
手把手教数据仓库建设dataworks(小白版)
阿里云数据仓库体系目前构建数据仓库的技术主要为开源框架,像Hadoop,hive,kafka,flink,spark等等,如果自己从0到1去搭建整个数据仓库工作量比较大,且对于性价比不高,故我们采用现成的阿里云提供的数据仓库,阿里云技术框架如下:阿里云产品介绍类比DataHub数据总线Kafka+dataxE-MapReduce开源大数据计算框架上面所说的从0到1用开源框架去搭建数据仓库,适用于已
阿里云数据仓库体系
目前构建数据仓库的技术主要为开源框架,像Hadoop,hive,kafka,flink,spark等等,如果自己从0到1去搭建整个数据仓库工作量比较大,且对于性价比不高,故我们采用现成的阿里云提供的数据仓库,阿里云技术框架如下:
| 阿里云产品 | 介绍 | 类比 |
|---|---|---|
| DataHub | 数据总线 | Kafka+datax |
| E-MapReduce | 开源大数据计算框架 | 上面所说的从0到1用开源框架去搭建数据仓库,适用于已搭建了数据仓库的公司进行改造升级。 |
| MaxCompute | 阿里黑盒大数据计算框架 | E-MapReduce差不多,但是其主要是阿里自己研发的,相当于一个黑盒,即开即用,适合没有搭建过数据仓库的公司使用。 |
| DataWorks | 可视化的开发管理平台 | 相当于我们之前海度系统 |
| RDS | 关系型数据库 | MySQL |
| QuickBI,datav | 可视化数据展示工具 | Tableau,Echarts,powerbi,帆软BI |
我们项目的技术选型主要是:
- 数据采集传输:datax
- 数据存储:MaxCompute,DataWorks
- 数据计算:MaxCompute,DataWorks
- 数据可视化:Superset,Finebi(好像暂时没有)
- 任务调度:DolphinScheduler
Dataworks
新手入门
由于Dataworks和maxcompute有按量计费的特性,我们可以先用自己的阿里云账号进行体验。
控制台入口:Dataworks产品入口
购买体验
可以通过支付宝进行扫描登陆
