人工智能:第二章 机器学习之线性回归
目标这次学习:机器学习的线性回归模型,先了解下机器学习和线性回归的介绍,然后通过三个案例实战来进行理解和熟练掌握机器学习的线性回归模型。机器学习介绍下面大概介绍下什么是机器学习,机器学习的应用场景,机器学习的基本原理框架和机器学习的类别。什么是机器学习可以先思考下图的问题机器学习的应用场景实现机器学习的基本框架机器学习的类别回归分析介绍什么是回归分析可以先思考下图的问题线性回归...
目标
这次学习:机器学习的线性回归模型,先了解下机器学习和线性回归的介绍,然后通过三个案例实战来进行理解和熟练掌握机器学习的线性回归模型。
机器学习介绍
下面大概介绍下什么是机器学习,机器学习的应用场景,机器学习的基本原理框架和机器学习的类别。
什么是机器学习
可以先思考下图的问题
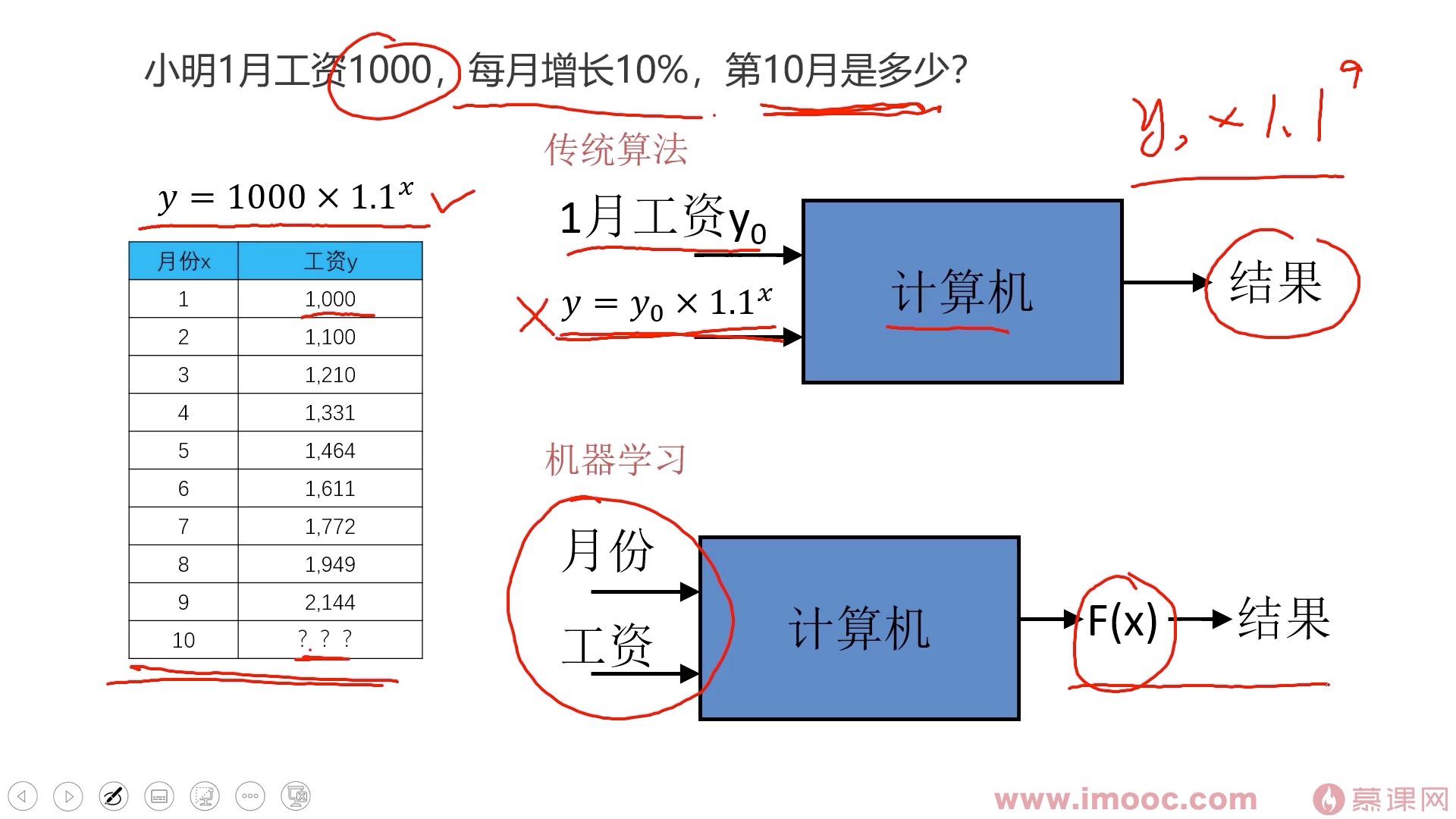

