Kubernetes — 日志管理方案
容器引擎或运行时提供的本地功能通常不足以支撑完整的日志记录解决方案。例如,一个容器崩溃、一个Pod被驱逐、或者一个Node死亡,往往仍然需求可以访问应用程序的日志。日志应该具有独立于Node、Pod或者容器的单独存储和生命周期,这个概念被称为Cluster 级日志记录需要一个独立的后端来存储、分析和查询日志Kubernetes 本身并没有为日志数据提供原生的存储解决方案,但可以将许多现有的日志记录
目录
2. 查看elasticsearch软件包信息,所需相关配置信息
一、Kubernetes 日志管理
1、简介
1. 容器引擎或运行时提供的本地功能通常不足以支撑完整的日志记录解决方案。
例如,一个容器崩溃、一个Pod被驱逐、或者一个Node死亡,
往往仍然需求可以访问应用程序的日志。
2. 日志应该具有独立于Node、Pod或者容器的单独存储和生命周期,这个概念被称为
cluster-level-logging。
Cluster 级日志记录需要一个独立的后端来存储、分析和查询日志
3. Kubernetes 本身并没有为日志数据提供原生的存储解决方案,但可以将许多现有的日志记录解决方案集成到Kubernetes 集群中。
参考文档: 日志架构 | Kubernetes
2、日志的三个级别
1. Pod级别日志
1. Kubernetes Pod 日志数据输出到标准输出流时,可以使用kubectl logs 命令获取容器日志信息
$ kubectl -n kube-system get pod etcd-k8s-master #查看系统空间的pod状态 NAME READY STATUS RESTARTS AGE etcd-k8s-master 1/1 Running 8 (66m ago) 39d $ kubectl -n kube-system logs etcd-k8s-master #查看pod日志2. 但是使用该方式时,当Pod 消亡时,这些日志就无法通过这种方式获取了。你可以快速查看Pod 的健康状况,而不需要搭建一套大的日志收集集群
$ kubectl -n kube-system describe pods etcd-k8s-master #当pod故障时,可通过describe查看
2. Node级别日志
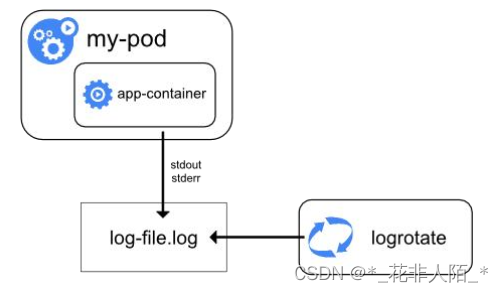
1. 容器化应用写入 stdout 和 stderr 的任何数据,都会被容器引擎捕获并被重定向到某个位置。Docker 将这两个输出流重定向到某个日志驱动,该日志驱动在 K8s 中配置为以json格式写入文件(和运行时有关)
$ ls /var/log/pods/ #此目录中的文件夹,对应的就是正在运行的pod $ ls /var/log/pods/kube-system_kube-apiserver-k8s-master_f737a6523b3acaf296aab9ddc03d5a50/kube-apiserver/ 0.log 1.log '以api-server为例' $ sudo apt-get install jq #安装查看json文件工具 $ sudo cat /var/log/pods/kube-system_kube-apiserver-k8s-master_f737a6523b3acaf296aab9ddc03d5a50/kube-apiserver/7.log | jq2. Node级别的日志比Pod级别的日志更有持续性(因为Pod的日志都是临时的)。