建议先点击免费开通基础版和本教程一步步学,旁边免费体验的教程太快了,很难跟上。

然后可以进入购买页面
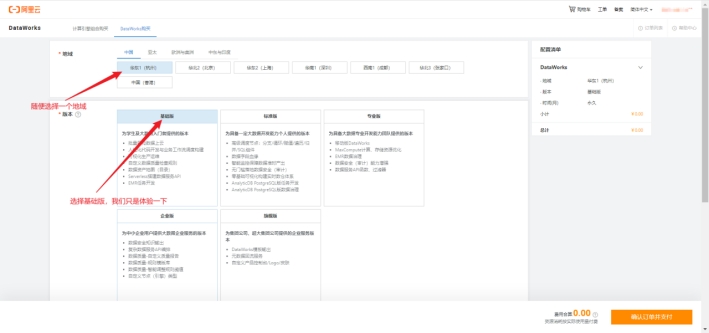
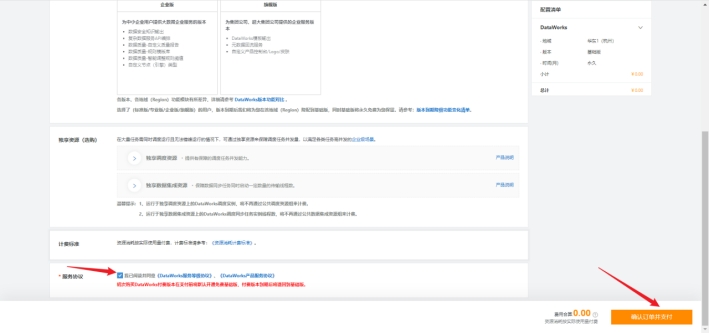
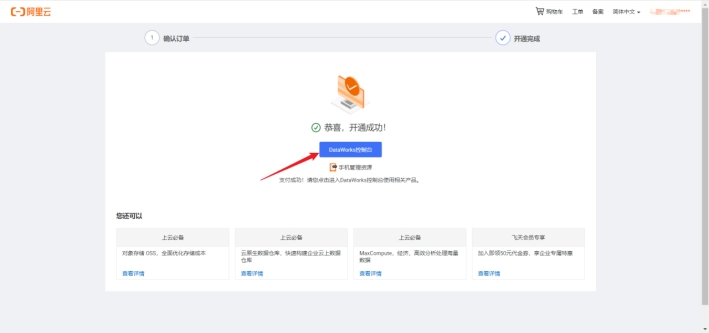
根据新用户引导创建工作空间
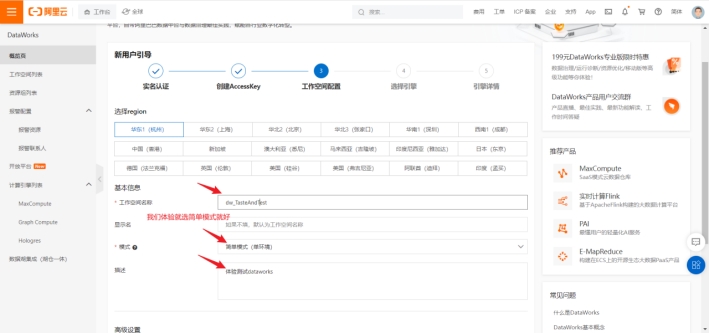
选择对应引擎,我们项目采用的是maxcompute,我们可以点击购买
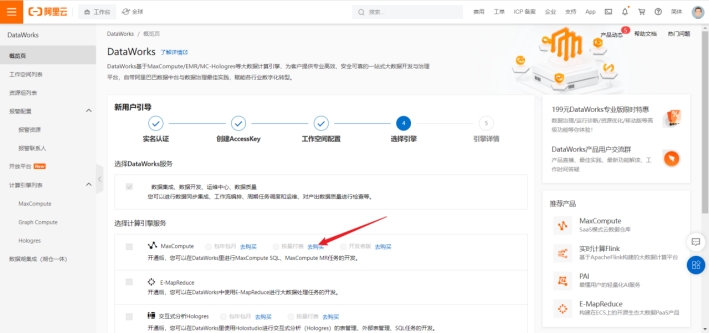
购买maxcompute
按量计费购买
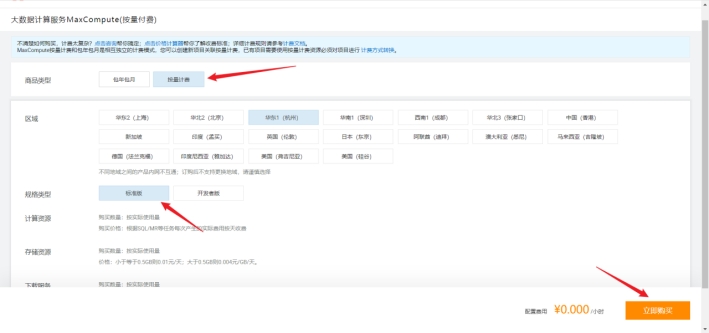
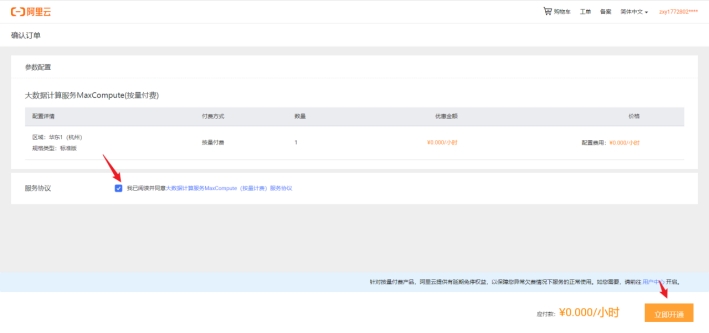
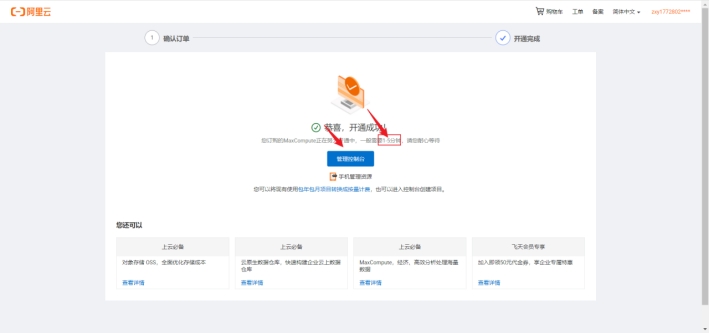
然后我们返回dataworks的页面选择引擎,这时我们可以看到maxcompute的按量计费可以选择