机器学习的应用场景

实现机器学习的基本框架
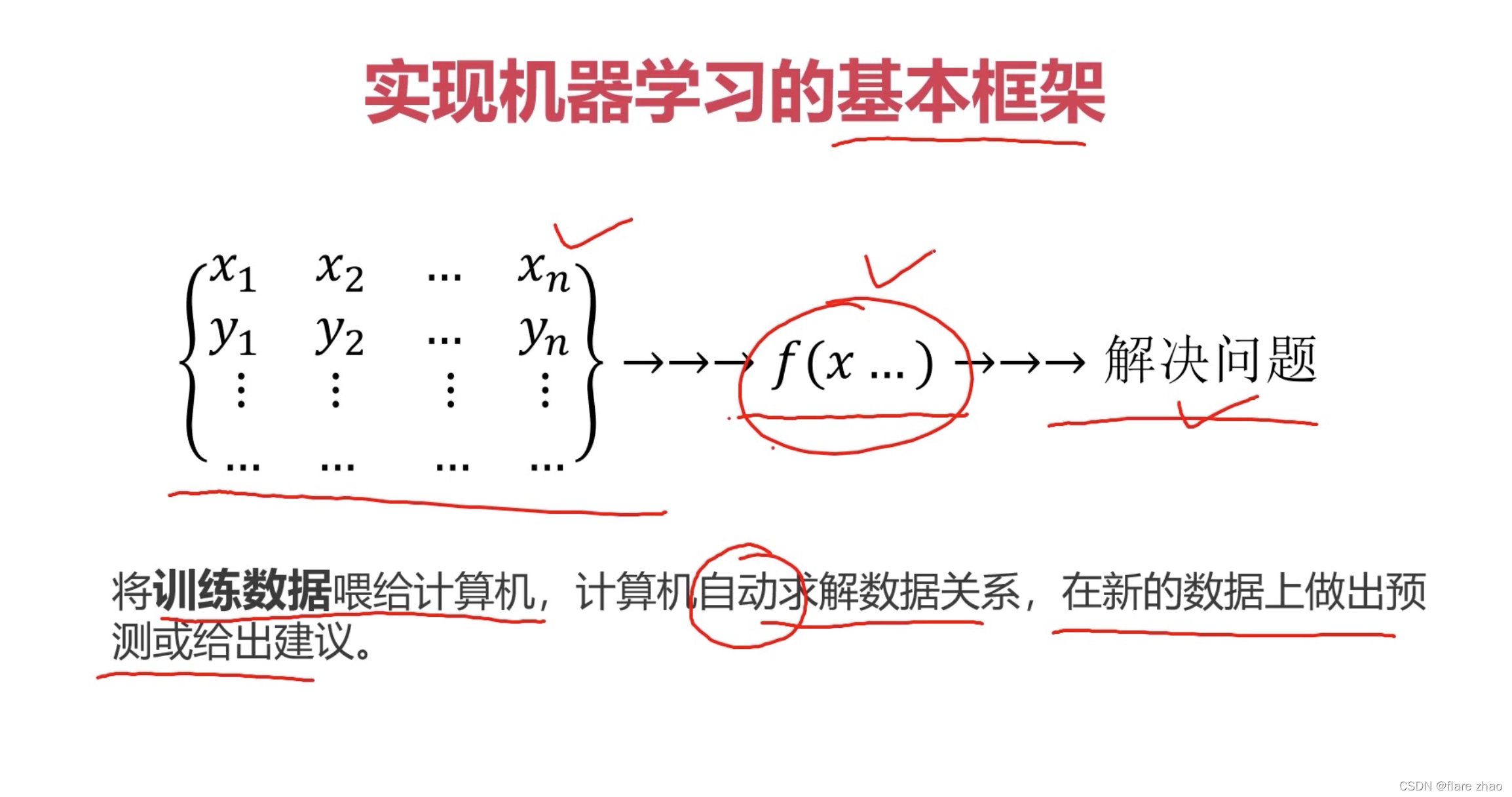
