深度学习吴恩达笔记
个人笔试,不全

1、深度学习基础知识
1、logical二分分类:下图将一个彩色图片用一个三个二维数组来表示RGB值,然后将RGB矩阵的值依次放入矩阵x中,于是第一个图片用x(1)来表示,依次类推,每一个x对应一个y,然后组合成的关系如下图X和Y所示,经常使用n来表示样本的数量
2、logistic回归:假如我们用y=wx+b来表示一个物体的概率,此时就需要弄一个概率值,也就是将wx+b进行一个函数变化,这个函数是下图所示,这样可以使得y永远在0-1之间,也就可以用来表示一个概率,此时的y就叫做y帽
3、如何训练wx+b中的w和b:
损失函数:用来衡量单个样本中输出值y hot和y的实际值有多接近。在下图中是L函数,当y=1时,需要我们的y hot越大越好,也就使得整个函数表达式为1,同理,当y=0时也是一样。
成本函数:用来衡量全体训练样本上的表现。在下图中是J。我们在logical中就是要找到一个w和b,使得成本函数最小。
这两个函数的定义一般是直接用论文里的,而不是自己定义的
4、梯度下降法训练参数w和b:对于logical来说,大部分的初始化w和b的方法都是可以的,通常使用0来进程初始化;
在下图中,J(w)是成本函数,横轴表示w,公式中埃尔夫表示学习率,表示w增长的快慢,当w初始值在左边时,w会增长到使得J(w)最小值,同理在右边也是的,w的变化是下图中的公式:
这里是单个样本的计算公式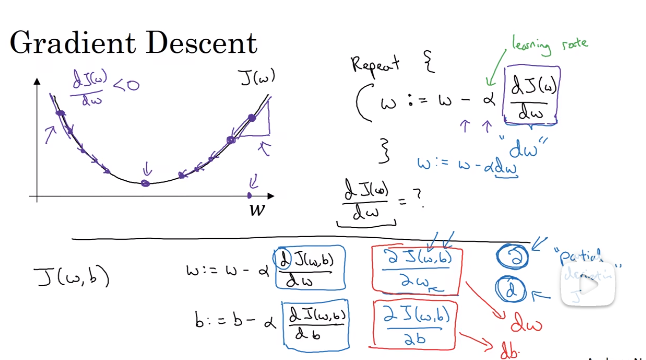
5、m个样本的梯度下降计算:没太看懂
6、向量化:用来消除代码中的for循环,可以减少计算时间,主要是用python的函数,存在于numpy当中,只要有机会就不要用for循环;
前向计算下图说明:单个z表示一个样本的logical函数,然后使用艾尔法函数将其归一化,X表示所有样本的集合,Z表示多个z的集合,a表示每个样本的预测值,A表示每个样本的预测值的集合;
7、python中的广播:可以让代码执行的更快,reshape函数,维数不同的矩阵进行运算,系统会自动将其进行对齐然后进行计算。
