
eLife:一个开源、高性能的自动睡眠分期工具
摘要近年来,对于人类睡眠的临床和社会学测量需求越来越多,但与其它已经实现高自动化分析的医学领域不同的是,基础和临床的睡眠研究仍然依赖人眼目测打分。基于人工的评估体系耗时、单调,且已被证实可能出现主观偏倚。作者开发出了一种已经过30000+小时源于世界不同人种的多导睡眠图记录数据验证的新型算法,可以提供精确匹配人工赋分准确度的睡眠分期功能。此工具简洁易用开源免费,对计算机运行要求低,希望以此实现自动
摘要
近年来,对于人类睡眠的临床和社会学测量需求越来越多,但与其它已经实现高自动化分析的医学领域不同的是,基础和临床的睡眠研究仍然依赖人眼目测打分。基于人工的评估体系耗时、单调,且已被证实可能出现主观偏倚。作者开发出了一种已经过30000+小时源于世界不同人种的多导睡眠图记录数据验证的新型算法,可以提供精确匹配人工赋分准确度的睡眠分期功能。此工具简洁易用开源免费,对计算机运行要求低,希望以此实现自动化睡眠分期。
介绍
睡眠对人体健康至关重要。充足的睡眠支持一整套生理身体功能,包括免疫、代谢和心血管系统。在大脑内部,充足的睡眠有助于最佳的学习、记忆、注意力、情绪和决策过程。因此,在研究、临床和基于消费者的层面上量化人类睡眠的需求在过去十年中迅速增长。
多导睡眠描记术(PSG是对人类睡眠进行客观生理量化的金标准。对夜间睡眠阶段的分类提供了关于夜间睡眠的总体结构的信息,以及睡眠阶段的持续时间和比例,所有这些都为睡眠障碍和特定疾病状态的诊断提供了信息。
目前,这种睡眠评分通常由人类完成,但不同的人类睡眠评分专家看到相同的记录,最终可能会得出不同的睡眠阶段评价,甚至同一个专家看到在两个不同时间点评估的相同记录,也会得出不同的结果。
机器学习的进步促使人们尝试使用自动化系统对睡眠进行分类。尽管自动化工具的数量在不断增长,但准确的自动睡眠分期还没有成为该领域事实上的标准。这可能有几个原因。首先,有些算法不是免费的,或者无法公开使用。其次,其他算法需要付费软件来运行尽管是免费的算法,比如MATLAB。第三,有些算法训练的样本量太小,不具有稳健性,而且/或数据来自单一睡眠中心或人群。因此,他们是否有能力推广到其他记录系统和/或人群,包括睡眠障碍患者或跨大年龄段的患者,一直令人担忧。第四,设置和运行这些算法对于大多数典型的个人来说往往过于复杂,因为它们需要中等到高级的编程经验,这为采用和广泛使用创造了进入障碍。所有这些算法的最后一个共同限制是,它们在不同的测试数据集上进行评估,使用不同的指标,这阻止了对这些算法的性能进行直接比较,并导致了一些睡眠研究人员和临床医生可以理解的困惑。
为了解决所有这些问题,作者提供了一种免费、灵活、易于使用的自动睡眠分期软件,该软件已经对超过30000小时的PSG睡眠分期进行了训练和评估,这些睡眠分期来自大量的独立和异构数据集,涵盖了广泛的年龄、种族和健康状况水平。并用两种最近的睡眠分期算法对健康成年人和阻塞性睡眠呼吸暂停(OSA)患者的一致评分睡眠数据集进行了研究。
结果
描述性统计
训练集包括超过31,000小时的PSG数据,包括来自7个不同数据集的3163个独特的整晚PSG记录(克利夫兰儿童睡眠与健康研究[CCSHS], n = 414;克利夫兰家庭研究[CFS], n = 586;儿童腺扁桃体切除术试验[CHAT], n = 351;家庭气道正压[HomePAP], n = 82;动脉粥样硬化多民族研究[MESA], n = 575;男性骨质疏松性骨折研究[mro], n = 565;睡眠心脏健康研究[SHHS], n = 590)。表1列出了培训集的人口统计和健康数据。平均呼吸暂停-低通气指数(AHI)为12.9±16.35(中位数为6.95,范围为0 ~ 125)。29%的夜间AHI≥15(=中度睡眠呼吸暂停)。MESA数据集的平均AHI最高(19.2±18.1),CCSHS数据集的平均AHI最低(1.5±5.2)。
表1。训练集和测试集的人口统计数据年龄、体重指数(BMI)、呼吸暂停-低通气指数(AHI)以均数±标准差表示。这三个变量的p值使用Welch’s双面t检验计算,效应大小参考Hedges g。所有其他类别变量都用百分比表示。采用独立性卡方检验评估显著性,效应量参考Cramer 's v。呼吸暂停严重程度分级如下:无= AHI <5次/小时,轻度= AHI≥5但<15、中度= AHI≥15但<30, severe = AHI≥30。p值未进行多次比较调整。
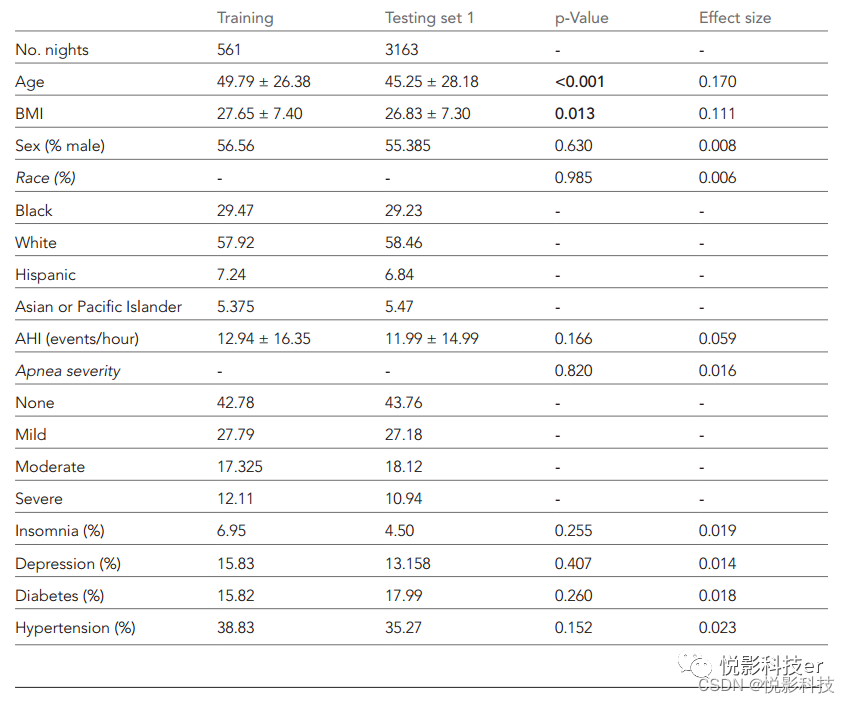
测试集1由来自6个不同数据集的585个独特的整晚PSG记录组成(CCSHS, n = 100;CFS, n = 99;CHAT, n = 100;MESA, n = 97;mro, n = 90;SHHS, n = 99)。总的来说,这585个测试夜晚代表了716,367个独特的30秒周期,或大约6000小时的PSG数据。试验集1的人口统计和健康数据见表1。重要的是,在性别比例、种族分布、失眠、抑郁或糖尿病患者的比例上没有显著差异。此外,AHI和轻度、轻度、中度或重度睡眠呼吸暂停患者的比例没有差异。虽然参与者被随机分配到训练/测试集中,但这两个集之间有一些显著的差异。具体而言,与原始训练集相比,测试组的年龄和体重指数(BMI)较低(p <0.05),尽管这些差异的效应量均低于0.17(被认为是小或可忽略)。
