深度学习基础:矩阵求导+反向传播
重点:向量对向量求导a = , 向量a对向量W求导,导数为WT.当自变量和因变量均为向量时,求导结果为一个矩阵,我们称该矩阵为雅可比矩阵(Jacobian Matrix)。
·

求导过程
常用损失函数公式的求导: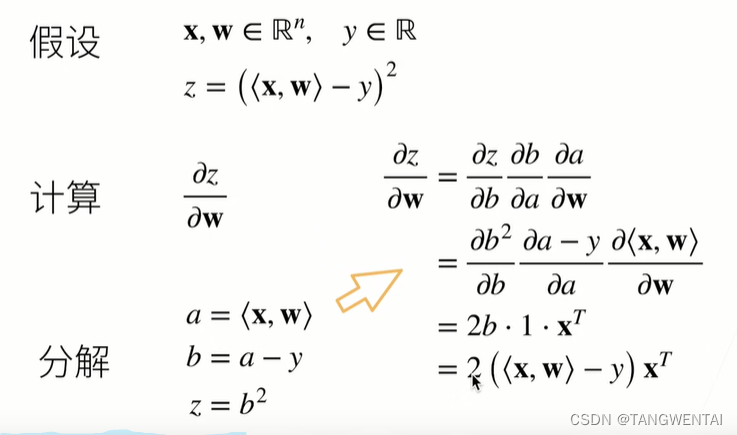
重点:向量对向量求导
a = <X,W>, 向量a对向量W求导,导数为 W T W^{T} WT.
推导过程:
当自变量和因变量均为向量时,求导结果为一个矩阵,我们称该矩阵为雅可比矩阵(Jacobian Matrix)。
反向传播:
整体过程: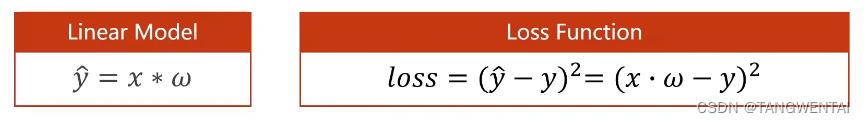
模型函数表达为y = x*w, 损失函数为loss
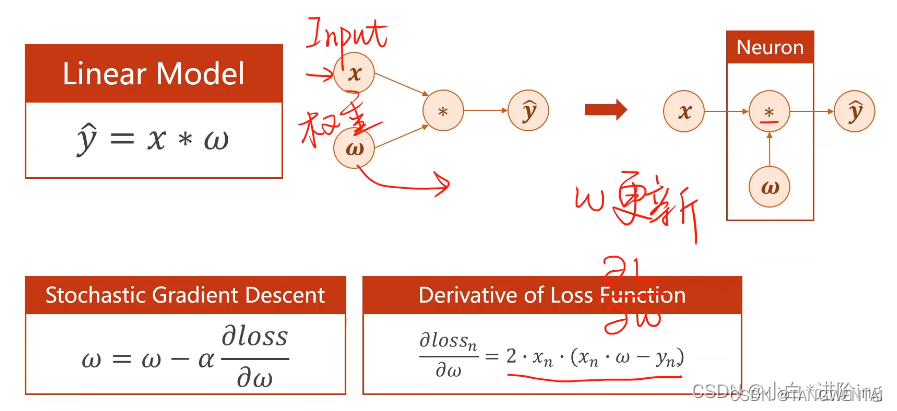
反向传播是通过损失loss对参数求偏导,对参数w进行随机梯度下降的更新。使损失函数达到局部最优解。
重点在于损失函数loss对参数w的偏导如何求:
案例如下:
1.利用前向传播由输入参数(浅灰)确定中间参数值(橙色)
2.反向传播:利用前向传播确定的中间参数值,反向求出损失函数loss对参数w(浅蓝)的偏导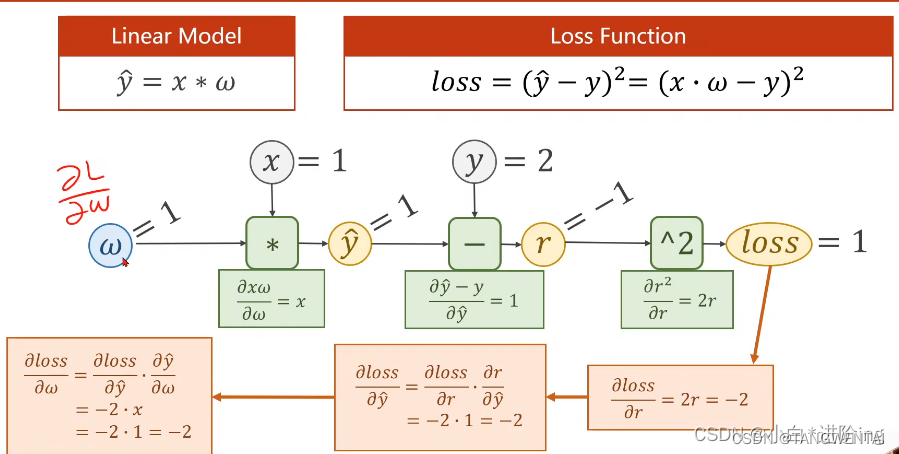
代码中反向传播的使用:
一个标量调用它的backward()方法后,会根据链式法则自动计算出源变量的梯度值。
import torch
x = torch.arange(4.0)
x.requires_grad_(True)
y = 2 * torch.dot(x, x)
y.backward()
x.grad
# 输出: tensor([ 0., 4., 8., 12.])
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
# 输出: tensor([1., 1., 1., 1.])
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
#输出: tensor([0., 2., 4., 6.])
第一段代码: y = 2 * torch.dot(x,x) 的结果为28为一个标量
第二段代码: y = x.sum 进行反向传播后所得的各方向梯度均为1,而结果为8一个标量
第三段代码: y = x * x 的结果为 [0 , 1, 4, 9] 为一个向量
那么,如何将一维张量y变成标量呢?
一般通过对一维张量y进行求和来实现,即y.sum()。
一个一维张量就是一个向量,对一维张量求和等同于这个向量点乘一个等维的单位向量,使用求和得到的标量y.sum()对源变量x求导与y的每个元素对x的每个元素求导结果是一样的,最终对源张量x的梯度求解没有影响。
点击阅读全文

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 4
4 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容









 服务器0元试用
服务器0元试用
所有评论(0)