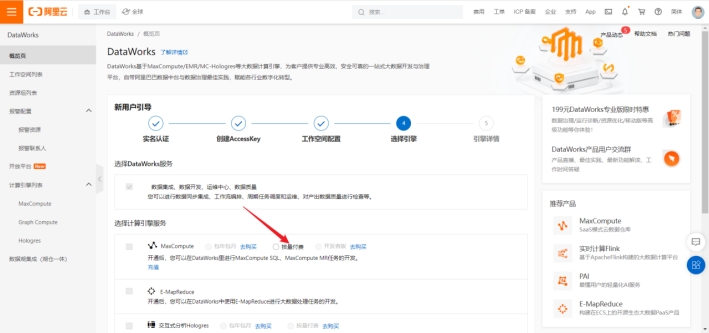
接着我们给引擎命名,同时确认创建工作空间。
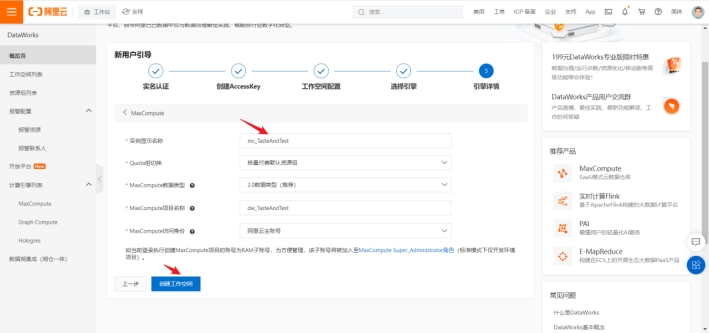
我们选择刚刚创建的工作空间,选择数据开放,就可以进入dataworks的开发页面
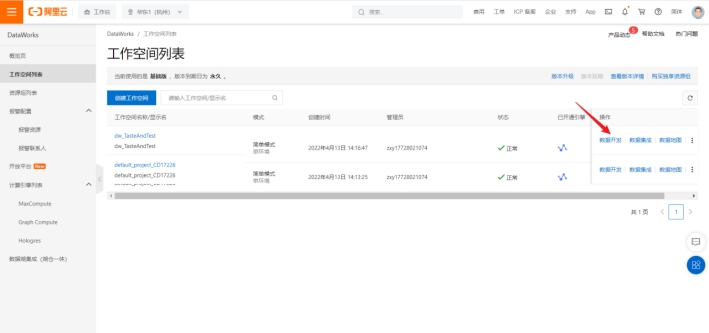
DataStudio操作
DataStudio是DataWorks上进行数据开发的核心模块,支持开发离线、实时的任务。
新用户会有操作向导,进行教学,可以先跟着向导学一遍,然后再看本教程。
但是向导的配图可能和当前操作环境不一致,可以直接看本教程。
数据仓库分层命名规范
ODS层命名为ods_表名
DWD层命名为dwd_表名
DWS层命名为dws_表名
DWT层命名为dwt_表名
ADS层命名为ads_表名
临时表命名为tmp_表名
建立业务流程
1)点击数据开发->业务流程->新建业务流程->输入业务名称
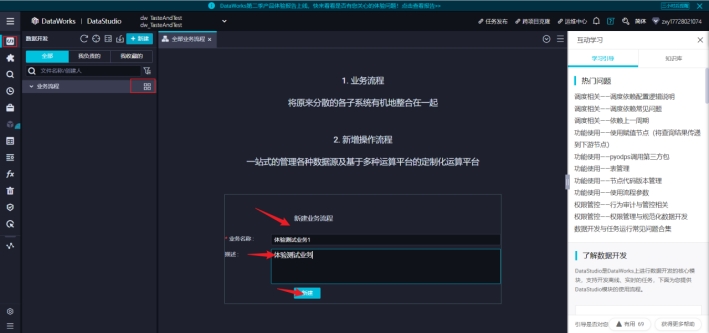