测试集2由来自公开的Dreem开放数据集(Dreem Open Dataset, DOD)的80个通宵PSG记录组成(Guillot等人,2020年)。DOD包括25个晚上的健康成人(DOD-健康:年龄= 35.3±7.51岁,76%男性,BMI = 23.8±3.4)和55个晚上的阻塞性睡眠呼吸暂停障碍(OSA)患者(DOD-Obstructive: 年龄= 45.6±16.5岁,64%男性,BMI = 29.6±6.4,AHI = 18.5±16.2)。DOD数据集没有提供个人层面的人口统计数据和病史; Guillot等人于2020年报告了年龄、BMI和AHI的组平均值。排除了5个晚上,因为PSG数据的持续时间和催眠图的持续时间相差超过1分钟,导致最终样本为75个晚上(约607小时的数据)。测试集2的每个晚上都由5名注册的睡眠技术人员评分,这样就可以根据人类评分者的共识来测试算法(见材料和方法)。与NSRR数据集不同,NSRR数据集被分为训练和测试子集,DOD的两个数据集(健康和患者)只用于性能评估。这为算法的性能提供了一个更可靠的评估,该评估基于来自一个新的睡眠诊所或实验室的真实数据。
验证结果
测试集1:NSRR
算法在测试集1上的总体性能如图1A所示。在全部585个测试夜计算的中位准确率为87.46%。Cohen 's kappa值的中位数为0.819,表明一致性极好;Matthews相关系数的中位数为0.821。CCSHS数据库测试集的总体准确率最高(中位数= 90.44%),MESA数据库的总体准确率最低(中位数= 83.99%)。除了传统的睡眠分期之外,该算法还能够量化每个30 s时期每个睡眠阶段的概率,然后可用于获得每个时期的置信度评分。在所有测试夜,该算法的中位置信度为85.79%。平均置信度较高的夜晚,其准确度显著较高(图1B, r = 0.76, p<0.001)。接下来,我们测试了各个睡眠阶段的分类性能(图1C)。N3睡眠的总体灵敏度(即正确分类的时间段百分比,见资料和方法)为83.2%,因此所有测试夜的中位f1评分为0.835。快速眼动(REM)睡眠、N2睡眠和觉醒期的灵敏度均高于85% (f1评分的中位数均≥0.86)。N1睡眠的一致性最低,总体灵敏度为45.4%,f1评分的中位数为0.432,这一发现与人类睡眠评分者的一致性通常非常低(<45%)。当分别对每个数据库进行检查时,这些算法性能结果是一致的(图1 -图补充1)。对混淆矩阵的进一步检查表明,该算法最常见的两个错误是(1)将N1睡眠错误标记为N2睡眠(占所有真实的N1睡眠时期的27.5%)和(2)将N3睡眠错误标记为N2睡眠(占所有真实的N3睡眠时期的16.1%)。重要的是,该算法很少出现明显的错误,例如将N3睡眠错误标记为快速眼动睡眠(0.2%)或将快速眼动睡眠错误标记为N3睡眠(0.03%)。此外,当该算法错误分类一个时期时,该算法预测的第二高概率阶段的正确率为76.3%±12.6%。
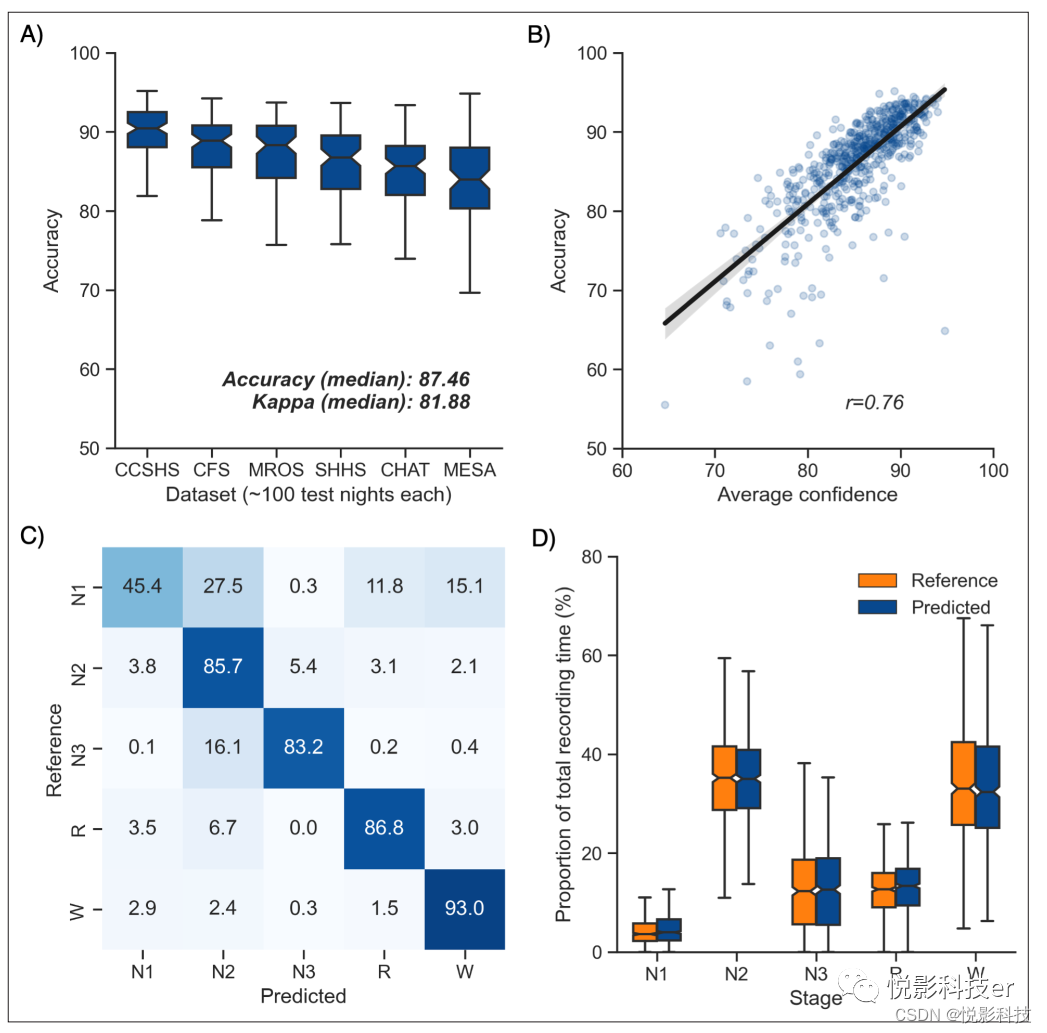
图1 算法在测试集1 (n = 585个夜晚)上的性能。(A)所有测试夜的准确性,按数据集分层。所有测试夜的中位准确率为87.5%。(B)算法的准确率和平均置信水平(%)的相关性。通过平均所有时期的置信度来计算每晚的总体置信度。©混淆矩阵。对角线元素表示被算法正确分类的年代的百分比(也称为灵敏度或召回),而非对角线元素显示被算法错误标记的年代的百分比。(D)人体每个阶段的持续时间(红色)和自动评分(绿色),计算每个测试夜,并表示为多导睡眠图(PSG)记录的总时间的比例。
图1补充。测试集1的混淆矩阵,按数据集分层
图2补充。测试集1中各睡眠阶段的置信度评分分布
图3补充。YASA, Stephansen等人,2018年和Perslev等人,2021年算法在DOD-Healthy测试集(n = 25名健康成人)上的性能
图4补充。DOD-Healthy测试集(n = 25名健康成人)上每个个体人类评分者的混淆矩阵
图5补充。stephenen等2018年和Perslev等2021年在DOD-Obstructive测试集(n = 50例阻塞性睡眠呼吸暂停患者)上的YASA算法性能
图6补充。DOD -阻塞性测试集(n = 50例睡眠呼吸暂停患者)上每个个体人类评分者的混淆矩阵
图7补充。分类器最重要的20个特征
测试集2:DOD -健康数据集和DOD -阻塞数据集的共识评分
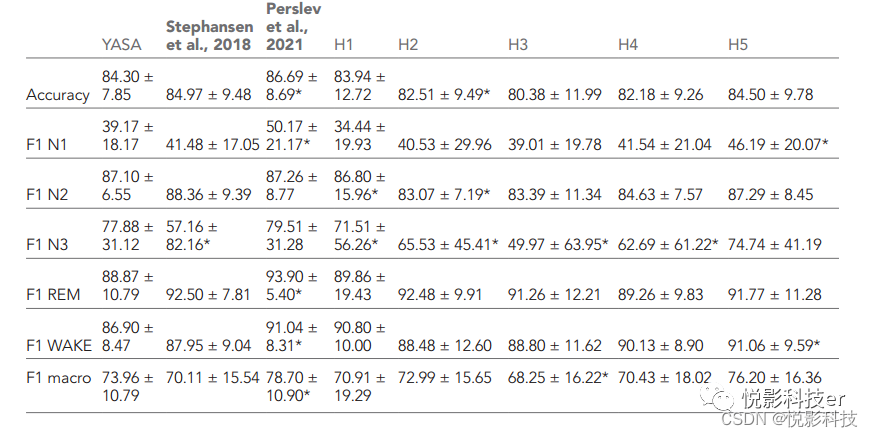
接下来,作者研究了YASA在测试集2上的表现,测试集2是一个之前未见过的健康和睡眠呼吸障碍患者数据集,由5名注册专家进行评分. 表2报告了健康成人(n = 25)的算法性能,表3报告了睡眠障碍患者的算法性能。在健康成人中,YASA与5位专家的一致评分的正确率中位数为86.6%。所有夜间的kappa值中位数为80.1%,一致性良好。所有夜间各睡眠阶段f1评分的中位数和四分位距见表2。然后将YASA的表现与5名单独的人类评分者中的每一位进行了比较,并与最近发表的两种睡眠分期算法进行了比较。使用Holm数值代表所有25个夜晚的中位数±四分位距对多重比较进行了配对t检验校正. YASA专栏显示了当前算法的性能相对于5个人类专家的共识评分(参见材料和方法)。
方法显示,YASA在这一健康验证数据集中的准确性与其他两种基于深度学习的睡眠分期算法或任何单个评分者(评分者4除外,见下文或表2)无显著差异。每个睡眠阶段的f1评分在YASA、Stephansen等人2018年的算法和人类评分者1、2、3和5之间无显著差异。评分者4对N1 (p=0.034)和N2 (p<0.001)的f1评分显著较低,导致整体准确性较低(p=0.001)。在N1期、快速眼动睡眠期和觉醒期,Perslev等2021算法的f1评分显著高于YASA(分别为p=0.006, p<0.001和p=0.042)。N2和N3的f1评分在YASA和Perslev等人2021算法之间无统计学差异。DOD-Healthy数据集的共识评分和3种自动算法的每晚睡眠图见补充文件1,其中YASA与共识评分的一致性由高到低排序。每个评分者(人和算法)的混淆矩阵可以在图1 -图补充3和4中找到。对55例OSA (DOD-Obstructive)患者进行了同样的分析。5位专家对YASA评分的一致性评分中位准确率为84.3%,kappa值为76.5%。所有夜间各睡眠阶段f1评分的中位数和四分位距见表3。对准确度进行的两两比较表明,YASA与Stephansen等2018算法或人工评分者1、3、4和5无显著差异。人类评分者2的准确率显著较低(p=0.004),而Perslev算法的准确率显著较高(p=0.009)。对f1评分的两两比较表明,YASA的表现优于Stephansen等人2018年的算法,以及N3睡眠评分的5名评分者中的4名(均p<0.01)。然而,在N1期、快速眼动期和觉醒期方面,Perslev等2021算法的评分显著高于YASA(均p<0.011)。共识评分和三种自动算法的一致性由高到低的催眠图见补充文件2。混淆矩阵见图1 -图补充部分5和6。
