
深度学习时,训练集的精度与测试集精度之间的关系
1. 训练精度 > 测试精度
当训练集和测试集两个loss 之间的有较大的差距时, 定义为高方差;
根本原因在于两点:
- 训练集,测试集数据不同分布;
- 模型过拟合;
1.1训练集,测试集数据分布不同
- 训练集和验证、测试集的数据分布不同。这个在于实验数据本身,可以尝试shuffle数据、重新划分数据集或者对实验数据进行扩充。
1.2 模型过拟合
- 模型过拟合。
表现为训练效果好,但是测试效果差,即模型的泛化能力差。
可以通过观察模型在训练集和测试集上的损失函数值随着epoch的变化,
如果是过拟合,模型在测试集上的损失函数值一般是先下降后上升。
1.3 过拟合的原因
-
训练数据太少,样本单一。
如果训练样本只有负样本,然后拿生成的模型去预测正样本,这肯定预测不准。
所以训练样本要尽可能的全面,覆盖所有的数据类型; -
存在噪声。
噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系; -
模型过于复杂, 层数太深。
模型太复杂,已经能够死记硬背记录下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的数据都有稳定的输出。模型太复杂是过拟合的重要因素。
1.4 过拟合解决方式
-
增加样本,要覆盖全部的数据类型。
数据经过清洗之后再进行模型训练,防止噪声数据干扰模型; -
降低模型复杂度。
在训练和建立模型的时候,从相对简单的模型开始,不要一开始就把特征做的非常多,模型参数挑的非常复杂; -
正则化。在模型算法中添加惩罚函数来防止过拟合。常见的有L1,L2正则化。而且 L1正则还可以自动进行特征选择;
-
集成学习方法bagging(如随机森林)能有效防止过拟合;
-
减少特征个数(不是太推荐,但也是一种方法)。可以使用特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间;
-
交叉检验,通过交叉检验得到较优的模型参数;
-
早停策略。本质上是交叉验证策略,选择合适的训练次数,避免训练的网络过度拟合训练数据;
-
DropOut策略。
Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元。
在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元,并用去掉隐藏层的神经元的网络来拟合我们的一批训练数据。由于dropout会将原始数据分批迭代,因此原始数据集最好较大,否则模型可能会欠拟合。
2. 训练精度 < 测试精度
当训练集和测试集两个loss, 虽然都是收敛, 但是loss值都很高, 定义为高偏差;
- 当偏差很高,训练集和验证集的准确率都很低,很可能是欠拟合;
- 表现为不能很好的拟合数据,训练集和测试集效果都不佳。
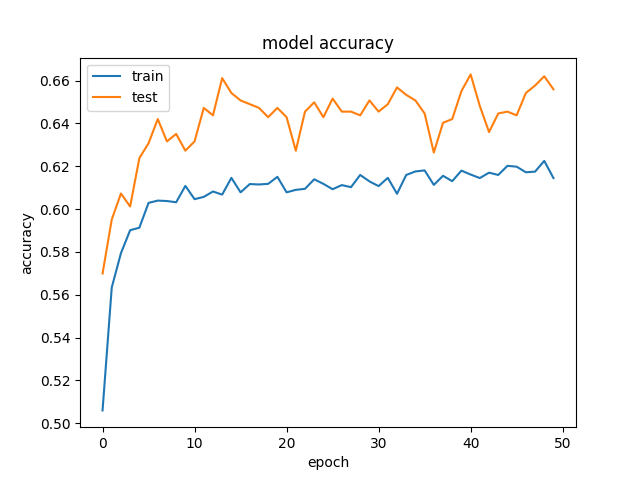
训练的时候,会得到测试集的准确率或者验证集的准确率高于训练集的准确率,这是什么原因造成的呢
本质上, 因为: 模型没有很好的捕捉数据特征,不能很好地拟合数据
2.1 欠拟合的原因
- 数据集太小,且数据集切分的不均匀。
当训练集和测试集的分布不均匀,如果模型能够正确捕捉到数据内部的分布模式话,这可能造成训练集的内部方差大于验证集,会造成训练集的误差更大。
训练集的数据做了一系列的增广,如旋转,仿射,模糊,添加噪点等操作;过多的增广使得训练集分布产生了变化。
这时你要重新切分数据集或者扩充数据集,使其分布一样;
- 模型正则化过多,
比如训练时dropout较大,比如为0.5;
而验证时的模型不会有dropout。
Dropout迫使你的神经网络成为一个非常大的弱分类器集合,这就意味着,一个单独的分类器没有太高的分类准确性,只有当你把他们串在一起的时候他们才会变得更强大。它能基本上确保您的测试准确性最好,优于您的训练准确性。
因为在训练期间,Dropout将这些分类器的随机集合切掉,因此,训练准确率将受到影响
在测试期间,Dropout将自动关闭,并允许使用神经网络中的所有弱分类器,因此,测试精度提高
2.2 欠拟合的解决方式
-
做特征工程,添加更多的特征项,比如特征组合、高次特征,来增大假设空间。如果欠拟合是由于特征项不够,没有足够的信息支持模型做判断;
-
集成学习方法boosting(如GBDT)能有效解决high bias;
-
增加模型复杂度。如果模型太简单,不能够应对复杂的任务。可以使用更复杂的模型。比如说可以使用SVM的核函数,增加了模型复杂度,把低维不可分的数据映射到高维空间,就可以线性可分,减小欠拟合;
-
减小正则化系数。
3. 训练精度很低
当训练集进度很低时, 表明模型没有正确的在学习或者根本没有在学习:
举例讲来
