支持向量机SVM的原理、算法、应用超详述
建立在统计学习理论VC维理论和结构风险最小化原理基础上的机器学习方法。用于解决数据挖掘或模式 识别领域中数据分类问题它在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题。此外,它具有坚实的理论基础,简单明了的数学模型,因此,在模式识别、回归分析、函数估计、时间序列预测等领域都得到了长足的发展,并被广泛应用于文本识别、手写字体识别、人脸图
1.引言
2.原理(线性可分、线性不可分、核函数)
一.引言
1.支持向量机[1-2](support vector machines,SVM)是建立在统计学习理论[3-4]VC维理论和结构风险最小化原理基础上的机器学习方法。用于解决数据挖掘或模式 识别领域中数据分类问题它在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题。此外,它具有坚实的理论基础,简单明了的数学模型,因此,在模式识别、回归分析、函数估计、时间序列预测等领域都得到了长足的发展,并被广泛应用于文本识别[5]、手写字体识别[6]、人脸图像识别[7]、基因分类[8]及时间序列预测[9]等。
二、基本原理
它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
1.线性可分
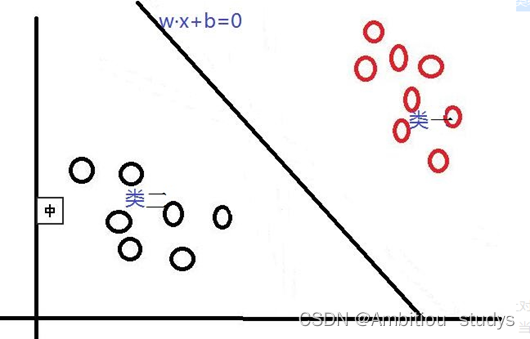
首先,对于SVM来说,它用于二分类问题,也就是通过寻找一个分类线(二维是直线,三维是平面,多维是超平面)可以将数据分为两类。 并用线性函数f(x)=w*x+b来构造这个分类器(如下图是一个二维分类线)
其中,w是权重向量,x为训练元组(X=(X1,X2…Xn),n为特征个数,Xi为每个X在属性i上对应的值),b为偏置,w•x是w和x的点积。当某数据被分类时,就会代入此函数,通过计算f(x)的值来确定所属的类别,当f(x)>0时,此数据被分为类一,当f(x)<0时,此数据被分为类二。通过观察,我们可以发现,如果我们平移或者旋转一下此分类线,同样可以完成数据的分类,那么,选择哪一个分类线才是最好的呢?
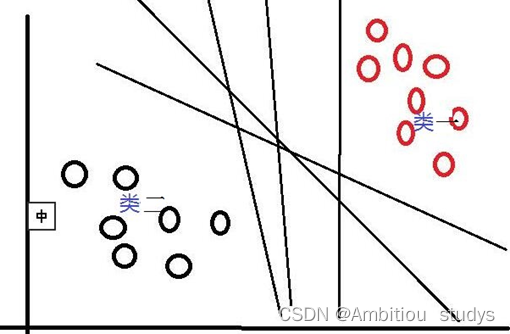
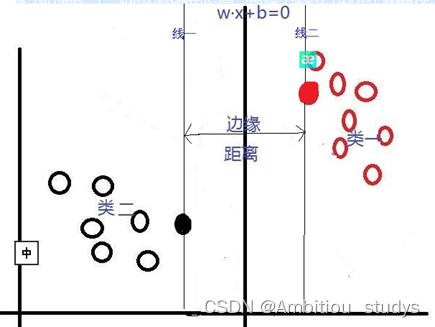