即使一个Pod被重启了,它之前的日志也会保留在节点上。
但是如果一个Pod被从一个节点上驱逐了,那么它的日志数据也会被驱逐
3. 节点级日志记录中,需要重点考虑实现日志的切割和压缩,以此来保证日志不会消耗节点上所有的可用空间
4. 每一个节点(node)的日志收集存储在一个JSON文件中
3. Cluster级别的日志架构
1. Node级和Pod级的日志在Kubernetes中是非常重要的概念,但它们本身不是一个实际的解决方案。
它们是构建一个实际的集群级别日志系统解决方案的基石
2. Cluster 级别的日志处理系统,与容器、Pod 以及 Node 的生命周期完全无关,这种设计就是为了保证,无论是容器退出、Pod被删除,甚至节点宕机的时候,应用的日志依然可以被正常获取到
3. K8s没有为集群级日志记录提供原生的解决方案
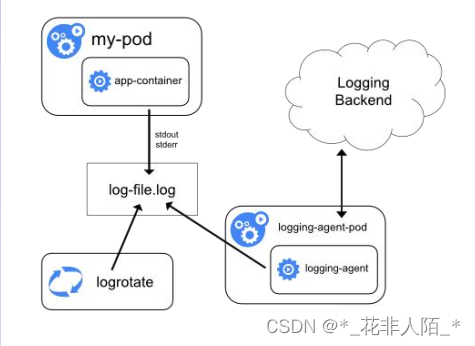
① 使用在每个节点上运行的节点级日志记录代理
- 最常用和被推荐的方式
- 在Node上部署logging agent(做日志代理,日志写在node)
- 专门的工具,是一个容器
- 日志代理必须在每个节点上运行
- 通常用DaemonSet 的形式运行
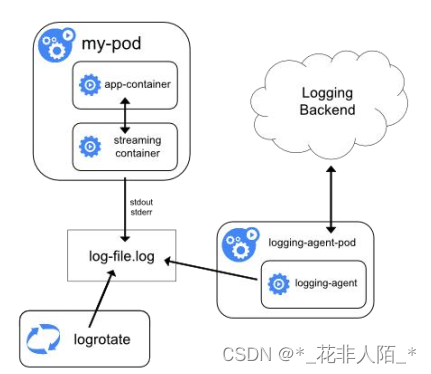
② 在应用程序的Pod中,包含专门记录日志的边车(Sidecar)容器
(区别在于logging-agent放在哪)
Sidecar方案1:
- Sidecar跟主容器之间共享Volume,额外性能损耗不高
Sidecar方案2:
- 严重的资源损耗
- 不能使用kubectl logs 访问日志
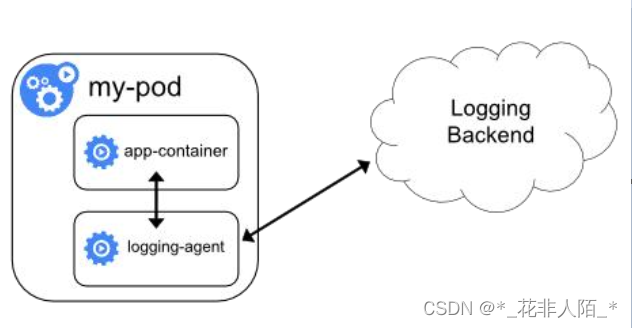
③ 将日志直接从应用程序中推送到日志记录后端
- 从各个应用中直接暴露和推送日志数据的集群日志机制已超出k8s的范围
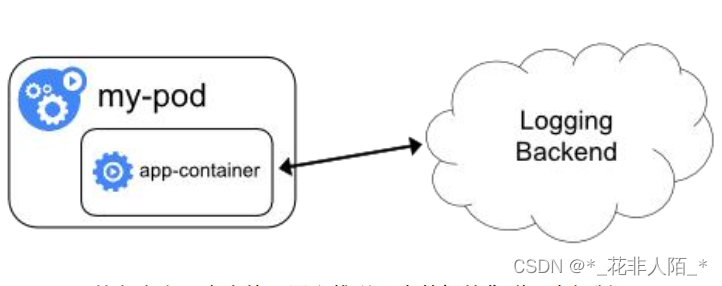
二、EFK 日志管理
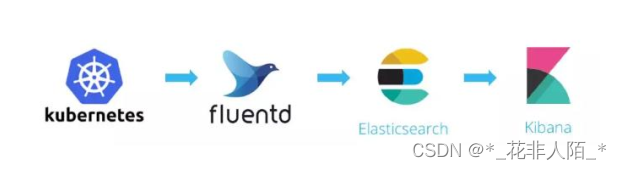
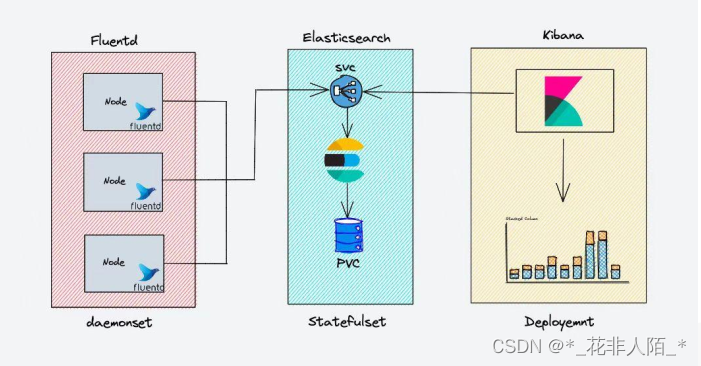
1、EFK日志管理解决方案
1. Elasticsearch 是一个搜索引擎,负责存储日志并提供查询接口(可以用nfs共享再pv做成条件自动匹配)
2. Fluentd (通过kubelet服务,在工作节点安装agent,将日志搜集出)负责从 Kubernetes 搜集日志并发送给 Elasticsearch(弹性搜索)
3. Kibana(web界面展示)提供了一个Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志通过暴露或推送每个应用的日志(C/S , B/S体系)
参考资料: 日志架构 | Kubernetes
2、安装Elasticsearch
1.安装helm
参照链接文档安装好helm后,添加仓库:
$ helm repo add elastic https://helm.elastic.co && \ helm repo add fluent https://fluent.github.io/helm-charts $ helm repo update$ helm search repo #查看仓库列表 NAME CHART VERSION APP VERSION DESCRIPTION elastic/apm-server 7.17.3 7.17.3 Official Elastic helm chart for Elastic APM Server #日志收集 elastic/eck-elasticsearch 0.1.0 A Helm chart to deploy Elasticsearch managed by... elastic/eck-kibana 0.1.0 A Helm chart to deploy Kibana managed by the EC... elastic/eck-operator 2.4.0 2.4.0 A Helm chart for deploying the Elastic Cloud on... elastic/eck-operator-crds 2.4.0 2.4.0 A Helm chart for installing the ECK operator Cu... elastic/eck-stack 0.1.0 A Parent Helm chart for all Elastic stack resou... elastic/elasticsearch 7.17.3 7.17.3 Official Elastic helm chart for Elasticsearch elastic/filebeat 7.17.3 7.17.3 Official Elastic helm chart for Filebeat #日志收集 elastic/kibana 7.17.3 7.17.3 Official Elastic helm chart for Kibana elastic/logstash 7.17.3 7.17.3 Official Elastic helm chart for Logstash #日志收集 elastic/metricbeat 7.17.3 7.17.3 Official Elastic helm chart for Metricbeat #日志收集 fluent/fluent-bit 0.20.9 1.9.9 Fast and lightweight log processor and forwarde... #轻量级的日志收集,专门针对K8S做集成用的 fluent/fluentd 0.3.9 v1.14.6 A Helm chart for Kubernetes #稍微重量级的日志收集参照上篇文档: Helm 包管理工具_*_花非人陌_*的博客-CSDN博客
2. 查看elasticsearch软件包信息,所需相关配置信息
$ helm inspect values elastic/elasticsearch | less #查看软件包配置信息
...输出省略
# These will be set as environment variables. E.g. node.master=true
roles:
master: "true"
ingest: "true"
data: "true"
remote_cluster_client: "true"
ml: "true"
replicas: 3 #副本数量 ,因为有2个node所以这个要改2
minimumMasterNodes: 2 #master数量,因为当前只有一个master,也要改1