2)在业务流程下面就可以看到体验测试业务1
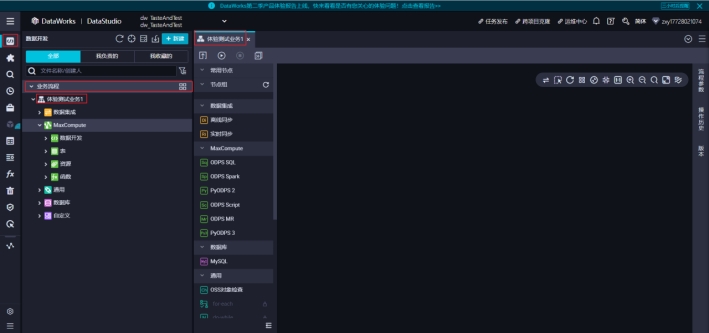
配置表主题
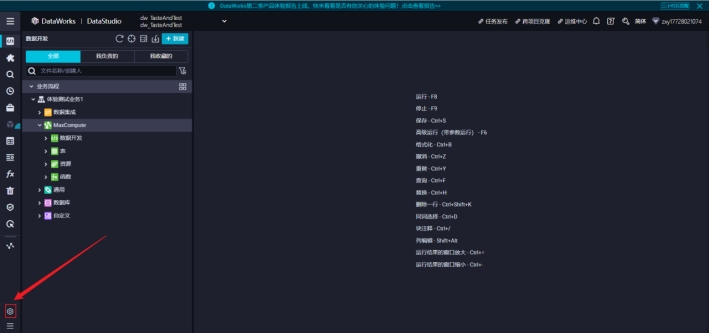
1)进入配置中心
点击最下方的齿轮,进入配置中心
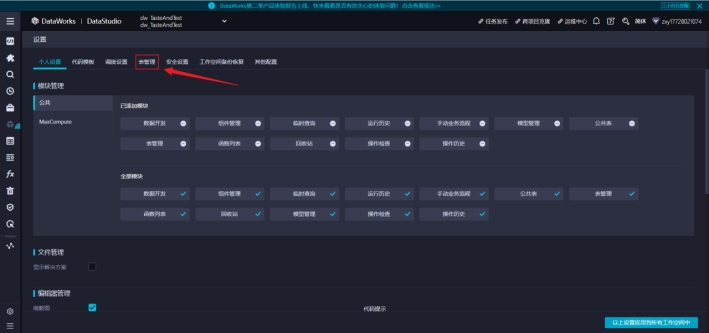
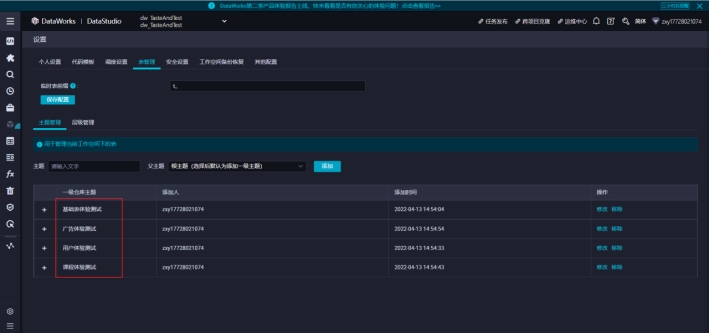
2)配置主题管理,这里主要是划分表的主题
主题一般是表的对应的业务主题,比如:基础表、用户、课程、广告等对应的业务线。
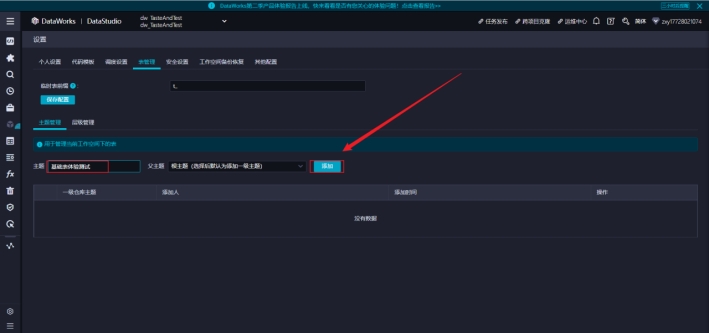
依次添加
配置表层级
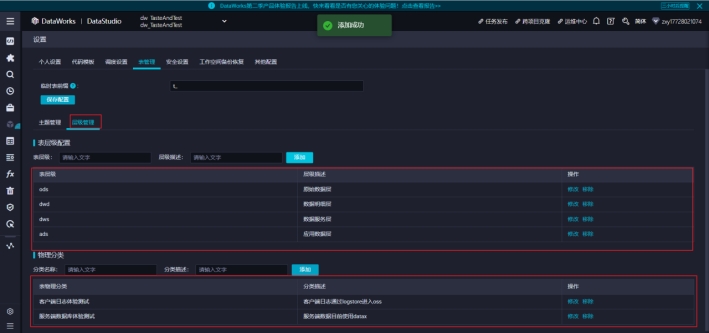
在同一页面中,DataWorks 还提供了一个物理分类的划分维度,用户可以根据情况自行决定划分方式。
由于客户端上报的数据,经过阿里云的 logstore,到达oss, 服务端数据目前使用 datax,对数据表按照数据来源划分为:客户端日志和服务端数据库。
