k8s - pod卷的使用 - pod镜像的升级与回滚 - 探针
验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。在实际生产系统中,经常会遇到某个服务需要扩容的场景,可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的场景。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其。创建的卷默认存储在node节点
目录
2.1.2、也可以直接修改yaml文件,将nginx版本修改为 latest
HorizontalPodAutoscaler(HPA):实现Pod的自动扩缩容
kubectl describe svc my-nginx查看刚才发布的service详细信息:
知识点1:配置pod使用卷进行存储
1.1、为什么使用卷?
只要容器存在,容器的文件系统就会存在,因此当一个容器终止并重新启动,对该容器的文件系统改动将丢失,为了独立于容器的持久化存储,可以使用卷
官方文档:
##############################################################################################
1.2、为pod配置卷来存储
以下是pod的一些配置:
[root@k8s-master pod]# cat redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
创建pod:
[root@k8s-master pod]# kubectl apply -f redis.yaml
pod/redis created
可以看到:redis已经成功启动,使用kubectl describe pod redis查看 redis 详细信息。
[root@k8s-master pod]# kubectl get pod redis
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 74s
[root@k8s-master pod]# kubectl get pod redis -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis 1/1 Running 0 4m43s 10.244.2.7 k8s-node2 <none> <none>
[root@k8s-master pod]# kubectl describe pod redis
Name: redis
Namespace: default
Priority: 0
Node: k8s-node2/192.168.44.212
Start Time: Thu, 29 Sep 2022 20:50:46 +0800
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.2.7
IPs:
IP: 10.244.2.7
Containers:
redis:
Container ID: docker://6c54ddc5cc1402d37b8608d7836917fc6929c8f1bfbc827891557c624e6e096c
Image: redis
Image ID: docker-pullable://redis@sha256:b4e56cd71c74e379198b66b3db4dc415f42e8151a18da68d1b61f55fcc7af3e0
Port: <none>
Host Port: <none>
State: Running
Started: Thu, 29 Sep 2022 20:51:02 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/data/redis from redis-storage (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-lkk9p (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
redis-storage:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
kube-api-access-lkk9p:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 6m1s default-scheduler Successfully assigned default/redis to k8s-node2
Normal Pulling 5m59s kubelet Pulling image "redis"
Normal Pulled 5m45s kubelet Successfully pulled image "redis" in 14.485267427s
Normal Created 5m45s kubelet Created container redis
Normal Started 5m45s kubelet Started container redis
docker top :查看容器内部启动了什么进程
[root@k8s-node2 ~]# docker top 85e0c6ce1354
UID PID PPID C STIME TTY TIME CMD
polkitd 22370 22350 0 17:19 ? 00:00:00 redis-server *:6379
##############################################################################################
1.3、pod的存储卷类型
使用tree命令查看/var/lib/kubelet/pods

##############################################################################################
1.3.1、emptyDir
默认情况下,emptyDir卷实在node节点上的磁盘创建的,其实还可以让emptyDir卷存在于内存中而不是磁盘,通过设置medium参数即可。

创建的卷默认存储在node节点上的/var/lib/docker/volume目录下面

1.3.2、hostPath
用于将目录从工作节点的文件系统挂载到pod中

##############################################################################################
知识点2:pod里镜像的升级与回滚,扩缩
官方文档:
首先创建一个deployment,来启动三个nginxpod,yaml文件如下
[root@k8s-master pod]# cat my-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
可以看到,pod正在创建中,任意取一台node节点,使用docker images查看镜像,我们刚才创建的nginx镜像是1.14.2版本,因为以前使用kubectl启动过nginx pod,默认是使用的latest最新版本的nginx,因为yaml文件里指定了nginx镜像的版本,所以它是1.14.2,
[root@k8s-master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-9456bbbf9-27zc5 0/1 ContainerCreating 0 14s
nginx-deployment-9456bbbf9-64vn7 1/1 Running 0 14s
nginx-deployment-9456bbbf9-lgt7w 0/1 ContainerCreating 0 14s
redis 1/1 Running 0 52m
[root@k8s-master pod]#
[root@k8s-master pod]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/3 3 1 19s