...输出省略
hostAliases: []
#- ip: "127.0.0.1"
# hostnames:
# - "foo.local"
# - "bar.local"
image: "docker.elastic.co/elasticsearch/elasticsearch" #仓库地址需要修改
imageTag: "7.17.3"
imagePullPolicy: "IfNotPresent"
...输出省略
resources: #需求的资源配置
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
...输出省略
volumeClaimTemplate: #PVC模板,pv数量和副本数量一致
accessModes: ["ReadWriteOnce"]#权限
resources:
requests:
storage: 30Gi
...输出省略
persistence: #数据卷是否持久
enabled: true
...输出省略
service: #service
enabled: true
labels: {}
labelsHeadless: {}
type: ClusterIP #默认的service类型
...输出省略
若总有镜像拉取失败时,可通过编辑yaml文件方式重新加载
$ kubectl edit pods fluent-bit-wnpqk -o yaml
3. 配置nfs&创建PV
'配置NFS' $ sudo apt -y install nfs-kernel-server $ sudo mkdir -m 777 /nfs_log{0..1} $ sudo tee /etc/exports <<EOF #生成配置文件 /nfs_log0 *(rw,no_root_squash) /nfs_log1 *(rw,no_root_squash) EOF $ systemctl restart nfs-server.service #重启服务 $ showmount -e #查看nfs挂载 Export list for k8s-master: /nfs_log1 * /nfs_log0 *'创建2个PV' $ kubectl apply -f- <<EOF apiVersion: v1 kind: PersistentVolume metadata: name: pv-log0 spec: capacity: storage: 30Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle nfs: path: /nfs_log0 server: 192.168.5.100 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv-log1 spec: capacity: storage: 30Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle nfs: path: /nfs_log1 server: 192.168.5.100 EOF $ kubectl get pv #查看PV状态 NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLA pv-log0 30Gi RWO Recycle Available 67s pv-log1 30Gi RWO Recycle Available 67s