对合并数据集(n = 75个夜晚,健康和患者合并)的额外分析表明,第一,YASA相对于共识评分的准确性在稳定时期显著高于过渡时期(均值±标准差:91.2±7.8 vs. 68.95±7.7,p<0.001),或在被算法标记为高置信度时期(93.9±6.0 vs. 64.1±7.0,p<0.001)。其次,5位人类专家一致同意的时代发生在稳定时代的可能性是发生在过渡时代的4倍(46.2%±12.1%所有时间段vs. 11.5%±4.9%,p<0.001),而且在算法标记为高置信区间(≥80%)的时间段发生的可能性也高出4倍(所有时间段的46.4%±12.9% vs. 11.3%±5.7%,p<0.001)。第三,YASA标记为高可信度的时间点的百分比与具有一致性的时间点的百分比之间存在显著相关性(r = 0.561, p<0.001),这意味着YASA总体上对具有较高的评定者间一致性的记录更有信心。
表3。在DOD-Obstructive数据集(阻塞性睡眠呼吸暂停患者,n = 50)中,比较YASA与两种现有算法和个体人类评分者。
数值代表所有n = 50个夜晚的中位数±四分位距。YASA专栏显示了当前算法的性能相对于5个人类专家的共识评分(参见材料和方法)。H1-H5列显示了每个人的表现与一个无偏倚的共识(见材料和方法)。星号表示与YASA的显著差异。使用Holm方法对p值进行了逐行多重比较校正。准确性被定义为预测睡眠阶段和真实睡眠阶段之间的总体一致性。F1是F1评分,为每个睡眠阶段分别计算。F1-macro是所有睡眠阶段f1评分的平均值。
调节分析
对于不同调节因子对睡眠分期准确性的影响,随后的分析基于测试集1 (NSRR),与测试集2 (DOD)不同,该测试集可获得大量个人层面的人口和健康数据。与人类睡眠评分一样,专注于年龄这一第一个因素的分析显示,它与准确率存在微小但显著的负相关(r =−0.128,p=0.002,图2A),表明准确率随着年龄的增长存在适度的线性下降。其次,身体成分与准确性不显著相关(r =−0.001,p=0.97,图2B)。第三,性别也不是准确性的显著决定因素(Welch 's T =−1.635,p=0.103,图2C)。第四,睡眠呼吸暂停,特别是AHI,与准确率(r =−0.29,p<0.001,图2E)和算法的总体置信度(通过整晚逐时段置信度的平均值计算,r =−0.339,p<0.001)呈负相关。这表明,在一定程度上,算法的性能和可信度在睡眠呼吸暂停指数严重的患者中会下降,这可能是由睡眠呼吸暂停患者的阶段过渡数量增加所调节的(见上述阶段过渡发现)。与后者一致,(人为定义的)阶段过渡的百分比与AHI显著相关(r = 0.427, p<0.001)。最后,种族是准确性的一个显著预测因子(方差分析,F(3,581) = 3.281, p=0.021,图2D)。两两的事后测试调整了多次比较与Tukey的方法揭示西班牙裔白人的准确性低于非西班牙裔白人(p=0.032)。然而,这种效应可能是由这两个类别之间的样本量的不平衡所驱动的(n = 40 vs. n = 342)。没有其他种族类别之间的配对比较是显著的。为了更好地理解这些调节因子如何影响精度变异性,作者在模型中包括了所有上述的人口统计变量,以及抑郁症、糖尿病、高血压和失眠的医学诊断,以及从基本事实睡眠评分中提取的特征,如每个睡眠阶段的百分比、记录的持续时间和催眠图中阶段转换的百分比。模型的结果变量是YASA相对于地面真实睡眠分期的准确性得分,每晚分别计算。测试集1中的所有夜晚都被包括在内,导致样本量为585个独特的夜晚。结果见补充文件3b。N1睡眠的百分比和阶段转换的百分比——两者都是睡眠碎片化的标志——是准确性的两个最高预测指标,占总相对重要性的40%。相比之下,年龄、性别、种族和失眠、高血压、糖尿病和抑郁症的医疗诊断的综合贡献约占总重要性的10%。
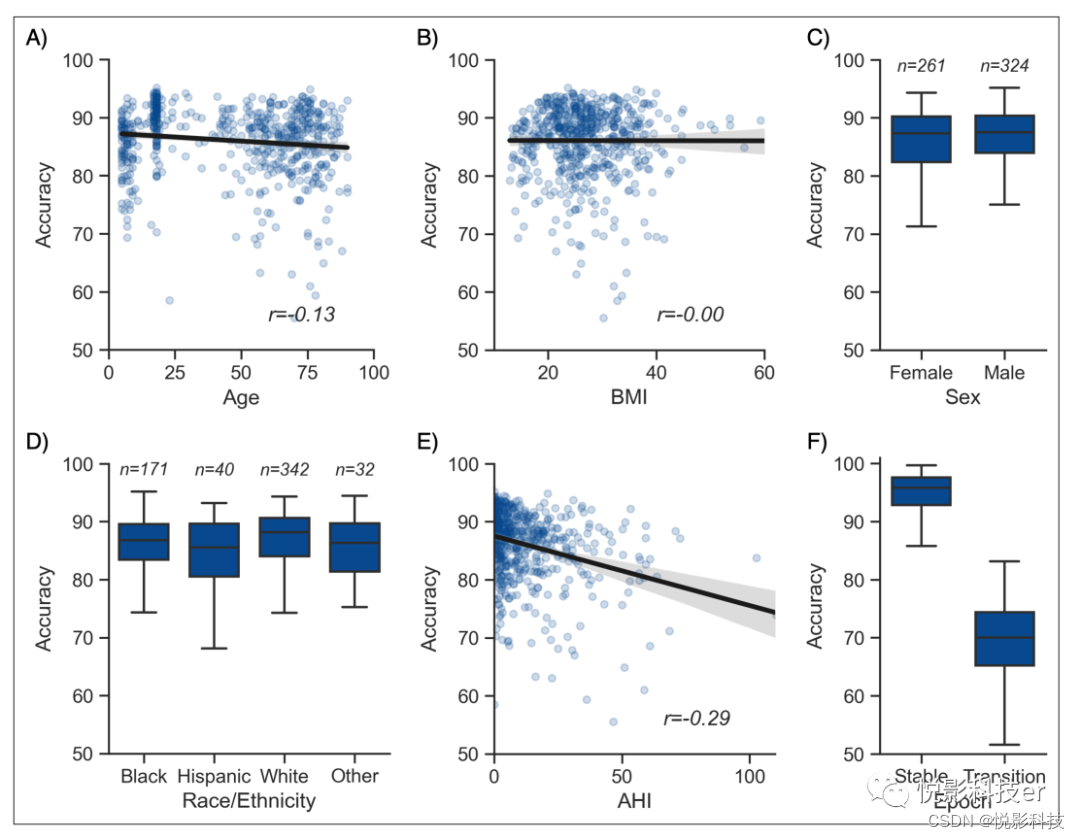
图2 调节分析 测试夜晚的准确性作为年龄(a)、体重指数(BMI) (B)、性别©、种族(D)、呼吸暂停-低通气指数(E)的函数,以及该时段是否在一个阶段过渡(F)附近。如果根据人类评分定义的阶段过渡出现在该时段前后的3分钟内(之前1.5分钟,之后1.5分钟),则认为该时段在一个过渡期附近
软件实现