对于这个问题,SVM是通过搜索“最大边缘距离分类线”(面)来解决的。那么,什么是边缘距离,为什么要寻找最大的边缘距离呢?如下图所示,如果我们将某一分类线向右平移,在平移到右侧最大限度,又能确保此时的这个被平移的线仍然能将数据分为两类时,也就是如下图所示的:右侧与类一中某个或某些数据(实心点)相交的位置。此时正好,在线右侧和线上的数据是类一,在线左侧的数据是类二;同理,如果我们将这个分类线向左移动,也是移动到左侧最大限度(线二),此时这条线刚好也与类二中的某个或某些(实心点)数据相交,线上和线左侧的数据是类二,线右侧的数据是类一。对于这两条“极限边界线”,我们可以称之为支持线,或者对于面来说,就是支持面,而确定这些支持面或者支持线的那些数据点,我们称之为支持向量。两个支持线或支持面之间的这个距离,就是我们所说的边缘距离。
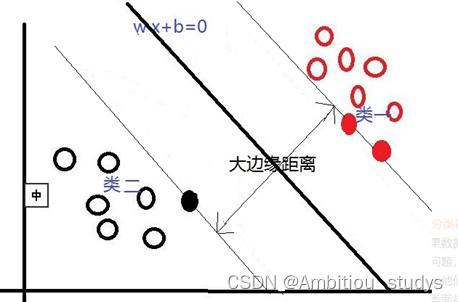
在这里我们可以发现,不同的分类线(面)会对应不同的支持线(面),支持线(面)之间的边缘距离也是不同的,并且,我们认为:边缘距离越大的分类线,对分类精度更有保证,所以,我们要找的”最好的“分类线(面),就是拥有最大边缘距离的那个分类线(面)。也就是说:对于线性可分的情况,SVM会选择最大化两类之间边缘距离的那个分类线(面)来完成二分类问题。并且此分类线(面)平行于两个支持线(面),平分边缘距离。下图是一个与上图相比,拥有更大边缘距离的分类线(面)。
2.线性不可分
对于线性可分的情况,我们上面说到,可以通过一个线性函数f(x)=w•x +b来构造一个分类器,寻找一个有着最大边缘距离的分类线(面)来完成对数据的分类。但是,我们还会遇到另一个问题,就是,如果数据是线性不可分的情况,用一个二维直线,三维平面或者多维超平面不能完成二分类,又该如何呢?对于线性不可分问题,SVM采取的方法是将这些线性不可分的原数据向高维空间转化,使其变得线性可分。就像下图所示,对于一些数据,他们是线性不可分的,那么,通过将他们向高维转化,也许就像图中所示,将二维数据转化到三维,就可以通过一个分类面将这些数据分为两类。所以说,SVM通过将线性不可分的数据映射到高维,使其能够线性可分,再应用线性可分情况的方法完成分类。而在这个高维转化过程中,SVM实际上并没有真正的进行高维映射,而是通过一种技巧来找出这个最大边缘分类面,即将一个叫做核函数的函数,应用于原输入数据上。
3.核函数
这个技巧首先允许我们不需要知道映射函数是什么,只将选定的核函数应用到原输入数据上就行;其次,所有的计算都在原来的低维输入数据空间进行,避免了高维运算。对于这个核函数,可选项有好几种,包括多项式核函数,高斯径向基函数核函数,S型核函数等
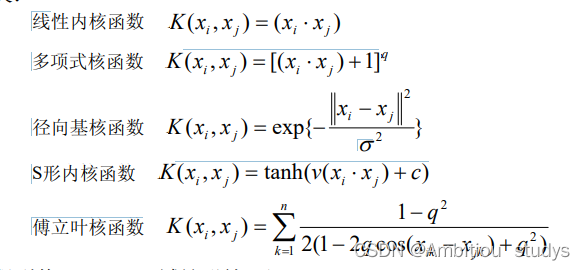
1.多项式核计算数据点之间的高维关系,并且在不添加任何特征的前提下将数据映射到更高的维度。这里的q是一个超参数,指的是函数应该使用的多项式的次数。