机器学习的类别



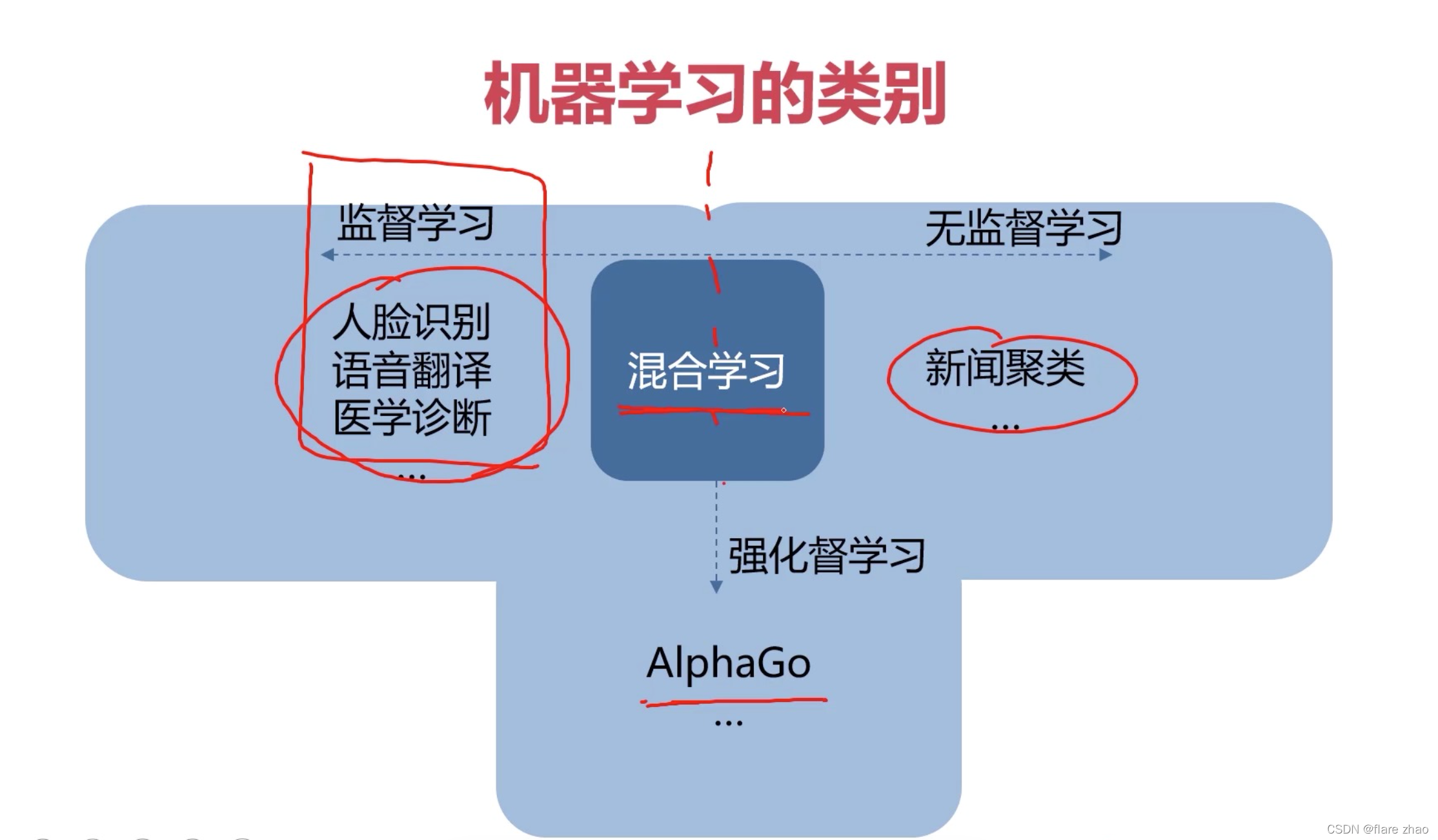
回归分析介绍
