paddlespeech_server语音识别通过tcpflow抓包确定post请求参数
paddlespeech_server语音识别通过tcpflow抓包确定post请求参数以及链接。并且使用python来调用paddlespeech_server服务
在paddlespeech开源项目中(https://github.com/PaddlePaddle/PaddleSpeech),我们可以使用paddlespeech_server和paddlespeech_client来进行语音识别,paddlespeech_server作为服务端,paddlespeech_client作为客户端。
使用方式如下:
paddlespeech_server start --config_file ./paddlespeech/server/conf/application.yamlpaddlespeech_client asr --server_ip 127.0.0.1 --port 8090 --input pr-12-2.wav那么假如现在我们使用paddlespeech_server作为服务端,然后我们自己使用编程语言,例如java、Python去调用paddlespeech_server,需要怎么做呢?
其实paddlespeech_server就是提供了一个http接口,是一个post请求,现在要确定的就是这个接口的请求参数是什么,以及请求链接是什么,这样我们就可以使用编程语言去调用了。
我最先想到的就是进行抓包,来确定paddlespeech_server和paddlespeech_client进行http调用时,传递了哪些参数?在网上一番搜索,确定了一款在linux中使用的抓包工具,就是tcpflow,它可以抓取http接口整个参数。
centos安装tcpflow的方式: sudo yum install tcpflow
现在我们就可以开始动手肝了。
①我们把paddlespeech_server启动起来:
paddlespeech_server start --config_file ./paddlespeech/server/conf/application.yaml启动日志如下:


②使用tcpflow进行抓包监听
tcpflow -i lo -e http -c host 127.0.0.1 or 192.168.6.138 > log.log-i lo就是监听本地地址
-e http请求
-c host 抓取源头为127.0.0.1或者192.168.6.138的请求地址
> log.log就是将抓包的数据存入log.log文件,避免刷屏难找请求报文。

③paddlespeech_client进行请求
一旦paddlespeech_client请求成功,第②步中的log.log文件就会抓取到报文

请求完成后,我们在第二步的界面按住ctrl + c中断,然后查看log.log文件
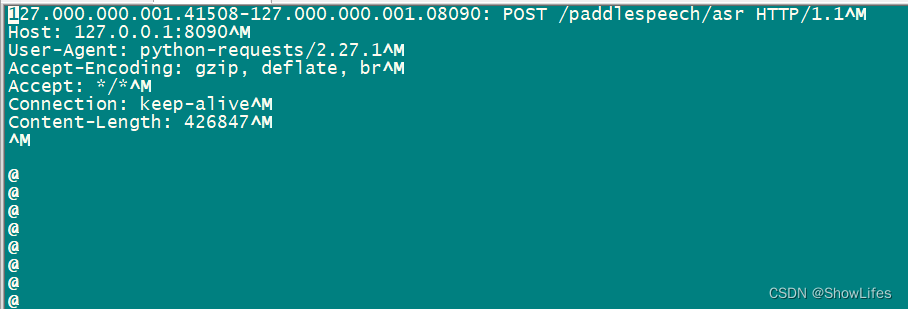
其部分截图如下:


从以上图可以得知:
paddlespeech_server暴露的url为: http://127.0.0.1:8090/paddlespeech/asr
post请求参数为:
{"audio": "", "audio_format": "wav", "sample_rate": 16000, "lang": "zh_cn"}其中audio参数猜测就是声音文件的base64编码。
为了验证其audio的值为base64编码,我用python语言将一个wav声音文件得出base64编码,然后使用postman进行访问

哈哈,访问成功了,验证了其我的猜测!!!
后面使用python进行编码直接调用http://127.0.0.1:8090/paddlespeech/asr这个接口应该就很容易了。
其Python完整代码如下:
# -*-coding:utf-8 -*-
import base64
import requests
import json
def toBase64(file):
with open(file, 'rb') as fileObj:
audio_data = fileObj.read()
base64_data = base64.b64encode(audio_data)
return base64_data.decode()
def audioRequest(audioBase64, requestUrl):
headers = {
"content-type": "application/json"
}
data = {
"audio": audioBase64,
"audio_format": "wav",
"sample_rate": 16000,
"lang": "zh_cn"
}
response = requests.post(requestUrl, data=json.dumps(data), headers=headers)
print(response.text)
print(response.status_code)
audioFilePath = "D:\\develop\\server\\nginx-1.13.9\\html\\videoVoice\\convert\\pr-12-2.wav"
audioRequestUrl = "http://vm4:8090/paddlespeech/asr"
audioBase64Str = toBase64(audioFilePath)
audioRequest(audioBase64Str, audioRequestUrl)
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)