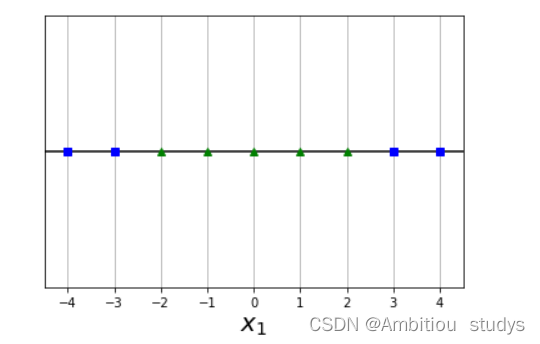
举个栗子,图一的数据是低维的线性不可分的,但是我们使用多项式核的SVM转化后,我们就得到了如图二所示的高维线性可分的映射。再说一遍,多项式内核只是把数据从低维映射到高维,并计算高维之间的关系,并不转化或者新增特征。另外,多项式次数越高,拟合能力越强,如果感觉模型过拟合了,可以适当减小多项式的次数。
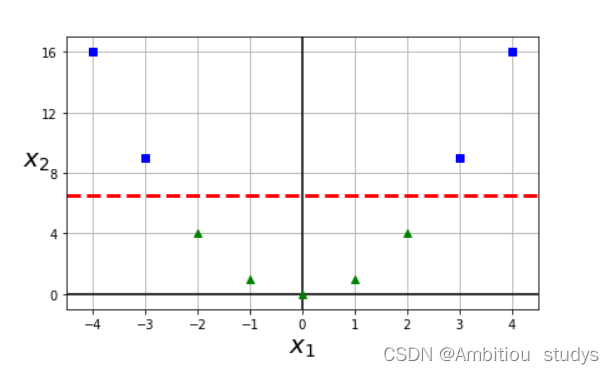
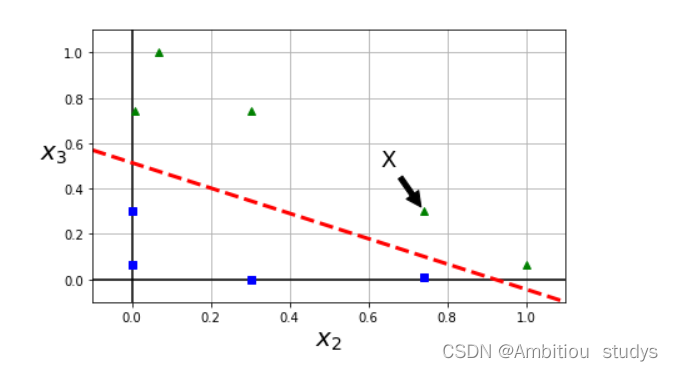
2.高斯核也是拔高特征的维度,将低纬度的特征映射到高纬度,只不过映射方式使用的是高斯函数。其中,x表示样本点,x’表示地标。地标本质上是也是样本中的点,我们用来计算和其他样本点之间的相似性。如图三所示,是一个1维的图,图中有两个地标(红色的点),对于样本x=-1,它距离第一个地标1个距离,距离第二个地标 2个距离。
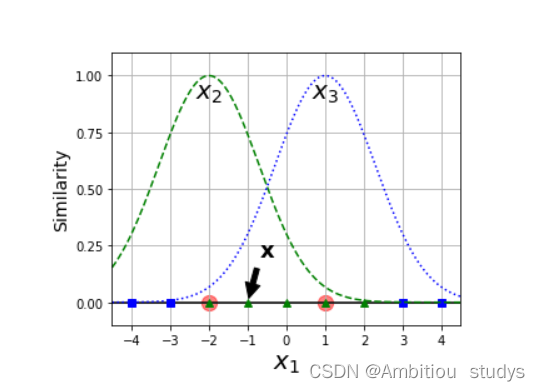
因此,将图三根据高斯公式被映射过后的特征如图四所示。我们可以很轻松的使用图中红线将样本点分为两类(蓝色和绿色)。
参考文献
[1] CRISTIANINI N, TAYLOR J S.支持向量机导论[M]. 李国正, 王猛, 曾华军, 译. 北京: 电子工业出版社, 2004.
[2] 张学工. 关于统计学习理论与支持向量机[J]. 自动化学报, 2000, 26(1): 32-41.
[3] VAPNIK V N. 统计学习理论的本质[M]. 张学工, 译. 北京: 清华大学出版社, 2000.
[4] VAPNIK V N. 统计学习理论[M]. 许建华, 张学工, 译. 北京: 电子工业出版社, 2004.
[5] 刘晓亮, 丁世飞. SVM用于文本分类的适用性[J]. 计算机工程与科学, 2010, 32(6): 106-108.
[6] 林开标, 王周敬. 基于支持向量机的传真收件人识别方法[J]. 计算机工程与应用, 2006, 42(7): 156-158.
[7] 谢塞琴, 沈福明, 邱雪娜. 基于支持向量机的人脸识别方法[J]. 计算机工程, 2009, 35(16): 186-188.
[8] 李颖新, 阮晓钢. 基于支持向量机的肿瘤分类特征基因选取[J]. 计算机研究与发展, 2005, 42(10): 1796-1801.
[9] 高伟, 王宁. 浅海混响时间序列的支持向量机预测[J]. 计算机工程, 2008, 34(6): 25-27.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)