
PaddleNLP 百度飞桨:快速试用和部署文本纠错模型
环境准备最方便的方法就是docker了:docker pull paddlepaddle/paddle:2.3.0rc0-jupyter启动容器并挂载本地目录docker run -it --rm -v $(pwd):/workspace -p 8000:8000 paddlepaddle/paddle:2.3.0rc0-jupyter bash安装依赖pip install paddlenlp
环境准备
最方便的方法就是docker了:
docker pull paddlepaddle/paddle:2.3.0rc0-jupyter启动容器并挂载本地目录
docker run -it --rm -v $(pwd):/workspace -p 8000:8000 paddlepaddle/paddle:2.3.0rc0-jupyter bash安装依赖
pip install paddlenlp pypinyinPaddleNLP
飞桨增加了Taskflow的接口,非常方便调用,类似于huggingface的pipeline
我们可以试用一下文本纠错模型:
from paddlenlp import Taskflow
corrector = Taskflow("text_correction")
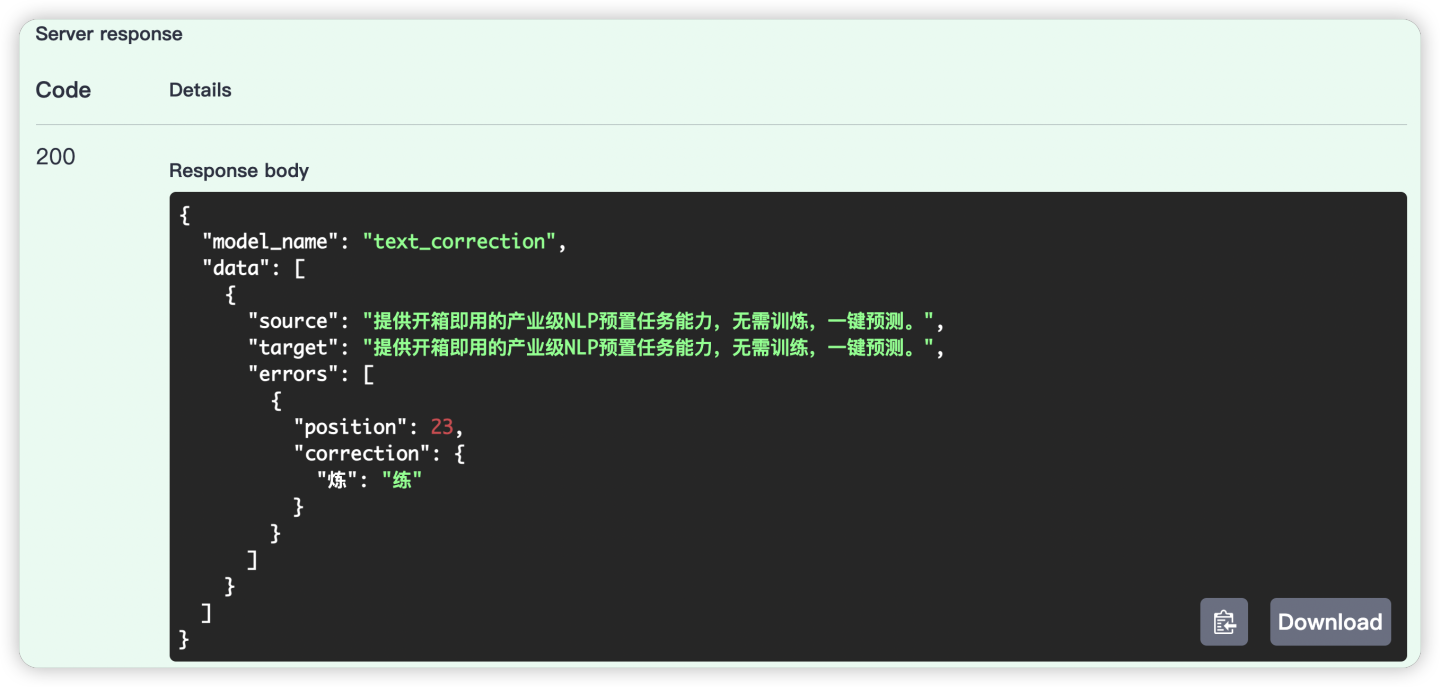
corrector("提供开箱即用的产业级NLP预置任务能力,无需训炼,一键预测。")结果:
[{
'source': '提供开箱即用的产业级NLP预置任务能力,无需训炼,一键预测。',
'target': '提供开箱即用的产业级NLP预置任务能力,无需训练,一键预测。',
'errors': [{'position': 23, 'correction': {'炼': '练'}}]
}]可以看到,找到了对应的错别字。我也试用其他几个错字,但效果不是很理想。
比如训练改成训炼,或者任务改成任物,都没能找到错字。
Pinferencia
那如果我们有了这么一个方便的接口,怎么部署呢?不得不推荐下这个超级简单方便的部署工具:Pinferencia
(Github 搜索 Pinferencia 即可查看项目,或者点击 underneathall/pinferencia: Python + Inference)
我们新建一个文件app.py
from paddlenlp import Taskflow
from pinferencia import Server
corrector = Taskflow("text_correction")
service = Server()
service.register(model_name="text_correction", model=corrector)然后执行
当看到以下输出,表明模型已经启动
INFO: Started server process [270]
INFO: Waiting for application startup.