该算法的实现是完全开源的,可以免费获得。此种睡眠算法,俗称YASA,是用Python编写的更广泛的睡眠分析包(或“库”)的一部分。除了自动睡眠分期模块之外,YASA还包括几个附加功能,如睡眠纺锤波和慢波的自动检测、自动伪影抑制、从催眠图计算睡眠统计数据、谱功率估计(例如,图3B)和相位幅值耦合。然而,使用基本的睡眠阶段模块完全不是基于想要量化这些指标。简单地说,如果用户希望的话,它们可以作为软件套件中的附加工具提供。YASA附带大量文档,并在BSD-3条款许可下发布,这是开源计划的一部分,可以通过Python包索引存储库中的一行简单代码直接安装(在终端:pip install YASA)。YASA的源代码在GitHub上是免费和公开的,用户可以选择忽略最新的版本,而保留代码和登台算法的特定版本,这对于例如,在纵向研究中,预处理和分析步骤应该随着时间保持一致。下面描述执行自动睡眠分期的一般工作流程。此外,作者提供了在单个欧洲数据格式(EDF)文件(图3 -图补充1)或在包含多个EDF文件的文件夹(图3 -图补充2)上展示算法最简单用法的代码片段。首先,用户将PSG数据加载到Python中。假设PSG数据存储在金标准EDF中,这可以使用MNE包在一行代码中完成,该包有一个专门的功能来加载EDF文件。第二,自动睡眠分期使用算法的睡眠分期模块执行。唯一的要求是用户指定他们想要应用检测的EEG通道的名称(优先是一个中心推导,如C4-M1)。该算法现在已经准备好对数据进行分级。如果用户愿意,可以选择命名EOG和EMG通道(首选下巴EMG)。如果需要的话,用户还可以包含辅助信息,例如年龄和性别,这有助于提高算法的准确性,尽管这对于高精确度完全不是必需的(如前所述)。对于算法的处理步骤,睡眠阶段是通过“预测”功能执行的。该函数自动识别并加载预先训练的分类器,对应于用户提供的传感器/元数据的组合。虽然预训练的分类器包含在算法中,但如果用户愿意,他们可以定义自定义预训练的分类器,这些分类器可以根据特定的用例进行定制。然而,再次强调,这只是为了使用的灵活性,并不是算法执行高精确度所必需的。顺便说一句,这种灵活性还可以用于各种用例,例如,评分啮齿类动物的睡眠数据,而不是人类的睡眠数据。除了阶段评分之外,’ predict_proba '函数的实现为用户提供了量化每个阶段在每个epoch的概率确定性的能力。如果需要的话,这种概率确定性可以用来获得一个置信度分数,尽管这对于用户的标准睡眠阶段来说也是不必要的(图3C)。最后,如果用户愿意,可以使用标准Python函数轻松地将预测的催眠图和阶段概率导出到文本或CSV文件中,但同样不需要这样做。自动化数据分析方法的一个局限性是,它们对计算量的要求很高,通常需要特定的昂贵的高端计算机系统。为了避免这种限制,当前算法通过利用Python中的高性能工具(例如Numpy的向量化和Numba编译)设计为快速和高内存效率。因此,在一个基本的、基本标配的笔记本电脑上,一个以100赫兹采样的一整晚PSG记录通常在不到5秒的时间内处理完毕。
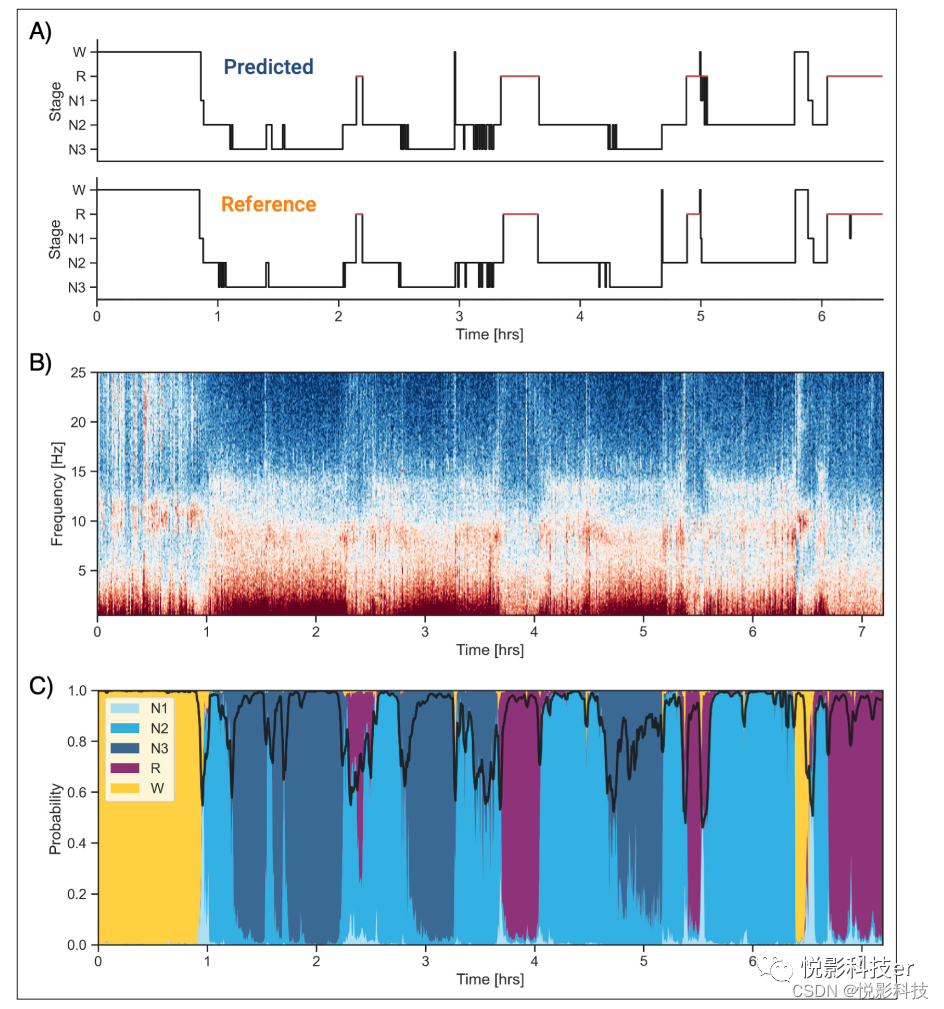
图3 一个主题的数据和睡眠阶段预测的例子。(A)健康年轻女性的预测和真实(=人类评分)催眠图(CFS数据集,24岁,黑人,呼吸暂停-低通气指数[AHI] <1).两者评分的一致性为94.3%。(B)中枢脑电图(EEG)通道对应的通宵频谱图。暖色表示这些频率的能量更高。这种类型的图可以用来很容易地识别整个睡眠结构。例如,频率低于5hz的高功率时期很可能表明深度非快速眼动(NREM)睡眠。©算法对每个睡眠阶段在每30秒的预测累积概率。黑线表示算法的置信度。请注意,在软件中可以很容易地绘制该图中的所有图形。本文的在线版本包括以下图3的图补充:图补充1。演示算法最简单用法的代码片段。图2的补充。说明在多个欧洲数据格式(EDF)文件上使用该算法的代码片段
讨论
作者试图开发一种睡眠分期算法(1)与人类评分者的准确性相匹配,(2)在大型异构数据集上进行了训练,(3)容易被大多数人实现,(4)计算需求低,因此可以在基本的笔记本电脑上运行,(5)完全免费,因此很容易被研究人员、临床医生和商业企业采用。
表现
该算法显示出高水平的准确性,与观察到的人类评分者之间的一致。对比两种最新的深度学习算法表明,在精确性上YASA与共识评分的对比与现有的两种健康成人算法相同(即,在统计上没有差异)。然而,YASA在OSA患者中的表现比Perslev等人的2021算法差2.4%(如“局限性和未来方向”部分所述)。
对于个体的睡眠阶段,该算法对N2睡眠、N3睡眠、REM睡眠和觉醒表现出良好的分类性能,对N1睡眠的一致性中等。这些结果与人类评估者间的一致性一致,即与其他睡眠阶段相比,N1睡眠阶段的评估者间一致性较低。此外,该算法成功地保留了整晚睡眠阶段的总体分布,从而既不会高估也不会低估特定的睡眠阶段。除了基本睡眠阶段分类之外,该算法的一个优势是能够为每个阶段的每个单独时期提供概率(即似然)值。这些概率告诉用户算法的置信度。因此,该算法为睡眠评分提供了一个独特的特征,它超越了睡眠分期的量化和睡眠分期的定性评估。证明了这一测量的有效性,该算法的准确性在标记为高可信的时期具有统计学上的优势,与人类评分达到了约95%的一致性。
普适性
算法的能力和效用不仅取决于其准确性,还取决于用于训练和验证的基础数据集的特征。作者在多个独立的异构数据集中,对近4000个夜晚超过30,000小时的PSG人类睡眠记录进行了训练和评估。这些数据集包括了来自广泛年龄范围、不同地理位置、种族、性别、身体成分、健康状况和睡眠障碍的参与者。重要的是,这些独立研究涉及不同的记录设备和设置(如蒙太奇、采样率)。这种高度的异质性对于保证算法的高可靠性和通用性至关重要。调节因子分析表明,该算法的性能不受性别和身体成分的影响。此外,算法的内置灵活性允许使用不同通道的组合,应该是用户希望的。该算法不仅具有广泛的实用性,而且有助于研究的工作的复制,并与现有和未来的工作进行比较。
易于使用,计算需求低
为了促进睡眠界的广泛采用,任何算法都能被相关各方(例如学生、研究人员、临床医师、技术人员)使用和理解,无论其专业技术水平如何,这一点至关重要。为了确保这一点,软件的构建特别注重易用性、文档化和透明度。首先,端到端睡眠-分期管道可以用不到10行Python代码编写,软件自带预训练的分类器,根据所使用的通道组合自动选择,从而限制任何错误的风险。其次,该软件有广泛的文档,包括大量的示例数据集,允许任何用户在将其应用到自己的数据集之前熟悉算法,如果他们希望(尽管这不是必要的)。第三,该算法使用传统的基于特征的方法来分类睡眠阶段,而不是黑箱算法。这些特征在算法的文档和源代码中详细描述,并可以解释给任何研究人员或临床医生在lay术语。最后,睡眠分期是在用户的计算机上本地完成的,数据从未上传到云或任何外部服务器,从而限制了安全和隐私风险,以及使用软件时对任何连接的需求。