4. 安装elasticsearch
①. 安装elasticsearch
$ helm install elasticsearch elastic/elasticsearch --set replicas=2,minimumMasterNodes=1,image="registry.cn-hangzhou.aliyuncs.com/k-cka/elasticsearch" NAME: elasticsearch LAST DEPLOYED: Tue Oct 18 17:20:43 2022 NAMESPACE: default STATUS: deployed REVISION: 1 NOTES: 1. Watch all cluster members come up. $ kubectl get pods --namespace=default -l app=elasticsearch-master -w2. Test cluster health using Helm test. $ helm --namespace=default test elasticsearch②. 查看创建过程
$ kubectl get pods --namespace=default -l app=elasticsearch-master -w NAME READY STATUS RESTARTS AGE ... elasticsearch-master-1 `1/1` Running 0 5m33s elasticsearch-master-0 `1/1` Running 0 5m33s <Ctrl-C>③. 查看状态
'测试,会自动在集群中新建一个pod,来测试当前的elasticsearch是否正常' $ helm --namespace=default test elasticsearch #使用helm测试集群健康状态 ...输出省略... Phase: `Succeeded` $ kubectl get statefulsets.apps elasticsearch-master NAME READY AGE elasticsearch-master 2/2 6m $ kubectl get services #查看发现有两个service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticsearch-master ClusterIP 10.96.101.76 <none> 9200/TCP,9300/TCP 146m elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 146m官网: Elasticsearch:官方分布式搜索和分析引擎 | Elastic
官方资料: GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine
3、安装fluent(每个工作节点会安装一个fluent)
1. 安装fluent
$ helm install fluent-bit fluent/fluent-bit
NAME: fluent-bit
LAST DEPLOYED: Fri Oct 21 15:21:12 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