什么是回归分析
可以先思考下图的问题

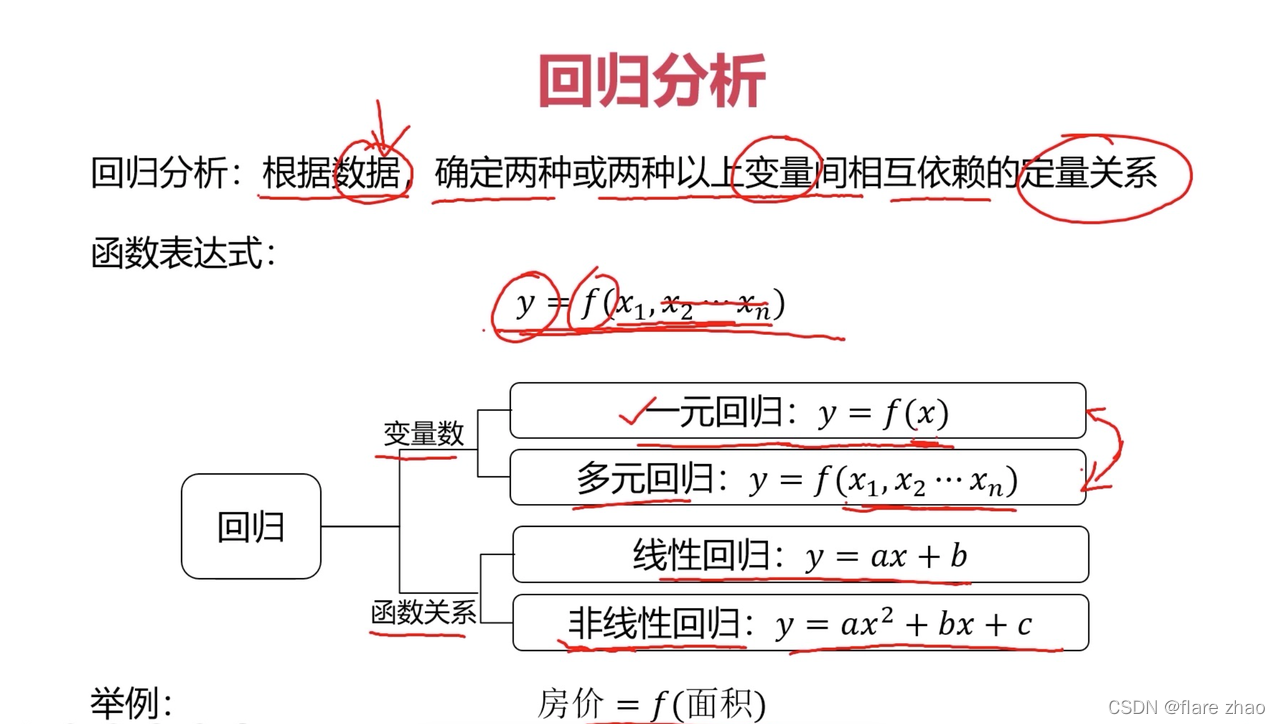
