k8s CRD相关
Kubernetes 1.7之后,提供了CRD(CustomResourceDefinitions)自定义资源的二次开发能力来扩展kubernetes API,通过此扩展可以向kubernetes API中增加新的资源类型,会比修改kubernetes apiserver的源代码或创建自定义的apiserver来的更加的简洁和容易。
Operator与CRD
Operator不应当被称作是一种工具或者系统,它应该算是一种封装、部署和管理 Kubernetes 应用的方法,尤其是针对最复杂的有状态应用去封装运维能力的解决方案,最早由 CoreOS 公司(于 2018 年被 RedHat 收购)的华人程序员邓洪超所提出。
Operator 将简洁的高级指令转化为 Kubernetes 中具体操作的方法, Helm 或者 Kustomize 的思路并不相同。Helm 和 Kustomize 最终仍然是依靠 Kubernetes 的内置资源来跟 Kubernetes 打交道的,Operator 则是要求开发者自己实现一个专门针对该自定义资源的控制器,在控制器中维护自定义资源的期望状态。通过程序编码来扩展 Kubernetes,比只通过内置资源来与 Kubernetes 打交道要灵活得多,譬如当需要更新集群中某个 Pod 对象的时候,由 Operator 开发者自己编码实现的控制器完全可以在原地对 Pod 进行重启,而无需像 Deployment 那样必须先删除旧 Pod,然后再创建新 Pod。
1、基本概念
-
CRD (Custom Resource Definition): 允许用户自定义 Kubernetes 资源,是一个类型(和 Pod、service 类似);包括可指定的名称和模式,无需任何编程。Kubernetes API提供和处理自定义资源的存储
-
CR (Custom Resourse): CRD 的一个具体实例;
自定义资源:扩展Kubernetes API或允许将自定义API引入kubernetes集群的对象
自定义控制器:以新的方式处理内置的Kubernetes对象,如Deployment、Service等,或管理自定义资源,如同管理本机Kubernetes组件 -
Operator模式(适用于CRD和自定义控制器controller):Operator基于Kubernetes资源和控制器增加了允许Operator执行常见应用程序任务的配置。
Kubernetes 1.7之后,提供了CRD(CustomResourceDefinitions)自定义资源的二次开发能力来扩展kubernetes API,通过此扩展可以向kubernetes API中增加新的资源类型,会比修改kubernetes apiserver的源代码或创建自定义的apiserver来的更加的简洁和容易。**用于统一部署/编排多个内置K8S资源(pod,service等),**熟练掌握 CRD 是成为 Kubernetes 高级玩家的必备技能。
1.2 创建crd
当你创建一个新的CustomResourceDefinition (CRD)时,Kubernetes API服务器将为你指定的每个版本创建一个新的RESTful资源路径,我们可以根据该api路径来创建一些我们自己定义的类型资源。
CRD可以是命名空间的,也可以是集群范围的,由CRD的作用域(scpoe)字段中所指定的,与现有的内置对象一样,删除名称空间将删除该名称空间中的所有自定义对象。customresourcedefinition本身没有名称空间,所有名称空间都可以使用。
operator与crd实质
k8s的文档中本身没有operator这个词,operator实质是指:用户注册自己自定义的Custom Resource Definition,然后创建对应的资源实例(称为Custom Resource,简称CR),而后通过自己编写Controller来不断地检测当前k8s中所定义的CR的状态,如果状态和预期不一致,则调整。Controller具体做的事就是通过调用k8s api server的客户端,根据比较预期的状态和实际的状态,来对相应的资源进行 增,删,改。
举个例子,deployment中的replica数量是3,意味着pod的数量必须维持在3,多了,就去除,少了,就创建。由于deployment是k8s内置的资源,k8s本身就有内置的controller来维护deployment的状态。如果自己要创建一个新的逻辑,那么就创建新的CRD和controller,来创建和维护对应的deployment,service之类的服务。
为什么需要CRD?
