如何搭建云原生大数据平台的K8s底座
数据时代,企业如何让云原生大数据平台借力K8s以发挥最大价值?
作者 | 智领云科技云平台研发经理 金津
供稿 | 智领云科技
伴随着数字化转型脚步的加快,大数据已成为企业经营管理的主要手段之一,越来越多的行业也选择通过大数据来实现业绩增长。今年年初,CNCF中国区总监陈泽辉在2022云原生超级英雄会上表示,Kubernetes (K8s)已无处不在,越来越多的人在使用云原生和Kubernetes。数据时代,企业如何让云原生大数据平台借力K8s以发挥最大价值,今天我们就跟着智领云科技云平台研发经理Jason一起来深入了解一下。
背景介绍:什么叫云原生架构
并不是运行在云主机上的程序或者容器化的程序就是云原生程序。
过去十年,随着云计算的发展,云原生技术架构逐步被更多的科技企业采纳和应用,其概念可归纳为以下几点:
Containerization:可运行代码必须容器化发布
Dynamic management:动态配置服务,按使用量付费
Micro-service:使用类似于K8s的云操作系统面向资源池发布和运维微服务,而不是自己面向节点操作
Orchestration: 使用底层云平台操作系统的分布式管理体系,而不是自己独立管理
Automation: 大部分运维操作由代码完成,而不是手工操作
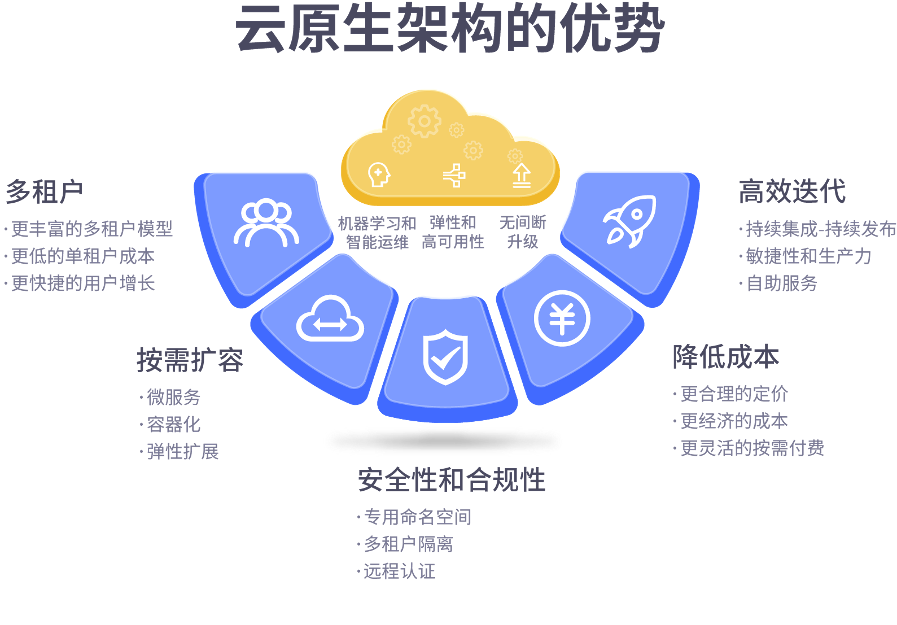
云原生架构的优势
使用云原生架构带来的好处很多,其优势归纳起来大概可以有以下几点:多租户、按需扩容、高效迭代、降低成本,以及安全性和合规性。