建表语句
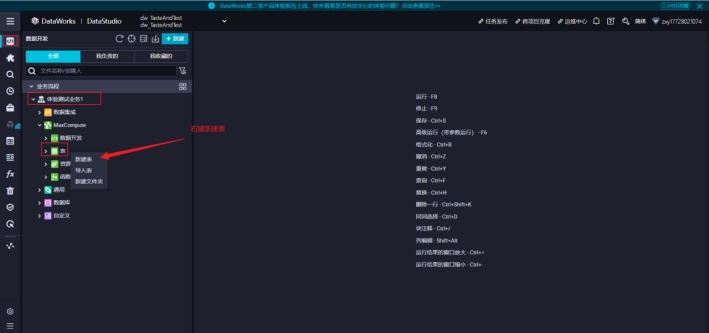
1)回到数据开发的界面,按下图开始创建数据表
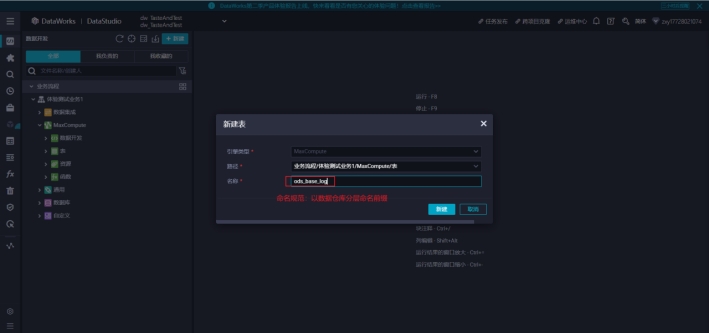
设置基本属性和物理模型
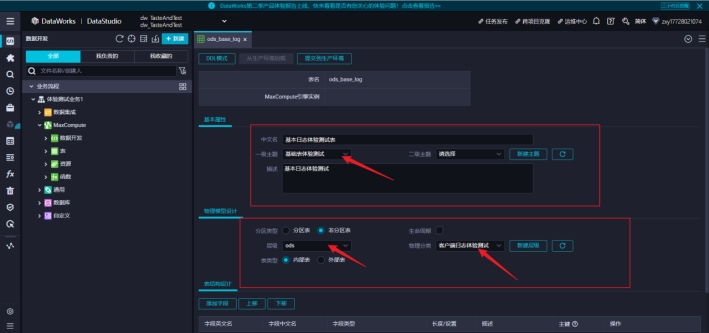
手工文件导入的表可以选择非分区。 为了减少再购买存储服务器,所以选择内部表。真实开发时,大部分情况都是创建外部表,需要在 OSS 服务中申请存储空间。
发送过来的日志包含两部分:服务器时间和日志详情。这里面设计了两个字段对应接收。
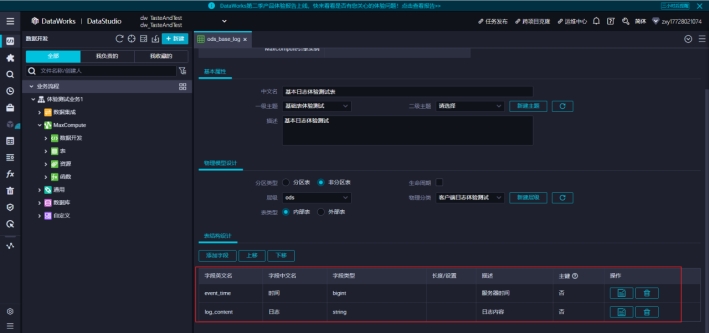
这里的主键,是指一个标志而已,本身不提供索引和唯一性约束。
点击 DDL 模式,可以查看自动生成的建表语句。和普通的创建表语句一样。
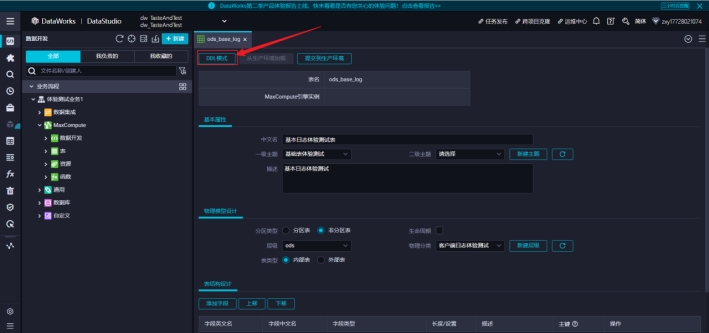
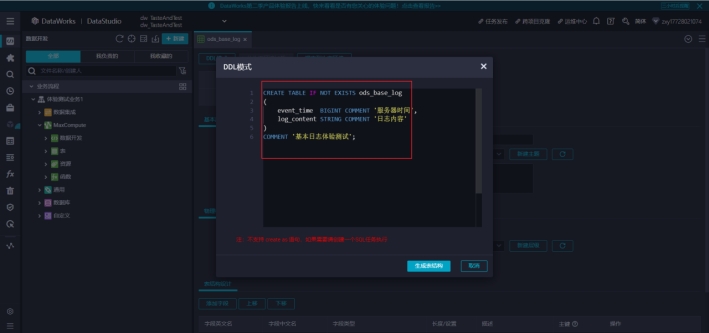