线性回归
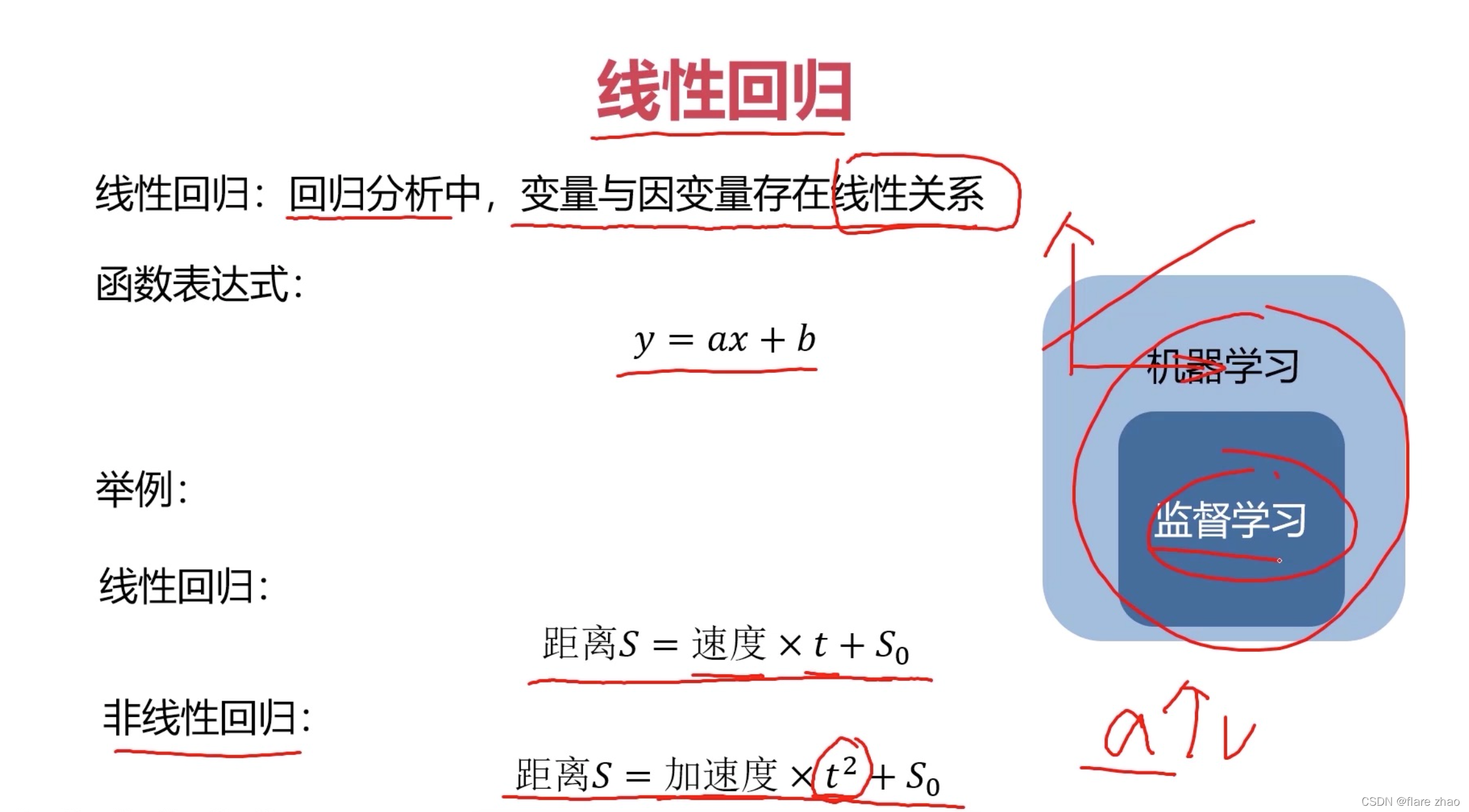
回归问题求解