8、numpy向量的说明:
2、神经网络概述
1、()表示单个样本,[]表示神经网络的层数,每一次都需要计算这个艾尔法,艾尔法又叫做激活函数,激活函数后作为下一层的输入;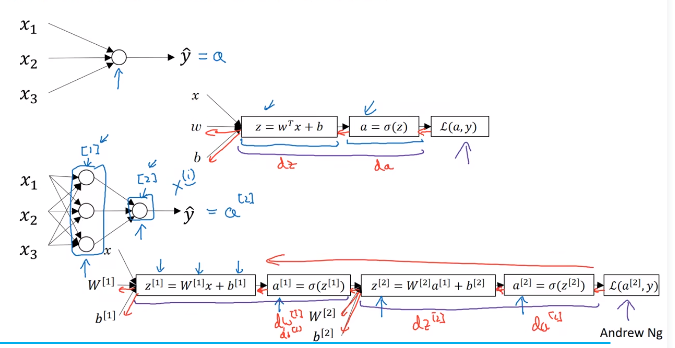
下图是一个神经网络的计算过程:每一层的每个节点都对应一个w和b,这里暂时不太懂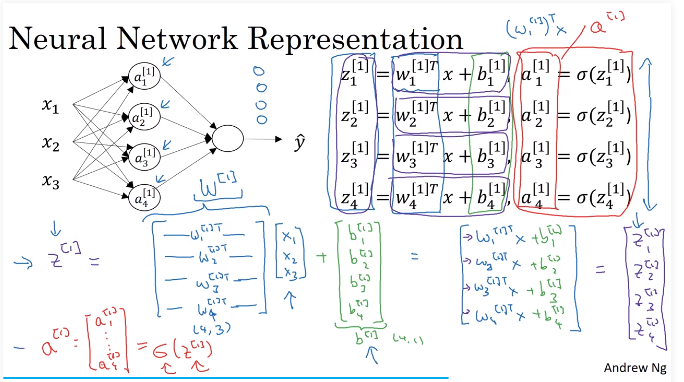
2、激活函数:如果做二元函数,使用艾尔法激活函数;其他基本上都使用Relu激活函数,Relu函数的缺点是小于0时斜率为0;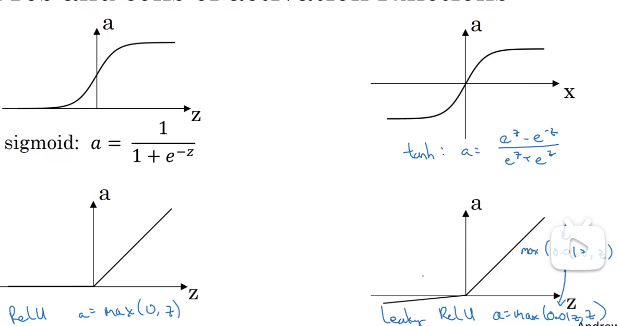
3、随机初始化权重w和b,使用randow函数,一般初始化参数都很小,最常用的就是0.01
3、计算机视觉知识
1、padding:在做卷积前,给原始数据四周填充元素的行数;不padding的卷积叫做valid
卷积,最后的输出图像的大小为n-f+1;padding的叫做same卷积
2、输入输出的维度计算:nn的图像,ff的过滤器,padding=p,步长s=2,那么输出就是(n+2p-f)/s +1 * (n+2p-f)/s +1;如果(n+2p-f)/s +1不是一个整数,那就向下取整,也就是只在输入图像内做卷积
3、三维图像的卷积:过滤器和输入图像的维数要相同;输入图像的维数和过滤器的个数相同
4、下图显示了一个前向传播的过程: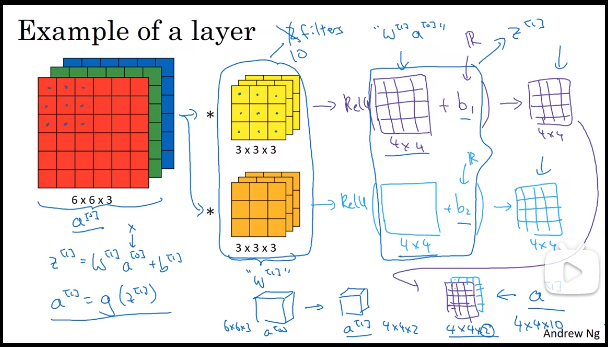
5、conv卷积层,pool池化层,fc全连接层
6、残差网络:
1 残差块:本来是l层输出到l+1层,但是我们直接将l层的输出放到l+2或者后面的其他层,和它的输出相加然后再使用激活函数,在一个网络当中多次这样操作就使得网络可以更深;有助于解决梯度下降和梯度爆炸的问题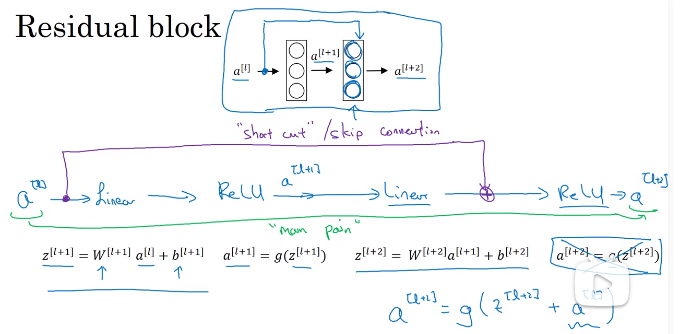
2 1*1的卷积是很有用的,可以压缩信道数量