然后取消,点击提交到生产环境,表就创建完成了。
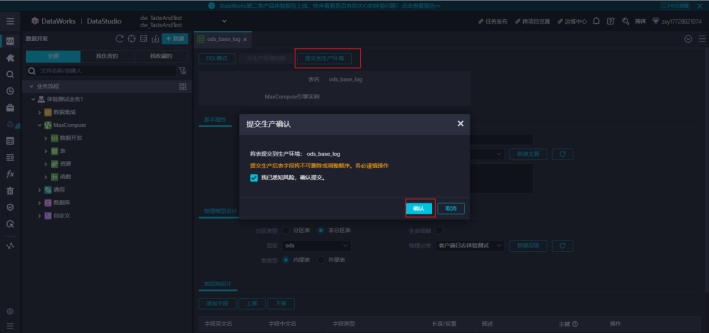
表的基本操作
在最左侧菜单中选择【表管理】,可以在右侧查看表的结构信息。但是不可以修改。
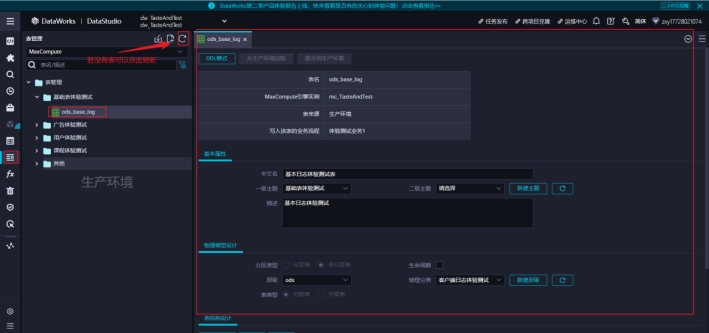
按数据仓库分层管理表
1)在体验测试业务1中建 ods、dwd、dws、ads,4 个文件夹
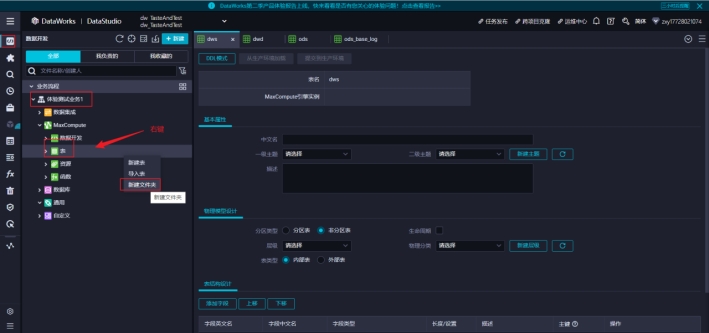
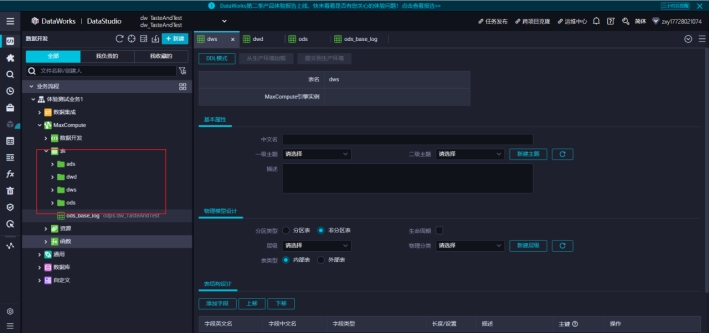
将ods_base_log拖拽到ods文件夹中
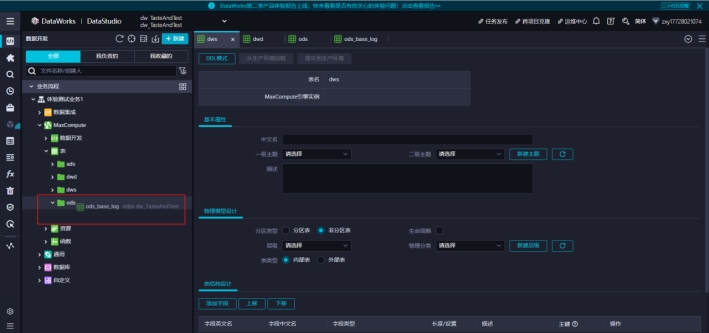
然后需要刷新才能看见表移动到了ods文件夹了
临时查询
1)点击临时查询->新建->ODPS SQL
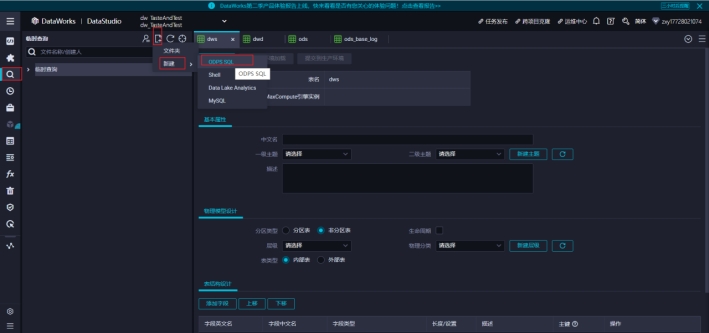
2)创建临时节点
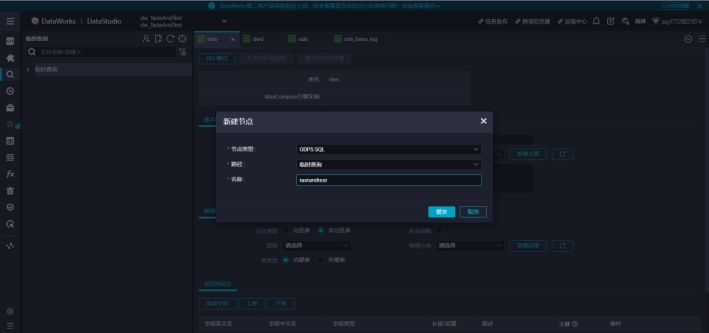