##############################################################################################
2.1、pod镜像的滚动升级
2.1.1、设置新版本nginx为1.16.1
设置要升级nginx的版本:
[root@k8s-master pod]# kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
deployment.apps/nginx-deployment image updated
在nginx更新镜像版本的时候,查看pod的状态,就可以理解什么是滚动升级
[root@k8s-master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-9456bbbf9-64vn7 1/1 Running 0 12m
nginx-deployment-ff6655784-blfh9 1/1 Running 0 50s
nginx-deployment-ff6655784-fmdnb 1/1 Running 0 33s
nginx-deployment-ff6655784-v8k6p 0/1 ContainerCreating 0 15s
redis 1/1 Running 0 64m
[root@k8s-master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6655784-blfh9 1/1 Running 0 55s
nginx-deployment-ff6655784-fmdnb 1/1 Running 0 38s
nginx-deployment-ff6655784-v8k6p 1/1 Running 0 20s
redis 1/1 Running 0 64m
滚动升级:
Deployment 可确保在更新时仅关闭一定数量的 Pod
如果仔细查看上述 Deployment ,将看到它首先创建了一个新的 Pod,然后删除旧的 Pod, 并创建了新的 Pod。它不会杀死旧 Pod,直到有足够数量的新 Pod 已经出现。 在足够数量的旧 Pod 被杀死前并没有创建新 Pod。它确保至少 3 个 Pod 可用, 同时最多总共 4 个 Pod 可用。 当 Deployment 设置为 4 个副本时,Pod 的个数会介于 3 和 5 之间。
##############################################################################################
k8s 发布pod的策略
金丝雀发布:
在实践中,金丝雀发布一般会先发布到一个小比例的机器,比如 2% 的服务器做流量验证,然后从中快速获得反馈,根据反馈决定是扩大发布还是回滚。金丝雀发布通常会结合监控系统,通过监控指标,观察金丝雀机器的健康状况。如果金丝雀测试通过,则把剩余的机器全部升级成新版本,否则回滚代码
蓝绿发布:
蓝绿部署是指有两个完全相同的、互相独立的生产环境,一个叫做“蓝环境”,一个叫做“绿环境”。其中,绿环境是用户正在使用的生产环境。当要部署一个新版本的时候,先把这个新版本部署到蓝环境中,然后在蓝环境中运行冒烟测试,以检查新版本是否正常工作。如果测试通过,发布系统更新路由配置,将用户流量从绿环境导向蓝环境,蓝环境就变成了生产环境。
灰度发布:
灰度发布是金丝雀发布的延伸,是将发布分成不同的阶段/批次,每个阶段/批次的用户数量逐级增加。如果新版本在当前阶段没有发现问题,就再增加用户数量进入下一个阶段,直至扩展到全部用户。
滚动发布 :(启动一个新的pod,删除旧的pod)
一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。
##############################################################################################
2.1.2、也可以直接修改yaml文件,将nginx版本修改为 latest

然后重新apply一下yaml文件
[root@k8s-master pod]# kubectl apply -f my-nginx.yaml
deployment.apps/nginx-deployment configured
[root@k8s-master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-67dffbbbb-4zf7b 1/1 Running 0 4s
nginx-deployment-67dffbbbb-kmd9k 1/1 Running 0 2s
nginx-deployment-67dffbbbb-mlb7c 0/1 ContainerCreating 0 0s
nginx-deployment-ff6655784-fmdnb 1/1 Running 0 10m
nginx-deployment-ff6655784-v8k6p 1/1 Terminating 0 10m
redis 1/1 Running 0 74m
[root@k8s-master pod]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-67dffbbbb-4zf7b 1/1 Running 0 3m10s
nginx-deployment-67dffbbbb-kmd9k 1/1 Running 0 3m8s
nginx-deployment-67dffbbbb-mlb7c 1/1 Running 0 3m6s
redis 1/1 Running 0 77m
注意:在节点处于“不可用”状态时或者K8S节点工作负载异常,K8S平台会迁移节点上的容器实例,并将节点上运行的pod置为“Terminating”状态。其实就是滚动升级的体现
##############################################################################################
2.2、k8s pod镜像的回滚 rollout
假设我将nginx镜像设置为1.161然后再将其回滚到之前的nginx版本
kubectl set image deployment/nginx-deployment nginx=nginx:1.161查看deployment修订历史
kubectl rollout history deployment/nginx-deployment输出:
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161查看修订历史的详细信息
kubectl rollout history deployment/nginx-deployment --revision=2deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.
回滚历史修订版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2
检查回滚是否成功以及 Deployment 是否正在运行,运行
kubectl get deployment nginx-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 30m##############################################################################################
2.3 、pod的扩缩 (scale)
在实际生产系统中,经常会遇到某个服务需要扩容的场景,可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的场景。可以利用Deployment/RC的Scale机制来完成这些工作。
2.3.1、使用命令行来进程扩缩
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6655784-77fgv 1/1 Running 0 16h
nginx-deployment-ff6655784-djrxv 1/1 Running 0 16h
nginx-deployment-ff6655784-f4kkg 1/1 Running 0 16h
redis 1/1 Running 0 17h
[root@k8s-master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 16h
kubectl scale deployment nginx-deployment --replicas 5 :将部署控制器副本数设置为5
[root@k8s-master ~]# kubectl scale deployment nginx-deployment --replicas 5
deployment.apps/nginx-deployment scaled
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6655784-2vdqf 1/1 Running 0 2s
nginx-deployment-ff6655784-77fgv 1/1 Running 0 16h
nginx-deployment-ff6655784-djrxv 1/1 Running 0 16h
nginx-deployment-ff6655784-f4kkg 1/1 Running 0 16h
nginx-deployment-ff6655784-mz49f 1/1 Running 0 2s
redis 1/1 Running 0 17h
##############################################################################################
2.3.2、通过设置yaml文件来进行扩缩
直接修改yaml文件里的replicas副本数