局限性和未来方向
尽管该算法有许多优点,但也有必须考虑的局限性。下面将讨论这些问题,以及未来改进算法的思路。首先,虽然在健康成人中,YASA相对于共识评分的准确性与Stephansen等人,2018和Perslev等人,2021算法无显著差异,但在OSA患者中,YASA算法显著低于后者。Perslev等人2021年的算法使用了所有可用的EEG和两个(双侧)EOG,而YASA的评分是基于一个中央EEG、一个EOG和一个EMG。这表明,提高这一人群表现的一种方法可能是纳入更多的脑电通道和/或双侧eog。例如,使用双侧eog的负积可能会增加对REM睡眠期快速眼球运动或N1睡眠期缓慢眼球运动的敏感性。其次,目前算法广泛采用的一个障碍是缺乏图形用户界面(GUI)。设计和维护开源跨平台GUI本身就是一项艰巨的任务,需要专门的资金和软件工程师。相反,为了促进将YASA的输出集成到现有的睡眠gui,已经做出了大量的努力。具体来说,该算法的文档包括如何在EDFBrowser、Visbrain和SleepTrip等几个免费gui中加载和编辑睡眠评分的示例。第三,在整晚PSG记录中对该算法进行测试和评估。因此,它在短时间录音(如白天小睡)中的表现尚不清楚。因此,需要对该算法进行进一步的测试,以验证该算法在小睡中的有效性。虽然YASA可以处理任意长度的输入数据,但如果数据小于该算法使用的最长平滑窗口(即小于7.5分钟),则性能可能会降低。
第四,不同于其他基于深度学习的算法,该算法目前不具备在较短分辨率下评分的能力。第五,该算法目前无法识别常见睡眠障碍的标志物(如睡眠呼吸暂停、腿部运动),因此可能不适合用于临床目的。但需要注意的是,我们的软件确实包括了量化睡眠期间的阶段性事件(慢波、纺锤波、快速眼动、伪影)以及睡眠图的片段化功能。因此,YASA可能为加速PSG记录的临床评分提供一个有帮助的起点,而不是取代临床医生的关键专业知识。此外,该软件的未来发展应该优先考虑临床疾病的自动评分,特别是呼吸暂停低通气事件。
最后一个局限性是该算法是针对人类数据定制的。因此,那些想要使用YASA对人类颅内数据、动物数据,甚至来自特定人群的人类数据进行评分的人将需要根据自己的需求调整算法。算法可以在两个级别上进行修改。首先,个体可能希望在不改变潜在特征的情况下,对特定人群重新训练分类器。这种灵活性是由算法本身支持的,不需要修改YASA的原始源代码。然而,在某些情况下,可能还需要修改特征,以捕获输入数据的不同方面和动态(例如,啮齿动物或人类颅内数据)。
与现有工具相比,YASA的优势
尽管人工智能的最新进展已经使许多医学领域的繁琐工作自动化成为可能,但睡眠研究领域仍然依赖于人类的视觉评分,这一过程耗时且容易产生主观偏见。作者认为,阻碍自动睡眠分期广泛应用的一个障碍是每年发布的算法的数量,其中大多数算法实际上是无法与其他算法相比的,因为它们使用不同的测试数据集和/或不同的评估策略。除了高准确性之外,YASA还有一些值得潜在用户考虑的独特优势。
首先,与绝大多数现有算法不同,YASA的设计目的并不是将睡眠进行分期,而是作为一个广泛的工具箱,涵盖了睡眠研究人员和临床医师使用的绝大多数分析。这包括:(1)从睡眠图中计算睡眠统计数据,(2)自动检测睡眠期间的相位事件(如纺锤波、慢波、快速眼动和身体运动),(3)光谱分析,以及(4)更复杂和新颖的分析方法,包括事件锁定交叉频率耦合以及将睡眠功率谱分解为非周期性和振荡成分。与现有算法相比,YASA的第二个优势是处理速度。事实上,YASA比Stephansen等人2018年的算法快了几个数量级(约10-20 s vs. 10-20分钟,包括数据加载)。值得注意的是,虽然Perslev等人2021算法的计算速度较快,但将EDF文件上传到web服务器可能很慢,而且对于敏感的临床数据来说也不够。虽然在处理时间上的这些差异对于小型研究可能不是问题,但当处理数百个记录时,它们可以显著扩大。第三,只有少数人拥有修改和再训练复杂的深度学习神经网络架构所需的技术技能和/或硬件,具有Python基本知识的人可以很容易地修改核心YASA算法,并且在不超过几个小时的时间内,可以在任何基本的笔记本电脑上训练完整的模型。
结论
在过去十年中,人们对量化和追踪人类睡眠的兴趣呈指数级增长,对高度自动化、准确、高速和易于实现的人类睡眠评分算法的需求也有类似的增长。在这里,作者提供了一种算法,旨在实现这一需求。希望它能成为一种可以通过跨协作的开源社区开发来建立、扩展和完善的行业标准方法。
材料和方法
数据集
该算法在来自NSRR的大规模独立数据集上训练(https://sleepdata. org/)。该数据库提供了在研究队列和临床试验中收集的大量去识别生理信号和临床数据。所有PSG记录由经过培训的技师根据标准AASM指南进行评分,有关数据集的完整描述可以在https://sleepdataorg/上找到。文中使用了以下数据集。
MESA
MESA是一项多中心纵向研究,在2000—2002年的6,814名黑种人、白种人、西班牙语裔和华裔美国男性和女性中,对与亚临床心血管疾病发生和亚临床向临床心血管疾病进展相关的因素进行了研究,基线时年龄为45 ~ 84岁。于末次随访时采集整晚PSG记录2010年至2012年,共纳入2,237名研究对象(年龄范围= 54 ~ 95岁)。家庭PSG使用Compumedics Somte系统(Compumedics Ltd, Abbotsford, Australia)进行。记录内容包括三个皮质EEG(中央C4-M1、枕部Oz-Cz和额部Fz-Cz导联)、双侧EOG、颏EMG以及用于测量心率、呼吸和腿部运动的其他几个传感器。PSG数据采集频率为256 Hz,记录时采用硬件低通滤波器,截止频率为100 Hz。