智领云联合创始人 & CEO彭锋博士曾以Twitter公司为例,强调云原生架构的优势。
“Twitter从2011年开始建设自己内部的私有云平台,我们看到的是业务开发效率数量级的增长,同时避免了部门墙,避免了数据孤岛和应用孤岛(因为都必须遵守云平台和其上的大数据平台的发布规范)。从80台机器的Hadoop集群,到8000台机器的全局数据平台,在统一集群中不断扩展数据能力矩阵,支撑业务运营。很多数据能力建设的工作,也因为应用的云原生化成为可能。”
对比企业在使用传统大数据平台时遇到的困难和难点,云原生架构的优势便能够更好地凸显出来。那么,云原生架构又是如何解决这些难点,成为如今大数据平台搭建的市场趋势呢?
传统大数据平台的难点,主要体现在其组件安装运维复杂:
- 每个大数据组件都有自己的安装流程,系统要求,第三方库支持要求
- 独立的分布式管理,高可用,容错,日志,授权,鉴权机制
- 难以实现对于多租户,资源隔离,审计,计费的支持
- 工具体系复杂,无法支持CI/CD,系统测试,质量控制
- 无法实现大数据组件及应用的混合调度,资源使用率低
因此,数据应用的开发流程及管理散布在各个系统组件中,缺乏统一全局的管理,开发运营效率低。
传统大数据平台存在的问题,已经逐渐无法支撑数据驱动业务运营更为丰富的需求,所以呈现出来的市场趋势就是大数据平台的云原生化。具体来看:
- K8s基本已成为云平台的标配,我们只需要适配K8s即可
- 新的大数据组件更多的以云原生的方式发布
- Hadoop会被云原生存储+资源调度取代,现有Hadoop集群的工作负载需要迁移
- 原始的大数据平台已经建设完毕,DataOps的需求出现
- 云原生应用的普及,数据源逐渐标准化,在线集成处理成为可能
- 数字化转型需要低门槛,低代码的自助型平台
规划设计
接下来,我们要讨论的是怎样规划设计这样的云平台系统,这部分可以从基础设施层(IaaS)、平台服务层(PaaS),以及应用交付层来看,而每个层面都需要结合当前的业务规模和需求来权衡一些问题,比如
- IaaS:基础设施管理成本的权衡
- PaaS:K8s的版本管理、监控告警日志集成
- 应用交付:如何隔离容器编排层的复杂概念,专注于应用开发
我们的目标是要去交付一个K8s云平台,需求可以先拆分为以下三大方面:
首先 IaaS 层的建设,我们要决定是托管在公有云,还是自建私有云,或者是最复杂的混合云架构;
其次 PaaS 层的建设,我们要决定是用原生的K8s,还是发型版的K8s(各公有云厂商的K8s服务,或者像Kubesphere、Rancher、OpenShift这些面向私有发布的发行版等);
最后是应用交付的体系,我们的目的不是为了搭建K8s而搭建,交付了K8s平台之后,更重要的是如何快速、灵活地将业务系统“搬”到K8s平台上来,并在未来能够充分利用好K8s容器编排的各种特性,例如容器运行时/网络/存储接口、故障自动迁移、弹性伸缩、租户控制等。
针对以上三个方面的设计规划,其现状及问题包括:
IaaS层:最主要的是管理成本的权衡:公有云搭建最快,具备公有云产品使用的能力即可,管理成本相对较低,但产品价格很贵;私有云需要有虚拟化平台建设及运维的能力,管理成本相对较高;混合云前两者的能力都需要,还需要具备网络基础设施建设的能力,管理成本最高。
PaaS层:官方开源版本无任何定制,但要构建一套完整的生态系统,需要自行搭建例如仓库、监控、报警、日志、负载均衡等额外的系统,技术选型可控但对团队能力要求高;发行版一般提供一套比较完备的生态系统,但技术选型往往不可控,容易被绑定,另外难以满足自定义需求的时候,还是需要自行建设;除此之外,K8s的版本发布非常快,如果想用新的特性或者修复bug,需要跟上新版本,但底层平台升级往往是非常吃力且容易出事故的。
应用交付:K8s的优势是容器化编排能力很强,一开始看上去像海面上一座优美的小岛;劣势是它的系统架构、概念原理、管理使用非常复杂,等深入了解了之后才发现小岛原来只是露出海面的冰山一角;对于应用开发者来说,平台工程师应该把容器编排层的能力抽象隔离并封装简化,让上层用户专注于应用开发,不需要承受整个冰山的重量。
实现路径
结合规划设计各层面的具体实践,接下来要讲一讲我们自己的实现路径。首先,在基础设施层和平台服务层,面向公有云场景,我们的实践是基于阿里云容器服务ACK去构建在公有云场景的K8s平台。
ACK 整合了阿里云虚拟化、存储、网络和安全能力,提供高性能可伸缩的容器应用管理能力,支持企业级容器化应用的全生命周期管理。
ACK当前支持的版本为:1.22.3 和 1.20.11,仅发布Kubernetes双数号的大版本,版本支持策略如下:
集群创建:ACK支持Kubernetes两个大版本的创建,例如v1.16、v1.18。当新版本Kubernetes发布时,较老的一个版本将不再开放创建功能。
升级和运维保障:ACK保障最近的三个Kubernetes大版本的稳定运行,同时支持最新版本往前两个大版本的升级功能,例如当前最新版本为v1.20,则ACK支持v1.18、v1.16的升级功能。
工单答疑:ACK仅提供最近的三个Kubernetes大版本的技术支持。
那么,在私有云场景中,我们的建设实践是采用了VMware的一套技术架构,物理机采用DELL的PowerEdge系列。并在物理机上部署VMware ESXi,通过VMware vCenter Server将多台物理机资源组成资源池,组成虚拟化管理平台。