然后使用kubectl apply -f + yaml文件应用即可
如何知道你的pod不够用了,需要进行扩缩?
1、业务量增大
通过监控,察觉资源使用很多,
HorizontalPodAutoscaler(HPA):实现Pod的自动扩缩容
HorizontalPodAutoscaler属于Kubernetes的一种资源类型;
##############################################################################################
知识点3:探针probe
官方文档:
probe 是由 kubelet 对容器执行的定期诊断。 要执行诊断,kubelet 既可以在容器内执行代码,也可以发出一个网络请求。
pod是由kubelet管理的,但是kubelet是怎么样知道pod是否存活? ----》引入探针的概念
探针探测的四种方法
使用探针来检查容器有四种不同的方法。 每个探针都必须准确定义为这四种机制中的一种:
exec在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
grpc使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC健康检查。 如果响应的状态是 "SERVING",则认为诊断成功。 gRPC 探针是一个 alpha 特性,只有在你启用了 "GRPCContainerProbe" 特性门控时才能使用。
httpGet对容器的 IP 地址上指定端口和路径执行 HTTP
GET请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
tcpSocket对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
三种探测结果

三种探针类型
livenessProbe指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为
Success。
readinessProbe指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为
Failure。 如果容器不提供就绪态探针,则默认状态为Success。
startupProbe指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,
kubelet将杀死容器,而容器依其 重启策略进行重启。 如果容器没有提供启动探测,则默认状态为Success。
##############################################################################################
知识点4:service 服务
官方文档:
service:
将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
使用 Kubernetes,你无需修改应用程序即可使用不熟悉的服务发现机制。 Kubernetes 为 Pod 提供自己的 IP 地址,并为一组 Pod 提供相同的 DNS 名, 并且可以在它们之间进行负载均衡。
service类型:
ClusterIP:提供一个集群内部的虚拟IP以供Pod访问(service默认类型)。
NodePort:使用 NAT 在集群中每个选定 Node 的相同端口上公开 Service 。使用<NodeIP>:<NodePort> 从集群外部访问 Service。
LoadBalancer:通过外部的负载均衡器来访问
示例:首先使用yaml文件启动3个nginx pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 3
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
[root@k8s-master service]# kubectl apply -f my_nginx.yaml
deployment.apps/my-nginx created
[root@k8s-master service]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx-cf54cdbf7-hd64b 0/1 ContainerCreating 0 4s
my-nginx-cf54cdbf7-j9pkd 0/1 ContainerCreating 0 4s
my-nginx-cf54cdbf7-rf7tm 0/1 ContainerCreating 0 4s
redis 1/1 Running 0 4h12m
编写yaml文件,发布服务
[root@k8s-master service]# cat my_service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- port: 8080
targetPort: 80
protocol: TCP
name: http
selector:
run: my-nginx
[root@k8s-master service]# kubectl apply -f my_service.yaml
service/my-nginx created
[root@k8s-master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 5d3h
my-nginx NodePort 10.1.20.144 <none> 8080:32697/TCP 6s
kubectl describe svc my-nginx查看刚才发布的service详细信息:
[root@k8s-master service]# kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.1.20.144
IPs: 10.1.20.144
Port: http 8080/TCP
TargetPort: 80/TCP
NodePort: http 32697/TCP
Endpoints: 10.244.1.3:80,10.244.2.4:80,10.244.3.5:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>