CFS
CFS是一项以家庭为基础的睡眠呼吸暂停研究,包括来自361个家庭的2284名个体(46%为非洲裔美国人),在16年期间进行了多达4次研究。采用前次检查(第5次访视,735例,年龄6 ~ 88岁)的整夜PSG记录。采用Compumedics E-Series系统进行室内多导睡眠监测。记录内容包括双侧皮质脑电图(C3-Fpz、C4-Fpz)、双侧眼电图(EOG)和颏肌电图(EMG)。EEG和EOG通道采样频率为128 Hz, EMG通道采样频率为256 Hz。记录时使用截止频率为0.016 Hz和105 Hz的硬件带通滤波器。
CCSHS
CCSHS是一项以人群为基础的、具有客观睡眠评估的儿科研究,具有较大的少数群体代表性。我们使用了最近一次访视(2006—2010年),包括实验室PSG (n = 517,年龄范围= 16 ~ 19岁)。PSG记录(Compumedics E-series, Compumedics)包括两个皮层EEG (C3-Fpz和C4-Fpz)、双侧EOG和颏肌电图。所有通道采样频率为128 Hz,记录时采用硬件高通滤波器,截止频率为0.15 Hz。
SHHS
SHHS是一项多中心队列研究,旨在确定睡眠呼吸障碍的心血管和其他后果。我们只纳入了1995 ~ 1998年的第一次访视,并纳入了5,804名参与者(年龄范围= 40 ~ 89岁)的完整实验室PSG。PSG记录(Compumedics P-Series, Compumedics)包括两个皮层EEG (C3-M2和C4-M1)、双侧EOG和颏肌电。所有通道采样频率为125 Hz,记录时采用硬件高通滤波器,截止频率为0.15 Hz。
MrOS
MrOS是一项纳入5,994名男性的多中心观察性研究,其中睡眠研究是一项随访辅助研究。我们收集了2907名参与者(年龄范围为65-89岁)的夜间PSG记录,约占家长研究参与者的一半。PSG记录(Compumedics P-Series, Compumedics)包括双侧皮质EEG (C3-Fpz和C4-Fpz)、双侧EOG和颏EMG。所有通道采样频率为256 Hz,记录时采用硬件高通滤波器,截止频率为0.15 Hz。
CHAT
CHAT是一项多中心、单盲、随机对照试验,旨在检验在7个月观察期后,随机接受早期腺样体扁桃体切除术的5 ~ 9.9岁轻度至中度OSA儿童是否会表现出更高水平的神经认知功能。本研究于2007年至2012年收集了1447例受试者(年龄5 ~ 9.9岁)的整夜PSG记录,其中464例随机接受治疗。PSG记录包括8个皮层脑电图(包括C3-Fpz和C4-Fpz)、双侧眼电图和颏肌电图。所有通道采样频率均为200 Hz。
HomePAP
HomePAP是一项多中心、随机对照试验,纳入了373例患者(年龄范围= 20 ~ 80岁),中重度OSA的验前概率高。采用室内多导睡眠图(PSG)记录,包括6个皮层脑电图(C3-Fpz和C4-Fpz)、双侧眼电图和颏肌电图。所有通道采样频率均为200 Hz。
每个数据集被随机分为训练集(最多600晚)和测试集(最多100晚)。纳入训练集的PSG夜用于建模和训练,纳入测试集的PSG夜用于性能评估。重要的是,训练集和测试集是完全独立的(即没有重叠)。用于生成训练集和测试集的代码可以在这里找到。我们还提供了每个数据集的人口统计学和健康数据,如年龄、性别、种族/民族、BMI、AHI(3%减饱和)以及失眠、抑郁、糖尿病和高血压的医学诊断。为了在全新的数据集上对模型进行无偏向评估,我们进一步在DOD (Guillot等人,2020年)上测试了该算法的性能。DOD是一个公开的数据集,包括健康个体(DOD- healthy)和OSA患者(DOD- obstructive)。
DOD-Healthy
DOD-Healthy由25名在法国武装部队生物医学研究所疲劳和警戒单位招募的健康志愿者组成。参与者无睡眠抱怨,年龄18 ~ 65岁,招募时不考虑性别或民族。采用美国Compumedics公司的午睡多导睡眠监测设备(Siesta PSG)进行PSG记录,包括12个导EEG (C3/M2、F4/ M1、F3/F4、F3/M2、F4/O2、F3/O1、FP1/F3、FP1/M2、FP1/O1、FP2/F4、FP2/M1、FP2/O2)、1个EMG和双侧eog,采样频率均为250 Hz。
DOD-Obstructive
DOD-Obstructive包括55例临床怀疑睡眠相关呼吸障碍的患者。PSG在美国斯坦福睡眠医学中心进行(临床试验NCT03657329)。临床诊断为OSA以外的睡眠障碍、患有病态肥胖、服用睡眠药物或有某些心肺或神经合并症的个体被排除在研究之外。采用美国Compumedics公司的午睡多导睡眠监测设备(Siesta PSG)进行PSG记录,包括8个脑电信号(C3/M2、C4/M1、F3/F4、F3/M2、F4/O2、F3/O1、O1/M2、O2/M1)、1个肌电图和双侧眼电图,采样频率均为250 Hz。国防部数据集未提供个体水平的人口统计学和病史;年龄、BMI和AHI的组平均值来自Guillot等人,2020年。重要的是,DOD没有夜晚用于模型训练。由5名临床专家对DOD的每晚进行评分,从而将算法的性能与人工评分者的共识进行比较(见“共识评分”部分)。
预处理和特征提取
