深度学习多进程GPU部署(二)- 深度学习部署
下面针对使用多台裸机使用分布式的场景提供指导,总体而言,强烈推荐使用 docker 环境部署使用分布式训练当机器数量多于 5 台且长期使用时,建议使用 Kubernetes 部署 或其他类似集群管理工具使用。
根据环境情况,实现深度学习算法应用分布式多进程,可以分为:
- 裸机部署
- docker环境
- kubernetes部署
下面针对使用多台裸机使用分布式的场景提供指导,总体而言,
强烈推荐使用 docker 环境部署使用分布式训练
当机器数量多于 5 台且长期使用时,建议使用 Kubernetes 部署 或其他类似集群管理工具使用
深度学习GPU部署
Fast API部署
Fast API 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 3.6+ 并基于标准的 Python 类型提示。
使用FastAPI接口,如果想调用这个接口,启动接口,需要安装一个ASGI服务器,生产环境下可以使用Uvicorn或者Hypercorn
WSGI与ASGI
wsgi和ASGI都是web服务器网关接口,是一套Web Server与APP之间的接口标准协议/规范,确保不同Web服务器可以和不同的Python程序之间相互通信。
ASGI在WSGI的基础上实现了异步服务器网关接口
可以说ASGI就是WSGI的加强版
对于不同的生产环境框架,在实际生产环境中,Flask更适合app,Gunicorn/uswgi适合wsgi,Uvicorn 、Daphne 、Hypercorn 更适合asgi
安装
安装fastapi和Uvicorn
pip install fastapi
pip install "uvicorn[standard]"
fast_api接口实例
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
启动接口服务
uvicorn main:app --reload
- main:main.py 文件(一个 Python “模块”)。
- app:在 main.py 文件中通过 app = FastAPI(),创建的对象。
- –reload:让服务器在更新代码后重新启动。仅在开发时使用该选项。
uvicorn 常用参数
| 参数 | 作用 |
|---|---|
| app | 运行py文件 |
| host | 访问的url |
| port | 访问端口 |
| reload | 热更新,有内容修改自动重启服务器 |
| debug | 同reload |
| reload_dirs | |
| log_level | 设置日志级别 |
fast_api提供交互式API文档,访问 http://127.0.0.1:8000/docs
在这里可以输入传入到接口的参数,然后点进execute执行,就会得到对应的curl命令。
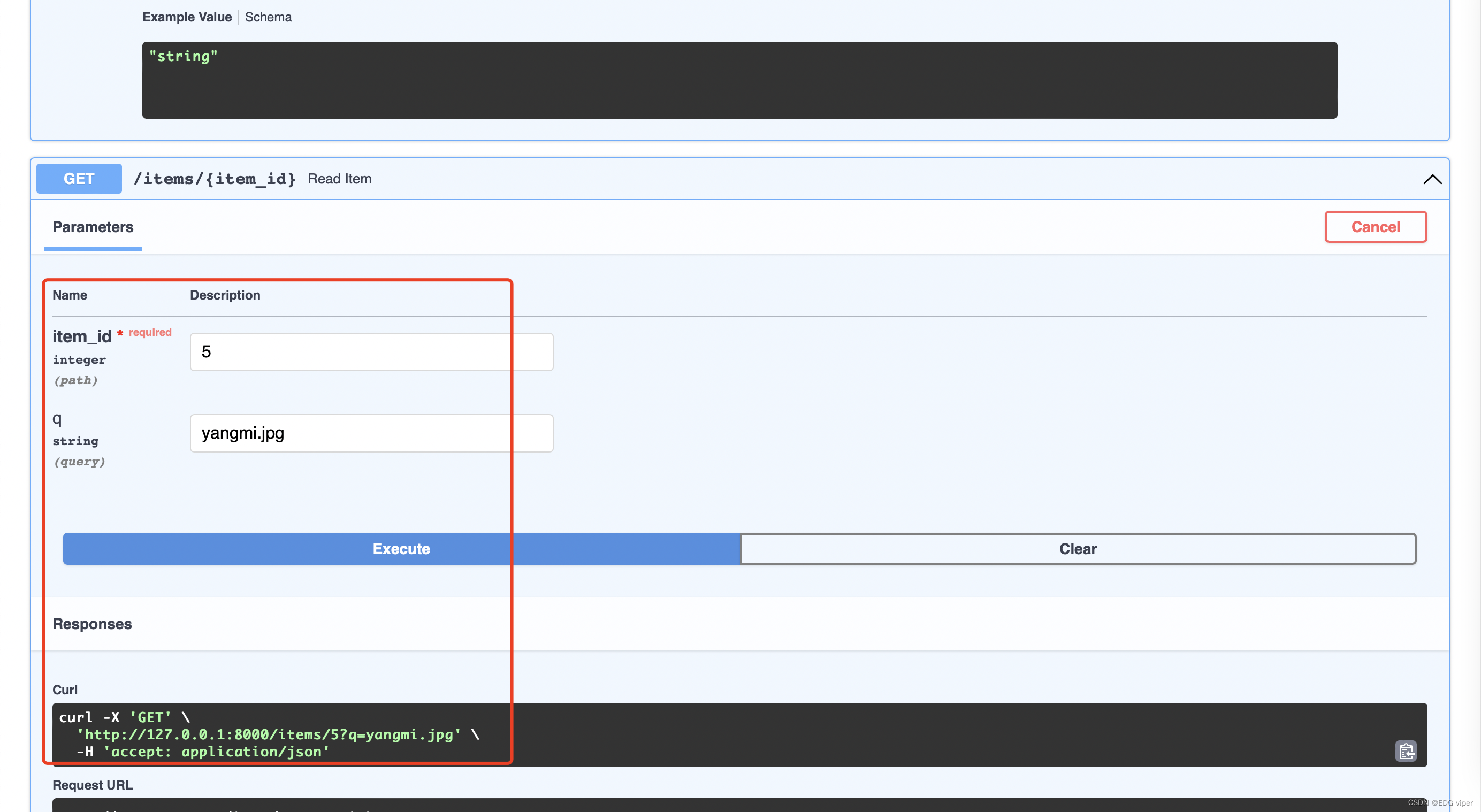
fast_api实现线性模型
api.py
import uvicorn as uvicorn
from fastapi import FastAPI
import joblib
from linear import LS
from os.path import dirname, join, realpath
app = FastAPI(title="Iris Prediction Model API",
description="A simple API that use LogisticRegression model to predict the Iris species",
version="0.1",) # 必须实例化该类,启动的时候调用
# 请求根目录
@app.get('/')
def index():
return {'message': 'iris线性模型!'}
def data_clean(str):
arr = str.split(',')
arr = list(map(float,arr))
return arr
# get请求带参数数据
@app.get('/predict')
def predict(request):
LS()
print(dirname(realpath(__file__)))
with open(join(dirname(realpath(__file__)),'irisclassifier.pkl'),"rb") as f:
model = joblib.load(f)
request = data_clean(request)
prediction = model.predict([request])
output = int(prediction[0])
probas = model.predict_proba([request])
output_probability = "{:.2f}".format(float(probas[:, output]))
# output dictionary
species = {0: "Setosa", 1: "Versicolour", 2: "Virginica"}
# show results
result = {"prediction": species[output], "Probability": output_probability}
return result
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=8001)
linear.py
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
import joblib
from sklearn import datasets
def LS():
iris = datasets.load_iris()
x = iris.data