3)可以执行 SQL 命令
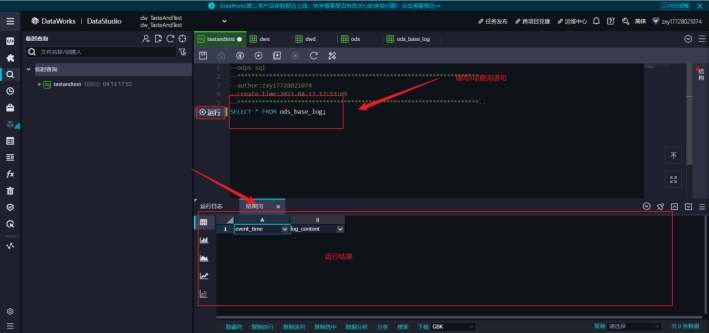
可以看到我们没有数据所以我们可以先去导入两条数据
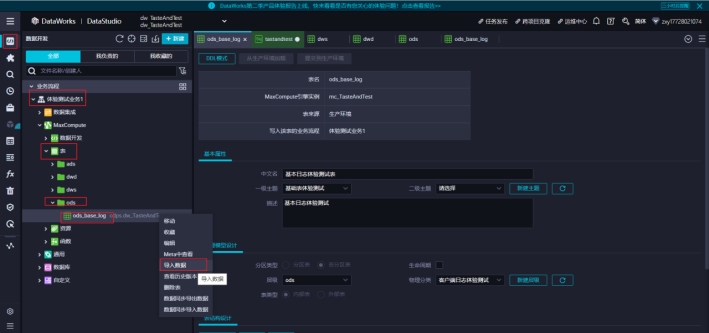
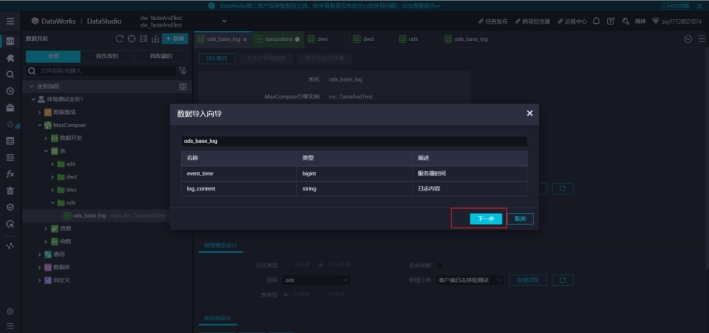
我们在本地电脑中新建一个log_base.csv
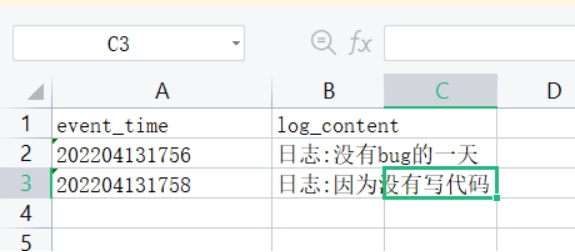
内容如下:
202204131756,日志:没有bug的一天
202204131758,日志:因为没有写代码
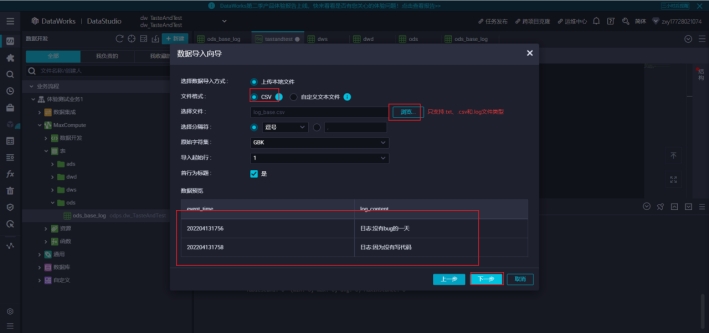
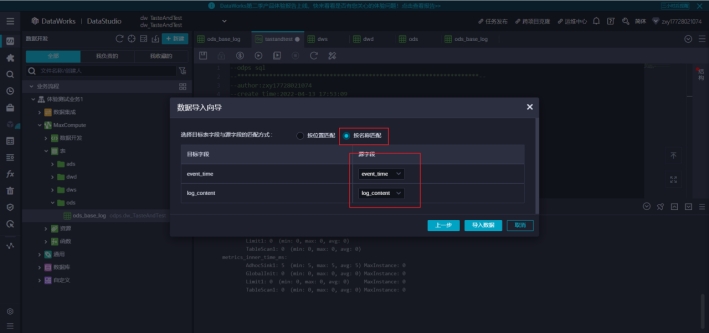
然后我们再回去临时表查询
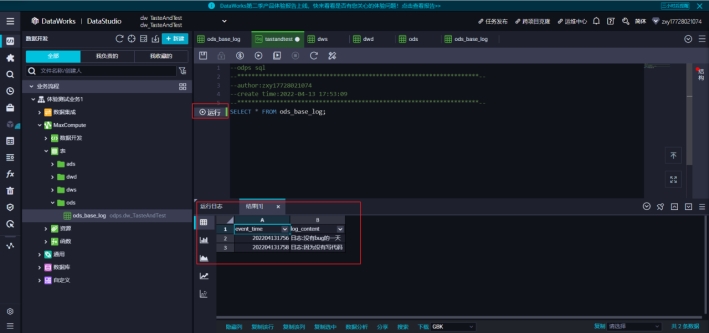
可以看到查询出了结果

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)