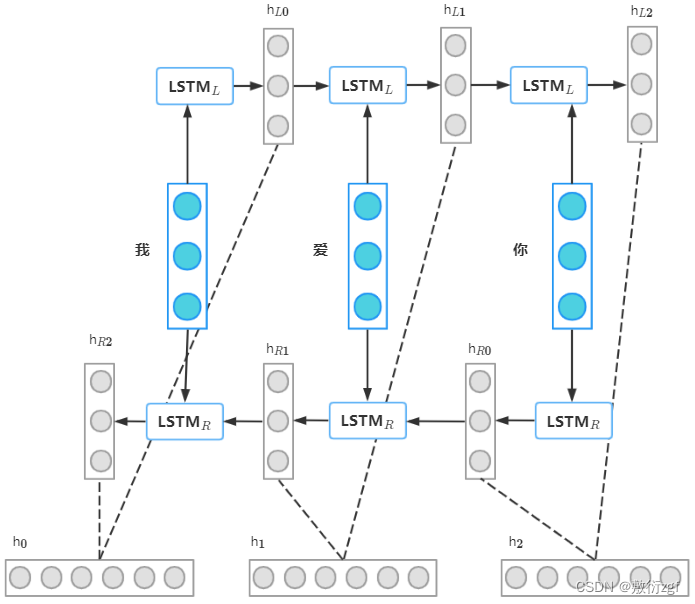
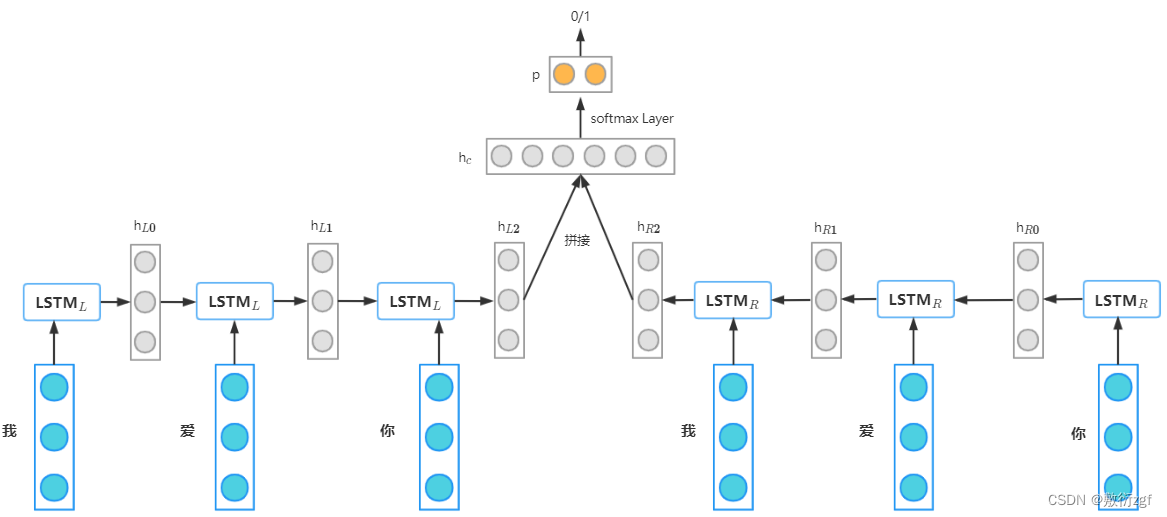
前向的LSTML依次输入“我”,“爱”,“你”得到三个向量{hL0,hL1,hL2}。后向的LSTMR依次输入“你”,“爱”,“我”得到三个向量{hR0,hR1,hR2}。最后将前向和后向的隐向量进行拼接得到{[hL0,hR2],[hL1,hR1],[hL2,hR0]},即{h0,h1,h2}。对于情感分类任务来说,我们采用的句子表示往往是[hL2,hR2],因为这其中包含了前向和后向的所有信息。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 44
44 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)