y = iris.target
print('___')
clf = LogisticRegression()
p = Pipeline([('clf',clf)])
print('training model...')
p.fit(x,y)
print('model trained')
model_pkl = 'irisclassifier.pkl'
print('Saving model in %s'%model_pkl)
joblib.dump(p,model_pkl)
print('model saved!')
uvicorn启动接口服务的方法:
uvicorn 像是一个流管理器,专门用来处理python线程的
python启动
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=8001)
Uvicorn命令启动
uvicorn api:app --port 5000 --host 0.0.0.0
这里的api就是启动程序的代码py文件名
Gunicorn启动
Gunicorn 是成熟的,功能齐全的服务器,Uvicorn 内部包含有 Guicorn 的 workers 类,允许你运行 ASGI 应用程序,这些 workers 继承了所有 Uvicorn 高性能的特点,并且给你使用 Guicorn 来进行进程管理。
这样的话,你可能动态增加或减少进程数量,平滑地重启工作进程,或者升级服务器而无需停机。
在生产环境中,Guicorn 大概是最简单的方式来管理 Uvicorn 了,生产环境部署我们推荐使用 Guicorn 和 Uvicorn 的 worker 类:
gunicorn example:app -w 4 -k uvicorn.workers.UvicornWorker
具体fast 和uvicorn使用可以参考文档:
uvicorn:https://www.uvicorn.org/
fastapi:https://fastapi.tiangolo.com/zh/
fast_api实现Yolov5模型
要想使用GPU,那就只能用深度学习模型才能使用,这里用yolov5模型,使用预训练模型torch.load(),来做个实例
翻阅资料pytorch官网只有多GPU训练的部分,没有介绍有类似模型推理部署api,多GPU并行的
yolov5预训练模型,使用实例代码如下:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# Images
imgs = ['https://ultralytics.com/images/zidane.jpg'] # batch of images
# Inference
results = model(imgs)
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # img1 predictions (tensor)
results.pandas().xyxy[0] # img1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
fast_api部署代码
yolov5_api.py
import torch
import uvicorn as uvicorn
from typing import Union
from fastapi import FastAPI
app =FastAPI(title="Yolov5 Model API",
description="A simple API that use Yolov5 model to predict the image species",
version="0.1")
def yolov5_model():
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5/yolov5s6.pt')
model.conf = 0.6 # confidence threshold (0-1)
model.iou = 0.2 # NMS IoU threshold (0-1)
device_ids = [0,1,2,3]
#Parallel
model = torch.nn.DataParallel(model,device_ids=device_ids)
model = model.cuda(device=device_ids[0])
return model
# 请求根目录
@app.get('/')
def index():
return {'message': 'yolov5 model!'}
# get请求带参数数据
@app.get('/items/{item_id}')
def predict(item_id:str,q:Union[str, None] = None):
img = q
print(img)
# Inference
model = yolov5_model()
results = model(img, size=1920, augment=True)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
results.show()
print(results.xywhn)
print(results.xyxy)
print(results.pandas().xyxy[0].to_json(orient="records"))
result = {"prediction": results.pandas().xyxy[0].to_json(orient="records")}
return result
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=8001)

开源、云原生的融合云平台
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)