除此之外,在私有发布场景中,还需要去部署K8s的整个系统,我们选用了青云的KubeKey。
这款开源K8s安装器项目,可以轻松、高效、灵活地单独或整体安装 Kubernetes 和 KubeSphere。
支持的Linux 发行版本
- Ubuntu 16.04, 18.04, 20.04
- Debian Buster, Stretch
- CentOS/RHEL 7
- SUSE Linux Enterprise Server 15
支持的Kubernetes 版本
- v1.17: v1.17.9
- v1.18: v1.18.6
- v1.19: v1.19.8
- v1.20: v1.20.6
- v1.21: v1.21.5 (default)
- v1.22: v1.22.1

使用起来也比较简单,具体操作如下:
1、创建集群
./kk create cluster -f config.yaml
2、添加节点
./kk add nodes -f config.yaml
3、删除节点
./kk delete node <nodeName> -f config.yaml
4、删除集群
./kk create cluster -f config.yaml

在应用交付层,我们的实践是基于KubeVela这一引擎来做平台建设。
KubeVela 作为一个开箱即用的现代化应用交付与管理平台,使得应用在面向混合云环境中的交付更简单、快捷。使用 KubeVela 的软件开发团队,可以按需使用云原生能力构建应用,随着团队规模的发展、业务场景的变化扩展其功能,一次构建,随处运行。

KubeVela 围绕着云原生应用交付和管理场景展开,背后的应用交付模型是 Open Application Model,简称 OAM ,其核心是将应用部署所需的所有组件和各项运维动作,描述为一个统一的、与基础设施无关的“部署计划”,进而实现在混合环境中标准化和高效率的应用交付。

为什么要用 KubeVela?
云原生技术的发展趋势正在朝着利用 Kubernetes 作为公共抽象层来实现高度一致的、跨云、跨环境的的应用交付而不断迈进。然而,尽管 Kubernetes 在统一底层基础架构细节方面表现出色,它并没有在混合的分布式部署环境之上提供应用层的软件交付模型和抽象。我们已经看到,这种缺乏统一上层抽象的软件交付过程,不仅降低了生产力、影响了用户体验,甚至还会导致生产中出现错误和故障。
然而,为现代微服务应用的交付过程建模是一个高度碎片化且充满挑战的事情。到目前为止,绝大多数试图解决上述问题的技术方案,要么过于简单以致于无法覆盖实际生产使用中的问题,要么过于复杂难以落地使用。云原生带来的基础设施能力爆发式增长也决定了新一代的应用管理平台不能以硬编码的方式做能力的集成和 UI 的构建,除了满足基础的功能和场景,平台本身的扩展能力成为了新时代应用管理平台的核心诉求。这就意味着平台不仅要简单易用,还要能够随着应用交付和管理的需求复杂度提升能够不断扩张,能够让开发者自助式的接入和使用,充分享受云原生生态的红利。
这也是 KubeVela 出现的核心价值:它既能够简化面向混合环境(多集群/多云/混合云/分布式云)的应用交付过程;同时又足够灵活可以随时满足业务不断高速变化所带来的迭代压力。它本身是一个面向混合交付环境同时又高可扩展的应用交付引擎,满足平台构建者的扩展和自建需求;同时又附加了一系列开箱即用的扩展组件,能够让开发者自助式的开发、交付云原生应用。
KubeVela 核心功能
统一的应用交付模型:KubeVela 创新性的提出了 开放应用模型(OAM)来作为应用交付的顶层抽象,该模型支持交付任意类型的工作负载包括容器、数据库甚至是虚拟机到不同的云和 Kubernetes 集群中。用户无需关心任何基础设施细节,只需要专注于定义和部署应用即可。应用只需要一次编排,就可以随处运行,免去了适配不同平台的痛苦。
声明式交付工作流:KubeVela 的整个交付模型完全是由用户声明式驱动的,兼顾用户体验和健壮性,其控制循环能够有效避免配置漂移,且具备多租权限控制能力。用户可以通过 CUE 语言(一种源自 Google Borg 系统的数据配置语言)自由的根据需求场景来设计和选用交付工作流中的每一个步骤,满足业务快速增长的需求,同时持续保证生产环境面向终态的稳定性。
多集群/混合云应用交付控制平面:KubeVela 原生支持丰富的多集群/混合环境持续交付策略,也支持跨环境交付。这些交付策略为你的分布式交付流程提供了充足的效率和安全的保证。KubeVela 提供的中心化管控能力也减轻了到每一个集群去排查问题的负担,针对不同的平台提供统一的体验,为了享受自动化交付的便利,你再也不需要成为 Kubernetes 专家。
KubeVela vs. 传统 PaaS 平台
传统 PaaS (如 Heroku,Cloud Foundry 等) 提供完整的应用程序部署和管理功能,旨在提高开发人员的体验和效率。在这个场景下,KubeVela 也有着相同的目标。
不过,KubeVela 和它们最大的区别在于其可扩展性。
KubeVela 是可编程的。它的交付工作流乃至整个应用交付与管理能力集都是由独立的可插拔模块构成的,这些模块可以随时通过编写 CUE 模板的方式进行增/删/重定义且变更会即时生效。与这种机制相比,传统的 PaaS 系统的限制非常多:它们需要对应用类型和提供的能力进行各种约束来实现更好的用户体验,但随着应用交付需求的增长,用户的诉求就一定会超出 PaaS 系统的能力边界。这种情况在 KubeVela 平台中则永远不会发生。
此外,KubeVela 是一个独立于运行时集群的应用交付控制平面(这是我们认为的下一代 PaaS 系统的合理形态),而现有的 PaaS 则往往选择以插件形式部署在运行时集群当中。
下面,我们来举一个最简单的示例来看一看怎样将一个应用或服务,能够快速的在K8s上以容器化的方式运行起来:

交付Helm组件

在交付应用后,我们需要运维该应用来观测它的指标和日志。
基于此,我们在KubeVela引擎构建云平台时,在日志、监控告警等层面做了相应的自动化的集成。主要的四个方面包括监控目标、监控面板、日志采集、告警规则特征上做了相应的开发。
下图为监控目标特征、监控面板特征、日志采集特征、告警规则特征:




向上赋能
基于前面构建好的底层云平台系统,最后我们讲讲它的能力。
由于我们公司核心产品是一个一站式的云原生DataOps平台,底层的云平台系统搭载了上层的容器化大数据平台、数据集成开发平台、数据资产运营平台、数据质量平台等各种数据平台系统。
- 从应用交付的角度,云平台赋能了数据平台的大数据及各种中间件快速容器化集成落地,例如典型的离线计算平台开源组件Hive、Spark、HDFS以及流处理平台开源组件Kafka、Flink等
- 从多租户的角度,云平台赋能了数据平台的多租户管理,例如资源配额管理、鉴权、授权等
- 从弹性的角度,云平台赋能了数据平台服务的弹性伸缩,以及集群级别的伸缩等
- 从调度的角度,云平台赋能了数据平台服务的K8s原生调度(Spark on K8s),以及增强型调度框架如Volcano的集成等
由于核心引擎提供的灵活、可扩展性,未来我们的云平台还能够将更多的K8s生态及系统能力纳入进来,向上面的业务层提供更强大的功能及性能支撑。
具体来说,目前的阶段性成果体现在:
大数据组件的快速交付:Hive、Spark、HDFS、Kafka、Flink...
数据应用的快速开发集成:自定义程序发布
统一的可观测性集成和展示:监控、告警、日志
全系统的多租户实现:租户配额管理、服务/数据的鉴权+授权
未来更进一步向上赋能DataOps的能力则体现在:
开发运维:CI/CD,多环境管理
可观测性:大数据平台全链路追踪
弹性伸缩:大数据作业资源弹性、自适应
增强型调度:Volcano Scheduler,提供更适合大数据系统的使用
(完)
作者简介:金津,智领云科技云平台研发经理,华中科技大学计算机系硕士。加入智领云6年多,长期从事云原生、容器化编排领域研发工作,主导了智领云自研的BDOS应用云平台产品开发,并在多个大规模项目中成功实施落地,在大规模容器化编排系统方向有丰富的实践经验。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)