线性回归实战准备
scikit-learn

安装scikit-learn工具包前,确保python已经安装了numpy和scipy工具包
调用SKlearn求解线性回归问题

模型评估
线性回归里评估指标主要有均方误差(MSE-mean square error)和R方值R²
MSE越小越好,R²分数越接近1越好


图形展示
Matplotlib 是一个 Python 的 2D绘图库,可以生成出版质量级别的图形。可以绘制线图、散点图、等高线图、条形图、柱状图、3D 图形、甚至是图形动画等等。

任务介绍
实战一:
基于generated_data.csv数据,建立线性回归模型,预测x=3.5对应的y值,评估模型表现
实战二:
基于usa_housing_price.csv数据,建立线性回归模型,预测合理房价:
1、以面积为输入变量,建立单因子模型,评估模型表现,可视化线性回归预测结果
实战三:
1、以income、house age、numbers of rooms、population、area为输入变量,建立多因子模型,评估模型表现
2、预测Income=65000,House Age=5,Number of Rooms=5,population=30000,size=200的合理房价
流程
整体的思路,流程是:
1、导入数据
2、把数据分别赋值给X和y
3、创建线性回归模型
4、模型的拟合训练
5、模型预测
6、模型的评估
7、预测结果的可视化,直观对比预测价格和实际价格的差异
具体步骤
实战一:基于generated_data.csv数据,建立线性回归模型,预测x=3.5对应的y值,评估模型表现
1、导入generated_data.csv数据
先看下这个文件里面的内容

可以看到是非常简答的一组数据
# 导入工具包
import numpy as np
import pandas as pd
# 读取generated_data.csv文件数据
path='Desktop/artificial_intelligence/Chapter2/generated_data.csv'
data=pd.read_csv(path)
type(data)
pandas.core.frame.DataFrame
# 查看读取到的文件
data.head()
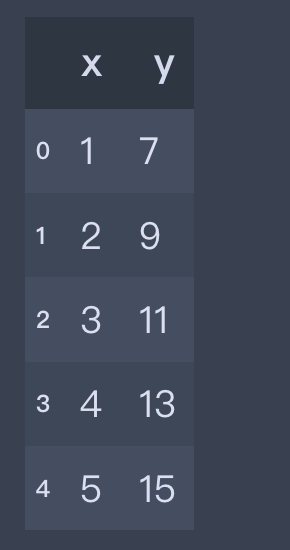
2、把数据分别赋值给X和y
X = data['x']
y = data['y']
type(X)
pandas.core.series.Series
3、可视化数据
from matplotlib import pyplot as plt
plt.figure(figsize=(10,8))
plt.scatter(X,y)
plt.show()

4、创建线性回归模型
from sklearn.linear_model import LinearRegression
lr_model=LinearRegression()
5、模型拟合训练
在拟合训练之前,需要对数据X进行处理,试它的一维数据变成二维数据,否则直接拟合,会报错。

X.shape
(10,)
先转换成numpy数组,再reshape变成二维数组
X=np.array(X)
X
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X = X.reshape(-1,1)
X
array([[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10]])
X.shape
(10, 1)
#拟合训练
lr_model.fit(X,y)
6、查看线性回归模型拟合后的系数a,b的值
y=ax+b
a=lr_model.coef_
b=lr_model.intercept_
print(a)
print(b)
[2.]
5.000000000000005
7、模型预测
预测x=3.5的时候对应的y值
c_predict=lr_model.predict([[3.5]])
print(c_predict)
y_predict=lr_model.predict(X)
print(y_predict)
[12.]
[ 7. 9. 11. 13. 15. 17. 19. 21. 23. 25.]
8、模型评估
from sklearn.metrics import mean_squared_error,r2_score
MSE=mean_squared_error(y,y_predict)
R2=r2_score(y,y_predict)
print(MSE)
print(R2)
1.4909471108677122e-29
1.0
MSE值很小,接近于0,R2值为1,可以看出这个模型对这组数据拟训练的非常好。
9、可视化y和y_predict
fig2=plt.figure(figsize=(10,10))
plt.scatter(y,y_predict)
plt.show()

实战二:单因子房价预测
1、导入房价统计数据
先用excel打开数据

可以看到影响房价的因子很多,这节就选取size这个单因子对房价进行预测
path='Desktop/artificial_intelligence/Chapter2/usa_housing_price.csv'
house_data=pd.read_csv(path)
house_data.head()

2、显示每个因子和房价的散点图
from matplotlib import pyplot as plt
plt.figure(figsize=(18,12))
fig1=plt.subplot(231)
plt.scatter(house_data['Avg. Area Income'],house_data['Price'])
plt.title('Income vs Price')
fig2=plt.subplot(232)
plt.scatter(house_data['Avg. Area House Age'],house_data['Price'])
plt.title('House Age vs Price')
fig3=plt.subplot(233)
plt.scatter(house_data['Avg. Area Number of Rooms'],house_data['Price'])
plt.title('Number of Rooms vs Price')
fig4=plt.subplot(234)
plt.scatter(house_data['Area Population'],house_data['Price'])
plt.title('Area Population vs Price')
fig5=plt.subplot(235)
plt.scatter(house_data['size'],house_data['Price'])
plt.title('size vs Price')
plt.show()