对于每一晚的PSG提取了单次中枢EEG、左侧EOG和颏EMG。选择了中枢EEG(例如C4-M1或C4-Fpz,取决于数据集),因为美国睡眠医学学会(American Academy of Sleep Medicine, AASM)建议将中枢EEG纳入所有PSG记录,因此中枢EEG更有可能出现在各种PSG记录中。然后将这些信号降采样到100 Hz以加快计算时间,并在0.40 Hz和30 Hz之间进行带通滤波。在运行睡眠分期算法之前,未对PSG数据进行伪影去除。这种分类算法基于一种机器学习方法,从脑电图信号中提取一组“特征”,也可以从眼电图和肌电图信号中提取一组“特征”。与人类睡眠分期一致,原始数据的每30秒周期都计算特征。所有用于计算这些特性的代码都是开源的,并免费提供给所有人(参见“数据和代码可用性”部分)。最终模型中包含的功能的完整列表可以在补充文件4中找到。
时域特征
所实现的时域特征包括标准描述性统计量,即信号的标准差、四分位距、偏度和峰度。此外,还计算了一些非线性特征,包括过零次数、迁移和复杂性的Hjorth参数(Hjorth, 1970)、排列熵和分形维数。
频域特征
从信号的周期图中计算频域特征,使用Welch 's方法(Welch, 1967)计算每30秒的周期(5秒的汉明窗,50%重叠[= 0.20 Hz分辨率],中值平均,以限制伪影的影响)。特征包括特定波段的相对频谱功率(慢= 0.4-1 Hz, δ = 1-4 Hz, θ = 4-8 Hz, α = 8-12 Hz, σ = 12-16 Hz, β = 16-30 Hz),宽带信号的绝对功率,以及功率比(δ / θ, δ / σ, δ / β, α / θ)。
平滑与标准化
在给睡眠评分时,人类专家经常依赖于上下文信息,比如当前被评分时期的之前和未来(即,最后几分钟的主要睡眠阶段是什么,下一个阶段是什么)。相比之下,基于特征的算法通常一次处理一个时代,独立于过去和未来的时代,忽略了这种上下文时间信息。为了克服这一限制,当前算法实现了一种涵盖上述所有特征的平滑方法。特别地,首先对特征进行复制,然后使用两个不同的滚动窗口进行平滑:(1)以7.5分钟为中心的三角加权滚动平均(即以当前epoch为中心的15个epoch,其权重为:[0.125,0.25,0.375,0.5,0.625,0.75,0.875,1]。, 0.875, 0.75, 0.625, 0.5, 0.375, 0.25, 0.125]),以及(2)当前epoch之前最近2分钟的滚动平均值。通过交叉验证方法找到了这两个滚动窗口的最佳时间长度(补充文件3a)。重要的是,脑电图脑波活动存在显著的个体间自然变异(Buckelmüller等人,2006;De Gennaro et al., 2008),这意味着每个个体都有独特的脑电图指纹。为了考虑到这一点,所有经过平滑处理的特征在每晚都被进行z评分,也就是说,以偏离当晚平均值的方式表示。包含这些归一化特征有助于适应个体间可变性对算法的潜在错误影响,从而提高最终的精度。最终的模型包括原始单元中基于30的特性(没有平滑或缩放),以及这些原始特性的平滑和规范化版本。原始特征被包括进来,以增加时间特异性,并保持绝对值,可以在个体间进行比较,而不考虑个体间的变异。最后,特征集包括从夜晚开始的时间,标准化从0到1。这很重要地解释了整个晚上睡眠阶段的不对称性,也就是说,深度非快速眼动睡眠在前半夜占主导地位,相反,快速眼动睡眠和较浅的非快速眼动睡眠在后半夜占主导地位。如果需要,用户还可以添加有关参与者特征的信息,如已知会影响睡眠阶段的年龄和性别(见“结果”;Carrier et al., 2001;Ohayon et al., 2004),分类器随后在分期过程中将其考虑在内。
机器学习分类
然后,使用LightGBM分类器(Ke等人,2017)对完整的训练数据集进行拟合,这是一种基于树的梯度提升分类器,使用以下超参数:500个估计量,最大树深度为5,每树的最大叶片数为90,以及在构建每棵树时随机选择的所有特征的60%的一部分。这些参数的选择是为了防止分类器的过拟合,损失函数定义为
acctest和acctrain分别是交叉验证测试/训练的平均准确率。换句话说,最好的超参数集必须最大化交叉验证的准确性,同时也要最小化训练集和测试集之间的准确性差异。然而,为了保持最佳性能,后者的权重是前者的4倍。此外,我们将定制的睡眠阶段权重传递给分类器,以限制整个夜间睡眠阶段比例的不平衡。如果没有这样的权重,分类器将倾向于代表最多的睡眠阶段(N2,一个典型夜晚的~50%),相反,很少选择代表最少的睡眠阶段(N1, ~5%)。通过在全训练集上进行交叉验证的参数搜索,以准确率和f1评分的平均值作为优化指标,找到最佳权重。共检验了324种可能的类别权重组合。参数空间定义为N1: [1.6, 1.8, 2, 2.2], N2: [0.8, 0.9, 1], N3/REM/Wake:[1, 1.2, 1.4]的笛卡尔积。N1的最佳权重为2.2,N2和Wake的最佳权重为1,N3的最佳权重为1.2,REM的最佳权重为1.4。在这里可以找到用于网格搜索最佳类权重的Python代码。然后将预训练的分类器导出为压缩文件(约2 MB),用于预测(1)测试集每个晚上的完整睡眠图,以及(2)每个30 s时期每个睡眠阶段的相关概率。
表现评估
对于每个单独的测试夜,作者逐个评估了人类评分(被认为是地面真实值)和算法预测之间的一致性。评价指标包括准确性(即正确分类的时间的百分比)、Cohen 's kappa(考虑到偶然发生一致的可能性的更稳健的评分)和Matthews相关系数。后者被认为是最稳健和信息量最大的分类评分,因为它自然地考虑到了睡眠阶段之间的不平衡。对于上述指标,数值越高,准确度一致性越高。除非特别说明,否则我们将报告包括1次EEG、1次EOG、1次EMG的完整模型的性能,以及参与者的年龄和性别。此外,为了衡量各阶段的表现,我们分别报告了每个阶段的混淆矩阵和f1评分。f1评分定义为精确度和灵敏度的调和平均值。简而言之,精确度是对预测质量的衡量(例如,算法分类为REM睡眠的所有时期中,在人类评分中实际被标记为REM睡眠的比例),而敏感性是对预测数量的衡量(例如,在人类评分中被标记为REM睡眠的所有时期中,在算法被正确分类为REM睡眠的比例)。由于f1评分是精确度和灵敏度的平均值,因此它是算法性能的最佳度量,可以对每个睡眠阶段独立计算。较高的值表示较高的性能。此外,作者还进行了差异分析,以检验该算法是否存在高估或低估特定睡眠阶段的系统性偏倚。最后,我们进行了调节因子分析,以测试该算法是否在不同年龄、性别和健康状况的参与者中保持了高水平的性能。