当训练准确率仍然很低(0.25左右)并且测试集混淆矩阵在四元(四类)分类问题中仅显示一列有数据而其他三列为0时,表明深度学习模型没有正确学习或根本没有学习。这可能是由于各种原因:
3.1 模型没有正确学习的原因
- 数据不足或质量差:用于训练的数据集可能很小、不具代表性或有干扰。深度学习模型需要大量且多样化的数据集才能很好地推广到新数据。
- 不正确的模型体系结构:所选的模型体系结构可能不适合特定问题,或者可能过于简单,无法捕获数据中的基础模式。
- 无效的训练过程:训练过程可能不充分,并且模型未经过足够的 epoch 或适当的学习率进行训练。
- 梯度消失或爆炸:基于梯度的优化方法可能会难以处理梯度消失或爆炸,使模型难以收敛。
- 数据不平衡:如果一个类主导数据集,则模型可能会发现更容易预测该类并忽略其他类,从而导致低准确性和偏斜的混淆矩阵。
不正确的数据预处理:不正确的数据预处理(例如不正确的规范化或特征缩放)可能会阻碍学习过程。
3.2 可选的解决方案
- 数据增强:通过应用数据增强技术来增加数据集的有效大小。这有助于创建其他训练示例并改进泛化。
- 查看模型体系结构:尝试更适合您的问题的不同模型体系结构。如果适用,请考虑使用更深入的模型或迁移学习。
- 超参数优化:优化超参数,例如学习率、批量大小和正则化参数,以找到适合您的模型的最佳配置。
- 检查梯度:通过在训练期间检查梯度来检查梯度是否消失或爆炸。如果梯度消失,请尝试使用跳过连接或批量归一化。对于分解梯度,梯度裁剪可能会有所帮助。
- 类平衡:通过使用过采样、欠采样或在训练期间使用类权重等技术来解决数据不平衡问题,以更加重视少数类。
6. 数据预处理:确保正确完成数据预处理,包括适当的规范化、缩放和处理缺失数据。
7. 检查错误:仔细检查代码是否存在可能影响训练过程的任何潜在错误或错误。
- 监控训练进度:在训练期间密切关注损失和准确性曲线,以检测任何异常情况。
- 集成方法:考虑使用打包或增强等集成方法组合多个模型以提高整体性能。
请记住,提高深度学习模型的性能可能是一个迭代过程。它通常涉及尝试不同的方法,以找到最适合您的特定问题的组合。此外,可能需要耐心和计算资源来有效地训练更深入和更复杂的模型。
4. 测试集精度震荡
还有一种情况, 训练集的进度稳步提升到1,但是测试集上的进度却是经常震荡;
测试集上验证精度的振荡可以归因于几个因素:
-
学习率: 如果学习率太高,模型在优化过程中可能会采取过大的步骤,导致它过度追求最优解,从而导致精度的振荡。试着降低学习率。
-
批量大小: 如果批次大小太小,模型可能在每一步都从你的数据的一个不太有代表性的样本中学习,导致更多的噪音和验证精度的波动。试着增加批量大小。
-
模型的复杂性: 如果你的模型太复杂,它可能会对训练数据中的噪声进行过度拟合,导致验证精度的不稳定。试着简化你的模型或增加正则化。
-
数据问题: 如果你的验证集不能代表你的训练集,模型可能会在它上面表现不一致。确保你的验证集能很好地代表你的训练集。
-
随机性: 由于训练过程中固有的随机性,验证精度的一些波动是可以预期的。这包括初始权重的随机性、数据顺序的随机性以及优化过程本身的随机性。
请记住,验证精度的一些振荡是正常的,特别是在训练的早期。但是,如果震荡很大或者持续了很多个 epochs,这可能表明训练过程有问题。
5. 小结
在深度学习训练过程中,如果训练集精度不上升,可能有以下原因:
-
学习率设置不当:学习率过低可能导致模型收敛速度过慢,训练精度难以提高;学习率过高可能导致模型无法收敛,训练精度波动。
-
模型复杂度不足:模型容量太小,无法很好地捕捉数据的特征,导致训练精度无法提高。
-
数据质量问题:数据可能存在错误标签、噪声,或者样本分布不均衡,导致训练精度无法提高。
-
优化算法问题:可能需要尝试其他优化算法,如Adam、RMSProp等,以改善训练过程中的收敛速度和效果。
-
模型初始化问题:模型参数的初始化方式可能影响训练过程。可以尝试使用不同的初始化策略,如Xavier或He初始化。
-
训练时间不足:训练时间可能不足以使模型收敛,可以尝试增加训练轮次或者训练时间。
当测试集精度大于训练精度时,可能存在以下原因:
-
训练集和测试集分布不一致:测试集的数据分布可能更简单,导致模型在测试集上的表现更好。
-
训练过程中使用了正则化技术,如Dropout、L1/L2正则化等,这些技术可能使训练精度受到限制,但有助于提高测试集精度。
-
训练集规模较小,模型可能无法充分学习数据特征,从而导致训练精度较低,但在测试集上表现较好。
随机性因素:模型训练和测试时的随机性可能导致测试集精度偶尔高于训练精度,但这种情况通常不会持续。
需要注意的是,测试集精度大于训练精度并不是一个普遍现象,需要仔细检查数据集的质量、模型的结构以及训练过程中的各种参数设置。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容









所有评论(0)