Get Fluent Bit build information by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=fluent-bit,app.kubernetes.io/instance=fluent-bit" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 2020:2020
curl http://127.0.0.1:2020
2. 设定变量读出当前pod名字
$ export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=fluent-bit,app.kubernetes.io/instance=fluent-bit" -o jsonpath="{.items[0].metadata.name}")
$ echo $POD_NAME #显示pod名
fluent-bit-58sl8
3. 服务导出(监控)
$ kubectl --namespace default port-forward $POD_NAME 2020:2020#服务导出
Forwarding from 127.0.0.1:2020 -> 2020
Forwarding from [::1]:2020 -> 2020
'当前终端已被占用,额外开启终端验证'
4. 访问验证
$ sudo apt -y install jq #安装jq,方便查看
$ curl http://127.0.0.1:2020 | jq #访问测试,代表fluent已正常工作
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 759 0 759 0 0 35161 0 --:--:-- --:--:-- --:--:-- 39947
{
"fluent-bit": {
"version": "1.9.9",
"edition": "Community",
"flags": [
"FLB_HAVE_IN_STORAGE_BACKLOG",
"FLB_HAVE_PARSER",
"FLB_HAVE_RECORD_ACCESSOR",
"FLB_HAVE_STREAM_PROCESSOR",
"FLB_HAVE_TLS",
"FLB_HAVE_OPENSSL",
"FLB_HAVE_METRICS",
"FLB_HAVE_AWS",
"FLB_HAVE_AWS_CREDENTIAL_PROCESS",
"FLB_HAVE_SIGNV4",
"FLB_HAVE_SQLDB",
"FLB_LOG_NO_CONTROL_CHARS",
"FLB_HAVE_METRICS",
"FLB_HAVE_HTTP_SERVER",
"FLB_HAVE_SYSTEMD",
"FLB_HAVE_FORK",
"FLB_HAVE_TIMESPEC_GET",
"FLB_HAVE_GMTOFF",
"FLB_HAVE_UNIX_SOCKET",
"FLB_HAVE_LIBYAML",
"FLB_HAVE_ATTRIBUTE_ALLOC_SIZE",
"FLB_HAVE_PROXY_GO",
"FLB_HAVE_JEMALLOC",
"FLB_HAVE_LIBBACKTRACE",
"FLB_HAVE_REGEX",