service负载均衡策略:
RoundRobin:轮询模式,即轮询将请求转发到后端的各个pod上(默认模式);
SessionAffinity:基于客户端IP地址进行会话保持的模式,第一次客户端访问后端某个pod,之后的请求都转发到这个pod上。
##############################################################################################
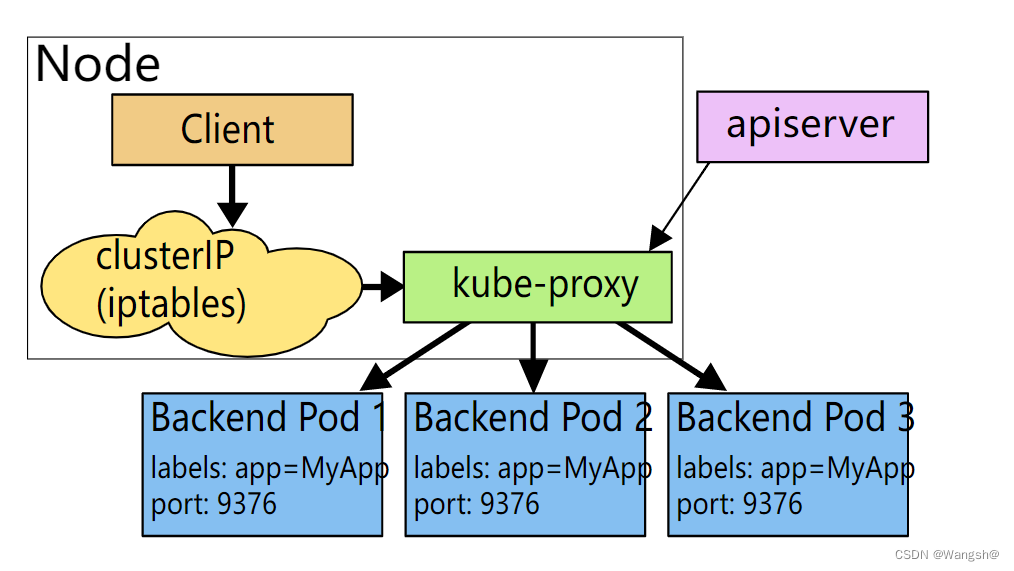
知识点5:kube-proxy 网络代理和负载均衡器
在 Kubernetes 集群中,每个 Node 运行一个
kube-proxy进程。kube-proxy负责为 Service 实现了一种 VIP(虚拟 IP)的形式,它的作用主要是负责Service的实现
##############################################################################################
kube-proxy的三种代理模式
userspace 代理模式
这种模式,kube-proxy 会监视 Kubernetes 控制平面对 Service 对象和 Endpoints 对象的添加和移除操作。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的后端
Pods中的某个上面(如Endpoints所报告的一样)。 使用哪个后端 Pod,是 kube-proxy 基于SessionAffinity来确定的。最后,它配置 iptables 规则,捕获到达该 Service 的
clusterIP(是虚拟 IP) 和Port的请求,并重定向到代理端口,代理端口再代理请求到后端Pod。默认情况下,用户空间模式下的 kube-proxy 通过轮转算法选择后端。

##############################################################################################
iptables 代理模式
这种模式,
kube-proxy会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会配置 iptables 规则,从而捕获到达该 Service 的clusterIP和端口的请求,进而将请求重定向到 Service 的一组后端中的某个 Pod 上面。 对于每个 Endpoints 对象,它也会配置 iptables 规则,这个规则会选择一个后端组合。默认的策略是,kube-proxy 在 iptables 模式下随机选择一个后端。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
你可以使用 Pod 就绪探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy 发送到已知已失败的 Pod。

##############################################################################################
IPVS 代理模式
特性状态:
Kubernetes v1.11 [stable]在
ipvs模式下,kube-proxy 监视 Kubernetes 服务和端点,调用netlink接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端 Pod 之一。IPVS 代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。

##############################################################################################

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)