
经典文献阅读之--Translating Images into Maps(鸟瞰图分割)
0. 简介
这是一片22年的ICRA 2022杰出论文《Translating Images into Maps》。来自萨里大学的研究者引入了注意力机制,将自动驾驶的 2D 图像转换为鸟瞰图,使得模型的识别准确率提升了 15%。相关的代码已经开源,下面是他们Github开源代码。这里由于作者之前并不是搞NLP的,所以也是边学边写的,如有问题请多多提出。

1. 文章贡献
与以往的方法不同,这项研究将 BEV 的转换视为一个「Image-to-World」的转换问题,其目标是学习图像中的垂直扫描线(vertical scan lines)和 BEV 中的极射线(polar ray)之间的对齐。在对齐模型上,研究者采用了 Transformer 这种基于注意力的序列预测结构。研究者将基于 Transformer 的对齐模型嵌入一个端到端学习公式中,该公式以单目图像及其固有矩阵为输入,然后预测静态和动态类的语义 BEV 映射。下图为该模型框架
作者验证得到,Transformer 非常适合图像到 BEV 的转换问题,因为它们可以推理出物体、深度和场景照明之间的相互依赖关系,以实现全局一致的表征。同时作者在第一节末尾处提到了本文的主要贡献点为:
-
用一组序列到序列的一维转换将一幅前视图像转换为一个 BEV 图;
-
根据标准的IPM数学转换公式,作者构建了一个有空间限制且高效的 Transformer 网络,虽然该Transformer是针对水平方向完成的卷积操作,但是该模块仍然具备空间感知能力。
-
结合第三部分的公式和语言领域单调注意力的思想表明,对于精确的映射来说,知道图像中一个点下面是什么比知道它上面是什么更重要,尽管两者都使用会导致最佳性能;
-
该文章展示了轴向注意力如何通过提供时间意识来提高性能,并在三个大规模数据集上展示了最新的结果。
2. 具体算法
2.1 整体框架
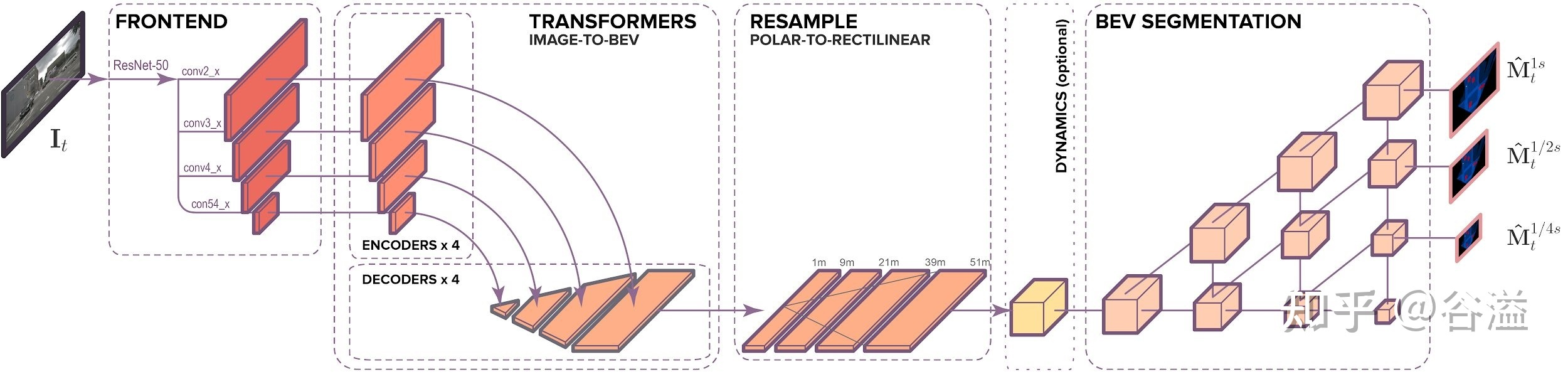
文中构建了的模型,有助于从对齐模型周围的单目图像预测语义 BEV 映射。如下图 1 所示,它包含三个主要组成部分:一个标准的 CNN 骨干,用于提取图像平面上的空间特征;编码器 - 解码器 Transformer 将图像平面上的特征转换为 BEV;最后一个分割网络将 BEV 特征解码为语义地图。
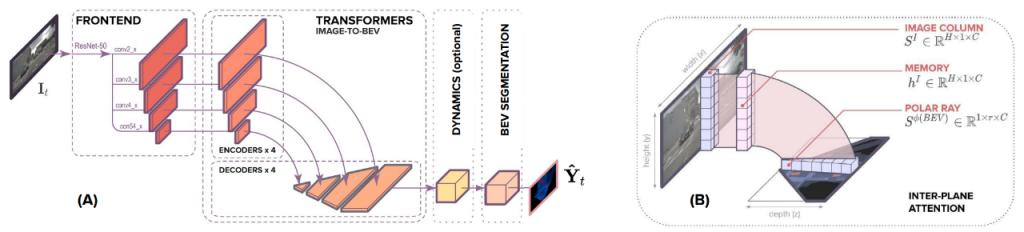
下面我们来详细讲述一下这个模型,首先(A) 部分为最主要的模型架构 。前端部分(frontend)主要用来提取多尺度空间特征,和大多数Transformer模型一样,以一个训练好的Resnet网络作为特征提取,并将多个尺度的通道传入到模型中。 编码器-解码器Transformer将空间特征从图像转换为 BEV,并利用可选的动态模块(dynamic module)将过去的空间的BEV特征来学习BEV的时空表征,BEV segmentation network(分割网络)主要用于处理 BEV 表征生成多尺度占用格。(B) 展示了文中的平面间注意机制 。在基于注意的模型中,图像的垂直扫描线被一条条地传递到transformer编码器,创建一个“内存(memory)”表征,解码为 BEV 极向射线(polar ray)。
2.2 Transformer 软注意机制
…详情请参照古月居

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)