helm也可以做到统一部署/编排deployment,service,ingress,但它缺乏对资源的全生命周期的监控
CRD通过apiserver接口,在etcd中注册一种新的资源类型,此后就可以创建对应的资源对象&并监控它们的状态&执行相关动作,
https://zhuanlan.zhihu.com/p/423735403
因为k8s内置的对象对于高端玩家不够使
一个典型的例子就是一键化部署prometheus套件的kube-prometheus
如果我们自己在k8s中部署prometheus全家桶,需要写的yaml很多,而且分片等也要自己实现,那么这个项目刚好使用了k8s的 crd封装了serviceMonitor对象
kube-prometheus请看kube-prometheus和prometheus-operator教程之实战和原理介绍

k8s deployment controller
比如kube-controller-manager中的deployment控制器,在初始化的时候就会传入要监听 Deployments、ReplicaSets和pod三个informer对象
首先list一下对象到本地缓存,同时watch对象的变更,等于增量更新
func startDeploymentController(ctx ControllerContext) (controller.Interface, bool, error) {
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
然后内部会做sync其实就是Reconcile loop,即调谐循环
说白了就是对比对象的 actualState 和expectState的差异,执行对应的增删操作 比如deployment中的扩缩容操作
阿里云k8s日志采集 crd AliyunLogConfig
K8S内部会注册自定义资源(CRD,CustomResourceDefinition)AliyunLogConfig,并部署alibaba-log-controller
⚡ kubectl get AliyunLogConfig -n kube-system
NAME AGE
k8s-nginx-ingress 112d
security-inspector-polaris-log-c9f3e93dda54e4407ac5ad01b9a910e9a 112d
kubectl get AliyunLogConfig k8s-nginx-ingress -o yaml -n kube-system
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
creationTimestamp: "2022-05-20T11:34:26Z"
generation: 2
name: k8s-nginx-ingress
namespace: kube-system
resourceVersion: "1809"
uid: 946a3743-b1c2-4313-a91a-a0865c8085dc
spec:
extenions: ""
lifeCycle: null
logstore: nginx-ingress
logtailConfig:
configName: k8s-nginx-ingress
inputDetail:
plugin:
inputs:
- detail:
IncludeLabel:
io.kubernetes.container.name: nginx-ingress-controller
Stderr: false
Stdout: true
type: service_docker_stdout
processors:
- detail:
KeepSource: false
Keys:
- client_ip
- x_forward_for
- remote_user
- time
- method
- url
- version
- status
- body_bytes_sent
- http_referer
- http_user_agent
- request_length
- request_time
- proxy_upstream_name
- upstream_addr
- upstream_response_length
- upstream_response_time
- upstream_status
- req_id
- host
NoKeyError: true
NoMatchError: true