7、谷歌inception网络:不需要认为决定使用哪个过滤器或是否需要池化,而是由网络自行确定这些参数,可以给网络添加这些参数的所有可能的值,让网络自己学习需要什么样的参数,但是会带来一个计算量很大的问题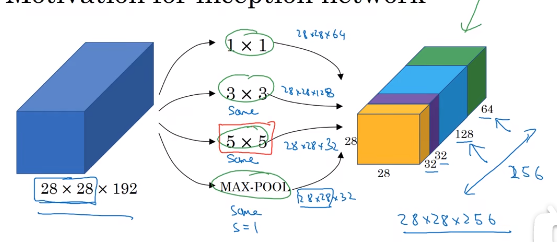
下面两图最后的输出是一样的,但是计算量减少为十分之一,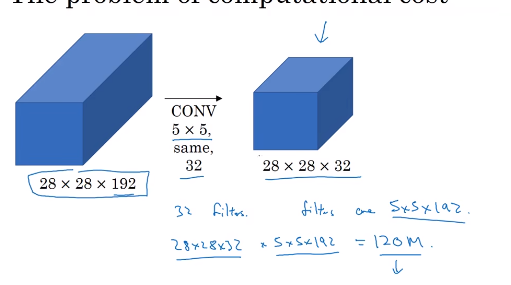
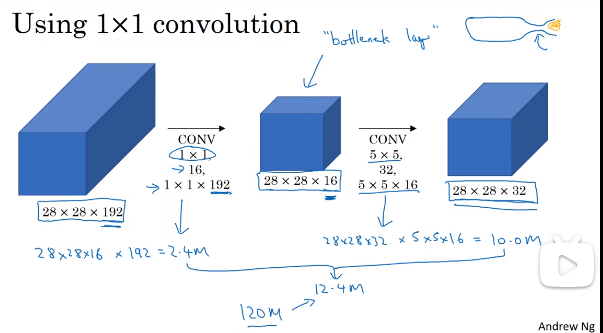
8、inception网络:和上面的第一个图是一样的,就是先分部卷积和池化,最后拼接在一起就行,只不过是由多个模块组成的
9、下载神经网络源码可以去开源网站进行下载
10、迁移学习:将别人的网络下载下来,改变其中的层或者softmax层,当自己的数据集很小时,就只需要改变softmax层就好了,当数据集大时,将所有层的参数当做初始化参数,然后进行训练即可;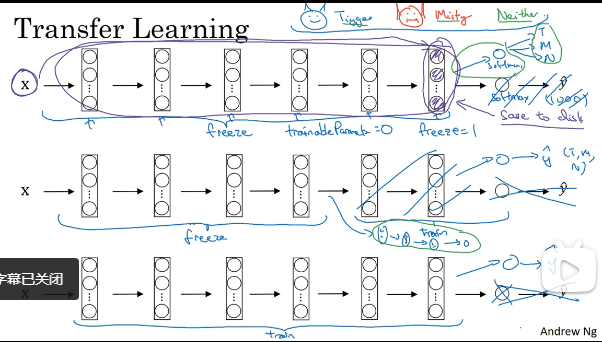
11、数据扩充:又叫数据增强,可以垂直翻转,,还有就是随机裁剪(不完美,可能会裁剪到其他区域),色彩转化(给rgb通道加上不同的失真值)
3、对象检测
1、bounding box预测,yolo算法:给输入图像放一个网格,假如要识别三类物体,那么就会在每个格子中输出8个参数,p,x1,x2,y1,y2,c1,c2,c3,c代表识别的类别,p代表有无物体;
假如我们划的格子是33,最后需要在每个格子当中输出8个参数,那么我们最后的输出就是应该33*8的大小
2、交并比IoU:计算两个边界框交集和并集之比,一般规定IoU>=0.5就说检测正确
3、非最大值抑制:可以确保每个对象只检测一次,一个物体可能会出现在多个网格,每个网格都说,我这里有车,非最大值抑制会计算每个网格中有车的iou,留下最大的那个iou值
4、anchor boxes
5、候选区域:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容









 服务器0元试用
服务器0元试用
所有评论(0)