INFO: Application startup complete现在可以打开浏览器,访问 http://127.0.0.1:8000, 即可访问Pinferencia提供的交互式API页面,我们试下用这个来预测吧:
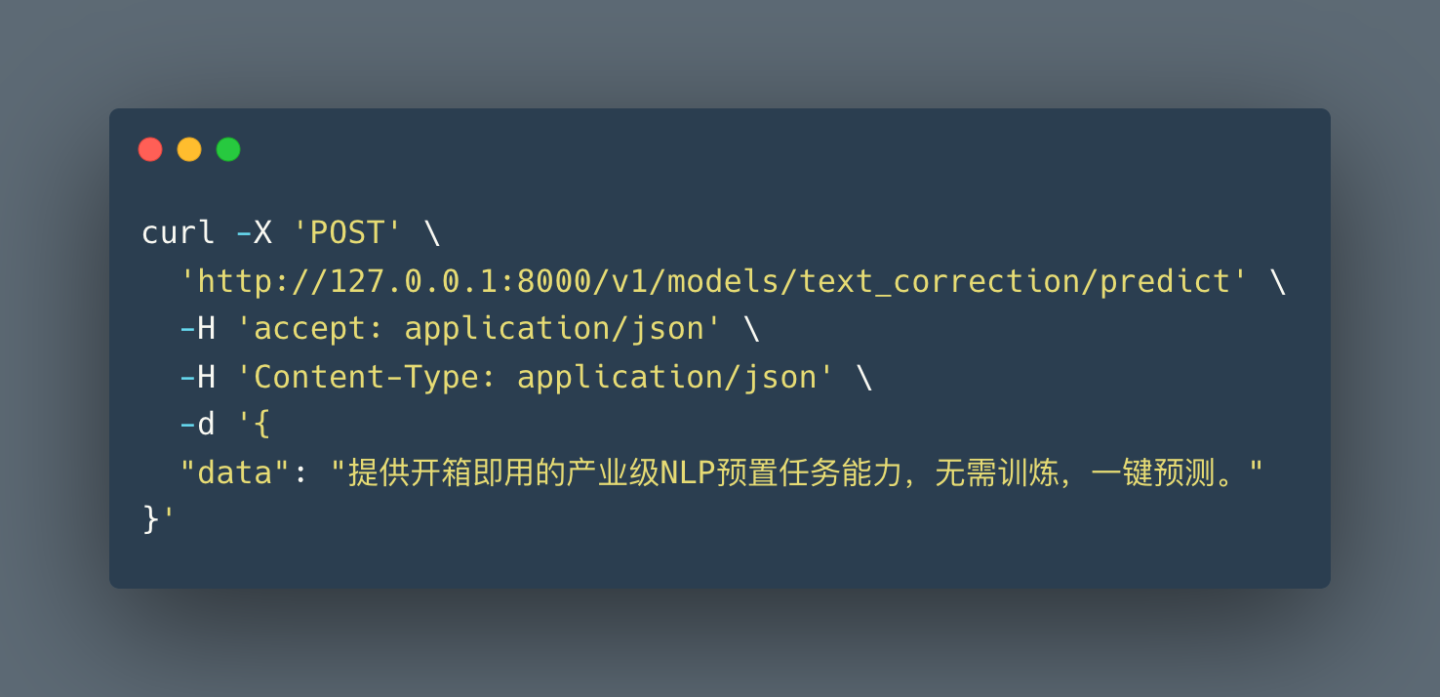
是不是很简单好用?相关的REST API接口也可以按照UI上提供的文档使用Curl或者postman等测试,我们试下Curl

相关项目的github地址
大家可以去相关项目查看详情,如果喜欢的话,可以收藏下
Pinferencia:
underneathall/pinferencia: Python + Inference - Model Deployment library in Python. Simplest model inference server ever. (github.com)![]() https://github.com/underneathall/pinferencia
https://github.com/underneathall/pinferencia

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)