Regex: ^(\S+)\s-\s\[([^]]+)]\s-\s(\S+)\s\[(\S+)\s\S+\s"(\w+)\s(\S+)\s([^"]+)"\s(\d+)\s(\d+)\s"([^"]*)"\s"([^"]*)"\s(\S+)\s(\S+)+\s\[([^]]*)]\s(\S+)\s(\S+)\s(\S+)\s(\S+)\s(\S+)\s*(\S*).*
SourceKey: content
type: processor_regex
inputType: plugin
machineGroups: null
productCode: k8s-nginx-ingress
productLanguage: ""
project: ""
shardCount: null
status:
status: OK
statusCode: 200
在k8s上创建资源的过程
用户创建一个资源,实际上是把k8s抽象的资源根据资源清单(yaml文件)做实例化。具体过程如下:
(1)用户的资源请求发送给apiserver,通过apiserver的认证、授权、准入控制以后,通过apiserver把对应的资源定义信息存放在etcd中;
(2)对应资源类型的控制器一般被称为 controller或operator,===controller通过watch机制监听apiserver上的资源变动,通过对应资源变动事件触发对应类型资源的控制器从etcd中读取对应资源的定义,并将对应资源创建出来,并通过控制器内部的和解循环(control loop)监控着对应资源状态是否和用户定义的期望状态一样;===如果发现不一样,内部和解循环就会被触发,对应的控制器会向apiserver发起创建资源的请求,将对应资源重建,让对应资源的状态始终满足用户期望的状态。
对于etcd来说,它是就一个kv数据库,可以存储任意类型的kv数据,但在k8s上,apiserver将不同类型的资源定义抽象成不同的资源,使得用户创建对应资源必须是满足对应类型资源定义的规范,然后将资源定义存放在etcd中。简单讲就是存入etcd中的数据必须是满足对应apiserver接口定义的规范。
k8s扩展资源类型的方式
在k8s上扩展资源类型的方式有三种:
- 第一种是CRD,crd是k8s内置的资源类型,通过crd资源可以将用户自定义资源类型转换为k8s上资源类型;
- 第二种是自定义apiserver,这种方式是复用 Kubernetes 的一些特性的同时,自由度最高的方式。可以自定义存储等,同时保有一定程度的公共特性。Cloud TiDB 的实现就是通过自定义 API server 进行的;
- 第三种方式就是修改现有k8s apiserver的源码,让其支持对应用户自定义资源类型;
另外,进行自定义资源类型,只能把对应资源类型的定义信息写入到etcd中,不能让对应自定义类型资源实例化为一个自定义资源对象,它不能真正的跑起来,要想真正的跑起来,我们还需要一个自定义控制器,将对应资源实例化为k8s上的资源对象,并专门负责监听对应的资源类型的资源变化。
因此需要(1)自定义资源类型CRD;+(2)对应自定义资源类型的控制器controller;
controller的作用是通过API Server提供的接口实时的对指定的resource进行监听和执行的动作(watch,diff,action)。
备注:
k8s api = k8s资源 = pod、service、PV等
5种控制器类型:Deployment;StatefulSet;DaemonSet;Job;CronJob
crd和operator的区别:
所有的Operator都是基于Controller模式,Operator是使用CRD实现的定制化的Controller. 它与内置K8S Controller遵循同样的运行模式(比如 watch, diff, action);
operator的逻辑也是创建一个crd资源,再创建一个控制器。
即Kubernetes CRD Operator = kubernetes CRD+ custom controller
开发自己的k8s的controller的好处是什么?
现在一般部署k8s上自家的代码,几乎都是stateless,也就是说,对应的pod崩了之后,在重启一个就行,吞吐上不来的时候,横向增加pod数量就行。但是如果代码的逻辑需要维护一个状态(比如当前消息读取的offset),怎么办?pod崩了之后,如何恢复状态?可以上wal,上zookeeper,甚至k8s自身的etcd,如何自动化这部分“恢复的逻辑”?就是controller可以做的事儿,其实你用ansible等脚本也可以做,只是operator给你提供了一个开发友好的方式。你可以测试,部署,发布,一切都用go写,而不是在脚本里挣扎。还有就是用go自己写如何扩展伸缩。