"FLB_HAVE_UTF8_ENCODER",
"FLB_HAVE_LUAJIT",
"FLB_HAVE_C_TLS",
"FLB_HAVE_ACCEPT4",
"FLB_HAVE_INOTIFY",
"FLB_HAVE_GETENTROPY",
"FLB_HAVE_GETENTROPY_SYS_RANDOM"
]
}
}
'Ctrl + c' #关闭正则监控的终端
5. fluent 配置文件
$ kubectl edit configmaps fluent-bit #可以查看相关环境配置,不用修改
6. 查看pod状态
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
elasticsearch-master-0 1/1 Running 0 10h 172.16.194.95 k8s-worker1 <none> <none>
elasticsearch-master-1 1/1 Running 0 10h 172.16.126.59 k8s-worker2 <none> <none>
fluent-bit-58sl8 1/1 Running 0 75m 172.16.126.60 k8s-worker2 <none> <none>
fluent-bit-wnpqk 1/1 Running 0 75m 172.16.194.70 k8s-worker1 <none> <none>
4、安装kibana
1. 查看kibana配置
$ helm inspect values elastic/kibana | less
...输出省略...
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
...输出省略...
service:
type: `ClusterIP` #要改成nodepode,因为需要物理机浏览器测试,cluster只能集群内部访问
...输出省略...
image: "docker.elastic.co/kibana/kibana" #网址也需要修改
2. 创建kibana
'查询集群的CPU和内存资源的申明占用情况'
$ kubectl describe node |grep -E '((Name|Roles):\s{6,})|(\s+(memory|cpu)\s+[0-9]+\w{0,2}.+%\))'
'其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]' 'NoSchedule:' 一定不能被调度 'PreferNoSchedule:' 尽量不要调度,实在没有地方调度的情况下,才考虑可以调度过来 'NoExecute:' 不仅不会调度, 还会立即驱逐Node上已有的Po
$ helm install kibana elastic/kibana \
--set service.type=NodePort,image="registry.cn-hangzhou.aliyuncs.com/k-cka/kibana"
$ kubectl describe pods kibana-kibana-7d58c45945-ncf9d #查看pod详细信息