一致性评分
DOD的每个夜晚都由五位独立的专家打分。通过对每个时期采取投票最多的阶段,因此有可能建立一个共识睡眠图,从而减少由评分者间的低一致性引起的偏倚。当在特定时期出现平局时,最可靠的评分者的睡眠评分被用作参考。对于给定的一夜,最可靠的得分者是与所有其他得分者平均一致率最高的得分者。作者还将每个人工评分者与基于N-1名剩余评分者(即排除当前评分者,Stephansen et al., 2018)的无偏倚共识进行了比较。在这里,N-1中最可靠的得分者被用于平局的情况下。
与现有算法对比
作者又进一步测试了当前算法(YASA)与最近开发的两种睡眠分期算法(Stephansen等人,2018和Perslev等人,2021算法)的性能。这两种算法都是基于深度学习方法,并在GitHub上公开。这两种算法被应用于DOD数据集的所有夜晚,使用相同的原始数据来测试当前的算法。与YASA类似,Stephansen等人(2018年)和Perslev等人(2021年)的算法在其训练集中未包括国防部的任何夜晚,因此确保了无偏倚比较。两种算法之间的唯一差异是算法用于预测睡眠阶段的通道的选择。虽然YASA只使用单个EEG(中央)、一个EOG和一个EMG,但Stephansen等人(2018年)和Perslev等人(2021年)的算法均使用两个EOG (LOC和ROC)以及几个EEG通道进行了测试。对于所有三种算法,基本事实是所有五名人类专家的一致评分。分别对健康个体(DOD-Healthy)和oOSA患者(DOD-Obstructive)的结果进行评估。统计学比较使用双侧配对t检验进行,使用Holm方法进行多重比较校正。
特征重要性
使用Shapley加性解释算法(Shapley Additive explain algorithm;Lundberg等人,2020)。起源于博弈论的Shapley值具有几个令人满意的特性,使其成为评估机器学习中特征贡献的最优方法。形式上,Shapley值是特征值在所有可能的特征组合中的平均边际贡献。作者首先计算所有时期的绝对Shapley值,然后计算所有睡眠阶段的平均Shapley值,从而得出每个特征的单一重要性评分。
补充文件
•补充文件1 DOD-Healthy验证数据集每晚的自动算法预测。准确率指的是算法与人类共识评分的一致性百分比。夜的排列顺序是由高到低的一致性的YASA和共识评分。
•补充文件2。DOD-Obstructive验证数据集每晚的自动化算法预测准确率指的是算法与人类共识评分的一致性百分比。夜的排列顺序是由高到低的一致性的YASA和共识评分。
•补充文件3 (A)特征时间平滑的最佳时间长度的交叉验证。共测试49种过去和中心滚动窗组合,定义为过去滚动平均时间长度[无,1 min, 2 min, 3 min, 5 min, 7 min, 9 min]和中心滚动加权平均时间长度[无,1.5 min, 2.5 min, 3.5 min, 5.5 min, 7.5 min, 9.5 min]的笛卡尔积,其中无表示未使用滚动窗。交叉验证在完整的训练集上进行,并按夜间分层,即训练集和验证集中都有多导睡眠图(PSG)监测,但不能同时出现在训练集和验证集中。在速度方面,分类算法只使用了50棵树。“平均数”列是准确度和五个f1分数的平均值。请注意,排名第二的组合(以9.5分钟为中心)的平均分数略高;然而,我们选择在最终模型中使用7.5分钟中心窗口(秩1),因为N2、N3和快速眼动(REM)睡眠的f1评分较高。(B)准确性变异性的贡献者。使用随机森林从测试集1中估计n = 585个夜晚的相对重要性(%)。模型的结局变量为每晚分别计算的YASA与地面真实睡眠分期的准确性评分。
•补充文件4从多导睡眠图记录的第一个样本开始,计算整个夜间连续30 s的所有特征。重要的是,该算法使用了所有时域和频域特征的三个不同版本:(1)原始特征,以原始数据单位表示(例如,标准差和四分位距的μV);(2)该特征的平滑和归一化版本,使用7.5分钟三角加权滚动平均;(3)该特征的平滑和归一化版本,使用过去2分钟滚动平均。使用基于5 ~ 95%百分位数的稳健方法在每晚平滑后进行归一化。频域特征是基于Welch的5 s窗口(= 0.2 Hz分辨率)的周期图。
数据可用性
所有的多导睡眠监测数据都可以从NSRR网站(http:// sleepdata. org)获得。DOD数据集可以在https:// github. com/ Dreem- Organization/ dreem- learning- open。算法的源代码和文档可在https:// github. com/ raphaelvallat/Yasa获取。重现本文所有结果和图形的Python代码可以在https://github. com/ raphaelvallat/ yasa_ classifier找到。所有分析均在Python 3.8中使用scikit-learn 0.24.2和lightgbm 3.2.1进行。
参考文献:An open-source, high-performance tool for automated sleep staging

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)