3、house_data赋值
先用size这个单因子和房价进行拟合训练,进行预测房价
X = house_data.loc[:,'size']
y = house_data.loc[:,'Price']
type(X)
pandas.core.series.Series
4、建立线性回归模型
from sklearn.linear_model import LinearRegression
lr1=LinearRegression()
5、模型拟合训练
X=np.array(X).reshape(-1,1)
lr1.fit(X,y)
6、预测计算
y_predict_1=lr1.predict(X)
7、评估模型
from sklearn.metrics import mean_squared_error,r2_score
mes_1=mean_squared_error(y,y_predict_1)
r2_1=r2_score(y,y_predict_1)
print(mes_1)
print(r2_1)
108771672553.6264
0.1275031240418234
通过均方差和R2可以看出这个模型对此次房价数据size这个单因子的拟合训练,对结果的预测并不太好
8、对预测值进行可视化
plt.figure(figsize=[8,6])
plt.scatter(X,y)
plt.plot(X,y_predict_1,'r')
plt.show()

实战三:多因子房价预测
1、数据赋值
还是根据上面的房价数据,只不过这次选择多因子,重新进行赋值
X_multi=house_data.loc[:,'Avg. Area Income':'size']
X_multi

2、创建第二个线性回归模型
lr2=LinearRegression()
3、模型训练拟合
lr2.fit(X_multi,y)
4、模型预测
y_multi_predict=lr2.predict(X_multi)
5、模型评估
from sklearn.metrics import mean_squared_error,r2_score
mse_multi=mean_squared_error(y,y_multi_predict)
r2_multi=r2_score(y,y_multi_predict)
print(mse_multi)
print(r2_multi)
10219846512.17786
0.9180229195220739
print(mes_1)
print(r2_1)
108771672553.6264
0.1275031240418234