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 116s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 2 Insufficient memory, 3 Insufficient cpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
'失败调度,master配置够但是有污点;3个节点cpu不足;另外2个cpu和内存资源不够,无法部署'
'master 节点参与 POD 负载,默认不参与'
$ kubectl taint nodes k8s-master node-role.kubernetes.io/control-plane- #删除污点
node/k8s-master untainted
'物理机对master增加cpu核数'
'若反复拉取不下来镜像,可以docker pull把镜像拉到本地使用'
$ kubectl get services -o wide -l app=kibana #查看服务,确定端口号
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kibana-kibana NodePort 10.98.144.79 <none> 5601:31615/TCP 20h app=kibana,release=kibana
$ kubectl get pods -o wide -l app=kibana #查看设备运行在哪个node
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kibana-kibana-7d58c45945-pfjmb 1/1 Running 1 (105m ago) 20h 172.16.235.193 k8s-master <none> <none>
3. 到如下界面代表安装成功
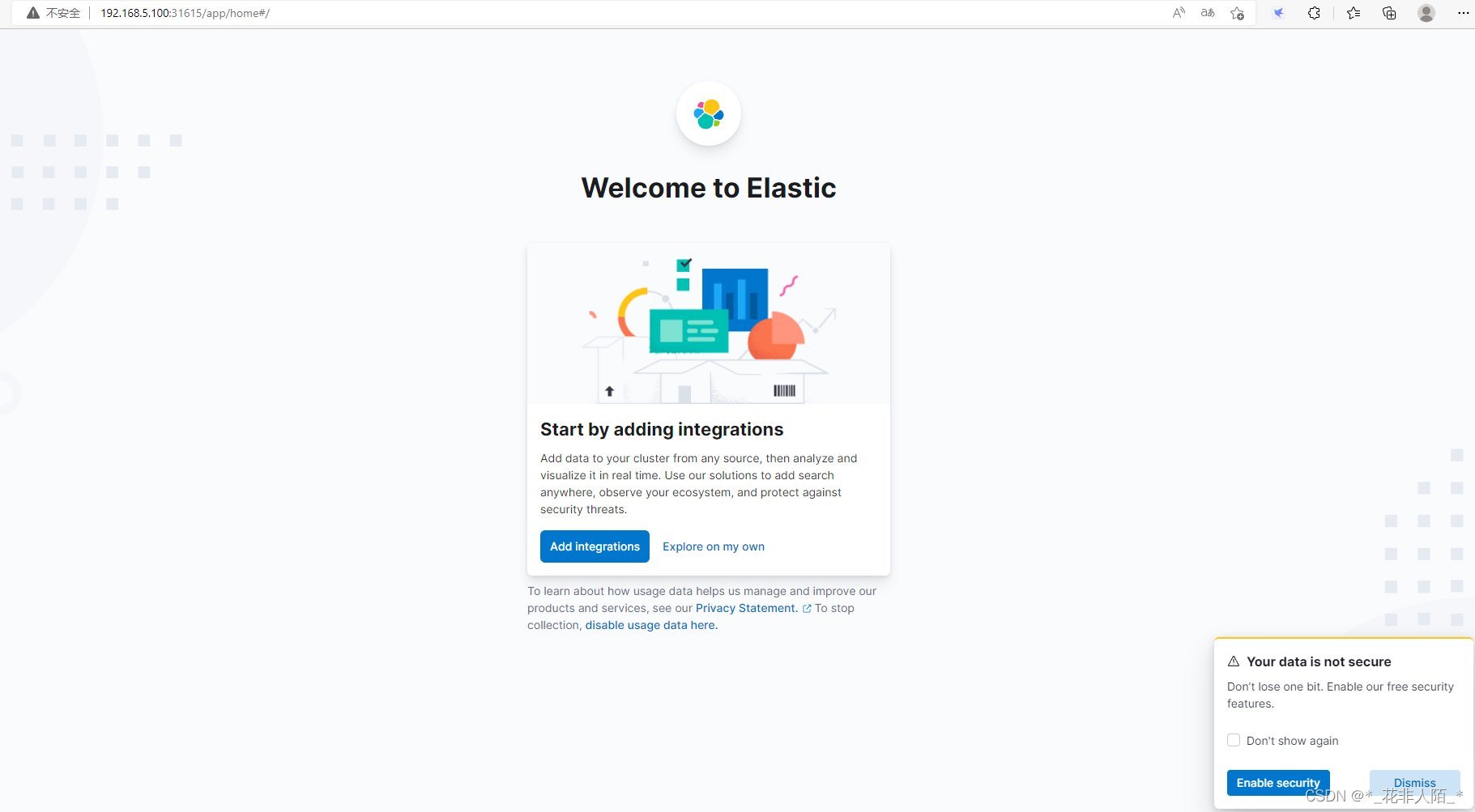
参考资料: 污点和容忍度 | Kubernetes
源代码官网:elastic · GitHub
5、使用elastic
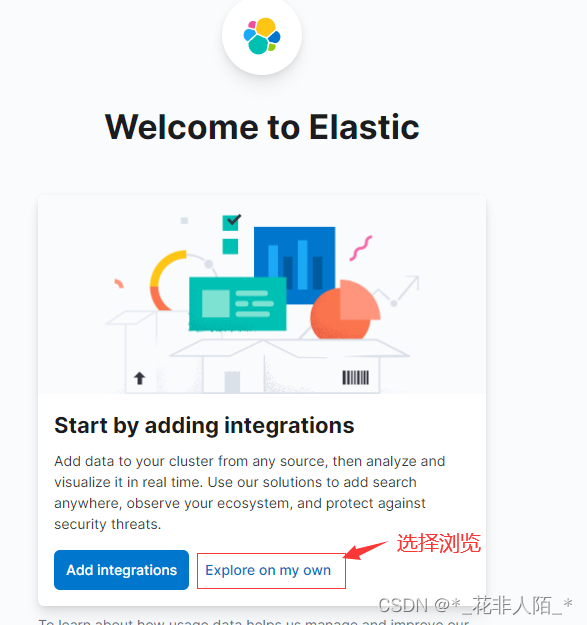
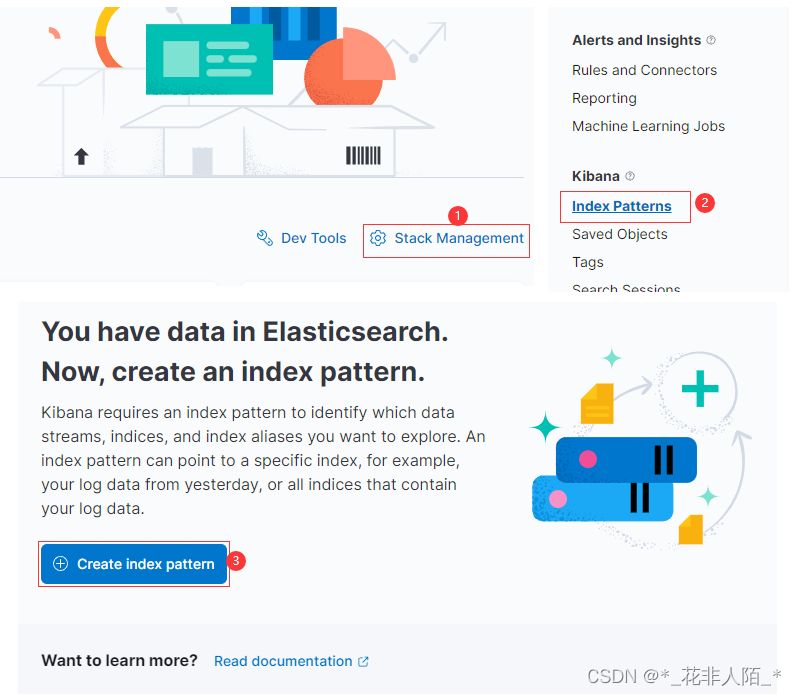
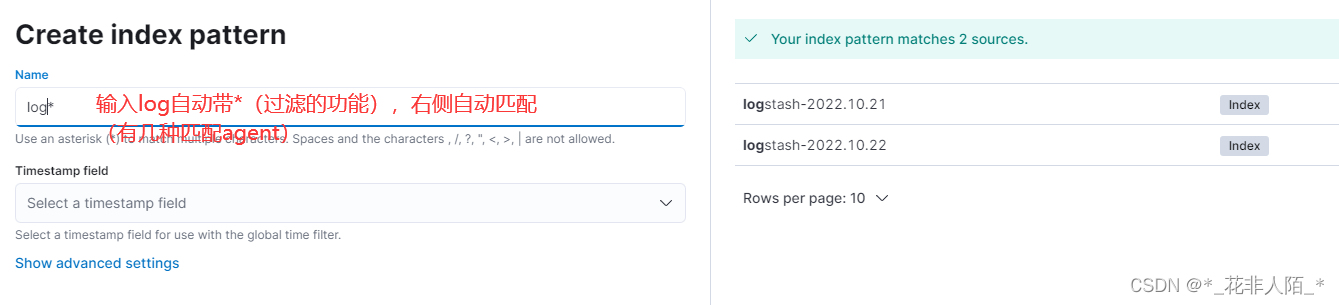
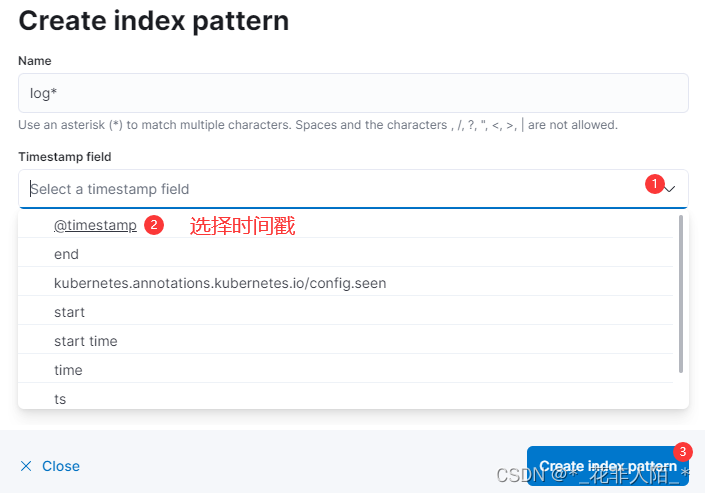
1. 配置
因为当前环境只安装了fluentd
可以通过不同的agent创建不同的索引


2. 运行一个pod
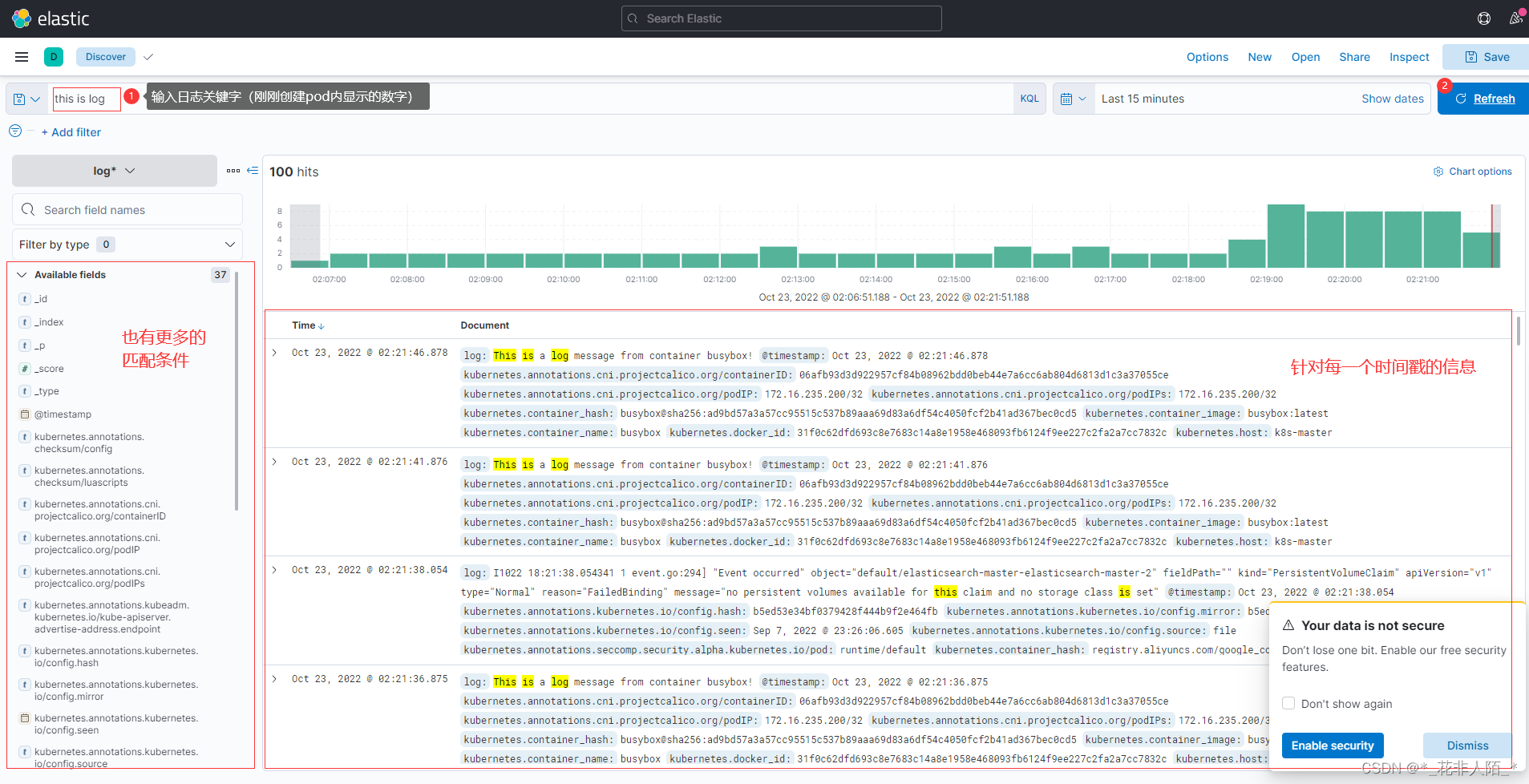
$ kubectl run busybox \ --image=busybox \ --image-pull-policy=IfNotPresent \ #镜像如果存在就使用本地(不在服务器拉取) -- sh -c 'while true; do echo "This is a log message from container busybox!"; sleep 5; done;' $ kubectl get pods busybox #确认pod已经运行 NAME READY STATUS RESTARTS AGE busybox 1/1 Running 0 21s

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)