这个Controller可以运行在k8s集群里,也可以是另外一个地方,本质就是一个使用了k8s客户端的小程序。
这里的开发逻辑是基于pull,而不是push,也就是说k8s的api server不会主动的发送事件给controller,而是k8s的go的client不断地‘拉’消息来获取最新的集群状态。这个‘拉’的方式的效率低,需要不断地get状态,这个肯定被考虑了,go的client内置就有一个队列来缓存事件消息,controller的逻辑就只需从队列中取消息处理即可。
k8s设计模式
https://zhuanlan.zhihu.com/p/94233354
k8s Prometheus Operator 架构:
Prometheus Operator 的目标是尽可能简化在 Kubernetes 中部署和维护 Prometheus 的工作。其架构如下图所示:
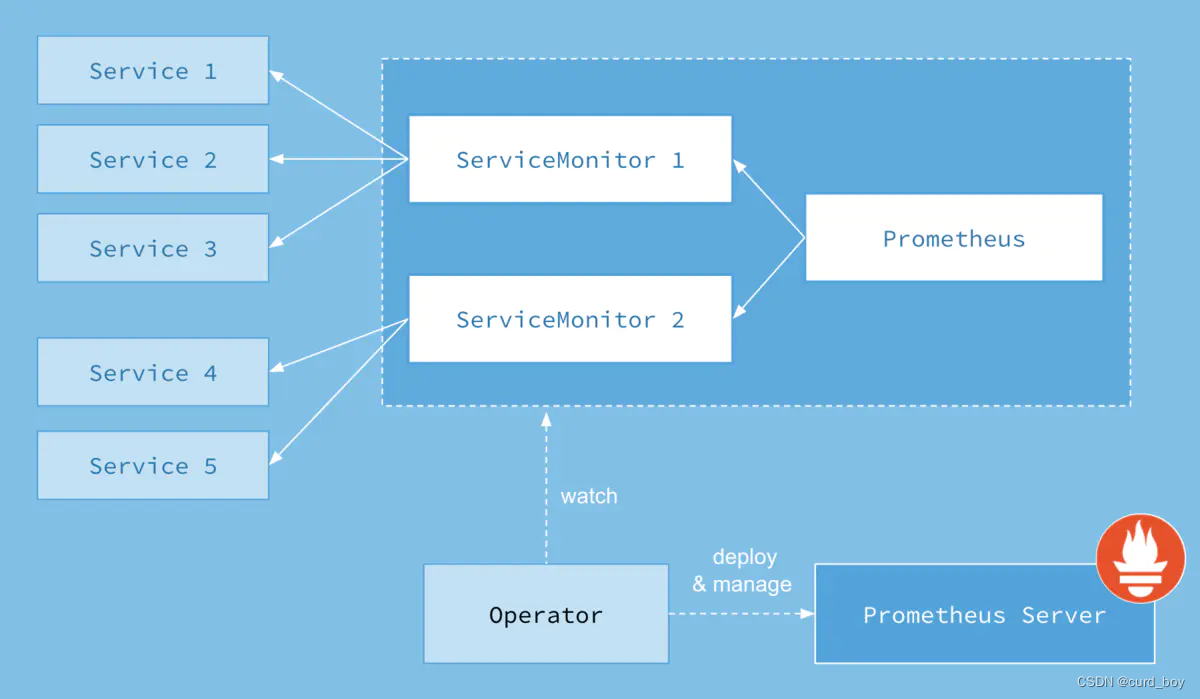
1)、Operator:
Operator 即 Prometheus Operator,在 Kubernetes 中以 Deployment 运行。其职责是部署和管理 Prometheus Server,根据 ServiceMonitor 动态更新 Prometheus Server 的监控对象,这里的ServiceMonitor资源对象就是指一个需要监控的目标对象在Prometheus中的配置信息。operator会根据Kubernetes标签查询自动生成监控目标配置;不需要学习普罗米修斯特有的配置语言。(operator就是一个将应用的操作性知识以软件的形式表现出来,通过基于K8s的Resources 和 Controllers来创建、配置、管理有状态的pod,使有状态的应用在k8s中得到简化的运用)
2)、Prometheus Server:
Prometheus Server 会作为 Kubernetes 应用部署到集群中。为了更好地在 Kubernetes 中管理 Prometheus,CoreOS 的开发人员专门定义了一个命名为 Prometheus 类型的 Kubernetes 定制化资源。我们可以把 Prometheus 看作是一种特殊的 Deployment,它的用途就是专门部署 Prometheus Server。Prometheus的配置是通过yaml文件中serviceMonitorSelector标签来选择ServiceMonitor资源对象来自动创建配置,其告警规则文件是通过一个独立的prometheus-rules.yaml文件来创建一个“PrometheusRule”自定义的资源对象。
3)、Service:
这里的 Service 就是 Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus中叫做 Target。每个监控对象都有一个对应的 Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler 对应的 Service。当然,Kubernetes 集群默认是没有这个 Service 的,Prometheus Operator 会负责创建。
4)、ServiceMonitor:
Operator 能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控 Kubernetes Scheduler,用户可以创建一个与 Scheduler Service 相对应的 ServiceMonitor对象。Operator 则会发现这个新的 ServiceMonitor,并将 Scheduler 的 Target 添加到 Prometheus 的监控列表中。ServiceMonitor 也是 Prometheus Operator 专门开发的一种 Kubernetes 定制化资源类型。
5)、Alertmanager:
除了 Prometheus 和 ServiceMonitor,Alertmanager 是 Operator 开发的第三种 Kubernetes 定制化资源。我们可以把 Alertmanager 看作是一种特殊的 Deployment,它的用途就是专门部署 Alertmanager 组件。。
https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/

开源、云原生的融合云平台
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)