通过和第一个模型的评估指标数据对比可以看出来,在这个数据模型中,多因子的预测模型远比单因子的模型要好的多,r2已经达到了0.9多
6、y,y_multi_predict的数据可视化
from matplotlib import pyplot as plt
plt.figure(figsize=(8,8))
plt.scatter(y,y_multi_predict)
plt.show()
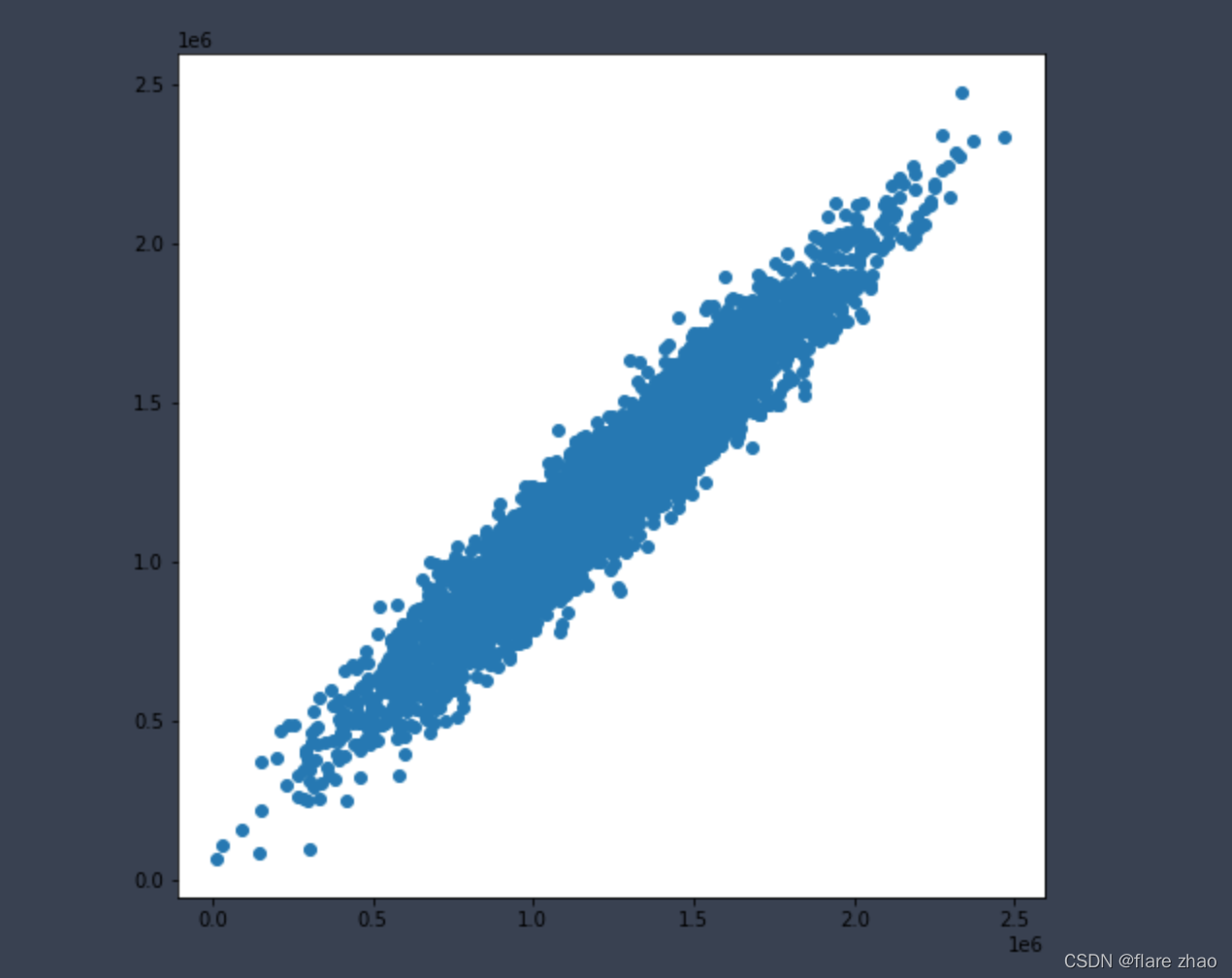
从图像中可以看出相对已经很集中了
7、根据给定的预测数据预测房价
预测Income=65000,House Age=5,Number of Rooms=5,population=30000,size=200的合理房价
x_test=[65000,5,5,30000,200]
y_test_predict=lr2.predict([x_test])
print(y_test_predict)
[817052.19516298]
或者用下面的方法,核心思想向量都是变成二维数组
x_test=[65000,5,5,30000,200]
X_test=np.array(x_test).reshape(1,-1)
y_test_predict=lr2.predict(X_test)
print(y_test_predict)
[817052.19516298]
总结
通过今天的学习,理解了机器学习和线性回归的基本概念,掌握了线性回归模型的基本用法。
线性回归模型是属于监督式的学习,模型的输出是连续型数值,可以用来预测有线性关系的问题,比如未成年前的身高(对应因子有年龄,营养,地区等),房价(对应因子有地区,面积,房龄等),面包的价格(对应相应的线性因子有:重量,人均收入,地区,品牌等)
基于generated_data.csv数据的单因子模型总结:
1、因为这个数据本身就是很规律的线性关系,所以用线性回归模型,可以发现拟合后模型是能够非常精准的预测的。
2、从而可以看出,模型的好坏跟训练的数据是有很大关系的。
3、不同的数据适合不同的模型。而且不同的模型对同一个数据的表现也会不同。
线性回归房价实战总结:
1、通过搭建线性回归模型,实现单因子的房屋价格预测。
2、在单因子模型效果不好的情况下,通过考虑更多的因子,建立了多因子模型。
3、多因子模型达到了更好的预测效果,r2分数为0.9多。
4、实现了预测结果的可视化,直观对比了预测价格和实际价格的差异。
更多详细的内容请观看flare老师的视频:Python3系统入门人工智能-慕课网实战

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)